Linux系统版本:
[root@master ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
Mysql数据版本:
mysql-5.7.31-1.el7.x86_64.rpm-bundle.tar
角色分配:
Master 10.40.42.103 (mha master)
Slave1 10.40.42.105 (mha node1)
Slave2 10.40.42.127 (mha node2)
安装mysql:
yum localinstall mysql-community-* -y
配置一主多从:
master主库/etc/my.cn的配置:
[root@master ~]# grep -v "^#" /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
server-id=1 # 服务ID
log_bin=/var/lib/mysql/mysql-bin # 指定二进制日志路径
binlog_format=ROW # 以行的方式保存二进制日志
skip-name-resolve # 不将IP地址解析成名字
relay_log=relay-log # 开启中继日志
Node1的/etc/my.cn配置:
[root@node1 ~]# grep -v "^#" /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
server-id=2
read-only
log_bin=/var/lib/mysql/mysql-bin
binlog_format=row
skip-name-resolve
relay_log_purge=0 # 默认是清除中继日志,选择不清除
relay_log=relay-log # 开启中继日志
Node2的/etc/my.cn配置:
[root@node2 ~]# grep -v "^#" /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
server-id=3
read-only
skip-name-resolve
relay_log_purge=0 # 不清除中继日志
log_bin=/var/lib/mysql/mysql-bin
binlog_format=row
relay_log=relay-log #开启中继日志
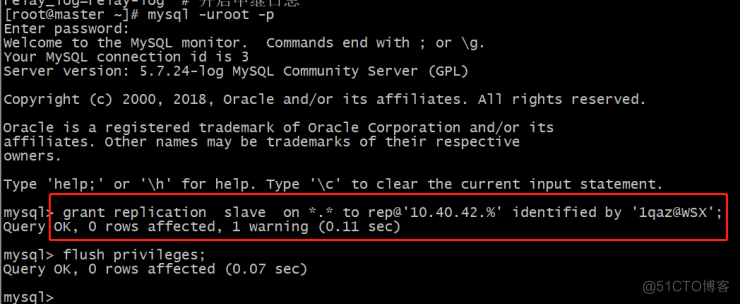
master创建主从复制用户权限:
mysql> grant replication slave on *.* to rep@'10.40.42.%' identified by '1qaz@WSX'; Query OK, 0 rows affected, 1 warning (0.11 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.07 sec)

Node1启动主从复制:
mysql> CHANGE MASTER TO MASTER_HOST='10.40.42.103',MASTER_USER='rep',MASTER_PASSWORD='1qaz@WSX',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=597;
Query OK, 0 rows affected, 2 warnings (0.24 sec)
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)

Node2启动主从复制:
mysql> CHANGE MASTER TO MASTER_HOST='10.40.42.103',MASTER_USER='rep',MASTER_PASSWORD='1qaz@WSX',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=597;
Query OK, 0 rows affected, 2 warnings (0.59 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)

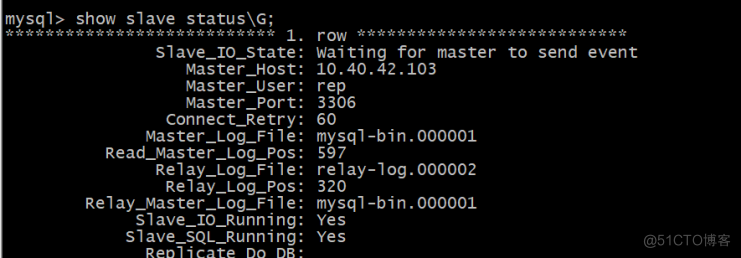
查看node1和node2的主从状态:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
master节点再创建一个super权限的用户:
登录三台数据库服务器,创建mhauser账号并授权,也可以直接使用root账户或其他有权限的已有用户
需要的权限:Super,select,create,insert,update,delete,drop,reload
这个账号主要提供给mah管理监控主从和自动选举等操作使用。
mysql> grant all privileges on *.* to 'mhauser'@'%' identified by '1qaz@WSX';
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.02 sec)
MHA的安装:
下载mha软件:
mha的安装依赖epel-release源,先安装epel-release源。
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
管理节点安装manger和node软件包(master主库)
Node节点安装node软件包(salve1和slave2)
master节点的安装:
