事情时这样,有用友u8的字典数据的帮助文档一份,同事需要把里面的很多张表的字典信息给提取出来,然后构成sql语句,插入数据库。字典就是一张对表里的字段的一个说明,长这样
事情时这样,有用友u8的字典数据的帮助文档一份,同事需要把里面的很多张表的字典信息给提取出来,然后构成sql语句,插入数据库。字典就是一张对表里的字段的一个说明,长这样
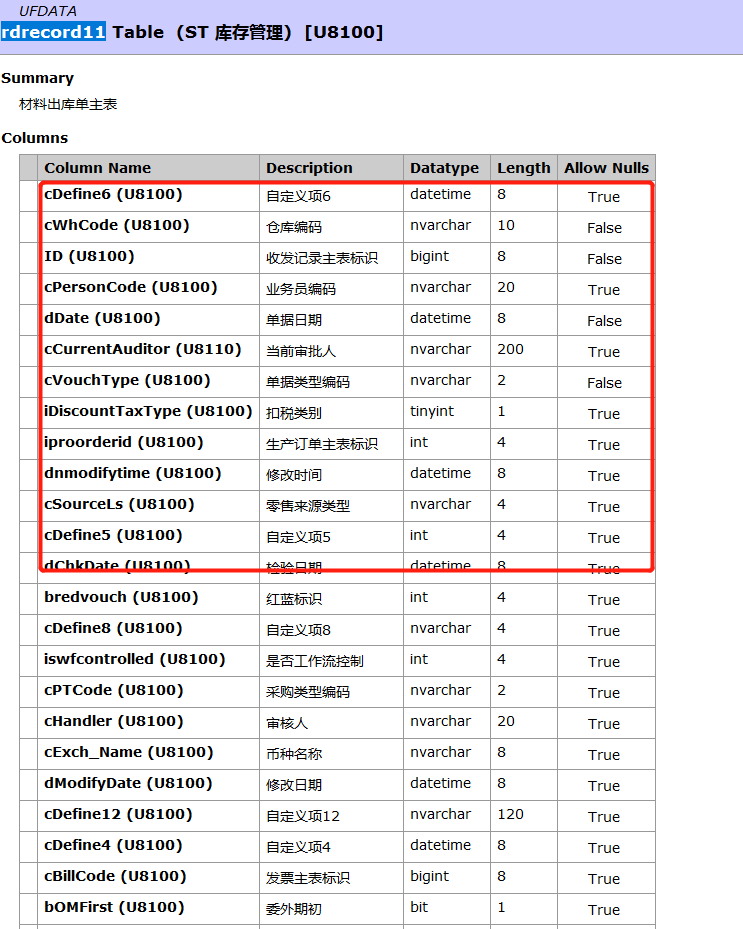
同事一开始是手动复制到excel文档在改的,他问我有没有什么简单的办法,所以我就决定用代码去实现,把表格、表名等一些有效数据构成对象,有了一个对象就好写sql了。
首先,我在百度上搜索,发现这个chm帮助文档能被反编译成html,经过一番操作,使用windows自带的工具 hh.exe 就可以实现帮助文档的反编译。运行cmd,直接输入命令就行,具体命令是这样:
hh -decompile d:\test\help help.chm
d:\test\help是反编译后的目录。
反编译之后,就会得到具体的html文档,和js、css,长这样:
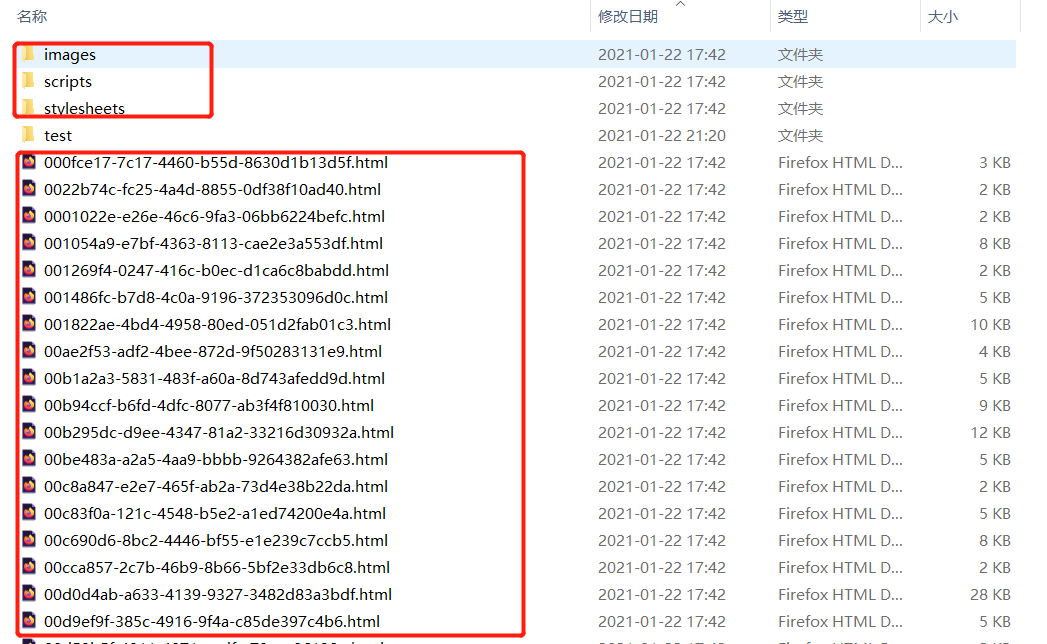
test目录是我自己建的。
后面就是查看html源码,分析出关键信息的xPath路径该怎么写,因为这里我用到了.net的一款工具专门对html操作的,叫做:HtmlAgilityPack,我的翻译是:html敏捷开发包,写xpath比写正则来的容易,这个包能很好的操作html的节点,获取html、innertext、属性。
贴上我的关键方法:
public TableInfo GetTableInfo()
{
TableInfo tab = new TableInfo();
HtmlDocument doc = new HtmlDocument();
doc.Load(FullPathName, Encoding.GetEncoding("gb2312"), true);
if (doc == null)
{
throw new NullReferenceException(FullPathName + "\r\n没有加载出文档");
}
string pathGetTableName = "/html/head/title";
string pathGetTableDesc = "/div/p";
String pathGetTd = "/div/table/tr";
var nodeTitle=doc.DocumentNode.SelectSingleNode(pathGetTableName);
if (null != nodeTitle)
{
tab.TableName = nodeTitle.InnerText.Split(new char[1] { ' '})[0].Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
}
var nodeBody = doc.GetElementbyId("pagebody");
var str = nodeBody.OuterHtml;
var doc1 = new HtmlDocument();
