最近和同事和朋友斗图斗得厉害,心想哪里来的这么多表情包,于是乎想着去表情包网站爬一波图片下来,便有了今天这篇文章。 -----难度指数 ✩ ----- 阅读 本文 大概需要12分 爬虫案例
最近和同事和朋友斗图斗得厉害,心想哪里来的这么多表情包,于是乎想着去表情包网站爬一波图片下来,便有了今天这篇文章。
-----难度指数 ✩
-----阅读本文大概需要12分
爬虫案例100篇栏目的第一篇
由于app爬虫网上的例子较少,今后的爬虫以手机包为主。
选择表情包软件
超热门表情包app
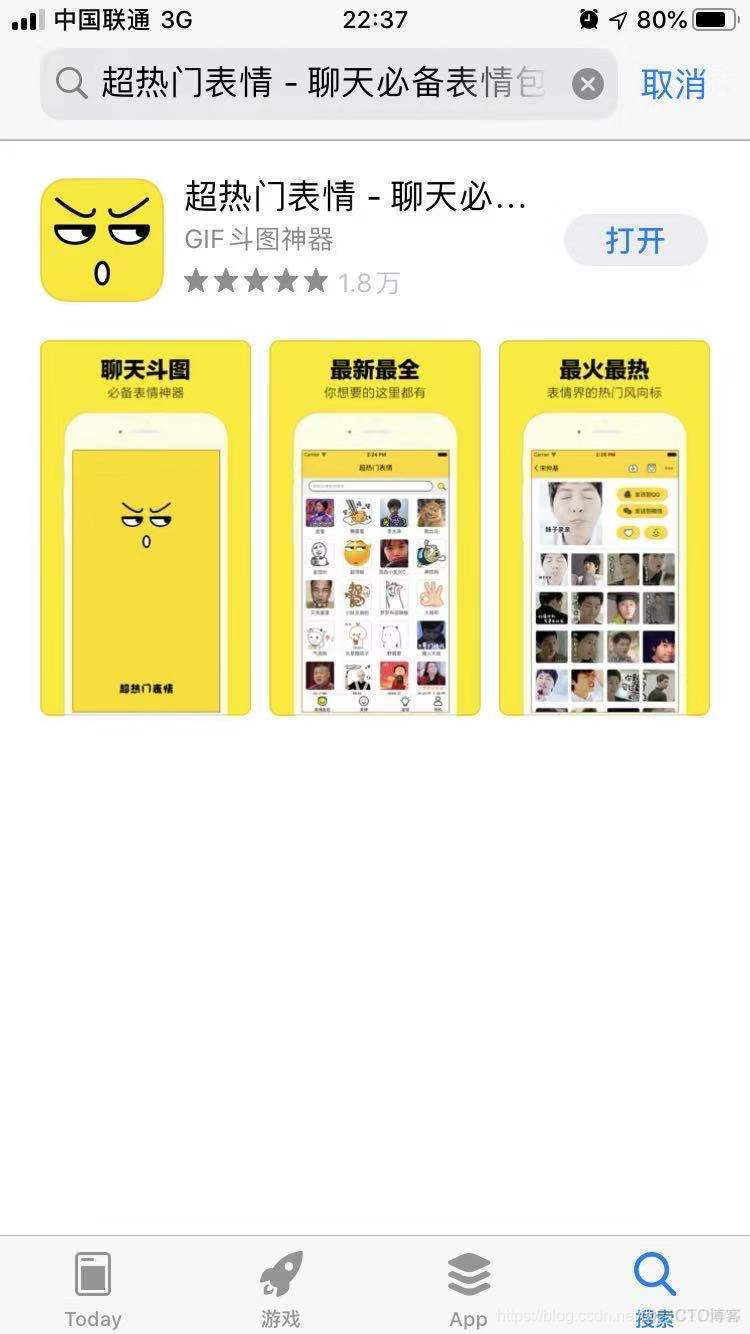
开发环境
python3.6
ios13
mac os
pycharm
charler
抓包
抓包工具使用的是charler软件,手机配置好代理后打开抓包工具,不会配置的可以参考我之前的文章也可以网上搜。
