最近【稿定设计】这个站点挺火,设计组的大哥一直在提,啊,这个好,这个好。 机智的我,思考了一下,决定给他采集一些公开素材,以后跟设计对线的时候,肯定要卖个人情。 目
最近【稿定设计】这个站点挺火,设计组的大哥一直在提,啊,这个好,这个好。
机智的我,思考了一下,决定给他采集一些公开素材,以后跟设计对线的时候,肯定要卖个人情。
目标站点分析
本次要采集的站点是:https://sucai.gaoding.com/plane/materials,高清图肯定不能采集啦,仅采集 1080 P 的缩略图。
目的是给设计组大哥提供素材参考,毕竟做设计的可不能抄袭哦(思路枯竭的时候,借鉴一下还凑合)。
目标站点的筛选项非常“贴心”的提供“全部”这一选项,省的我们拼凑分类了。
 在查阅分页的时候,发现稿定设计网站仅开放了 100 页数据,每页 100 条,也就是咱只能获取到 10000 张图片。
在查阅分页的时候,发现稿定设计网站仅开放了 100 页数据,每页 100 条,也就是咱只能获取到 10000 张图片。
看了一眼设计大哥的头发,我觉得够他用一年了。
页面 URL 跳转链接规则如下:
https://sucai.gaoding.com/plane/materials?p=1
https://sucai.gaoding.com/plane/materials?p=100
但是数据的请求链接为下述规则:
https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num=1
https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num=2
参数说明
q:搜索的关键字,为空即可;
sort:排序规则,可空;
colors 和 styles:颜色和风格, 保持空;
filter_id:过滤 ID,保持全部应该是 1617130;
page_size:获取的每页数据量;
page_num:页码,该值最大为 100。
有了上述分析之后,就可以进行编码工作了。
编码时间
在正式编码前,先通过一张图整理逻辑,该案例依旧为生产者与消费者模式爬虫,采用 threading 模块与 queue 队列模块实现。
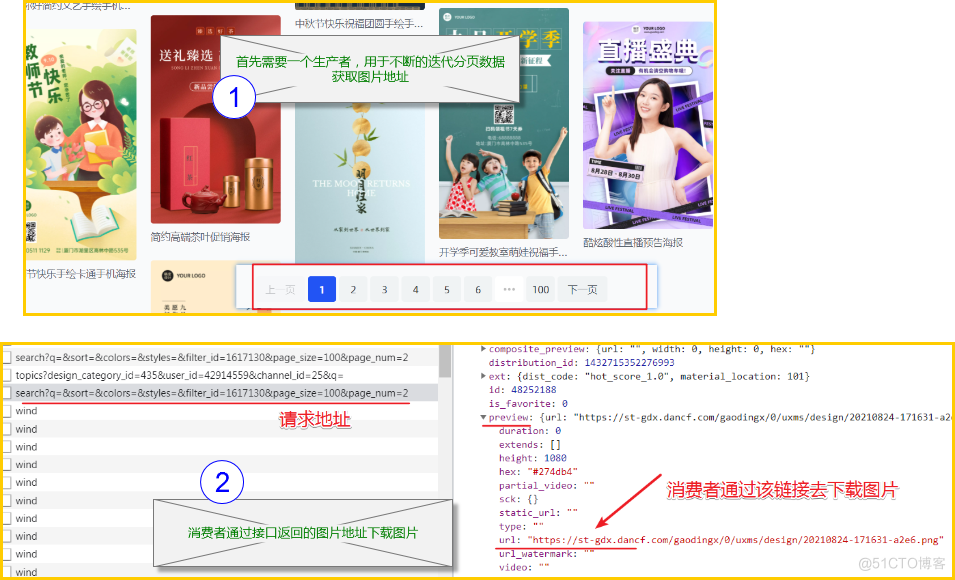 理解上图之后,就可以编写下述代码了,重点部分在注释中体现,本次采用类写法,学习的时候需要特别注意一下。
理解上图之后,就可以编写下述代码了,重点部分在注释中体现,本次采用类写法,学习的时候需要特别注意一下。
import requests
from queue import Queue
import random
import threading
import time
def get_headers():
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"其它UA,自行查找即可"
]
UserAgent = random.choice(user_agent_list)
headers = {'User-Agent': UserAgent,'referer': 'https://sucai.gaoding.com/'}
return headers
# 生产者线程
class Producer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
# 测试爬取 3 页,实际采集的时候,可以放大到100页
def run(self):
# 测试数据,爬取3页
for i in range(1,3):
print("线程名: %s,序号:%d, 正在向队列写入数据 " % (self.getName(), i))
# 拼接URL地址
url = 'https://api-sucai.gaoding.com/api/search-api/sucai/templates/search?q=&sort=&colors=&styles=&filter_id=1617130&page_size=100&page_num={}'.format(i)
res = requests.get(url=url,headers=get_headers(),timeout=5)
# 这里可以增加 try catch 验证,防止报错
if res:
data = res.json()
# JSON 提取数据
for item in data:
title = item["title"]
img_url = item["preview"]["url"]
self.data.put((title,img_url))
print("%s: %s 写入完成!" % (time.ctime(), self.getName()))
# 消费者线程
class Consumer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
def run(self):
while True:
# 从队列获取数据
val = self.data.get()
if val is not None:
print("线程名:%s,正在读取数据:%s" % (self.getName(), val))
title,url = val
# 请求图片
res = requests.get(url=url,headers=get_headers(),timeout=5)
if res:
# 保存图片
with open(f"./imgs/{title}.png","wb") as f:
f.write(res.content)
print(f"{val}","写入完毕")
# 主函数
def main():
queue = Queue()
producer = Producer('生产者', queue)
consumer = Consumer('消费者', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print('所有线程执行完毕')
if __name__ == '__main__':
main()
生产者线程用于产生图片地址,存放到队列 queue 中,消费者线程通过一个“死循环”不断从队列中,获取图片地址,然后进行下载。
代码运行效果如下图所示:

==数据没有采集完毕,想要的可以在评论区留言交流==
今天是持续写作的第 <font color=red>211</font> / 365 天。可以<font color=#04a9f4>关注</font>我,<font color=#04a9f4>点赞</font>我、<font color=#04a9f4>评论</font>我、<font color=#04a9f4>收藏</font>我啦。