1、概念
【关注公众号“轻松学编程”了解更多。
回复“协程”获取本文源代码。】
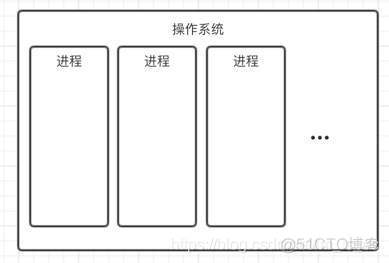
从计算机硬件角度:
计算机的核心是CPU,承担了所有的计算任务。
一个CPU,在一个时间切片里只能运行一个程序。
1.1 进程
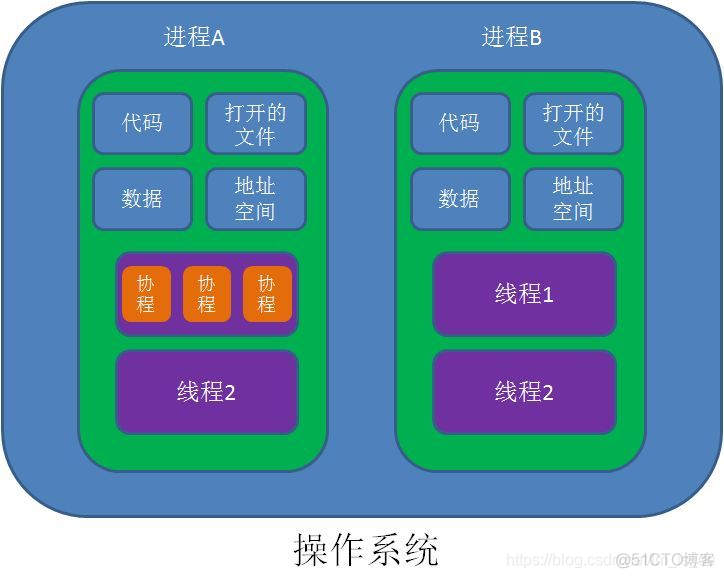
进程:是CPU对程序的一次执行过程、一次执行任务。各个进程有自己的内存空间、数据栈等。操作系统分配内存的基本单位(打开、执行、保存…)
1.2 线程
线程:是进程中执行运算的最小单位,是进程中的一个实体。(打开、执行、保存…)
一个程序至少有一个进程,一个进程至少有一个线程。
操作系统分配CPU的基本单位
1.3 协程
协程:比线程更小的执行单元,又称微线程,在单线程上执行多个任务,自带CPU上下文
用函数切换,开销极小。不通过操作系统调度,
没有进程、线程的切换开销。(gevent,monkey.patchall)
举例
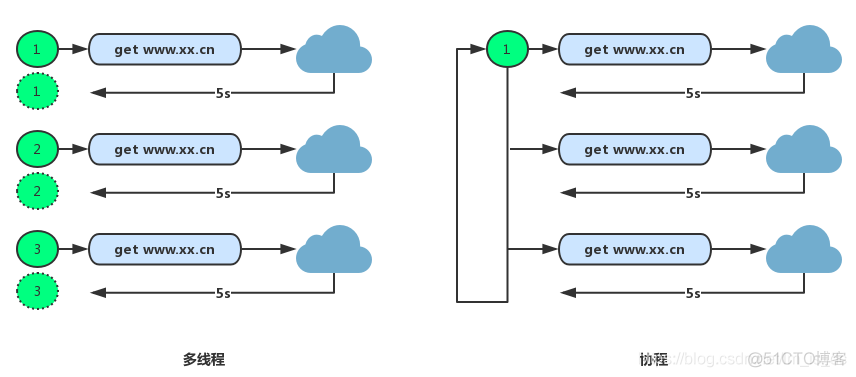
我们假设把一个进程比作我们实际生活中的一个拉面馆,负责保持拉面馆运行的服务员就是线程,每个餐桌代表要完成的任务。
当我们用多线程完成任务时,模式是这样的:每来一桌的客人,就在那张桌子上安排一个服务员,即有多少桌客人就得对应多少个服务员;
而当我们用协程来完成任务时,模式却有所不同了: 就安排一个服务员,来吃饭得有一个点餐和等菜的过程,当A在点菜,就去B服务,B叫了菜在等待,我就去C,当C也在等菜并且A点菜点完了,赶紧到A来服务… …依次类推。
从上面的例子可以看出,想要使用协程,那么我们的任务必须有等待。当我们要完成的任务有耗时任务,属于IO密集型任务时,我们使用协程来执行任务会节省很多的资源(一个服务员和多个服务员的区别,并且可以极大的利用到系统的资源。
1.4 线程安全
多线程环境中,共享数据同一时间只能有一个线程来操作。1.5 原子操作
原子操作就是不会因为进程并发或者线程并发而导致被中断的操作。1.6 并行和并发
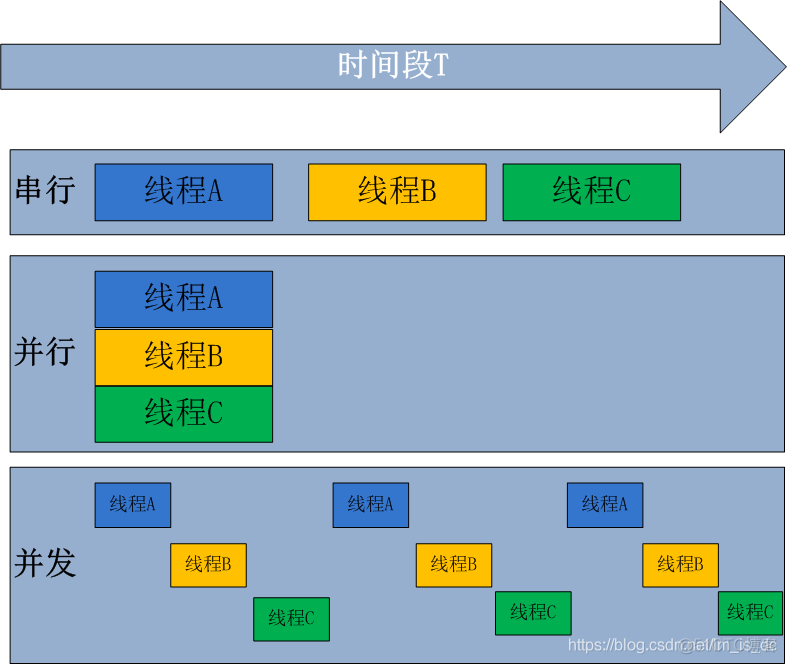
串行:单个CPU核心,按顺序执行
并行:多个CPU核心,不同的程序就分配给不同的CPU来运行。可以让多个程序同时执行。(多进程)
并发:单个CPU核心,在一个时间切片里一次只能运行一个程序,如果需要运行多个程序,则串行执行,遇到IO阻塞就切换,即计算机在逻辑上能处理多任务的能力。(多进程,多线程)
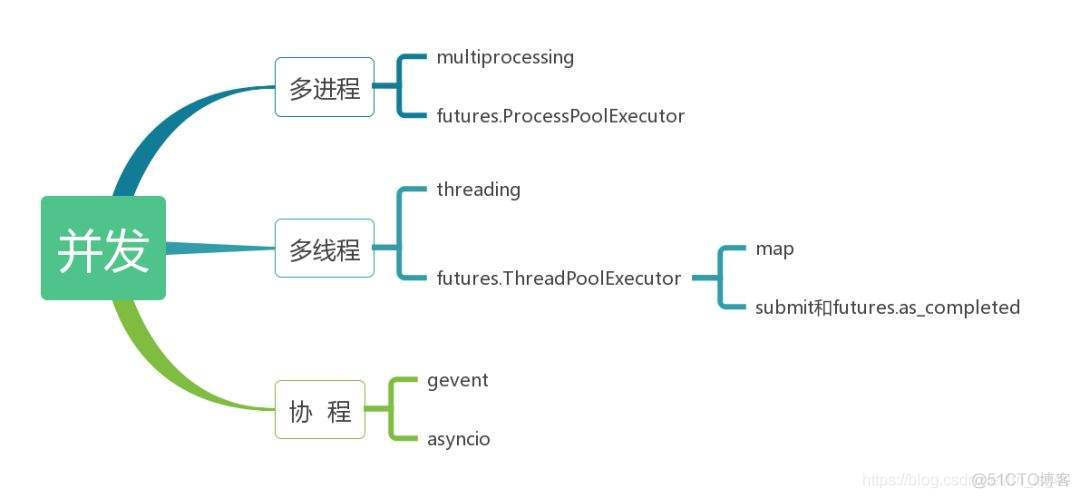
1.7 多进程/多线程
表示可以同时执行多个任务,进程和线程的调度是由操作系统自动完成。
进程:每个进程都有自己独立的内存空间,不同进程之间的内存空间不共享。
线程:一个进程可以有多个线程,所有线程共享进程的内存空间,通讯效率高,切换开销小。共享意味着竞争,导致数据不安全,为了保护内存空间的数据安全,引入"互斥锁",“递归锁”,“升序锁”等。