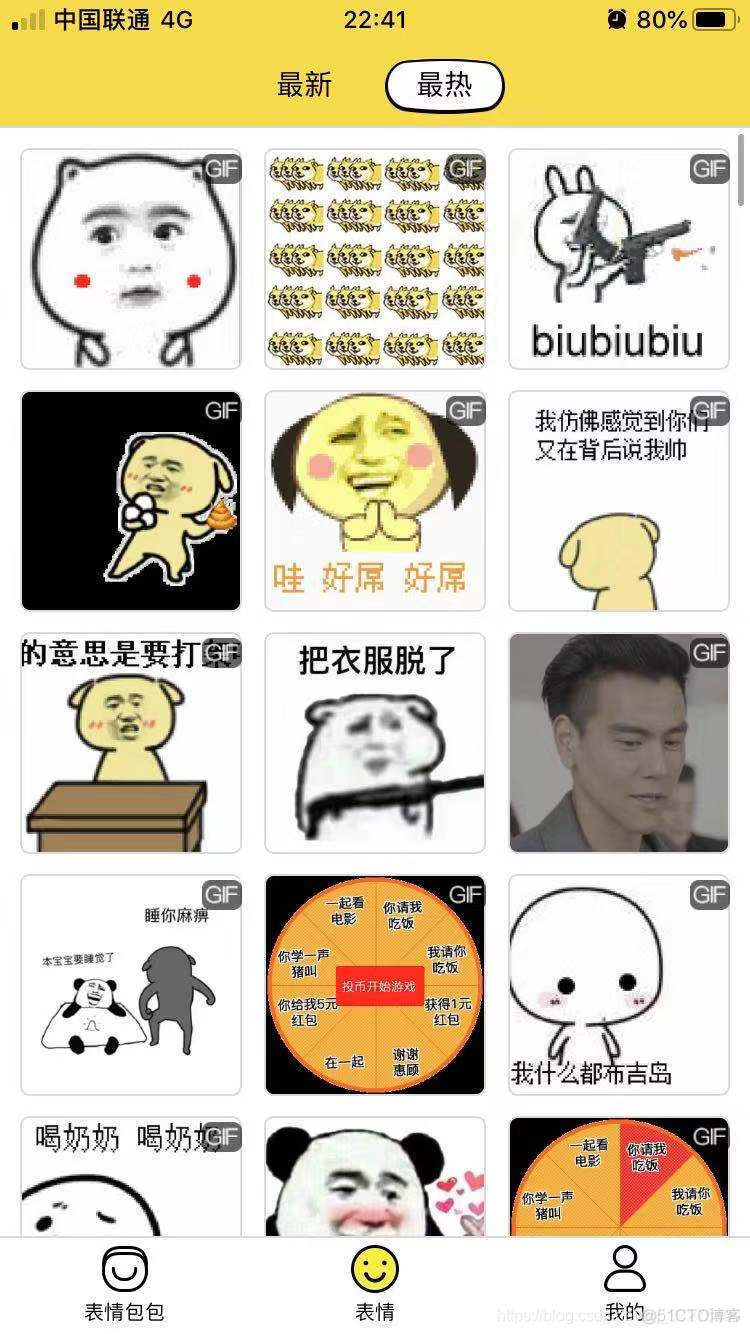
打开软件我就看最热的图黄,就抓这个栏目,耶稣也拦不住了。
找呀找呀找
咦?jpg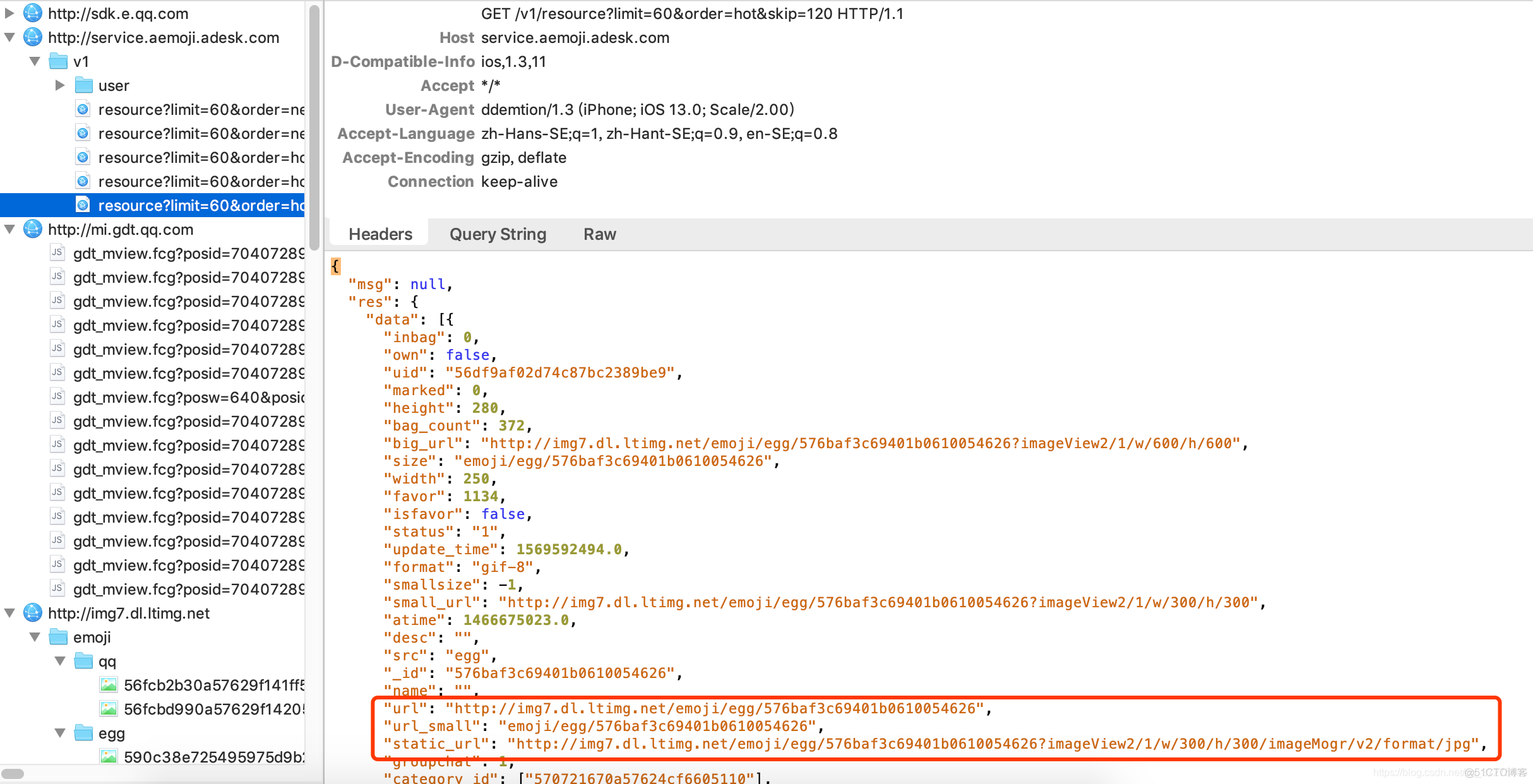
找到了,复制链接浏览器打开。woc居然连反爬都没有直接返回json。
代码:
import requestsfrom multiprocessing.dummy import Pool as mp
import os
from urllib.request import urlretrieve
def down_img(path, url):
f_path = './img/'
if not os.path.exists(f_path):
os.makedirs(f_path)
urlretrieve(url, f_path + path)
def get_json(page):
res = requests.get("http://service.aemoji.adesk.com/v1/resource?limit=60&order=hot&skip={}".format(page))
for data in (res.json()['res']['data']):
down_img(data['uid']+'.jpg', data['static_url'])
if __name__ == '__main__':
pool = mp(16)
for page in range(0, 1000, 60):
pool.apply_async(get_json, args=(page,))
pool.close()
pool.join()
现在,一个简单抓斗图app的爬就结束了。
