步骤 1.选择一个生活页面,按F12,选择Elements栏,点击左边的箭头,把鼠标移到某个视频上面,下栏会定位到其所在的标签,发现这些标签都是在li class="categoryem"标签下 2.循环li标签内的
步骤
1.选择一个生活页面,按F12,选择Elements栏,点击左边的箭头,把鼠标移到某个视频上面,下栏会定位到其所在的标签,发现这些标签都是在<li class="categoryem">标签下
2.循环li标签内的a标签里href的内容,拼接后是每个视频的详情页地址
3.在视频详情页上,查看视频详情页面的加载方式,发现网页源代码中找不到,说明该页面是动态加载的,这样就无需向详情页发送请求了直接向该地址发送即可(发送了也找不到)
4.通过network查看详情页的请求网址
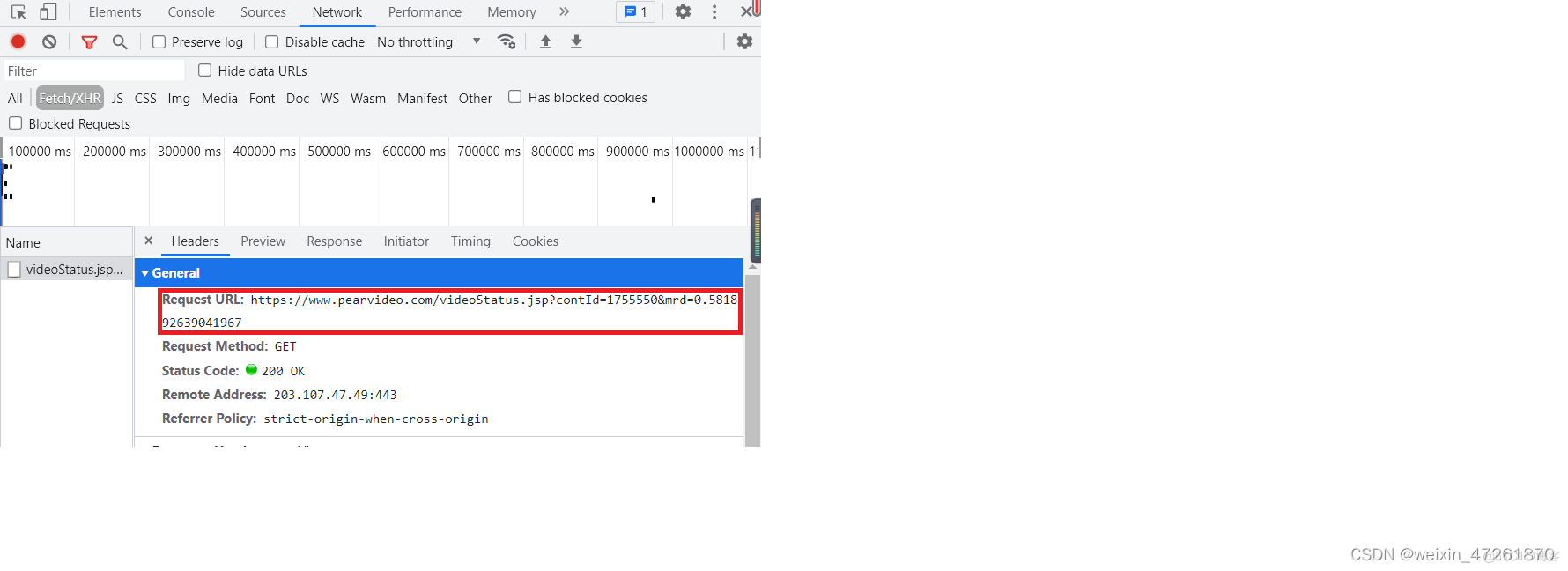

5.朝该详情页发送请求发现获取不到
url='https://www.pearvideo.com/videoStatus.jsp?contId=1755550&mrd=0.581892639041967'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/23'
}
video_page=requests.get(url=url,headers=headers).content
with open('./a.html','wb') as fp:
fp.write(video_page)

{
"resultCode":"5",
"resultMsg":"该文章已经下线!",
"systemTime": "1647781607669"
}
6.原因是有防爬措施之防盗链,得定义一个请求头加上Referer参数再去请求网站
7.去浏览器上复制视频的地址发现与我们拿到的有地方不一样
8.接着去想如何去替换核心数据,去拿到真正的视频地址,研究发现通过systemTime即可


{
"resultCode":"1",
"resultMsg":"success", "reqId":"8544a57d-1ad8-4d74-83ca-740fd9960052",
"systemTime": "1647780126911",
"videoInfo":{"playSta":"1","video_image":"https://image1.pearvideo.com/cont/20220318/11549967-150204-1.png","videos":{"hdUrl":"","hdflvUrl":"","sdUrl":"","sdflvUrl":"","srcUrl":"https://video.pearvideo.com/mp4/third/20220318/1647780126911-11549967-150114-hd.mp4"}}
}
代码示例
#导入模块import requests
from lxml import etree
import time
import os
# 创建存放视频的目录
if not os.path.exists(r'./video'):
os.mkdir(r'./video')
#1.生活页面的url
url='https://www.pearvideo.com/category_5'
#UA伪装
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/23'
}
#2.发送get请求获取页面数据
page_text=requests.get(url=url,headers=headers).text
# 3.使用xpath进行数据解析
#3.1.实例化,将网上获取的源码数据加载到该对象中
tree=etree.HTML(page_text)
# 3.2解析出视频详情链接
li_list=tree.xpath('//*[@id="listvideoListUl"]/li')
for li in li_list:
#1.解析出视频链接相对地址href="video_1755550"
datail_url=li.xpath('./div/a/@href')[0]
#解析出视频名称
name=li.xpath('./div/a/div[2]/text()')[0]+'.mp4'
# 每个视频的href _后面的一串数字都不同,将其拆分取出
video_id = datail_url.split('_')[-1]
#视频详情页的url
video_url='https://www.pearvideo.com/videoStatus.jsp'
headers = {
"Referer": "https://www.pearvideo.com/video_%s" % video_id #Referer告诉服务器我是从哪个页面链接过来的
}
#2.发起请求,获取视频详情页数据
res1 = requests.get(url=video_url,params={'contId': video_id},headers=headers)
# 避免访问次数过多,延迟
time.sleep(1)
#返回json对象
data_dict = res1.json()
#视频地址srcUrl
src_url = data_dict['videoInfo']['videos']['srcUrl']
systemTime = data_dict['systemTime']
#通过字符串替换拼接成真正地址
real_url = src_url.replace(systemTime, 'cont-%s' % video_id)
#发起请求,获取视频二进制数据
res2 = requests.get(real_url).content
#拼接成视频存储路径
file_path = os.path.join('./video', name)
#进行持久化存储
with open(file_path, 'wb')as fp:
fp.write(res2) #写入
print('%s 下载成功' % name)
