Redis主从复制集群及数据异常丢失恢复思路
1.redis主从复制原理
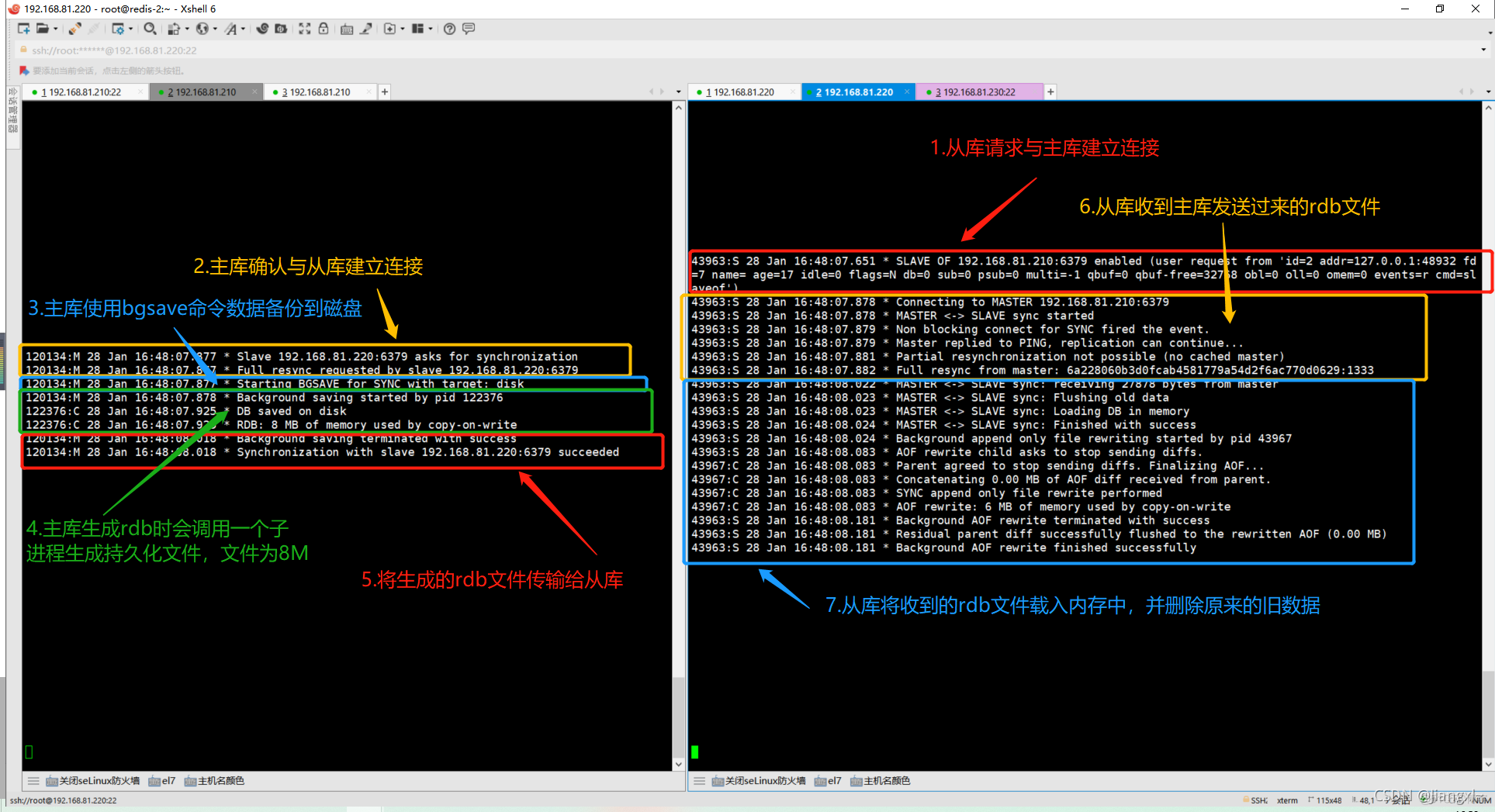
1.从库向主库发送同步请求
2.主库接收从库发送的同步请求
3.主库开始使用bgsave生成rdb文件
4.主库rdb文件生成后保存到磁盘,让将rdb文件发送给从库
5.从库接收主库发送的rdb文件,将rdb文件载入内存
从库在同步主库的时候,会把从库上的所有数据全部清空,因此在做redis主从的时候尽量选择没有任何数据的redis
架构图
环境准备
IP 服务 角色 192.168.81.210 redis-1 主库 192.168.81.220 redis-2 从库2.部署两台redis
2.1.192.168.81.210配置
1.创建redis部署路径 [root@redis-1 ~]# mkdir -p /data/redis_cluster/redis_6379/{conf,pid,logs,data} [root@redis-1 ~]# tree /data/redis_cluster/ /data/redis_cluster/ └── redis_6379 ├── conf ├── logs ├── pid └── data 2.下载redis [root@redis-1 ~]# mkdir /data/soft [root@redis-1 ~]# cd /data/soft [root@redis-1 /data/soft]# wget https://repo.huaweicloud.com/redis/redis-3.2.9.tar.gz 3.编译安装redis [root@redis-1 /data/soft]# tar xf redis-3.2.9.tar.gz -C /data/redis_cluster/ [root@redis-1 /data/soft]# cd /data/redis_cluster/ [root@redis-1 /data/redis_cluster]# ln -s redis-3.2.9/ redis [root@redis-1 /data/redis_cluster]# cd redis/src [root@redis-1 /data/redis_cluster/redis]# make && make install 4.准备配置文件 [root@redis-1 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf daemonize yes bind 192.168.81.210 127.0.0.1 port 6379 pidfile /data/redis_cluster/redis_6379/pid/redis_6379.pid logfile /data/redis_cluster/redis_6379/logs/redis_6379.log databases 16 dbfilename redis_6379.rdb dir /data/redis_cluster/redis_6379/data/ save 900 1 save 300 100 save 60 10000 appendonly yes appendfilename "appendonly.aof" appendfsync always appendfsync everysec appendfsync no no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes 5.启动redis [root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf2.2.192.168.81.220配置