1.8 Python的多线程:
GIL:Global Interpreter Lock, 全局解释器锁,线程的执行权限,在Python的进程里只有一个GIL。
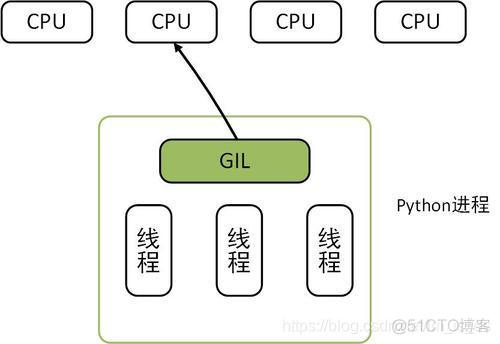
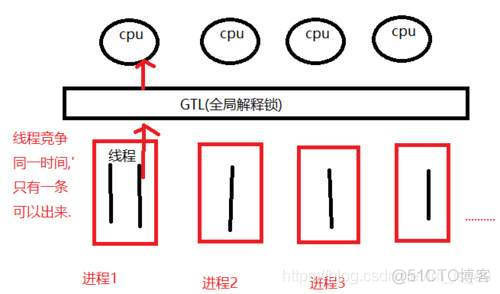
一个线程需要执行任务,必须获取GIL。
好处:直接杜绝了多个线程访问内存空间的安全问题。
坏处:Python的多线程不是真正多线程,不能充分利用多核CPU的资源。
但是,在I/O阻塞的时候,解释器会释放GIL。
1.9 同步、异步、阻塞、非阻塞
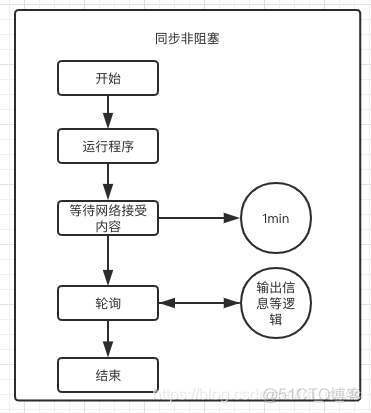
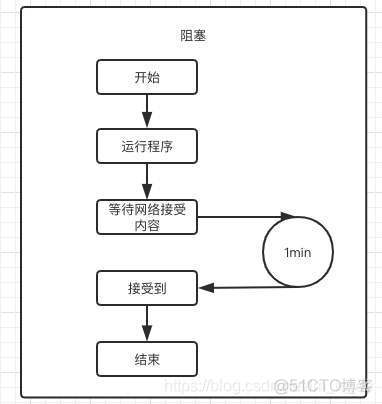
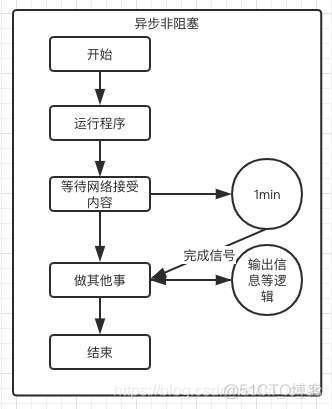
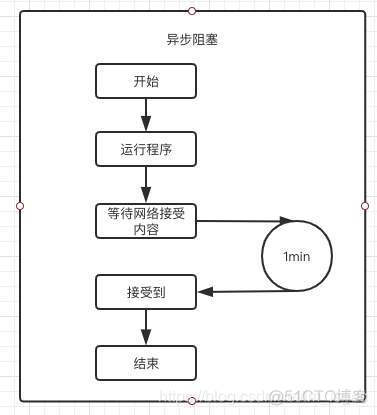
异步,异步本质上是单线程的,因为 IO 操作在很多时候会存在阻塞,异步就是在这种阻塞的时候,通过控制权的交换来实现多任务的。即异步本质上是运行过程中的控制权的交换。最典型的例子就是生产者消费者模型。
同步,即程序协同进行,遇到阻塞就等待,直到任务完成为止。
2.0 运用场景
多进程:密集CPU任务,需要充分使用多核CPU资源(服务器,大量的并行计算)的时候,用多进程。 multiprocessing
缺陷:多个进程之间通信成本高,切换开销大。
多线程:密集I/O任务(网络I/O,磁盘I/O,数据库I/O)使用多线程合适。
threading.Thread、multiprocessing.dummy
缺陷:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发。

协程:又称微线程(一种用户态的轻量级线程),在单线程上执行多个任务,用函数切换,由程序自身控制,开销极小。
不通过操作系统调度,没有进程、线程的切换开销。
每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置,不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
当程序中存在大量不需要CPU的操作时(IO),遇到IO操作自动切换到其它协程。
greenlet, gevent,monkey.patchall,yield,async
多线程请求返回是无序的,哪个线程有数据返回就处理哪个线程,而协程返回的数据是有序的。
因为协程是一个线程执行,所以想要利用多核CPU,最简单的方法是多进程+协程,这样既充分利用多核,又充分发挥协程的高效率。
缺陷:单线程执行,处理密集CPU和本地磁盘IO的时候,性能较低。处理网络I/O性能还是比较高.
