1. 导库
import numpy as npimport tensorflow as tf
import random
import os
import datetime
from collections import Counter #用来统计词频
2. 设置随机化种子
def set_seed():os.environ['PYTHONHASHSEED'] = '0' #会影响hash()函数的返回值
np.random.seed(2019)
random.seed(2019)
tf.set_random_seed(2019)
PYTHONHASHSEED可具体参考文档:https://docs.python.org/3.3/using/cmdline.html#envvar-PYTHONHASHSEED
3. 添加命令行参数
该操作添加命令行参数,或者通过FLAGS修改传入参数。
FLAGS = tf.app.flags.FLAGS#设置参数名称和默认值
tf.app.flags.DEFINE_string('cuda', '0', 'gpu id')
tf.app.flags.DEFINE_boolean('pre_embed', True, 'load pre-trained word2vec')
tf.app.flags.DEFINE_integer('batch_size', 50, 'batch size')
tf.app.flags.DEFINE_integer('epochs', 200, 'max train epochs')
tf.app.flags.DEFINE_integer('hidden_dim', 300, 'dimension of hidden embedding')
tf.app.flags.DEFINE_integer('word_dim', 300, 'dimension of word embedding')
tf.app.flags.DEFINE_integer('pos_dim', 5, 'dimension of position embedding')
tf.app.flags.DEFINE_integer('pos_limit', 15, 'max distance of position embedding')
tf.app.flags.DEFINE_integer('sen_len', 60, 'sentence length')
tf.app.flags.DEFINE_integer('window', 3, 'window size')
tf.app.flags.DEFINE_string('model_path', './model', 'save model dir')
tf.app.flags.DEFINE_string('data_path', './data', 'data dir to load')
tf.app.flags.DEFINE_string('level', 'bag', 'bag level or sentence level, option:bag/sent')
tf.app.flags.DEFINE_string('mode', 'train', 'train or test')
tf.app.flags.DEFINE_float('dropout', 0.5, 'dropout rate')
tf.app.flags.DEFINE_float('lr', 0.001, 'learning rate')
tf.app.flags.DEFINE_integer('word_frequency', 5, 'minimum word frequency when constructing vocabulary list')
4.类代码
class Baseline:4.1 构造函数
def __init__(self, flags):self.lr = flags.lr #学习率
self.sen_len = flags.sen_len #句子的长度,如果不够就做填充,如果超过就做截取
self.pre_embed = flags.pre_embed #预训练的词嵌入
self.pos_limit = flags.pos_limit #设置位置的范围
self.pos_dim = flags.pos_dim #设置位置嵌入的维度
self.window = flags.window #设置窗口大小
self.word_dim = flags.word_dim #设置词嵌入的维度
self.hidden_dim = flags.hidden_dim #设置各种维度
self.batch_size = flags.batch_size
self.data_path = flags.data_path #设置数据所在的文件夹路径
self.model_path = flags.model_path # 设置模型所在文件夹路径
self.mode = flags.mode #选择模式(训练或者测试)
self.epochs = flags.epochs
self.dropout = flags.dropout
self.word_frequency = flags.word_frequency #设置最小词频
self.pos_num = 2 * self.pos_limit + 3 #设置位置的总个数
self.relation2id = self.load_relation()
self.num_classes = len(self.relation2id)
#如果有预训练的词向量
if self.pre_embed:
self.wordMap, word_embed = self.load_wordVec()
self.word_embedding = tf.get_variable(initializer=word_embed, name='word_embedding', trainable=False)
else:
self.wordMap = self.load_wordMap()
self.word_embedding = tf.get_variable(shape=[len(self.wordMap), self.word_dim], name='word_embedding',trainable=True)
self.pos_e1_embedding = tf.get_variable(name='pos_e1_embedding', shape=[self.pos_num, self.pos_dim])
self.pos_e2_embedding = tf.get_variable(name='pos_e2_embedding', shape=[self.pos_num, self.pos_dim])
