正则表达式的使用
- 正则表达式的基础符号
- 在python中使用正则
- findall
- search
- “.*”和“.*?”的区别
正则表达式(Regular Expression)是一段字符串,它可以表示一段有规律的信息。Python自带一个正则表达式模块,通过这个模块可以查找、提取、替换一段有规律的信息。
在程序开发中,要让计算机程序从一大段文本中找到需要的内容,就可以使用正则表达式来实现。使用正则表达式有如下步骤。
寻找规律。
使用正则符号表示规律。
提取信息。
正则表达式的基础符号
点号“.”
- 一个点号可以代替除了换行符以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。
星号“*”
- 一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。
问号“?”
- 问号表示它前面的子表达式0次或者1次。注意,这里的问号是英文问号。
反斜杠“\”
反斜杠在正则表达式里面不能单独使用,甚至在整个Python里都不能单独使用。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号。
反斜杠不仅可以把特殊符号变成普通符号,还可以把普通符号变成特殊符号。
数字“\d”
正则表达式里面使用“\d”来表示一位数字。为什么要用字母d呢?因为d是英文“digital(数字)”的首字母。
再次强调一下,“\d”虽然是由反斜杠和字母d构成的,但是要把“\d”看成一个正则表达式符号整体。
小括号“()”
- 小括号可以把括号里面的内容提取出来。
跳转顶部
在python中使用正则
Python已经自带了一个功能非常强大的正则表达式模块。使用这个模块可以非常方便地通过正则表达式来从一大段文字中提取有规律的信息。
Python的正则表达式模块名字为“re”,也就是“regularexpression”的首字母缩写。在Python中需要首先导入这个模块再进行使用。导入的语句为:
import refindall
Python的正则表达式模块包含一个findall方法,它能够以列表的形式返回所有满足要求的字符串。
findall的函数原型为:
re.findall(pattern, string, flags=0)pattern表示正则表达式,string表示原来的字符串,flags表示一些特殊功能的标志。