由于redis-1已经部署好了一套redis,我们可以直接复制过来使用
1.使用rsync将redis-1的redis目录拷贝过来你 [root@redis-1 ~]# rsync -avz /data root@192.168.81.220:/ 2.查看拷贝过来的目录文件 [root@redis-2 ~]# ls /data/redis_cluster/ redis redis-3.2.9 redis_6379 [root@redis-2 ~]# ls /data/redis_cluster/redis_6379/ conf data logs pid 3.编译安装redis,使系统能使用redis命令 直接执行make install即可,因为编译步骤在redis-1已经做了 [root@redis-2 ~]# cd /data/redis_cluster/redis-3.2.9/ [root@redis-2 /data/redis_cluster/redis-3.2.9]# make install 4.修改redis配置文件 [root@redis-2 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf bind 192.168.81.220 127.0.0.1 5.启动redis [root@redis-2 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf3.redis主从复制配置
3.1.在主库批量创建key
[root@redis-1 ~]# for i in {0..2000}; do redis-cli set k_${i} v_${i}; echo "k_${i} is ok"; done 127.0.0.1:6379> DBSIZE (integer) 20013.2.配置从库连接主库
两种配置方式实现Redis主从复制:
- 配置文件实现
- 命令行执行命令实现
3.2.1.在配置文件中设置
1.修改配置文件 [root@redis-2 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf slaveof 192.168.81.210 6379 #指定主库的ip和端口 2.重启redis [root@redis-2 ~]# redis-cli shutdown [root@redis-2 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf3.2.2.在命令行热更新配置
[root@redis-2 ~]# redis-cli 127.0.0.1:6379> SLAVEOF 192.168.81.210 6379 OK3.3.查看从库是否同步主库数据
1.在从库上执行keys查看数据是否相同 [root@redis-2 ~]# redis-cli 127.0.0.1:6379> keys * 2.在主库上新建一个key,查看从库是否存在 主: 127.0.0.1:6379> set name jiangxl OK 从: 127.0.0.1:6379> get name "jiangxl" 3.在主库删除k_114,查看从库是否也删除 主: 127.0.0.1:6379> del k_114 (integer) 1 从: 127.0.0.1:6379> get k_114 (nil)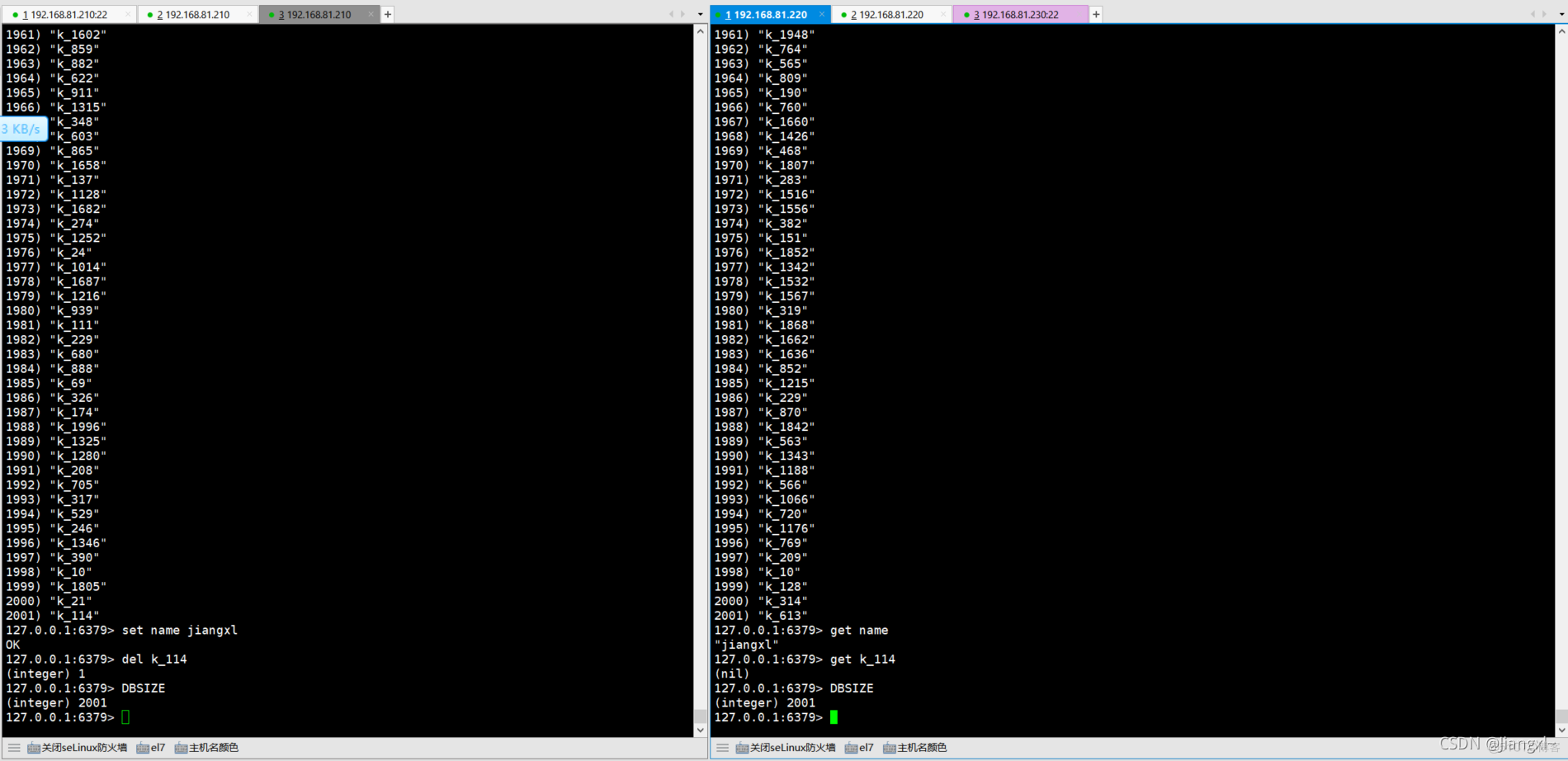