self.relation_embedding = tf.get_variable(name='relation_embedding', shape=[self.hidden_dim, self.num_classes])
self.relation_embedding_b = tf.get_variable(name='relation_embedding_b', shape=[self.num_classes]) #对应的是全连接层
self.sentence_reps = self.CNN_encoder()
self.sentence_level()
self._classifier_train_op = tf.train.AdamOptimizer(self.lr).minimize(self.classifier_loss)
4.2 读取词向量或者词典
def load_wordVec(self):wordMap = {}
wordMap['PAD'] = len(wordMap)
wordMap['UNK'] = len(wordMap)
word_embed = []
for line in open(os.path.join(self.data_path, 'word2vec.txt')):
content = line.strip().split()
if len(content) != self.word_dim + 1:
continue
wordMap[content[0]] = len(wordMap)
word_embed.append(np.asarray(content[1:], dtype=np.float32))
word_embed = np.stack(word_embed)
embed_mean, embed_std = word_embed.mean(), word_embed.std()
pad_embed = np.random.normal(embed_mean, embed_std, (2, self.word_dim))
word_embed = np.concatenate((pad_embed, word_embed), axis=0)
word_embed = word_embed.astype(np.float32)
return wordMap, word_embed
def load_wordMap(self):#key is word, value is id
wordMap = {}
wordMap['PAD'] = len(wordMap) #0
wordMap['UNK'] = len(wordMap) #1
all_content = []
for line in open(os.path.join(self.data_path, 'sent_train.txt')):
all_content += line.strip().split('\t')[3].split() #这里的+=相当于extend
for item in Counter(all_content).most_common(): 返回一个TopN的元组列表,元组第一个元素是词,第二个元素是频次。
if item[1] > self.word_frequency: #频次大于最低频率
wordMap[item[0]] = len(wordMap) #
else:
break
return wordMap
4.3 读取关系和句子
思考题一:为什么最后需要加reshape,从而把数据维度变为(1, 3, self.sen_len)。这里的1代表的是什么含义?
def load_relation(self):relation2id = {}
for line in open(os.path.join(self.data_path, 'relation2id.txt')):
relation, id_ = line.strip().split()
relation2id[relation] = int(id_)
return relation2id
def load_sent(self, filename):
sentence_dict = {}
with open(os.path.join(self.data_path, filename), 'r') as fr:
for line in fr:
id_, en1, en2, sentence = line.strip().split('\t')
sentence = sentence.split()
en1_pos = 0
en2_pos = 0
for i in range(0, len(sentence)):
if sentence[i] == en1:
en1_pos = i #得到实体1的位置
if sentence[i] == en2:
en2_pos = i #得到实体2的位置
words = []
pos1 = []
pos2 = []
length = min(len(sentence), self.sen_len)
for i in range(0, length):
words.append(self.wordMap.get(sentence[i], self.wordMap['UNK']))
pos1.append(self.pos_index(i - en1_pos))
pos2.append(self.pos_index(i - en2_pos))
if len(sentence) < self.sen_len: #句子长度不够self.sen_len,就进行填充
for i in range(length, self.sen_len):
words.append(self.wordMap['PAD'])
pos1.append(self.pos_index(i - en1_pos))
pos2.append(self.pos_index(i - en2_pos))
sentence_dict[id_] = np.asarray([words, pos1, pos2], dtype=np.int32).reshape(1, 3, self.sen_len)
return sentence_dict
回答一:这里的1代表的是单个句子。扩展为三维,是为了后续的concatenate操作。
4.4 划分数据
思考题一:transform_to_multi_hot是什么类型?为什么要转换成此类型,而不是直接返回list?
思考题二:transform_to_multi_hot的最后一行代码,np.asarray(label_multi_hot_list, dtype = np.float32), (-1, num_classes)中-1指的是多少呢?真实的数值代表什么物理含义呢?