findall结果是一个列表,包含了所有匹配到的结果,如果没有匹配的结果,就会返回空列表
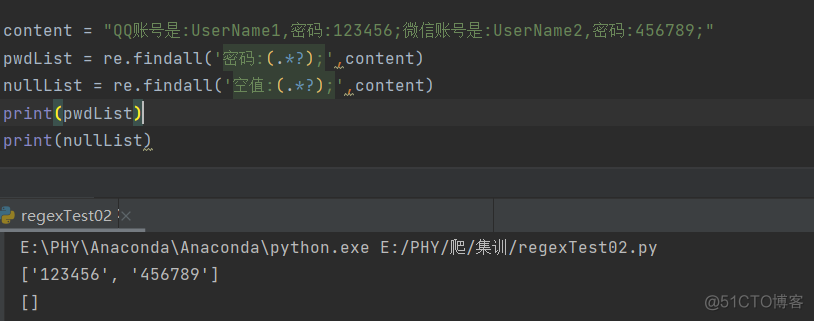
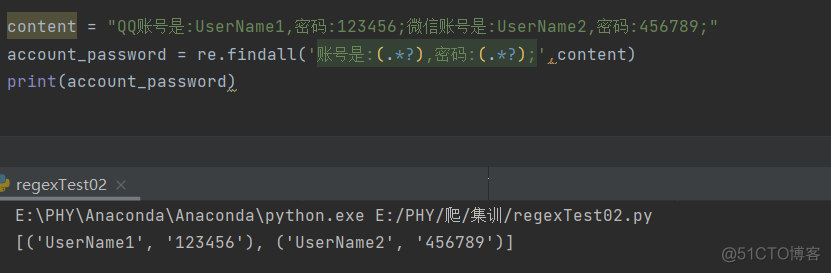
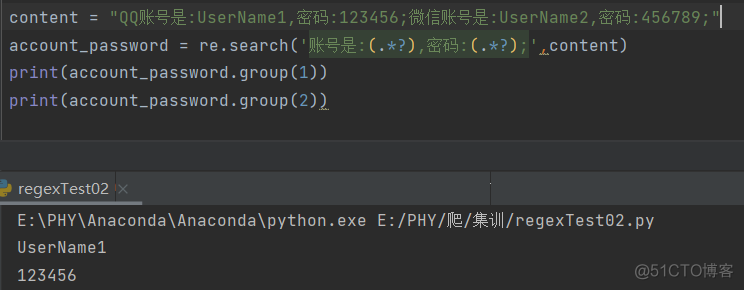
当提取默写内容时,需要使用小括号将这些内容括起来,这样才不会得到不相干的信息。如果包含多个(.*?),那么还是返回列表,但是列表里的元素变成了元组
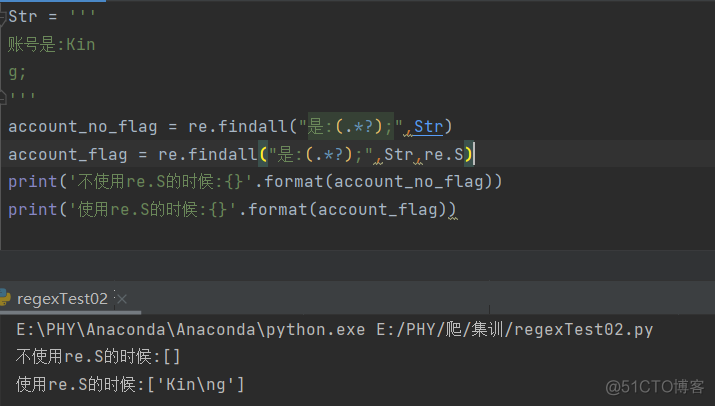
函数原型中有一个flags参数。这个参数是可以省略的。当不省略的时候,具有一些辅助功能,例如忽略大小写、忽略换行符等。这里以忽略换行符为例来进行说明。
跳转顶部
search
search()的用法和findall()的用法一样,但是search()只会返回第1个满足要求的字符串。一旦找到符合要求的内容,它就会停止查找。对于从超级大的文本里面只找第1个数据特别有用,可以大大提高程序的运行效率。
search()的函数原型为:
re.search(pattern, string, flags=0)对于结果,如果匹配成功,则是一个正则表达式的对象;如果没有匹配到任何数据,就是None。
如果需要得到匹配到的结果,则需要通过.group()这个方法来获取里面的值,
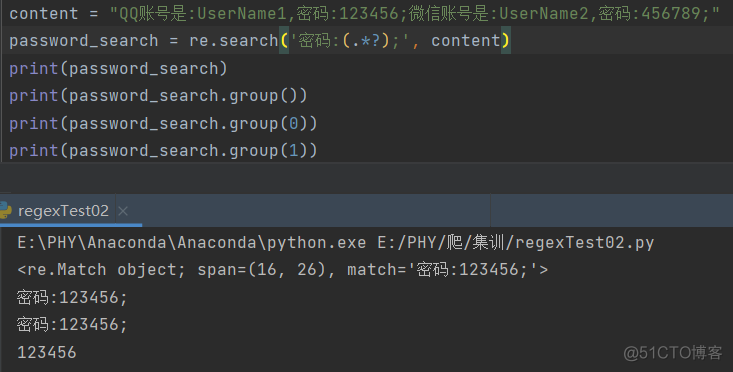
只有在.group()里面的参数为1的时候,才会把正则表达式里面的括号中的结果打印出来。
.group()的参数最大不能超过正则表达式里面括号的个数。参数为1表示读取第1个括号中的内容,参数为2表示读取第2个括号中的内容。
跳转顶部
“.”和“.?”的区别
点号表示任意非换行符的字符,星号表示匹配它前面的字符0次或者任意多次。所以“.*”表示匹配一串任意长度的字符串任意次。这个时候必须在“.*”的前后加其他的符号来限定范围,否则得到的结果就是原来的整个字符串。
如果在“.*”的后面加一个问号,变成“.*?”,那么可以得到什么样的结果呢?问号表示匹配它前面的符号0次或者1次。于是.*?的意思就是匹配一个能满足要求的最短字符串
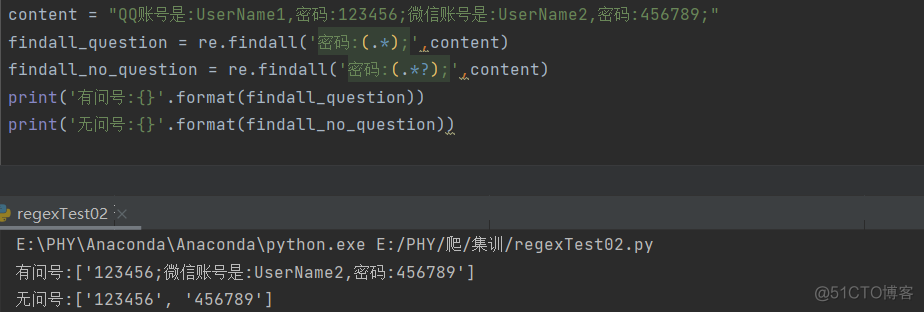
①“.*”:贪婪模式,获取最长的满足条件的字符串。
②“.*?”:非贪婪模式,获取最短的能满足条件的字符串。
跳转顶部