[root@master ~]# yum localinstall mha4mysql-* -y
两台台node节点的安装:
yum localinstall mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
MHA manager管理工具:
在manager节点安装完成后会生成一些管理工具,manager的主要管理工具有:
masterha_check_ssh:检查MHA的SSH配置状况
masterha_check_repl:检查MySQL复制状况
masterha_manger:启动MHA
masterha_check_status:检测当前MHA运行状态
masterha_master_monitor:检测master是否宕机
masterha_master_switch:控制故障转移(自动或者手动)
masterha_conf_host:添加或删除配置的server信息
生成ssh秘钥:
由于MHA manager通过SSH访问所有的node节点,各个node节点也同样通过SSH来相互发送不同的relay log 文件,所以要在每一个node和manager上配置SSH无密码登陆。
master和node各个节点之间相互无秘钥登录:
[root@master ~]# ssh-keygen
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.103
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.105
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.127
[root@node1 ~]# ssh-keygen
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.103
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.105
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.127
[root@node2 ~]# ssh-keygen
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.103
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.105
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.127
三台主机/etc/hosts增加解析:
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.40.42.103 master
10.40.42.105 node1
10.40.42.127 node2
MHA配置:
三台主机创建mha远程数据目录:
[root@master ~]# mkdir /etc/mha/data -p

创建mha.cnf作为mha的运行配置文件:
[root@master mha]# cat mha.cnf
[server default]
manager_workdir=/etc/mha/
manager_log=/etc/mha/app1.log
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover
#master_ip_online_change_script=/usr/local/bin/master_ip_online_change
user=mhauser
password=1qaz@WSX
ping_interval=1
remote_workdir=/etc/mha/data
repl_user=rep
repl_password=1qaz@WSX
ssh_user=root
[server1]
hostname=10.40.42.103
port=3306
candidate_master=1
[server2]
hostname=10.40.42.105
port=3306
candidate_master=1
check_repl_delay=0
[server3]
hostname=10.40.42.127
port=3306
check_repl_delay=0
no_master=1
检验 mha master和node之间免秘钥登录:
[root@master mha]# masterha_check_ssh --conf /etc/mha/mha.cnf
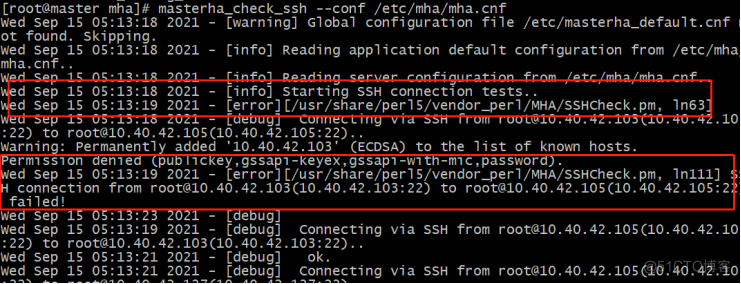
报错信息:
master ssh master 22端口失败
解决:
[root@master mha]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.40.42.103
再次检查全部成功:
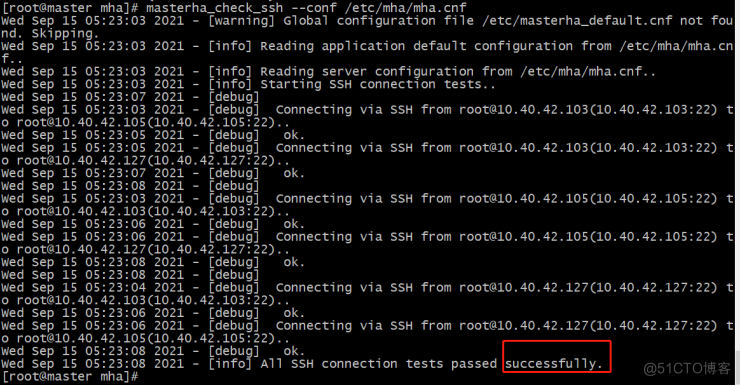
检验mha master和node之间 repl通道:
[root@master mha]# masterha_check_repl --conf /etc/mha/mha.cnf
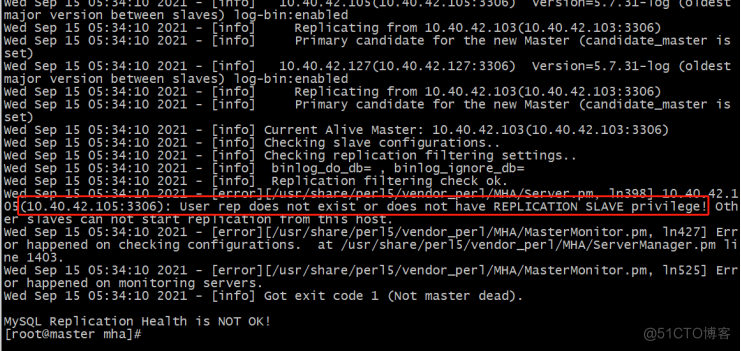
报错信息:
Node1(10.40.42.105)没有数据主从复制权限的用户rep,其实另一台node2(10.40.42.127)也没有添加rep用户.
有个问题思考:mysql的主从同步没有过滤mysql库,为什么user表没有同步?
解决:
node1和node2也创建rep用户。
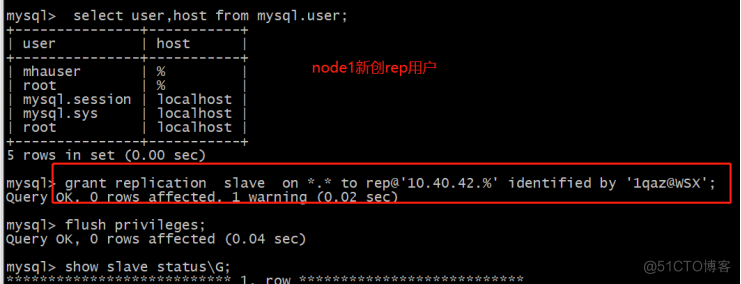
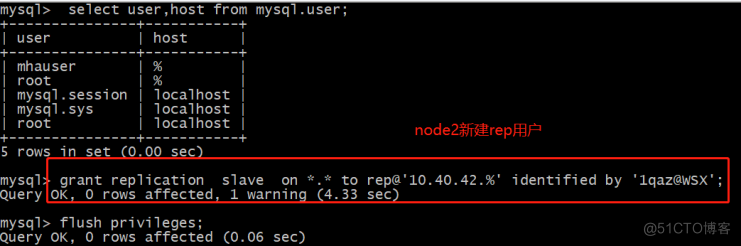
再次检查:
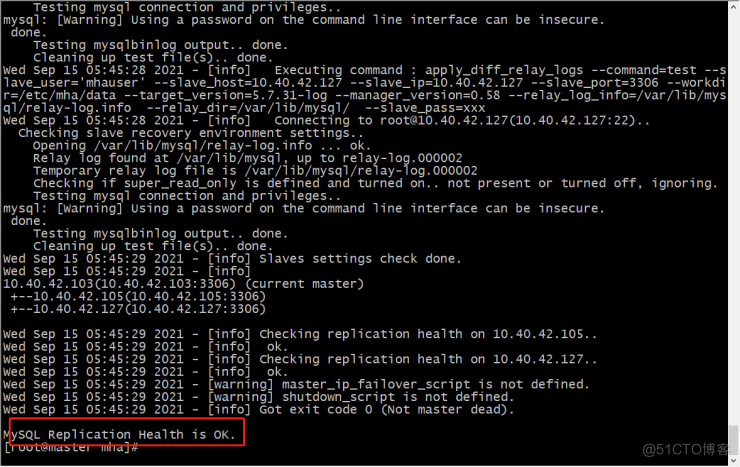
MHA Master节点创建虚拟vip:
#ip addr add 10.40.42.129/24 dev ens192

启动mha服务:
# nohup masterha_manager --conf=/etc/mha/mha.cnf --ignore_last_failover &
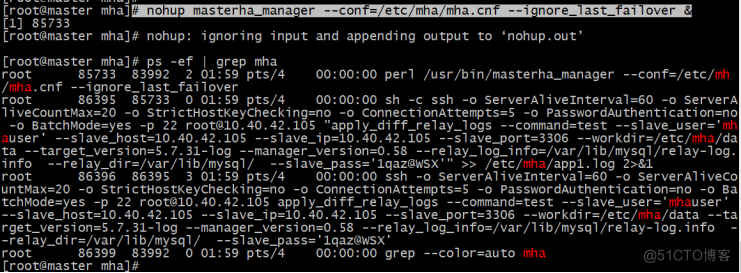
注意:mha服务可能会起来报错直接down掉。Ps -ef多看看。
Mha启动参数,根据需要自己添加:
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面我设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
检查MHA anager监控状态:
[root@master mha]# masterha_check_status --conf=/etc/mha/mha.cnf