2.1 互斥锁、递归锁、升序锁
Python的GIL只能保证原子操作的线程安全,因此在多线程编程时我们需要通过加锁来保证线程安全。
最简单的锁是互斥锁(同步锁),互斥锁是用来解决IO密集型场景产生的计算错误,即目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
递归锁:就是在一个大锁中再包含子锁
升序锁:两个线程想获取到的锁,都被对方线程拿到了,那么我们只需要保证在这两个线程中,获取锁的顺序保持一致就可以了。举个例子,我们有线程thread_a, thread_b, 锁lock_1, lock_2。只要我们规定好了锁的使用顺序,比如先用lock_1,再用lock_2,当线程thread_a获得lock_1时,其他线程如thread_b就无法获得lock_1这个锁,也就无法进行下一步操作(获得lock_2这个锁),也就不会导致互相等待导致的死锁。简言之,解决死锁问题的一种方案是为程序中的每一个锁分配一个唯一的id,然后只允许按照升序规则来使用多个锁,这个规则使用上下文管理器 是非常容易实现的。
2.2 代码
创建进程
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 创建进程.py
@time: 2020/3/3 12:22
@author:LDC
'''
import multiprocessing
import time
def func(arg):
pname = multiprocessing.current_process().name # 获取当前进程名称
pid = multiprocessing.current_process().pid # 获取当前进程id
print("当前进程ID=%d,name=%s" % (pid, pname))
for i in range(5):
print(pname, pid, arg)
time.sleep(1)
pass
if __name__ == "__main__":
pname = multiprocessing.current_process().name
pid = multiprocessing.current_process().pid
print("当前进程ID=%d,name=%s" % (pid, pname))
p = multiprocessing.Process(target=func, name='我是子进程', args=("hello",))
p.daemon = True # 设为【守护进程】(随主进程的结束而结束)
p.start()
while True:
print("子进程是否活着?", p.is_alive())
# 知道进程名称,可以通过以下方式检验
processing = list(filter(lambda mp: mp.name == '我是子进程', multiprocessing.active_children()))
if processing:
print('【我是子进程】这个进程还活着')
if not p.is_alive():
break
time.sleep(1)
pass
print("main over")
进程间的通讯
每个进程都拥有自己的内存空间,因此不同进程间内存是不共享的,要想实现两个进程间的数据交换,有几种常用的方法:
Queue(队列):
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 进程间的通讯.py
@time: 2020/3/3 15:13
@author:LDC
'''
from multiprocessing import Process, Queue, current_process
def start(q):
pname = current_process().name
pid = current_process().pid
print('当前进程是{}_{}'.format(pid, pname))
# 从队列中取出数据,先判断队列 是否为空
if not q.empty():
print(q.get())
# 存数据进队列
q.put('hello from {}_{}'.format(pid, pname))
if __name__ == '__main__':
q = Queue()
p_list = []
for i in range(0, 2):
p = Process(target=start, args=(q,))
p.start()
p_list.append(p)
# 确保所有进程执行完
for p in p_list:
p.join()
Manager(实现了进程间真正的数据共享):
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 进程间的通讯(manager).py
@time: 2020/3/3 15:54
@author:LDC
'''
from multiprocessing import Process, Manager, current_process
def start(m_dict, m_list):
pname = current_process().name
pid = current_process().pid
print('当前进程是{}_{}'.format(pid, pname))
print(m_dict)
m_dict[pid] = pname
m_list.append(pid)
if __name__ == '__main__':
manager = Manager()
m_dict = manager.dict() # 通过manager生成一个字典
m_list = manager.list() # 通过manager生成一个列表
p_list = []
for i in range(10):
p = Process(target=start, args=(m_dict, m_list))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(m_dict)
print(m_list)
进程池(多进程)
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
1、apply(同步)
2、apply_async(异步)
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 进程池.py
@time: 2020/3/3 16:05
@author:LDC
'''
from multiprocessing import Pool, current_process
import time
def Foo(i):
pid = current_process().pid
pname = current_process().name
time.sleep(1)
print('hello','{},{}_{}'.format(i, pid, pname))
return '{},{}_{}'.format(i, pid, pname)
def Bar(arg):
print('number::', arg)
if __name__ == "__main__":
pool = Pool(3) # 定义一个进程池,里面有3个进程
for i in range(10):
# 使用异步线程时,需要定义一个回调函数,当执行完后把结果传给回调函数
pool.apply_async(func=Foo, args=(i,), callback=Bar)
# pool.apply(func=Foo, args=(i,))
pool.close() # 关闭进程池
pool.join() # 进程池中进程执行完毕后再关闭,(必须先close在join)
输出:
hello 0,12776_SpawnPoolWorker-1number:: 0,12776_SpawnPoolWorker-1
hello 1,8832_SpawnPoolWorker-2
hello 2,4704_SpawnPoolWorker-3
number:: 1,8832_SpawnPoolWorker-2
number:: 2,4704_SpawnPoolWorker-3
hello 5,8832_SpawnPoolWorker-2
hello 4,4704_SpawnPoolWorker-3
number:: 5,8832_SpawnPoolWorker-2
number:: 4,4704_SpawnPoolWorker-3
hello 3,12776_SpawnPoolWorker-1
number:: 3,12776_SpawnPoolWorker-1
hello 6,8832_SpawnPoolWorker-2
hello 7,4704_SpawnPoolWorker-3
number:: 6,8832_SpawnPoolWorker-2
number:: 7,4704_SpawnPoolWorker-3
hello 8,12776_SpawnPoolWorker-1
number:: 8,12776_SpawnPoolWorker-1
hello 9,4704_SpawnPoolWorker-3
number:: 9,4704_SpawnPoolWorker-3
callback是回调函数,就是在执行完Foo方法后会自动执行Bar函数,并且自动把Foo函数的返回值作为参数传入Bar函数.