思考题三:以all_labels为例,all_labels在all_labels
= np.concatenate(all_labels, axis=0)之前的维度是多少?它的数据格式是什么样的?操作后又是什么样的呢?
def transform_to_multi_hot(label_str, num_classes):label_multi_hot_list = [0] * num_classes
label_list = label_str.split()
if len(label_list) == 1:
label_multi_hot_list[int(label_list[0])] = 1
else:
for single_label in label_list:
if single_label != '0':
label_multi_hot_list[int(single_label)] = 1 #得到multi-hot对应的list
return np.reshape(np.asarray(label_multi_hot_list, dtype = np.float32), (-1, num_classes))
def data_batcher(self, sentence_dict, filename, padding=False, shuffle=True):
sent_data = pd.read_csv(os.path.join(self.data_path, filename), sep = '\t', header = None)
sent_data.columns = ['id', 'relation']
all_sent_ids = list(sent_data['id'])
all_sents = list(map(lambda x: sentence_dict[x], all_sent_ids))
sent_data['relation'] = sent_data['relation'].apply(lambda x: transform_to_multi_hot(x, self.num_classes))
all_labels = np.asarray(sent_data['relation'])
self.data_size = len(all_sent_ids)
self.datas = all_sent_ids
all_sents = np.concatenate(all_sents, axis=0) #这里使用reshape就会报错
all_labels = np.concatenate(all_labels, axis=0)
data_order = list(range(self.data_size))
if shuffle:
np.random.shuffle(data_order)
if padding:
if self.data_size % self.batch_size != 0:
data_order += [data_order[-1]] * (self.batch_size - self.data_size % self.batch_size)
for i in range(len(data_order) // self.batch_size):
idx = data_order[i * self.batch_size:(i + 1) * self.batch_size]
yield all_sents[idx], all_labels[idx], None
回答一:因为transform_to_multi_hot返回值的元素会构成一个array。如果不进行reshape变成二维矩阵的话,concatenate就会变成一维的。如下所示:
a1 = np.asarray([1, 2])a2 = np.asarray([3, 4])
a3 = np.asarray([5, 6])
a = [a1, a2, a3]
res = np.concatenate(a, axis=0)
print(res)
结果即为
array([1, 2, 3, 4, 5, 6])正确的代码如下所示:
a1 = np.asarray([1, 2])a1 = a1.reshape(-1, 2)
a2 = np.asarray([3, 4])
a2 = a2.reshape(-1, 2)
a3 = np.asarray([5, 6])
a3 = a3.reshape(-1, 2)
a = [a1, a2, a3]
res = np.concatenate(a, axis=0)
print(res)
结果如下所示:
array([[1, 2],[3, 4],
[3, 4]])
回答二:这里的-1其实代表的是1,1代表的是单个句子。返回值代表的是单个句子对应的多种关系(最常见的是一种,少数为不止一只的)。
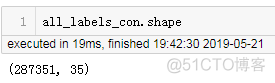
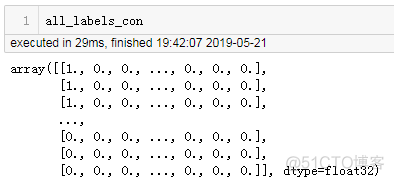
回答三:all_labels在concatenate之前是array of array,它的shape为287351,可见截图:
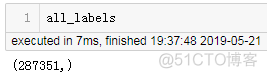
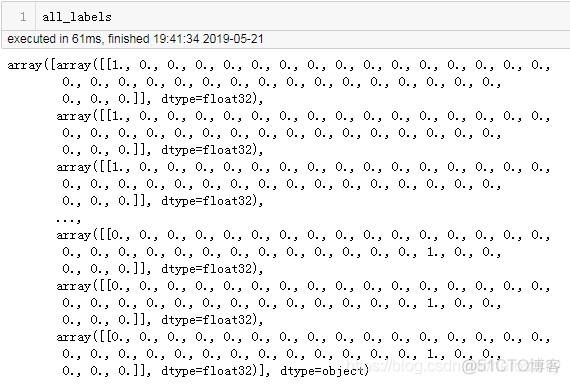
concatenate之后,shape变为了(287351, 35),shape和数据如下图所示: