使用字典的好处
System.Collections.Generic命名空间下的Dictionary,它的功能非常好用,且功能与现实中的字典是一样的。
它同样拥有目录和正文,目录用来进行第一次的粗略查找,正文进行第二次精确查找。通过将数据进行分组,形成目录,正文则是分组后的结果。它是一种空间换时间的方式,牺牲大的内存换取高效的查询效率。所以,功能使用率查询>新增时优先考虑字典。
public static Tvalue DicTool<Tkey, Tvalue>(Tkey key, Dictionary<Tkey, Tvalue> dic)
{
return dic.TryGetValue(key, out Tvalue _value) ? _value : (Tvalue)default;
}
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 1; i++)
{
DicTool(0, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
执行时间00:00:00.0003135
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool(0, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
执行时间00:00:00.0005091
从上面可以看出,它进行大量查询时的用时非常短,查询效率极高。但使用时需要避免使用枚举作为关键词进行查询;它会造成查询效率降低。
使用枚举作为key时查询效率变低
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool(MyEnum.one, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
执行时间00:00:00.0011010
从这里的执行时间可以看出,查询效率大大降低。
优化方案: 使用int代替enum,enum强制转型后间接查询;可使查询效率与非枚举的直接查询相近。(还有其他的优化方案,个人只使用过这个)
using System;
using System.Diagnostics;
using System.Collections.Generic;
namespace Test
{
public class Program
{
public enum MyEnum : int
{
one,
two,
three
}
public static void Main(string[] args)
{
Dictionary<int, int> Dic = new Dictionary<int, int>()
{
{ (int)MyEnum.one,1},
{ (int)MyEnum.two,2},
{ (int)MyEnum.three,3}
};
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool((int)MyEnum.one, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
}
public static Tvalue DicTool<Tkey, Tvalue>(Tkey key, Dictionary<Tkey, Tvalue> dic)
{
return dic.TryGetValue(key, out Tvalue _value) ? _value : (Tvalue)default;
}
}
}
执行时间 00:00:00.0005005
为什么使用枚举会降低效率
使用ILSpy软件反编译源码,得到以下:
public bool TryGetValue(TKey key, out TValue value)
{
int num = this.FindEntry(key);
if (num >= 0)
{
value = this.entries[num].value;
return true;
}
value = default(TValue);
return false;
}
private int FindEntry(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (this.buckets != null)
{
int num = this.comparer.GetHashCode(key) & 2147483647;
for (int i = this.buckets[num % this.buckets.Length]; i >= 0; i = this.entries[i].next)
{
if (this.entries[i].hashCode == num && this.comparer.Equals(this.entries[i].key, key))
{
return i;
}
}
}
return -1;
}
查看Dictionary源码后可以知道,效率减低来源于this.comparer.GetHashCode(key) 这段代码。
comparer是使用了泛型的成员,它内部使用int类型不会发生装箱,但是由于Enum没有IEquatable接口,内部运行时会引起装箱行为,该行为降低了查询的效率。
IEquatable源码:
namespace System
{
[__DynamicallyInvokable]
public interface IEquatable<T>
{
[__DynamicallyInvokable]
bool Equals(T other);
}
}
装箱:值类型转换为引用类型(隐式转换)
把数据从栈复制到托管堆中,栈中改为存储数据地址。
拆箱:引用类型转换为值类型(显式转换)
补充:C#中Dictionary<Key,Value>中[]操作的效率问题
今天有朋友问到如果一个Dictionary<Key,Value>中如果数据量很大时,那么[ ]操作会不会效率很低。
感谢微软开源C#,让我们有机会通过代码验证自己的猜想。
此处是微软C#的源代码地址
先上结论:Dictionary<Key,Value>的[ ]操作的时间 = 一次调用GetHashCode + n次调用Key.Equals的时间之和。
期中n受传入的key的GetHashCode 的重复率影响,比如传入的key的hash值为5,Dictionary中hash值为5的值有100个,这100值相当于用链表存储,如果要查找的值在第20个那么n的值就是19。如果GetHashCode 基本没什么重复率,那么n始终1,极端情况下n可能为一个很大的数(参考测试代码)。
C#中的关键代码如下:
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
同时在这里我想说一下Dictionary<Key,Value>类中数据的组织结构:
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private int[] buckets;
private Entry[] entries;
期中buckets是保存所有的相同hash值的Entry的链表头,而相同hash值的Entry是通过Entry .next连接起来的。在新加入的Value时,如果已经存在相同hash值会将buckets中的值更新,如果不存在则会加入新的值,关键代码如下:
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
注意最后一句,将新加入值的下标inddex的值赋值给了buckets,这样相当于就更新了链表头指针。这个链表就是前面产生n的原因。
下面我放一些测试的结果:
当GetHashCode的消耗为1ms时:
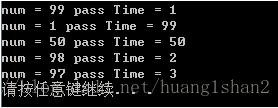
当GetHashCode的消耗为100ms时:
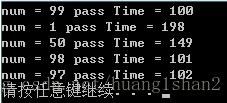
增加的消耗是99ms也就是GetHashCode增加的消耗,后面的尾数就是上面公式里的n。
附测试代码如下:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Threading;
namespace ConsoleApplication1
{
class Program
{
public class Test1
{
private ushort num = 0;
public Test1(ushort a)
{
num = a;
}
public override int GetHashCode()
{
Thread.Sleep(1);
return num / 100;
}
public override bool Equals(object obj)
{
Thread.Sleep(1);
return num.Equals((obj as Test1).num);
}
}
static void Main(string[] args)
{
Dictionary<Test1, string> testDic = new Dictionary<Test1, string>();
for (ushort a = 0; a < 100; a++)
{
Test1 temp = new Test1(a);
testDic.Add(temp, a.ToString());
}
Stopwatch stopWatch = new Stopwatch();
string str = "";
stopWatch.Start();
str = testDic[new Test1(99)];
stopWatch.Stop();
Console.WriteLine("num = " + str +" pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(1)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(50)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(98)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(97)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
}
}
}
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。如有错误或未考虑完全的地方,望不吝赐教。