多进程:
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 多进程.py
@time: 2020/3/3 16:19
@author:LDC
'''
import time
from concurrent import futures
from multiprocessing import current_process
def foo(i):
pid = current_process().pid
pname = current_process().name
time.sleep(3)
print('hello', '{},{}_{}'.format(i, pid, pname))
return '{},{}_{}'.format(i, pid, pname)
if __name__ == '__main__':
i_list = [1, 2, 3, 4, 5]
with futures.ProcessPoolExecutor(5) as executor:
res = executor.map(foo, i_list)
# to_do = [executor.submit(foo, item) for item in i_list]
# ret = [future.result() for future in futures.as_completed(to_do)]
注意:map可以保证输出的顺序, submit输出的顺序是乱的
如果你要提交的任务的函数是一样的,就可以简化成map。但是假如提交的任务函数是不一样的,或者执行的过程之可能出现异常(使用map执行过程中发现问题会直接抛出错误)就要用到submit()
submit和map的参数是不同的,submit每次都需要提交一个目标函数和对应的参数,map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
线程
方法:start 线程准备就绪,等待CPU调度
setName 设置线程名称
getName 获取线程名称
setDaemon 把一个主进程设置为Daemon线程后,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论有没执行完成,都会停止
join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
run 线程被cpu调度后自动执行线程对象的run方法# encoding: utf-8
'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 创建线程(常用).py
@time: 2020/3/3 16:49
@author:LDC
'''
import threading
import time
'''直接调用'''
def foo(name):
time.sleep(name)
# 获取当前线程名称与标志号
print(threading.currentThread().name, threading.currentThread().ident)
print("Hello %s" % name)
if __name__ == "__main__":
t_list = []
# 创建了两个线程
for i in range(2):
t = threading.Thread(target=foo, args=(i+2,), name='t_{}'.format(i)) # 生成线程实例
# t.setDaemon(True) # True表示子线程设置为守护线程,主线程死去,子线程也跟着死去,不管是否执行完
# t.setDaemon(False) # False表示子线程设置为非守护线程,主线程死去,子线程依然在执行
t_list.append(t)
t.start()
# 知道线程名,可以通过以下方式检验
threading_list = list(filter(lambda th: th.getName() == 't_1', threading.enumerate()))
if threading_list:
print('【t_1】这个线程还活着')
# for t in t_list:
# t.join() # 等待子线程执行完,
# print(t.getName()) # 获取线程名
多线程
# 可以使用for循环创建多个线程for i in range3):
t = threading.Thread(target=foo, args=(i+2,), name='t_{}'.format(i))
t.start()
线程池
为什么要使用线程池?
对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控,例如,整站爬虫,假设初始只有一个链接a,那么,这个时候只启动一个线程,运行之后,得到这个链接对应页面上的b,c,d,,,等等新的链接,作为新任务,这个时候,就要为这些新的链接生成新的线程,线程数量暴涨。在之后的运行中,线程数量还会不停的增加,完全无法控制。所以,对于任务数量不端增加的程序,固定线程数量的线程池是必要的。
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 线程池.py
@time: 2020/3/3 20:36
@author:LDC
'''
import time
from concurrent.futures import ThreadPoolExecutor
# 任务
def doSth(args):
print("hello", args)
# time.sleep(2)
if __name__ == '__main__':
# max_workers 线程数
argsList = (1, 2, 3, 4, 5, 6)
# 使用sumbit()函数提交任务
with ThreadPoolExecutor(5) as exe:
for a in argsList:
exe.submit(doSth, a)
# 使用map()函数提交任务
print("使用map()提交任务")
with ThreadPoolExecutor(5) as exe:
exe.map(doSth, argsList)
线程冲突
当多个线程同时访问同一个变量时就可能造成线程冲突
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 线程冲突.py
@time: 2020/3/3 20:57
@author:LDC
'''
import threading
money = 0
def add_money():
global money
for i in range(10000000):
money += 1
if __name__ == '__main__':
add_money()
add_money()
print('调用两次函数money实际值为:', money)
money = 0
t_list = []
for i in range(2):
t = threading.Thread(target=add_money)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('使用线程后money实际值为:', money)
输出:
调用两次函数money实际值为: 20000000使用线程后money实际值为: 11656269
原因:当对全局资源存在写操作时,如果不能保证写入过程的原子性,会出现脏读脏写的情况,即线程不安全。Python的GIL只能保证原子操作的线程安全,因此在多线程编程时我们需要通过加锁来保证线程安全。
最简单的锁是互斥锁(同步锁),互斥锁是用来解决IO密集型场景产生的计算错误,即目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
互斥锁
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 互斥锁.py
@time: 2020/3/3 21:08
@author:LDC
'''
import threading
lock = threading.Lock()
money = 0
def add_money():
global money
with lock:
for i in range(10000000):
money += 1
if __name__ == '__main__':
add_money()
add_money()
print('调用两次函数money实际值为:', money)
money = 0
t_list = []
for i in range(2):
t = threading.Thread(target=add_money)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('使用线程后money实际值为:', money)
锁适用于访问和修改同一个资源的时候,引起资源争用的情况下。
使用锁的注意事项:
1. 少用锁,除非有必要。多线程访问加锁的资源时,由于锁的存在,实际就变成了串行。2. 加锁时间越短越好,不需要就立即释放锁。
3. 一定要避免死锁,使用with或者try...finally。
第一种死锁:迭代死锁
该情况是一个线程“迭代”请求同一个资源,直接就会造成死锁。这种死锁产生的原因是我们标准互斥锁threading.Lock的缺点导致的。
标准的锁对象(threading.Lock)并不关心当前是哪个线程占有了该锁;如果该锁已经被占有了,那么任何其它尝试获取该锁的线程都会被阻塞,包括已经占有该锁的线程也会被阻塞。
比如:
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 迭代死锁.py
@time: 2020/3/3 22:10
@author:LDC
'''
import threading
import time
count_list = [0, 0]
lock = threading.Lock()
def change_0():
global count_list
with lock:
tmp = count_list[0]
time.sleep(0.001)
count_list[0] = tmp + 1
time.sleep(2)
print("Done. count_list[0]:%s" % count_list[0])
def change_1():
global count_list
with lock:
tmp = count_list[1]
time.sleep(0.001)
count_list[1] = tmp + 1
time.sleep(2)
print("Done. count_list[1]:%s" % count_list[1])
def change():
with lock:
change_0()
time.sleep(0.001)
change_1()
