这里就省略了~
- 第一页
- 第二页
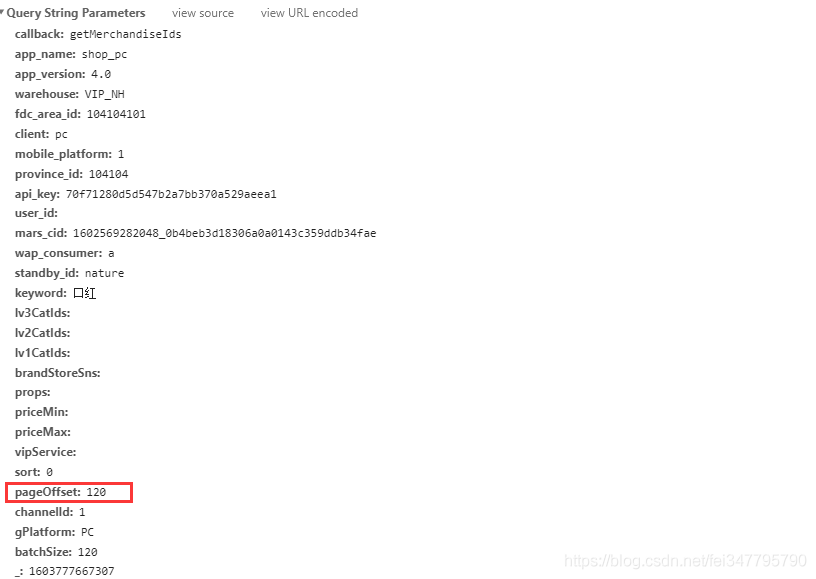
pageOffset参数的变化每120个数据翻一页嘛,ID都获取了,前面也看到每个商品数据接口对应的是50条数据,经过分析就知道 120个商品划分为是三个 50,50,20 分别传入相对应的商品ID就可以了。
[](()实现代码
- 获取每页商品ID值
for page in range(0, 1201, 120):
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank'
headers = {
'referer': 'https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&ff=235%7C12%7C1%7C1&page=3',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
params = {
'callback': 'getMerchandiseIds',
'app_name': 'shop_pc',
'app_version': '4.0',
'warehouse': 'VIP_NH',
'fdc_area_id': '104104101',
'client': 'pc',
'mobile_platform': '1',
'province_id': '104104',
'api_key': '70f71280d5d547b2a7bb370a529aeea1',
'user_id': '',
'mars_cid': '1602569282048_0b4beb3d18306a0a0143c359ddb34fae',
'wap_consumer': 'a',
'standby_id': 'nature',
'keyword': '口红',
'lv3CatIds': '',
'lv2CatIds': '',
'lv1CatIds': '',
'brandStoreSns': '',
'props': '',
'priceMin': '',
'priceMax': '',
'vipService': '',
'sort': '0',
'pageOffset': '{}'.format(page),
'channelId': '1',
'gPlatform': 'PC',
'batchSize': '120',
'_': '1603721644362',
}
response = requests.get(url=url, params=params, headers=headers)
ids = re.findall('"pid":"(.*?)"', response.text, re.S)
- 获取商品数据
def get_data(num_id):
data_url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2'
headers = {
'referer': 'https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&ff=235%7C12%7C1%7C1&page=3',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
params = {
'callback': 'getMerchandiseDroplets2',
'app_name': 'shop_pc',
'app_version': '4.0',
'warehouse': 'VIP_NH',
'fdc_area_id': '104104101',
'client': 'pc',
'mobile_platform': '1',
'province_id': '104104',
'api_key': '70f71280d5d547b2a7bb370a529aeea1',
'user_id': '',
'mars_cid': '1602569282048_0b4beb3d18306a0a0143c359ddb34fae',
'wap_consumer': 'a',
'productIds': '{}'.format(num_id),
'scene': 'search',
'standby_id': 'nature',
'extParams': '{"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2","exclusivePrice":"1","iconSpec":"2x"}',
'context': '',
'_': '1603721644366',
}
response_2 = requests.get(url=data_url, params=params, headers=headers)
titles = re.findall('"title":"(.*?)"', response_2.text, re.S) # 标题
salePrice = re.findall(',"salePrice":"(.*?)",', response_2.text, re.S) # 售价
marketPrice = re.findall('"marketPrice":"(.*?)"', response_2.text, re.S) # 原价
saleDiscount = re.findall('"saleDiscount":"(.*?)"', response_2.text, re.S) # 折扣
smallImage = re.findall('"smallImage":"(.*?)"', response_2.text, re.S) # 商品图片地址
lis = zip(titles, salePrice, marketPrice, saleDiscount, smallImage)
dit = {}
for li in lis:
dit['商品名字'] = li[0]
dit['售价'] = li[1]
dit['原价'] = li[2]
dit['折扣'] = li[3]
dit['商品图片地址'] = li[4]
print(dit)