本站所有数据均由作者定制的爬虫程序采集于互联网(类似于搜索引擎的爬虫),所有数据均为网站公开的非隐私数据,任何人均可看到。 本作者没有采用任何非法手段(例如黑客技术
- 本站所有数据均由作者定制的爬虫程序采集于互联网(类似于搜索引擎的爬虫),所有数据均为网站公开的非隐私数据,任何人均可看到。
- 本作者没有采用任何非法手段(例如黑客技术)盗取网站的非公开数据。
- 如果您觉得作者侵犯了您的合法权益,请联系作者予以处理
微博搜索采集
微博对比其他大站点反爬策略相对比较宽松,不像其他站点么苛刻。所以只要控制好访问频率,不对目标服务产生压力小规模采集点数据做下分析还是比较不错的;
博主采集了微博上2021-10-01 – 2021-12-28#剧本杀#话题的相关数据,共6210条数据,3441个用户。
部分代码展示
完整版请私信联系博主
def parse_weibo(self, response):"""解析网页中的微博信息"""
keyword = response.meta.get('keyword')
for sel in response.xpath("//div[@class='card-wrap']"):
info = sel.xpath(
"div[@class='card']/div[@class='card-feed']/div[@class='content']/div[@class='info']"
)
if info:
weibo = WeiboItem()
weibo['id'] = sel.xpath('@mid').extract_first()
weibo['bid'] = sel.xpath(
'(.//p[@class="from"])[last()]/a[1]/@href').extract_first(
).split('/')[-1].split('?')[0]
weibo['user_id'] = info[0].xpath(
'div[2]/a/@href').extract_first().split('?')[0].split(
'/')[-1]
weibo['screen_name'] = info[0].xpath(
'div[2]/a/@nick-name').extract_first()
txt_sel = sel.xpath('.//p[@class="txt"]')[0]
retweet_sel = sel.xpath('.//div[@class="card-comment"]')
retweet_txt_sel = ''
if retweet_sel and retweet_sel[0].xpath('.//p[@class="txt"]'):
retweet_txt_sel = retweet_sel[0].xpath(
'.//p[@class="txt"]')[0]
content_full = sel.xpath(
'.//p[@node-type="feed_list_content_full"]')
is_long_weibo = False
is_long_retweet = False
if content_full:
if not retweet_sel:
txt_sel = content_full[0]
is_long_weibo = True
elif len(content_full) == 2:
txt_sel = content_full[0]
retweet_txt_sel = content_full[1]
is_long_weibo = True
is_long_retweet = True
elif retweet_sel[0].xpath(
'.//p[@node-type="feed_list_content_full"]'):
retweet_txt_sel = retweet_sel[0].xpath(
'.//p[@node-type="feed_list_content_full"]')[0]
is_long_retweet = True
else:
txt_sel = content_full[0]
is_long_weibo = True
weibo['text'] = txt_sel.xpath(
'string(.)').extract_first().replace('\u200b', '').replace(
'\ue627', '')
weibo['article_url'] = self.get_article_url(txt_sel)
weibo['location'] = self.get_location(txt_sel)
if weibo['location']:
weibo['text'] = weibo['text'].replace(
'2' + weibo['location'], '')
weibo['text'] = weibo['text'][2:].replace(' ', '')
if is_long_weibo:
weibo['text'] = weibo['text'][:-6]
weibo['at_users'] = self.get_at_users(txt_sel)