def verify(sub):
global count_list
thread_list = []
for i in range(5):
t = threading.Thread(target=sub, args=())
t.start()
thread_list.append(t)
for j in thread_list:
j.join()
print(count_list)
if __name__ == "__main__":
verify(change)
示例中,我们有一个共享资源count_list,有两个分别取这个共享资源第一部分和第二部分的数字(count_list[0]和count_list[1])。两个访问函数都使用了锁来确保在获取数据时没有其它线程修改对应的共享数据。
现在,如果我们思考如何添加第三个函数来获取两个部分的数据。一个简单的方法是依次调用这两个函数,然后返回结合的结果。
这里的问题是,如有某个线程在两个函数调用之间修改了共享资源,那么我们最终会得到不一致的数据。
最明显的解决方法是在这个函数中也使用lock。然而,这是不可行的。里面的两个访问函数将会阻塞,因为外层语句已经占有了该锁。
结果是没有任何输出,死锁。
为了解决这个问题,我们可以用递归锁代替互斥锁。
递归锁
就是在一个大锁中再包含子锁。它相当于一个字典,记录了锁的门与锁的对应值,当开门的时候会根据对应钥匙来开锁。
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 迭代死锁.py
@time: 2020/3/3 22:10
@author:LDC
'''
import threading
import time
count_list = [0, 0]
lock = threading.RLock() # 递归锁
def change_0():
global count_list
with lock: # 小锁
tmp = count_list[0]
time.sleep(0.001)
count_list[0] = tmp + 1
time.sleep(2)
print("Done. count_list[0]:%s" % count_list[0])
def change_1():
global count_list
with lock: # 小锁
tmp = count_list[1]
time.sleep(0.001)
count_list[1] = tmp + 1
time.sleep(2)
print("Done. count_list[1]:%s" % count_list[1])
def change():
with lock: # 大锁
change_0()
time.sleep(0.001)
change_1()
def verify(sub):
global count_list
thread_list = []
for i in range(5):
t = threading.Thread(target=sub, args=())
t.start()
thread_list.append(t)
for j in thread_list:
j.join()
print(count_list)
if __name__ == "__main__":
verify(change)
第二种死锁:互相等待死锁
死锁的另外一个原因是两个进程想要获得的锁已经被对方进程获得,只能互相等待又无法释放已经获得的锁,而导致死锁。假设银行系统中,用户a试图转账100块给用户b,与此同时用户b试图转账500块给用户a,则可能产生死锁。
2个线程互相等待对方的锁,互相占用着资源不释放。
下面是一个互相调用导致死锁的例子:
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 互相等待死锁.py
@time: 2020/3/3 22:29
@author:LDC
'''
import threading
import time
class Account(object):
def __init__(self, name, balance, lock):
self.name = name
self.balance = balance
self.lock = lock
def withdraw(self, amount):
# 转账
self.balance -= amount
def deposit(self, amount):
# 存款
self.balance += amount
def transfer(from_account, to_account, amount):
# 转账操作
with from_account.lock:
from_account.withdraw(amount)
time.sleep(1)
print("trying to get %s's lock..." % to_account.name)
with to_account.lock:
to_account.deposit(amount)
print("transfer finish")
if __name__ == "__main__":
a = Account('a', 1000, threading.RLock())
b = Account('b', 1000, threading.RLock())
thread_list = []
thread_list.append(threading.Thread(target=transfer, args=(a, b, 100)))
thread_list.append(threading.Thread(target=transfer, args=(b, a, 500)))
for i in thread_list:
i.start()
for j in thread_list:
j.join()
最终结果是死锁:
trying to get account a's lock...trying to get account b's lock...
即我们的问题是:
你正在写一个多线程程序,其中线程需要一次获取多个锁,此时如何避免死锁问题。
解决方案:
在多线程程序中,死锁问题很大一部分是由于线程同时获取多个锁造成的。
举个例子:一个线程获取了第一个锁,然后在获取第二个锁的时候发生阻塞,那么这个线程就可能阻塞其他线程的执行,从而导致整个程序假死。
其实解决这个问题,核心思想是:目前我们遇到的问题是两个线程想获取到的锁,都被对方线程拿到了,那么我们只需要保证在这两个线程中,获取锁的顺序保持一致就可以了。举个例子,我们有线程thread_a, thread_b, 锁lock_1, lock_2。只要我们规定好了锁的使用顺序,比如先用lock_1,再用lock_2,当线程thread_a获得lock_1时,其他线程如thread_b就无法获得lock_1这个锁,也就无法进行下一步操作(获得lock_2这个锁),也就不会互相等待导致的死锁。
简言之,解决死锁问题的一种方案是为程序中的每一个锁分配一个唯一的id,然后只允许按照升序规则来使用多个锁,这个规则使用上下文管理器 是非常容易实现的,
升序锁
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 升序锁.py
@time: 2020/3/3 22:39
@author:LDC
'''
import threading
import time
from contextlib import contextmanager
thread_local = threading.local()
def acquire(*locks):
# sort locks by object identifier
# 根据对象标识符对锁进行排序
locks = sorted(locks, key=lambda x: id(x))
# make sure lock order of previously acquired locks is not violated
# 确保没有违反先前获取的锁的顺序
acquired = getattr(thread_local, 'acquired', [])
if acquired and (max(id(lock) for lock in acquired) >= id(locks[0])):
raise RuntimeError('Lock Order Violation')
# Acquire all the locks
# 获取所有锁
acquired.extend(locks)
thread_local.acquired = acquired
try:
for lock in locks:
lock.acquire()
yield
finally:
for lock in reversed(locks):
lock.release()
del acquired[-len(locks):]
class Account(object):
def __init__(self, name, balance, lock):
self.name = name
self.balance = balance
self.lock = lock
def withdraw(self, amount):
self.balance -= amount
def deposit(self, amount):
self.balance += amount
def transfer(from_account, to_account, amount):
print("%s transfer..." % amount)
with acquire(from_account.lock, to_account.lock):
from_account.withdraw(amount)
time.sleep(1)
to_account.deposit(amount)
print("%s transfer... %s:%s ,%s: %s" % (
amount, from_account.name, from_account.balance, to_account.name, to_account.balance))
print("transfer finish")
if __name__ == "__main__":
a = Account('a', 1000, threading.Lock())
b = Account('b', 1000, threading.Lock())
thread_list = []
thread_list.append(threading.Thread(target=transfer, args=(a, b, 100)))
thread_list.append(threading.Thread(target=transfer, args=(b, a, 500)))
for i in thread_list:
i.start()
for j in thread_list:
j.join()
运行结果:
transfer...transfer...
