概述 Python在处理CSV文件时,如果writerow的对象是type 'unicode'字符串时,写入到CSV文件时将会出现一个字符占一个单元格的情况: 但是将字符串 转 换为列表类型时,进行writerow写入即可实
概述
Python在处理CSV文件时,如果writerow的对象是<type 'unicode'>字符串时,写入到CSV文件时将会出现一个字符占一个单元格的情况:
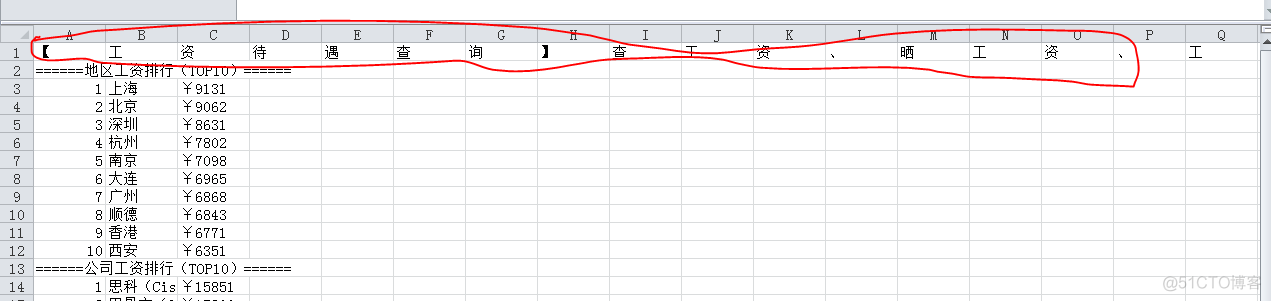
但是将字符串转换为列表类型时,进行writerow写入即可实现,writerow一个列表只占一个单元格:
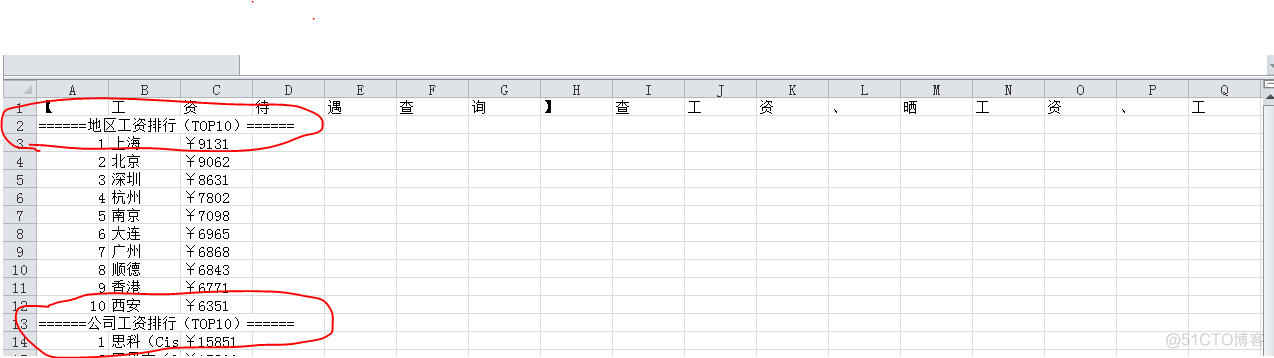
代码:
#encoding=utf-8#不打开浏览器进行操作
import sys,csv,codecs
import time
from lxml import etree
reload(sys)
sys.setdefaultencoding('utf-8')
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument("headless")
driver = webdriver.Chrome(chrome_options=option)
# driver = webdriver.Chrome()
driver.get("https://www.kanzhun.com/xs/?ka=head-salary")
print([driver.title])
#打开CSV文件
csvfile=codecs.open('C:\Users\Desktop\test.csv','wb','gbk')
writer = csv.writer(csvfile)
writer.writerow(driver.title)
#获取城市工资排名
aa=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[1]/dd/ul/li/i')
bb=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[1]/dd/ul/li/a')
cc=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[1]/dd/ul/li/span')
print('======地区工资排行(TOP10)======')
writer.writerow([u'======地区工资排行(TOP10)======'])
for (i,o,p) in zip(aa,bb,cc):
i = i.text
o = o.text
p = p.text
print(type(p))
ss = [i, o, p]
writer.writerow(ss)
print(i+'...'+o+'...'+p)
#获取公司工资排名
aa=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[2]/dd/ul/li/i')
bb=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[2]/dd/ul/li/a')
cc=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[2]/dd/ul/li/span')
print('======公司工资排行(TOP10)======')
writer.writerow([u'======公司工资排行(TOP10)======'])
for (i,o,p) in zip(aa,bb,cc):
i = i.text
o = o.text
p = p.text
ss = [i, o, p]
writer.writerow(ss)
print(i+'...'+o+'...'+p)
#获取职位工资排名
aa=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[3]/dd/ul/li/i')
bb=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[3]/dd/ul/li/a')
cc=driver.find_elements_by_xpath('/html/body/div/section[1]/div[3]/dl[3]/dd/ul/li/span')
print('======职位工资排行(TOP10)======')
writer.writerow([u'======职位工资排行(TOP10)======'])
for (i,o,p) in zip(aa,bb,cc):
i = i.text
o = o.text
p = p.text
ss = [i,o,p]
writer.writerow(ss)
print(i+'...'+o+'...'+p)
csvfile.close()
driver.quit()
CSV文件:

注意:
其中开头的reload(sys)和打开csv文件时的‘gbk’都是辅助解决字符编码问题的。
更多内容详见微信公众号:Python研究所