doc1.LoadHtml(str);
var nodeDesc = doc1.DocumentNode.SelectSingleNode(pathGetTableDesc);
if (null != nodeDesc)
{
tab.tableDescription = nodeDesc.InnerText.Split(new char[1] { ' ' })[0].Replace("\r","").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
}
var nodesTr = doc1.DocumentNode.SelectNodes(pathGetTd);
if (nodesTr == null)
{
return tab;
}
List<TabFieldInfo> lists = new List<TabFieldInfo>();
for (var i = 1; i < nodesTr.Count(); i++)
{
var childs = nodesTr[i].ChildNodes;
if (childs == null)
{
continue;
}
TabFieldInfo fi = new TabFieldInfo();
if (childs.Count <= 5)
{
continue;
}
fi.ColumnName = childs[1].ChildNodes[1].InnerText.Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
fi.Description = childs[2].InnerText.Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
fi.Datatype = childs[3].InnerText.Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
fi.Length = childs[4].InnerText.Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
fi.AllowNulls = childs[5].InnerText.Replace("\r", "").Replace("\n", "").Replace("\t", "").Replace("&", "").Replace("nbsp;", "");
lists.Add(fi);
}
tab.fields = lists;
return tab;
}
这里还出现一个问题,“指定的路径不合法”,原因是,我直接点击文件右键-》属性-》安全 把那里的文件路经复制到代码上去了,其实这样复制,会造成路径字符串最开始的地方有个特殊字符,在vs里是隐藏的,后来我就复制地址栏上的路径,就没问题了。
最后,需要完善的是,通过读取目录,把目录中的所有html结尾的文件遍历,并过滤出需要的表,在构建对象。
以上就是c# 提取文档信息的示例的详细内容,更多关于c# 提取文档信息的资料请关注自由互联其它相关文章!