transfer... a:900 ,b:1100
transfer finish
transfer... b:600, a:1400
transfer finish
成功的避免了互相等待导致的死锁问题。
在上述代码中,有几点语法需要解释:
线程同步(Event)
线程之间经常需要协同工作,通过某种技术,让一个线程访问某些数据时,其它线程不能访问这些数据,直到该线程完成对数据的操作。这些技术包括临界区(Critical Section),互斥量(Mutex),信号量(Semaphore),事件Event等。
互斥锁、递归锁、升序锁是实现线程同步的一个方法,其它的还有semaphore 信号量机制,event 事件机制。
semaphore 信号量机制在python 里面也很简单就能够实现线程的同步。
如果对操作系统有一定的了解, 那么对操作系统的PV原语操作应该有印象, 信号量其实就是基于这个机制的.
semaphore 类是threading 模块下的一个类, 主要两个函数: acquire 函数, release 函数这和lock 类的函数是一样的, 只不过功能不一样, semaphore 机制的acquire 函数的参数允许你自己设置最大的并发量, 就是说允许多少个线程来操作同一个函数或是变量, 同时执行一次就会递减一次, release 函数则是递增, 如果计数到了0, 则阻塞起线程, 不再允许线程访问该方法或是变量.
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 信号量实现线程同步.py
@time: 2020/3/4 22:30
@author:LDC
'''
# python 多线程同步 semaphore
import threading
import time
# 初始化信号量数量...当调用acquire 将数量置为 0, 将阻塞线程等待其他线程调用release() 函数
semaphore = threading.Semaphore(2)
def func():
if semaphore.acquire():
for i in range(2):
print(threading.currentThread().getName() + ' get semaphore')
time.sleep(1)
semaphore.release()
print(threading.currentThread().getName() + ' release semaphore')
if __name__ == '__main__':
for i in range(4):
t1 = threading.Thread(target=func)
t1.start()
输出
Thread-1 get semaphoreThread-2 get semaphore
Thread-1 get semaphore
Thread-2 get semaphore
Thread-1 release semaphore
Thread-3 get semaphore
Thread-2 release semaphore
Thread-4 get semaphore
Thread-3 get semaphore
Thread-4 get semaphore
Thread-3 release semaphore
Thread-4 release semaphore
可以看到主体函数一次只允许两个线程访问。
event 机制不仅能够实现线程间的通信, 也是实现线程同步的一个好方法。
事件是线程之间通信的最简单的机制之一, 一个线程指示一个事件和其他线程等待它.
event.py 是threading 模块下的一个类,
相比较前面两个机制, 这个类提供了四个方法, 分别是:
is_set() 函数, set() 函数, clear() 函数, wait() 函数. threading库中的event对象通过使用内部一个flag标记,通过flag的True或者False的变化来进行操作。
名称
含义
set( )
标记设置为True
clear( )
标记设置为False
is_set( )
标记是否为True
wait(timeout=None)
设置等待标记为True的时长,None为无限等待。等到返回True,等不到返回False
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: 事件机制实现线程同步.py
@time: 2020/3/4 22:46
@author:LDC
'''
import logging
import threading
import time
# 打印线程名以及日志信息
logging.basicConfig(level=logging.DEBUG, format="(%(threadName)-10s : %(message)s", )
def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
while not e.isSet():
logging.debug("wait_for_event_timeout starting")
event_is_set = e.wait(t) # 阻塞, 等待设置为true
logging.debug("event set: %s" % event_is_set)
if event_is_set:
logging.debug("processing event")
else:
logging.debug("doing other work")
e = threading.Event() # 初始化为false
t2 = threading.Thread(name="nonblock", target=wait_for_event_timeout, args=(e, 2))
t2.start()
logging.debug("Waiting before calling Event.set()")
# time.sleep(7)
e.set() # 唤醒线程, 同时将event 设置为true
logging.debug("Event is set")
输出:

协程
协程,是单线程下的并发,又称微线程,英文名Coroutine。是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置,当程序中存在大量不需要CPU的操作时(IO),适用于协程。【在一个线程中CPU来回切换执行不同的任务,这种现象就是协程】
协程有极高的执行效率,因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销。
不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,所以想要利用多核CPU,最简单的方法是多进程+协程,这样既充分利用多核,又充分发挥协程的高效率。
那符合什么条件就能称之为协程:
1、必须在只有一个单线程里实现并发
2、修改共享数据不需加锁
3、用户程序里自己保存多个控制流的上下文栈
4、一个协程遇到IO操作自动切换到其它协程
python中对于协程有四个模块,greenlet、gevent、yield和async来实现切换+保存线程
通过yield来实现任务切换+保存线程
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: yield_test.py
@time: 2020/3/5 15:39
@author:LDC
'''
import time
def func1():
while True:
print('func1')
yield '返回func1'
def func2():
g = func1()
print(next(g))
for i in range(3):
print(next(g))
time.sleep(3)
print('func2')
if __name__ == '__main__':
start = time.time()
func2()
stop = time.time()
print(stop - start)
yield不能节省IO时间,只是单纯的进行程序切换
# 基于yield并发执行,多任务之间来回切换,这就是个简单的协程的体现,但是他能够节省I/O时间吗?不能import time
def consumer():
'''任务1:接收数据,处理数据'''
while True:
x = yield
time.sleep(1) # 发现什么?只是进行了切换,但是并没有节省I/O时间
print('处理了数据:', x)
def producer():
'''任务2:生产数据'''
g = consumer()
next(g) # 找到了consumer函数的yield位置
for i in range(3):
g.send(i) # 给yield传值,然后再循环给下一个yield传值,并且多了切换的程序,比直接串行执行还多了一些步骤,导致执行效率反而更低了。
print('发送了数据:', i)
if __name__ == '__main__':
start = time.time()