weibo['topics'] = self.get_topics(txt_sel)
reposts_count = sel.xpath(
'.//a[@action-type="feed_list_forward"]/text()').extract()
reposts_count = "".join(reposts_count)
try:
reposts_count = re.findall(r'\d+.*', reposts_count)
except TypeError:
print(
"无法解析转发按钮,可能是 1) 网页布局有改动 2) cookie无效或已过期。\n"
"请在 https://github.com/dataabc/weibo-search 查看文档,以解决问题,"
)
raise CloseSpider()
weibo['reposts_count'] = reposts_count[
0] if reposts_count else '0'
comments_count = sel.xpath(
'.//a[@action-type="feed_list_comment"]/text()'
).extract_first()
comments_count = re.findall(r'\d+.*', comments_count)
weibo['comments_count'] = comments_count[
0] if comments_count else '0'
attitudes_count = sel.xpath(
'.//span[@class="woo-like-count"]/text()').extract_first()
if attitudes_count:
attitudes_count = re.findall(r'\d+.*', attitudes_count)
else:
attitudes_count = '0'
weibo['attitudes_count'] = attitudes_count[
0] if attitudes_count else '0'
created_at = sel.xpath(
'(.//p[@class="from"])[last()]/a[1]/text()').extract_first(
).replace(' ', '').replace('\n', '').split('前')[0]
weibo['created_at'] = util.standardize_date(created_at)
source = sel.xpath('(.//p[@class="from"])[last()]/a[2]/text()'
).extract_first()
weibo['source'] = source if source else ''
pics = ''
is_exist_pic = sel.xpath(
'.//div[@class="media media-piclist"]')
if is_exist_pic:
pics = is_exist_pic[0].xpath('ul[1]/li/img/@src').extract()
pics = [pic[8:] for pic in pics]
pics = [
re.sub(r'/.*?/', '/large/', pic, 1) for pic in pics
]
pics = ['https://' + pic for pic in pics]
video_url = ''
is_exist_video = sel.xpath(
'.//div[@class="thumbnail"]/a/@action-data')
if is_exist_video:
video_url = is_exist_video.extract_first()
video_url = unquote(
str(video_url)).split('video_src=//')[-1]
video_url = 'http://' + video_url
if not retweet_sel:
weibo['pics'] = pics
weibo['video_url'] = video_url
else:
weibo['pics'] = ''
weibo['video_url'] = ''
weibo['retweet_id'] = ''
if retweet_sel and retweet_sel[0].xpath(
'.//div[@node-type="feed_list_forwardContent"]/a[1]'):
retweet = WeiboItem()
retweet['id'] = retweet_sel[0].xpath(
'.//a[@action-type="feed_list_like"]/@action-data'
).extract_first()[4:]
retweet['bid'] = retweet_sel[0].xpath(
'.//p[@class="from"]/a/@href').extract_first().split(