mha (pid:85733) is running(0:PING_OK), master:10.40.42.103

测试node1通过虚拟vip连接数据库:
# mysql -uroot -p -h 10.40.42.129
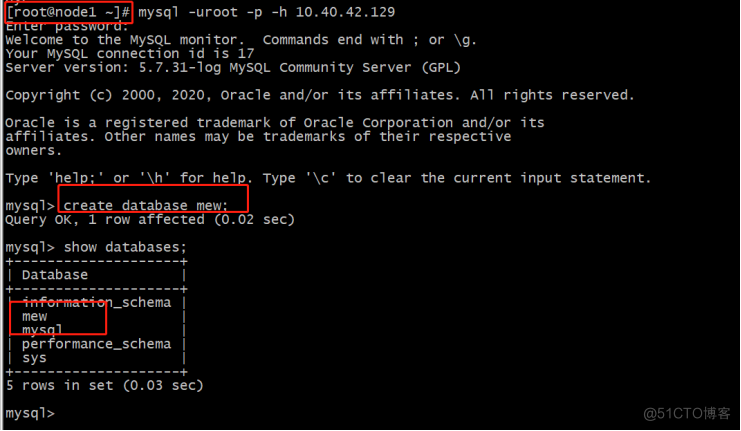
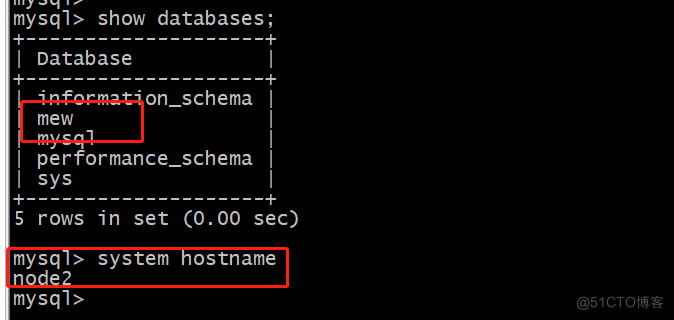
Node2 从库查看是否同步到mew库:
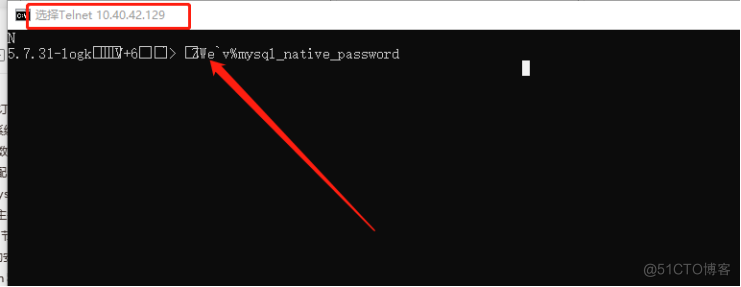
本地通过vip连接数据库:
本地telnet vip:port
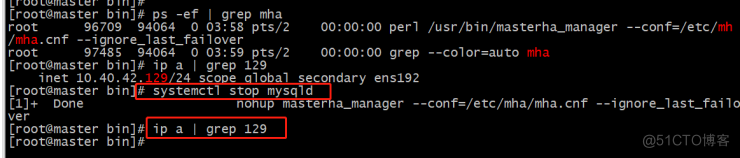
测试vip漂移:
数据库master节点stop:
[root@master bin]# systemctl stop mysqld
[1]+ Done nohup masterha_manager --conf=/etc/mha/mha.cnf --ignore_last_failover
[root@master bin]# ip a | grep 129
查看MHA manger的log:
[root@master bin]# tail -200f /etc/mha/app1.log