# 基于yield保存状态,实现两个任务直接来回切换,即并发的效果
# PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.
producer() # 我在当前线程中只执行了这个函数,但是通过这个函数里面的send切换了另外一个任务
stop = time.time()
print(stop - start)
# 串行执行的方式
# start = time.time()
# res = producer()
# consumer()
# stop = time.time()
# print(stop - start)
yield检测不到IO,无法实现遇到IO自动切换。
greenlet是手动切换
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: greenlet创建协程.py
@time: 2020/3/4 23:08
@author:LDC
'''
'''
使用greenlet + switch实现协程调度
'''
from greenlet import greenlet
import time
def func1():
print("开门走进卫生间")
time.sleep(3)
gr2.switch() # 把CPU执行权交给gr2
print("飞流直下三千尺")
time.sleep(3)
gr2.switch()
pass
def func2():
print("一看拖把放旁边")
time.sleep(3)
gr1.switch()
print("疑是银河落九天")
pass
if __name__ == '__main__':
gr1 = greenlet(func1)
gr2 = greenlet(func2)
gr1.switch() # 把CPU执行权先给gr1
pass
greenlet只是提供了一种比yield(生成器)更加便捷的切换方式,当切到一个任务执行时如果遇到IO,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
Gevent实现自动切换协程(多协程)
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。
一般在工作中我们都是进程+线程+协程的方式来实现并发,以达到最好的并发效果。
如果是4核的CPU,一般起5个进程,每个进程中20个线程(5倍CPU数量),每个线程可以起500个协程,大规模爬取页面的时候,等待网络延迟的时间的时候,我们就可以用协程去实现并发。并发数量=520500从而达到5000个并发,这是一般一个4个CPU的机器最大的并发数。nginx在负载均衡的时候最大承载量是5w个。
单线程里的这20个任务的代码通常既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。如此,才能提高效率,这就用到了Gevent模块。
Gevent(自动切换,由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成)。
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: monkey_patch.py
@time: 2020/3/4 23:40
@author:LDC
'''
'''
使用gevent + monkey.patch_all()自动调度网络IO协程
'''
from gevent import monkey;
monkey.patch_all() # 将【标准库-阻塞IO实现】替换为【gevent-非阻塞IO实现,即遇到需要等待的IO会自动切换到其它协程
import sys
import gevent
import requests
import time
sys.setrecursionlimit(1000000) # 增加递归深度
def get_page_text(url, order):
print('No{}请求'.format(order))
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
}
resp = requests.get(url, headers=headers) # 发起网络请求,返回需要时间——阻塞IO
html = resp.text
html_len = len(html)
print("%s成功返回:长度为%d" % (url, html_len))
return html_len
except Exception as e:
print('{}发生错误,{}'.format(url, e))
return 0
def gevent_joinall():
# spawn是异步提交任务
gevent.joinall([
gevent.spawn(get_page_text, "http://www.sina.com", order=1),
gevent.spawn(get_page_text, "http://www.qq.com", order=2),
gevent.spawn(get_page_text, "http://www.baidu.com", order=3),
gevent.spawn(get_page_text, "http://www.163.com", order=4),
gevent.spawn(get_page_text, "http://www.4399.com", order=5),
gevent.spawn(get_page_text, "http://www.sohu.com", order=6),
gevent.spawn(get_page_text, "http://www.youku.com", order=7),
])
g_iqiyi = gevent.spawn(get_page_text, "http://www.iqiyi.com", order=8)
g_iqiyi.join()
# #拿到任务的返回值
print('获取返回值', g_iqiyi.value)
if __name__ == '__main__':
#
start = time.time()
time.clock()
gevent_joinall()
end = time.time()
print("over,耗时%d秒" % (end - start))
print(time.clock())
monkey.patch_all() 一定要放到导入requests模块之前,否则gevent无法识别requests的阻塞。
async实现协程
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: async创建协程.py
@time: 2020/3/6 12:03
@author:LDC
'''
import asyncio
from functools import partial
'''
使用gevent + monkey.patch_all()自动调度网络IO协程
'''
import sys
import requests
import time
sys.setrecursionlimit(1000000) # 增加递归深度
async def get_page_text(url, order):
# 使用async创建一个可中断的异步函数
print('No{}请求'.format(order))
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
}
# 利用BaseEventLoop.run_in_executor()可以在coroutine中执行第三方的命令,例如requests.get()
# 第三方命令的参数与关键字利用functools.partial传入
future = asyncio.get_event_loop().run_in_executor(None, partial(requests.get, url, headers=headers))
resp = await future
html = resp.text
html_len = len(html)
print("%s成功返回:长度为%d" % (url, html_len))
return html_len
except Exception as e:
print('{}发生错误,{}'.format(url, e))
return 0
# 异步函数执行完后回调函数
def callback(future): # 这里默认传入一个future对象
print(future.result())
# 异步函数执行完后回调函数,可接收多个参数
def callback_2(url, future): # 传入值的时候,future必须在最后一个
print(url, future.result())
def async_run():
# 使用async创建协程
urls = ["http://www.youku.com", "http://www.sina.com", "http://www.qq.com", "http://www.baidu.com",
"http://www.163.com", "http://www.4399.com", "http://www.sohu.com",
]
loop_task = []
loop = asyncio.get_event_loop()
for i in range(len(urls)):
t = asyncio.ensure_future(get_page_text(urls[i], i + 1))
# t = loop.create_task(task(urls[i], i + 1))
t.add_done_callback(callback)
# t.add_done_callback(partial(callback_2, urls[i]))
loop_task.append(t)
print('等待所有async函数执行完成')
start = time.time()
loop.run_until_complete(asyncio.wait(loop_task))
loop.close()
end = time.time()
print("over,耗时%d秒" % (end - start))
if __name__ == '__main__':
async_run()
3、关键字:yield
3.1 yield表达式
yield相当于return,只不过return是终结函数并返回一个值,而yield是先把值返回并把函数挂起来,以后还会执行yield以下的语句。
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: yield_test.py
@time: 2020/3/5 15:39
@author:LDC
'''
def foo(end_count):
print('yield生成器')
count = 0
while count < end_count:
res = yield count
print('接收到的参数', res)
if res is not None:
count = res
else:
count += 1
if __name__ == '__main__':
f = foo(7)
# 第一次调用yield函数是预激活,
# 即调用函数foo时,只执行yield前面的语句,
# 遇到yield就把foo函数挂起来,
# 并返回yield后面附带的值
print(next(f)) # 使用next()调用yield函数
for i in range(3):
# 第二次调用就开始执行yield后面的语句
print(next(f)) # 使用next()调用yield函数
print('*' * 20)
# s使用send给foo函数传值,yield会接收到并赋给res,
print(f.send(5)) # send函数中会执行一次next函数
print(next(f))