'/')[-1].split('?')[0]
info = retweet_sel[0].xpath(
'.//div[@node-type="feed_list_forwardContent"]/a[1]'
)[0]
retweet['user_id'] = info.xpath(
'@href').extract_first().split('/')[-1]
retweet['screen_name'] = info.xpath(
'@nick-name').extract_first()
retweet['text'] = retweet_txt_sel.xpath(
'string(.)').extract_first().replace('\u200b',
'').replace(
'\ue627', '')
retweet['article_url'] = self.get_article_url(
retweet_txt_sel)
retweet['location'] = self.get_location(retweet_txt_sel)
if retweet['location']:
retweet['text'] = retweet['text'].replace(
'2' + retweet['location'], '')
retweet['text'] = retweet['text'][2:].replace(' ', '')
if is_long_retweet:
retweet['text'] = retweet['text'][:-6]
retweet['at_users'] = self.get_at_users(retweet_txt_sel)
retweet['topics'] = self.get_topics(retweet_txt_sel)
reposts_count = retweet_sel[0].xpath(
'.//ul[@class="act s-fr"]/li/a[1]/text()'
).extract_first()
reposts_count = re.findall(r'\d+.*', reposts_count)
retweet['reposts_count'] = reposts_count[
0] if reposts_count else '0'
comments_count = retweet_sel[0].xpath(
'.//ul[@class="act s-fr"]/li[2]/a[1]/text()'
).extract_first()
comments_count = re.findall(r'\d+.*', comments_count)
retweet['comments_count'] = comments_count[
0] if comments_count else '0'
attitudes_count = retweet_sel[0].xpath(
'.//a[@action-type="feed_list_like"]/em/text()'
).extract_first()
if attitudes_count:
attitudes_count = re.findall(r'\d+.*', attitudes_count)
else:
attitudes_count = '0'
retweet['attitudes_count'] = attitudes_count[
0] if attitudes_count else '0'
created_at = retweet_sel[0].xpath(
'.//p[@class="from"]/a[1]/text()').extract_first(
).replace(' ', '').replace('\n', '').split('前')[0]
retweet['created_at'] = util.standardize_date(created_at)
source = retweet_sel[0].xpath(
'.//p[@class="from"]/a[2]/text()').extract_first()
retweet['source'] = source if source else ''
retweet['pics'] = pics
retweet['video_url'] = video_url
retweet['retweet_id'] = ''
yield {'weibo': retweet, 'keyword': keyword}
weibo['retweet_id'] = retweet['id']
print(weibo)
yield {'weibo': weibo, 'keyword': keyword}
采集数据展示
数据分析报表
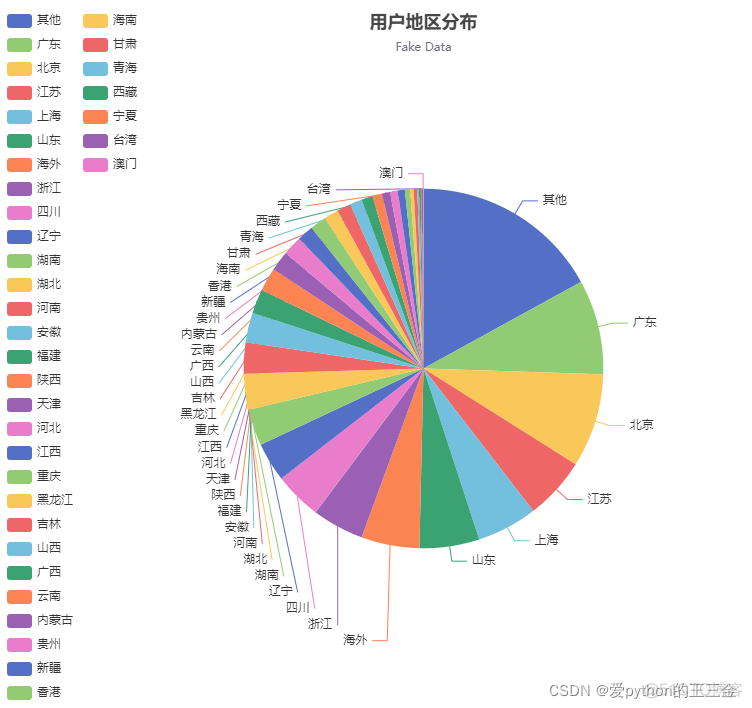
用户地区分布
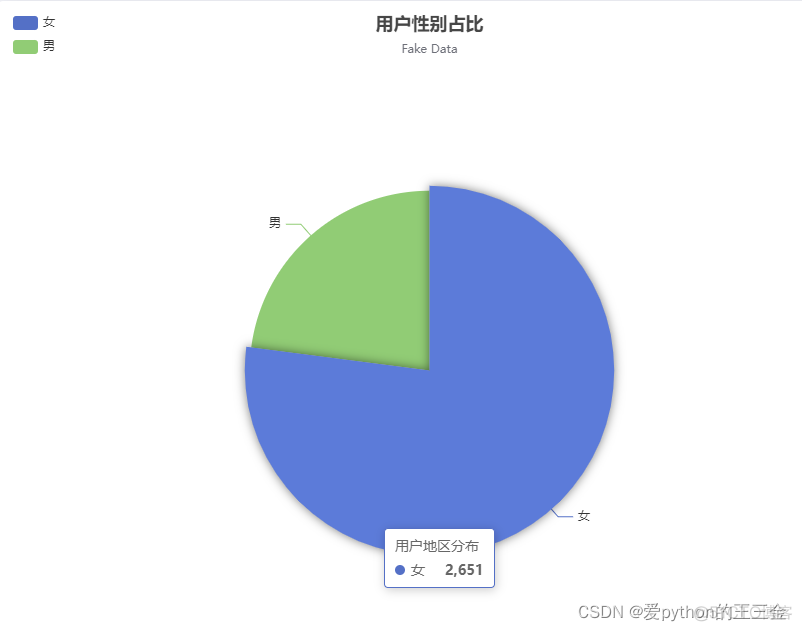
用户性别占比
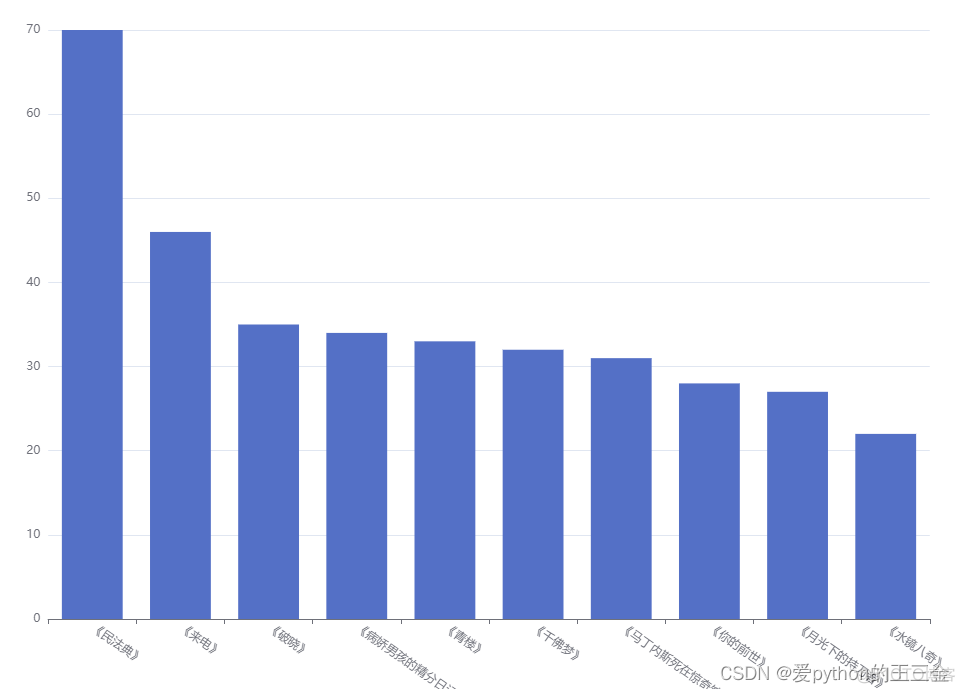
热点剧本排行
用户微博简介词云

微博文章词云
