prometheus监控JMX需要向Tomcat内添加jmx_prometheus_javaagent包,并暴露一个端口给外部访问来获取数据。
本文采用0.3.1版本:jmx_prometheus_javaagent-0.3.1.jar
Tomcat采用docker部署,生产环境建议做成镜像用k8s启动。
1、前置准备
本文采用docker方式部署Tomcat
1.1、创建install_tomcat脚本
# cat install_tomcat.sh
docker run -d \
--name tomcat-1 \
-v /root/manifests/jvm/prom-jvm-demo:/jmx-exporter \
-e CATALINA_OPTS="-Xms64m -Xmx128m -javaagent:/jmx-exporter/jmx_prometheus_javaagent-0.3.1.jar=6060:/jmx-exporter/simple-config.yml" \
-p 6060:6060 \
-p 8080:8080 \
tomcat:latest
1.2、创建prometheus-serviceMonitorJvm.yaml,用于向kube-prometheus内添加serviceMonitor
# cat prometheus-serviceMonitorJvm.yaml
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: jmx-metrics
namespace: monitoring
labels:
k8s-apps: jmx-metrics
spec:
jobLabel: metrics
selector:
matchLabels:
metrics: jmx-metrics # 根据label中有metrics: jmx-metrics 的service
namespaceSelector:
any: true # 所有名称空间
endpoints:
- port: http-metrics # 拉取的端口和下边对应
interval: 15s # 拉取metric的时间间隔
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrapetrue: "true"
labels:
metrics: jmx-metrics # 和上边一致
name: kube-jmx
namespace: monitoring
spec:
ports:
- name: http-metrics
port: 6060 # service的端口,供上边获取数据
protocol: TCP
targetPort: 6060 # 绑定宿主机的端口,也就是jmx_prometheus_javaagent的端口
# selector: # 因为是手动指定endpoint所以不能添加。否则过一段时间查看service的endpoint会为空
# k8s-app: kube-jmx # 如果是k8s部署的就需要写标签,去绑定tomcat pod的service
---
apiVersion: v1
kind: Endpoints
metadata:
name: kube-jmx
namespace: monitoring
subsets:
- addresses:
- ip: 宿主机IP
ports:
- name: http-metrics
port: 6060 # jmx_prometheus_javaagent的端口
protocol: TCP
1.3、在当前目录创建prom-jvm-demo,下载jmx_prometheus_javaagent至prom-jvm-demo目录下
# ls
docker.yaml prometheus-serviceMonitorJvm.yaml
# mkdir prom-jvm-demo
# wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar -O prom-jvm-demo/jmx_prometheus_javaagent-0.3.1.jar
1.4、进入prom-jvm-demo目录内,创建jmx_prometheus_javaagent的配置文件simple-config.yml
# cd prom-jvm-demo
# cat simple-config.yml
---
lowercaseOutputLabelNames: true
lowercaseOutputName: true
whitelistObjectNames: ["java.lang:type=OperatingSystem"]
rules:
- pattern: 'java.lang<type=OperatingSystem><>((?!process_cpu_time)\w+):'