# 生成不占空间的列表[0,1,2,3,4,5,6,7,8,9]
# for i in foo(10):
# print(i)
输出:
yield生成器0
接收到的参数 None
1
接收到的参数 None
2
接收到的参数 None
3
********************
接收到的参数 5
5
接收到的参数 None
6
1、第一次ti调用next函数时,进入foo函数,遇到yield就把count=0返回,并把foo函数挂起
2、在for循环中再次调用next函数时,就开始执行yield后面的赋值语句,由于没有接收到值就默认为None,所以res=None
3、然后接着执行赋值语句后面的打印语句和if判断,由于res为None所以执行count +=1,此时count值为1
4、再次遇到yield,返回1,并把foo函数挂起。
5、send函数是可以给yield生成器传参的,执行send函数时会默认执行一次next函数,原理同上。
到这里你可能就明白yield和return的关系和区别了,带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
为什么用这个生成器,是因为如果用List的话,会占用更大的空间,比如说取0,1,2,3,4,5,6…1000
你可能会这样:
for i in range(1000):print(i)
这个时候range(1000)就默认生成一个含有1000个数的list了,所以很占内存。
这个时候你可以用刚才的yield组合成生成器进行实现
for i in foo(10000):print(i)
但这个由于每次都要调用函数foo,所以比较耗时间。【这就是用时间换空间】
4、关键字:async/await
asyncio 是用来编写 并发 代码的库,使用 async/await 语法。
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建 IO 密集型和高层级 结构化 网络代码的最佳选择。
正常的函数在执行时是不会中断的,所以你要写一个能够中断的函数,就需要添加async关键。
async 用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是asyncio.sleep(5))消失后,也就是5秒到了再回来执行。
await 用来用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序。await 后面只能跟异步程序或有await属性的对象,因为异步程序与一般程序不同。假设有两个异步函数async a,async b,a中的某一步有await,当程序碰到关键字await b()后,异步程序挂起后去执行另一个异步b程序,就是从函数内部跳出去执行其他函数,当挂起条件消失后,不管b是否执行完,要马上从b程序中跳出来,回到原程序执行原来的操作。如果await后面跟的b函数不是异步函数,那么操作就只能等b执行完再返回,无法在b执行的过程中返回。如果要在b执行完才返回,也就不需要用await关键字了,直接调用b函数就行。所以这就需要await后面跟的是异步函数了。在一个异步函数中,可以不止一次挂起,也就是可以用多个await。
可以使用async、await来实现协程的并发,下面以一个爬虫例子来说明:
# encoding: utf-8'''
@contact: 1257309054@qq.com
@wechat: 1257309054
@Software: PyCharm
@file: async_await.py
@time: 2020/3/5 23:15
@author:LDC
'''
from gevent import monkey;
monkey.patch_all()
import gevent
import asyncio
from functools import wraps, partial
import time
import requests
# 定义一个查看函数执行时间的装饰器
def func_use_time(func):
(func)
def inside(*arg, **kwargs):
start = time.clock()
res = func(*arg, **kwargs)
print('***************执行时间*****************', time.clock() - start)
return res
return inside
def get_page_text(url):
# 爬取网站
print(url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
}
resp = requests.get(url, headers=headers) # 发起网络请求,返回需要时间——阻塞IO
html = resp.text
return html
except Exception as e:
print('{}发生错误,{}'.format(url, e))
return ''
class Narmal():
# 正常爬取
def __init__(self, urls):
self.urls = urls
self.res_dict = {}
def run(self):
for url in self.urls:
res = get_page_text(url)
self.res_dict[url] = len(res)
print('串行获取结果', self.res_dict)
class UseAsyncio():
# 使用async实现协程并发
def __init__(self, urls):
self.urls = urls
self.res_dict = {}
# 定义一个异步函数,执行爬取任务
async def task(self, url):
print(url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
}
# 利用BaseEventLoop.run_in_executor()可以在coroutine中执行第三方的命令,例如requests.get()
# 第三方命令的参数与关键字利用functools.partial传入
future = asyncio.get_event_loop().run_in_executor(None, partial(requests.get, url, headers=headers))
resp = await future
html = resp.text
self.res_dict[url] = len(html)
return html
except Exception as e:
print('{}发生错误,{}'.format(url, e))
return ''
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.task(url)) for url in self.urls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
# 获取async结果
# for task in tasks:
# print(task.result())
print('async获取结果', self.res_dict)
class UseGevent():
# 使用Gevent实现协程并发
def __init__(self, urls):
self.urls = urls
self.res_dict = {}
def task(self, url):
res = get_page_text(url)
self.res_dict[url] = len(res)
def run(self):
gevent.joinall([gevent.spawn(self.task, url) for url in self.urls])
print(self.res_dict)
if __name__ == '__main__':
urls = ["http://www.sina.com", "http://www.qq.com", "http://www.baidu.com",
"http://www.163.com", "http://www.4399.com", "http://www.sohu.com",
"http://www.youku.com",
]
print("使用正常爬取方式,即串行")
Narmal(urls).run()
print("使用Asyncio爬取方式,async实现协程并发")
UseAsyncio(urls).run()
print("使用Gevent爬取方式,实现协程并发")
UseGevent(urls).run()
输出:
使用正常爬取方式,即串行http://www.sina.com
http://www.qq.com
http://www.baidu.com
http://www.163.com
http://www.4399.com
http://www.sohu.com
http://www.youku.com
串行获取结果 {'http://www.sina.com': 539723, 'http://www.qq.com': 227753, 'http://www.baidu.com': 166916, 'http://www.163.com': 483531, 'http://www.4399.com': 172837, 'http://www.sohu.com': 178312, 'http://www.youku.com': 990760}
***************执行时间***************** 1.9352532
使用Asyncio爬取方式,async实现协程并发
http://www.sina.com
http://www.qq.com
http://www.baidu.com
http://www.163.com
http://www.4399.com
http://www.sohu.com
http://www.youku.com
async获取结果 {'http://www.4399.com': 172837, 'http://www.163.com': 483531, 'http://www.qq.com': 227753, 'http://www.sohu.com': 178310, 'http://www.baidu.com': 166625, 'http://www.sina.com': 539723, 'http://www.youku.com': 1047892}
***************执行时间***************** 0.951011
使用Gevent爬取方式,实现协程并发
http://www.sina.com
http://www.qq.com
http://www.baidu.com
http://www.163.com
http://www.4399.com
http://www.sohu.com
http://www.youku.com
{'http://www.163.com': 483531, 'http://www.4399.com': 172837, 'http://www.sohu.com': 178312, 'http://www.qq.com': 227753, 'http://www.baidu.com': 166760, 'http://www.sina.com': 539723, 'http://www.youku.com': 994926}
***************执行时间***************** 1.0057508
相对来说还是使用async执行效率高些。
后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号

关注我,我们一起成长~~
【https://docs.python.org/zh-cn/3/library/asyncio.html】