3.4.在查看日志中主从同步的原理
主库从库有记录复制的详细日志
4.redis主从复制危险操作
4.1.使用热更新配置误操作
redis主从复制如果使用热更新配置,有时候会因为选错主机把从库误认为主库,结果在主库上执行了slaveof,这样就会导致主库上的数据被清空,因为从库上是没有数据的
从库在同步主库的时候会把原本自己的数据全部清空
误操作过程
从库数据为0 127.0.0.1:6379> DBSIZE (integer) 0 主库数据为2001 127.0.0.1:6379> DBSIZE (integer) 2001 在主库上操作同步本该从库的数据 127.0.0.1:6379> SLAVEOF 192.168.81.220 6379 OK 再次查看数据,数据已经清空 127.0.0.1:6379> DBSIZE (integer) 04.2.避免热更新配置误操作
1.不使用热更新,直接在配置文件里配置主从
2.在执行slaveof的时候先执行bgsave,把数据手动备份一下,然后在数据目录,将rdb文件复制成另一个文件,做备份,这样即使出现问题也能即使恢复
bgsave之后不用重启,直接备份rdb文件即可
1.手动持久化 127.0.0.1:6379> BGSAVE Background saving started 2.备份rdb文件 [root@redis-1 ~]# cd /data/redis_cluster/redis_6379/ [root@redis-1 /data/redis_cluster/redis_6379]# cd data/ [root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb redis_6379.rdb.bak 3.再次同步错误的主库,造成数据丢失 127.0.0.1:6379> SLAVEOF 192.168.81.220 6379 OK 127.0.0.1:6379> keys * (empty list or set) 4.还原备份的rdb文件,先停掉redis,在还原 [root@redis-1 ~]# redis-cli shutdown [root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb.bak redis_6379.rdb 5.查看还原后的数据 [root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf 127.0.0.1:6379> DBSIZE (integer) 20015.模拟redis主从复制错误数据恢复
模拟redis主从同步误操作数据恢复
大致思路:
1.清空两台redis的数据
2.在主库上创建一些数据,然后使用bgsave命令,将数据保存到磁盘,再将磁盘的rdb文件备份
3.再将从库的数据同步过来,模拟主库数据丢失
4.从rdb备份文件还原数据库
这个实验的主要的目的是操作redis备份还原
5.1.清空数据
两台redis都需要操作
先关闭再删除数据再启动
[root@redis-1 ~]# redis-cli shutdown [root@redis-1 ~]# rm -rf /data/redis_cluster/redis_6379/data/* [root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf [root@redis-1 ~]# redis-cli 127.0.0.1:6379> keys * (empty list or set)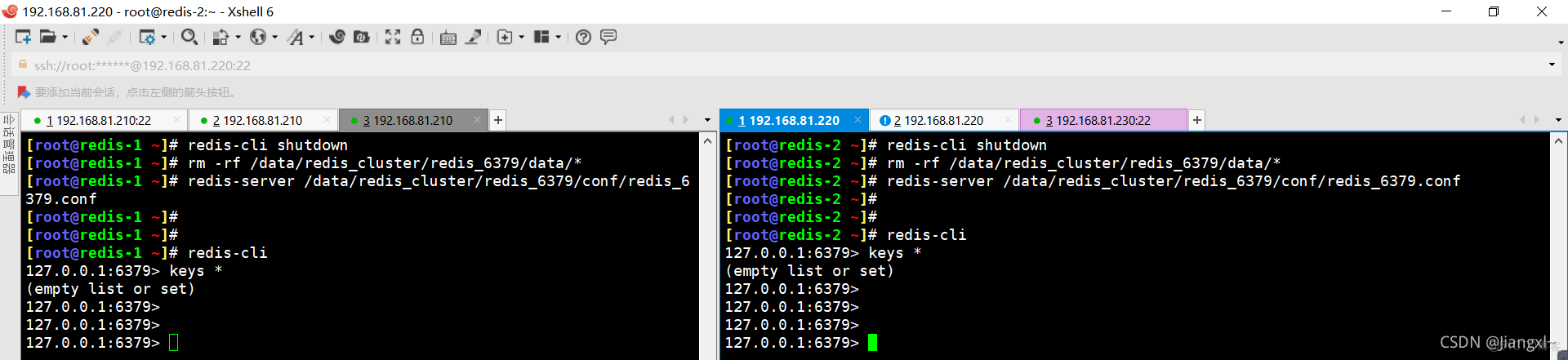