name: os_$1
type: GAUGE
attrNameSnakeCase: true
2、启动Tomcat
2.1、执行install_tomcat.sh
# sh install_tomcat.sh
2.2、测试访问6060端口
# curl 127.0.0.1:6060
# HELP jmx_config_reload_success_total Number of times configuration have successfully been reloaded.
# TYPE jmx_config_reload_success_total counter
jmx_config_reload_success_total 0.0
# HELP os_free_swap_space_size FreeSwapSpaceSize (java.lang<type=OperatingSystem><>FreeSwapSpaceSize)
# TYPE os_free_swap_space_size gauge
os_free_swap_space_size 0.0
# HELP os_free_physical_memory_size FreePhysicalMemorySize (java.lang<type=OperatingSystem><>FreePhysicalMemorySize)
# TYPE os_free_physical_memory_size gauge
os_free_physical_memory_size 3.68160768E8
# HELP os_max_file_descriptor_count MaxFileDescriptorCount (java.lang<type=OperatingSystem><>MaxFileDescriptorCount)
# TYPE os_max_file_descriptor_count gauge
os_max_file_descriptor_count 1048576.0
# HELP os_system_load_average SystemLoadAverage (java.lang<type=OperatingSystem><>SystemLoadAverage)
# TYPE os_system_load_average gauge
os_system_load_average 1.74
# HELP os_total_physical_memory_size TotalPhysicalMemorySize (java.lang<type=OperatingSystem><>TotalPhysicalMemorySize)
# TYPE os_total_physical_memory_size gauge
os_total_physical_memory_size 3.974213632E9
# HELP os_committed_virtual_memory_size CommittedVirtualMemorySize (java.lang<type=OperatingSystem><>CommittedVirtualMemorySize)
# TYPE os_committed_virtual_memory_size gauge
os_committed_virtual_memory_size 3.71601408E9
# HELP os_system_cpu_load SystemCpuLoad (java.lang<type=OperatingSystem><>SystemCpuLoad)
# TYPE os_system_cpu_load gauge
os_system_cpu_load 0.10213187902825979
# HELP os_available_processors AvailableProcessors (java.lang<type=OperatingSystem><>AvailableProcessors)
# TYPE os_available_processors gauge
os_available_processors 4.0
# HELP os_process_cpu_load ProcessCpuLoad (java.lang<type=OperatingSystem><>ProcessCpuLoad)
# TYPE os_process_cpu_load gauge
os_process_cpu_load 0.0
......省略
3、创建serviceMonitor
3.1、apply prometheus-serviceMonitorJvm.yaml
# kubectl apply -f prometheus-serviceMonitorJvm.yaml
3.2、查看创建的serviceMonitorJvm、service、endpoint
# kubectl get servicemonitors,svc,endpoints -n monitoring | grep jmx
servicemonitor.monitoring.coreos.com/jmx-metrics 4d20h