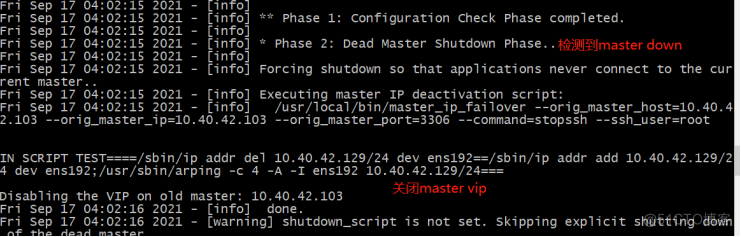
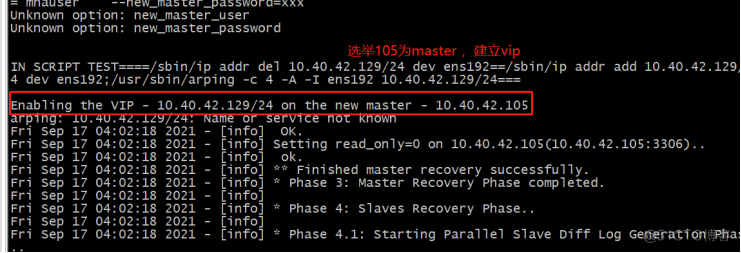
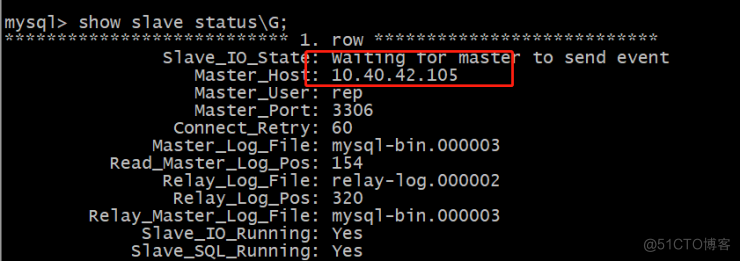
查看node2同步:
Node2从10.40.42.103变为10.40.42.105。
本地测试通过vip连接数据库:
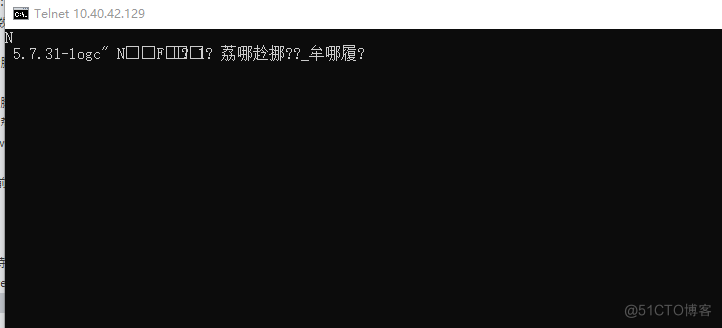
停止MHA 服务:
masterha_stop --conf=/etc/mha/mha.cnf

疑难点:
MHA至少三台,低于三台mha服务就会down。
错误脚本:
使用ifconfig添加vip,mha服务起不起来,一会是服务就down了,网上很多这样写的,全是错的。
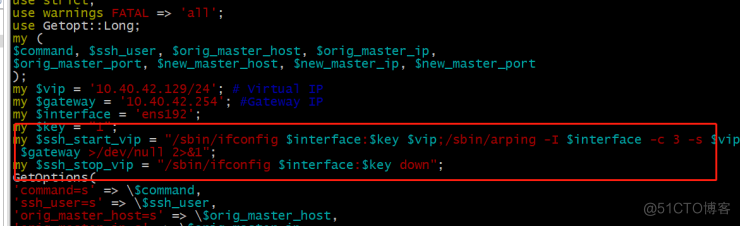
脚本参数错误:
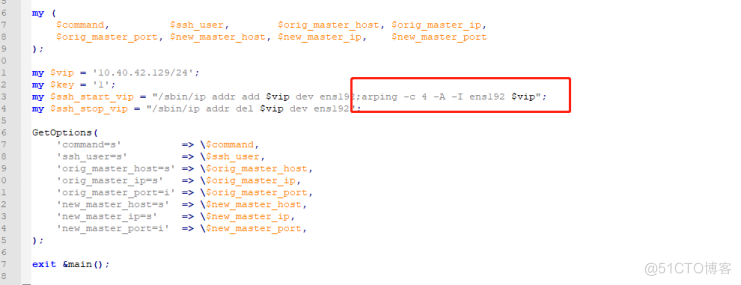
MHA服务启动成功,vip漂移成功,各但是本地ping/telnet不通mha的vip,需要手动执行下面圈起来的:
#arping -c 4 -A -I ens192 10.40.42.129
之后ping/telnet正常。
解决:脚本需要修改自定义个函数,自动刷新arping,即可自动完美漂移。