5.2.在主库批量创建数据并备份
1.批量创建数据 [root@redis-1 ~]# for i in {0..2000}; do redis-cli set k_${i} v_${i}; echo "k_${i} is ok"; done 127.0.0.1:6379> DBSIZE (integer) 2001 2.将近数据写入到 127.0.0.1:6379> BGSAVE Background saving started 3.备份rdb文件 [root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb redis_6379.rdb.bak [root@redis-1 /data/redis_cluster/redis_6379/data]# ll 总用量 56 -rw-r--r--. 1 root root 27877 1月 28 21:00 redis_6379.rdb -rw-r--r--. 1 root root 27877 1月 28 21:01 redis_6379.rdb.bak5.3.同步从库的数据造成数据丢失
这时从库的数据应该是空的
[root@redis-2 ~]# redis-cli 127.0.0.1:6379> keys * (empty list or set)主库同步从库的数据,同步完主库数据丢失,这样就模拟了主库数据丢失的情况
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379 OK 127.0.0.1:6379> keys * (empty list or set)5.4.恢复主库的数据
先关掉redis,还原,最后在开启redis
1.关掉redis [root@redis-1 ~]# redis-cli shutdown 2.还原rdb备份文件 [root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb.bak redis_6379.rdb cp:是否覆盖"redis_6379.rdb"? y 3.启动redis [root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf 4.查看数据是否还原 [root@redis-1 ~]# redis-cli 127.0.0.1:6379> keys *
6.模拟线上环境主库宕机故障恢复
思路:
1.首先保证主从同步已经配置完成,主库从库都有数据
2.关闭redis主库,模拟redis主库宕机
3.查看redis从库是否还存在数据,是否可读可写(不能写,只能读)
4.关闭从库的slaveof,停止主从同步,将应用连接redis的地址改成从库,保证业务不断
5.修复主库,主库上线后,与从库建立主从复制关系,原来的从库(redis-2)就变成了主库,现在的主库变成了从库(redis-1)这时 关掉应用程序,停止数据写入
6.然后将现在主库(redis-2)的数据同步到现在的从库(redis-1)
7.关闭现在从库(redis-1)的slaveof,停止主从复制,然后将现在主库(redis-2)配置salveof,同步原来的主库(redis-1)
8.数据同步完,原来的主库从库就恢复完毕了
简单明了的一句话:主库因为某种原因宕机无法提供服务了,直接将从库切换成主库提供服务,然后后原来的主库恢复后同步当前主库的数据,然后停掉所有线上运行的程序,将现在的主库去同步恢复后的主库,重新生成主从关系。
6.1.配置主从模拟线上环境
配置主从前先保证主库上面有数据