service/kube-jmx ClusterIP 10.0.0.157 <none> 6060/TCP 4d20h
endpoints/kube-jmx xxx.xx.x.xxx:6060 4d20h
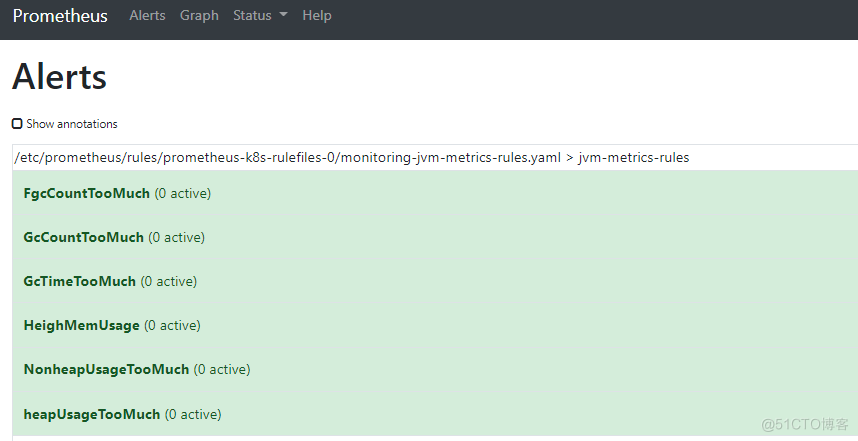
4、查看prometheus WEB
4.1、访问prometheus web页面
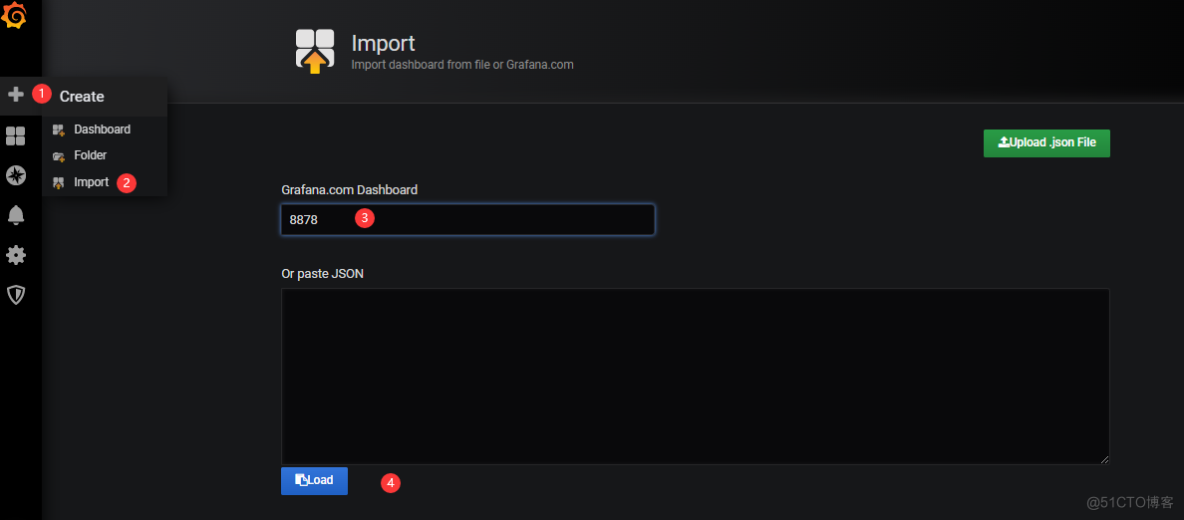
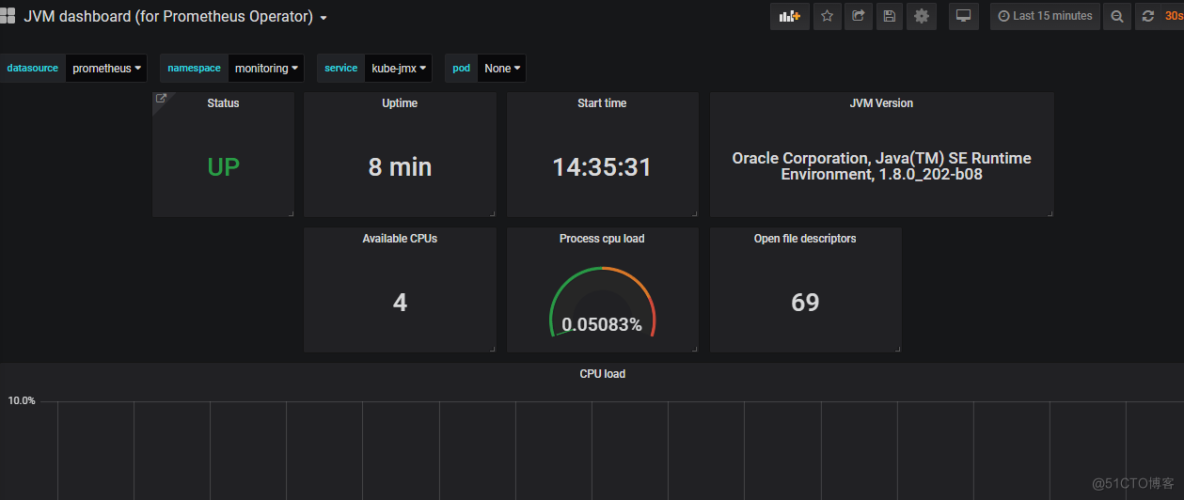
 5、添加grafana展示
5、添加grafana展示
5.1、在grafana内添加dashboards:8878
6、添加告警规则
6.1、编写prometheus-rules-add-jvm.yaml,也可在prometheus-rules.yaml内追加
# cat prometheus-rules-add-jvm.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: jvm-metrics-rules
namespace: monitoring
spec:
groups:
- name: jvm-metrics-rules
rules:
# 在5分钟里,GC花费时间超过10%
- alert: GcTimeTooMuch
expr: increase(jvm_gc_collection_seconds_sum[5m]) > 30
for: 5m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} GC时间占比超过10%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} GC时间占比超过10%,当前值({{ $value }}%)"
# GC次数太多
- alert: GcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count[1m]) > 30
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 1分钟GC次数>30次"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} 1分钟GC次数>30次,当前值({{ $value }})"
# FGC次数太多
- alert: FgcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count{gc="ConcurrentMarkSweep"}[1h]) > 3
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 1小时的FGC次数>3次"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} 1小时的FGC次数>3次,当前值({{ $value }})"
# 非堆内存使用超过80%
- alert: NonheapUsageTooMuch
expr: jvm_memory_bytes_used{job="jmx-metrics", area="nonheap"} / jvm_memory_bytes_max * 100 > 80
for: 5m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 非堆内存使用>80%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} 非堆内存使用率>80%,当前值({{ $value }}%)"
# 内存使用预警
- alert: HeighMemUsage
expr: process_resident_memory_bytes{job="jmx-metrics"} / os_total_physical_memory_bytes * 100 > 85
for: 5m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} rss内存使用率大于85%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} rss内存使用率大于85%,当前值({{ $value }}%)"
# 堆内存使用超过85%
- alert: heapUsageTooMuch
expr: jvm_memory_bytes_used{area="heap"} / jvm_memory_bytes_max * 100 > 95
for: 5m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 堆内存使用>85%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} ip:{{ $labels.instance }} 堆内存使用率>85%,当前值({{ $value }}%)"
6.2、执行并在prometheus Alerts内查看
# kubectl apply -f prometheus-rules-add-jvm.yaml