1.登陆主库redis-1查看是否有数据 [root@redis-1 ~]# redis-cli 127.0.0.1:6379> DBSIZE (integer) 2001 2.登陆从库redis-2查看是否有数据 [root@redis-2 ~]# redis-cli 127.0.0.1:6379> keys * (empty list or set) 3.从库没有数据的情况下在从库上配置主从,同步主库的数据 127.0.0.1:6379> SLAVEOF 192.168.81.210 6379 OK 数据已经同步 127.0.0.1:6379> DBSIZE (integer) 20016.2.模拟主库宕机验证从库是否可读写
1.直接关掉主库,造成宕机 [root@redis-1 ~]# redis-cli shutdown 2.查看从库是否可读写 只能读,不能写 [root@redis-2 ~]# redis-cli get k_1 "v_1" [root@redis-2 ~]# redis-cli set k999 k_1 (error) READONLY You can't write against a read only slave.主库一宕机,从库就会一直输出日志提示连接不上主库
6.3.关闭从库的主从复制保证业务的不间断
现在主库是不可用的,从库也只能读不能写,但是数据只有这么一份了,我们只能关闭从库上的主从复制,让从库变成主库,再配置业务的redis地址,首先要保证业务的不中断
1.关闭从库redis-2的主从同步配置,使其成为主库 [root@redis-2 ~]# redis-cli slaveof no one OK 2.将应用的redis地址修改为从库,只要从库关掉了主从配置,他自己就是一个可读可写的库了,库里有故障前的所有数据,可以先保证业务的不间断6.4.修复故障的主库同步原来从库的数据
修复完主库,已经是有数据的了,为什么还要同步从库的数据呢,因为在主库挂掉的那一瞬间,从库去掉了主从配置,自己已经成了主库,并且也提供了一段时间的数据写入,这时从库的数据时最完整的
同步现在主库(原来的从库)的数据时,先要将应用关掉,不要在往里写数据了
在主库(原来的从库上)写入几个新的数据,模拟产生的新数据
[root@redis-2 ~]# redis-cli 127.0.0.1:6379> set zuixinshujv vvvvv OK在重新上线的主库上配置主从同步,使自己变成从库,同步主库的(原来的从库)数据
同步之后,现在从库(重新修复的主库已经有最新数据了)
同步之前先将应用停掉,不要再往redis中写数据 [root@redis-1 ~]# redis-cli 127.0.0.1:6379> SLAVEOF 192.168.81.220 6379 OK 127.0.0.1:6379> get zuixinshujv "vvvvv"6.5.从库重新上线为主库
这里的从库重新上线指的就是原来故障的主库,现在已经同步到最新数据了,因此要上线成为主库,之前选他作为主库就是因为他的性能比从库各方面都要高,避免将来因为性能再次发生故障,因此要切换
1.关闭从库(原来的主库)的主从配置 [root@redis-1 ~]# redis-cli 127.0.0.1:6379> SLAVEOF no one OK 2.在主库(原来的从库)配置主从复制 [root@redis-2 ~]# redis-cli 127.0.0.1:6379> SLAVEOF 192.168.81.210 6379 OK6.6.将应用的redis地址再次修改为主库的地址
目前主库已经恢复了,并且主从之前重新建立了主从同步关系,现在就可以把应用的redis地址修改为主库,启动应用就可以了