Prometheus+Grafana+AlterManager+钉钉报警 1.准备测试环境 服务器名称IP地址硬件要求服务部署 master10.0.0.101核2GPrometheus+Grafananode110.0.0.111核1Gnode_exporternode210.0.0.121核1Gnode_exporternode310.0.0.131核1Gn
Prometheus+Grafana+AlterManager+钉钉报警
1.准备测试环境
服务器名称 IP地址 硬件要求 服务部署 master 10.0.0.10 1核2G Prometheus+Grafana node1 10.0.0.11 1核1G node_exporter node2 10.0.0.12 1核1G node_exporter node3 10.0.0.13 1核1G node_exporter node4 10.0.0.14 1核1G node_exporter #master节点做hosts解析并分发到其他节点 vim /etc/hosts 10.0.0.10 master 10.0.0.11 node1 10.0.0.12 node2 scp -rp root@10.0.0.{11..12}:/etc/hosts2.安装Prometheus
#安装prometheus prometheus官网:https://prometheus.io/download/ 我们下载最新版prometheu即可 #解压软件包 tar xf prometheus-2.28.1.linux-amd64.tar.gz #打开解压软件包的目录 cd prometheus-2.28.1.linux-amd64/ #修改配置文件 vim prometheus.yml 修改最后 - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node-exporte' static_configs: - targets: ['10.0.0.11:9100','10.0.0.12:9100'] #启动软件 加& 等于后台运行 ./prometheus --config.file="prometheus.yml" & #浏览器输入10.0.0.10:9090即可
3.安装node-exporte
#安装node-exporte(node1,node2) prometheus官网:https://prometheus.io/download/ 我们下载最新版node_exporter即可 https://prometheus.io/download/#node_exporter #解压软件包 tar xf node_exporter-1.1.2.linux-amd64.tar.gz #打开解压软件包的目录 cd node_exporter-1.1.2.linux-amd64 #启动软件 加& 等于后台运行 ./node_exporter &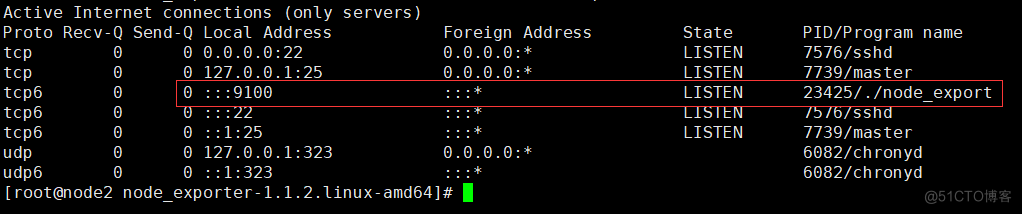
4.安装Grafana
#grafana出图 gtafana:插件/数据源(设置prometheus) #下载gtafana的rpm包 wget https://dl.grafana.com/oss/release/grafana-8.0.5-1.x86_64.rpm #yum安装gtafana yum localinstall grafana-8.0.5-1.x86_64.rpm -y #启动并且设置为开机自启 systemctl enable grafana-server.service systemctl start grafana-server.service
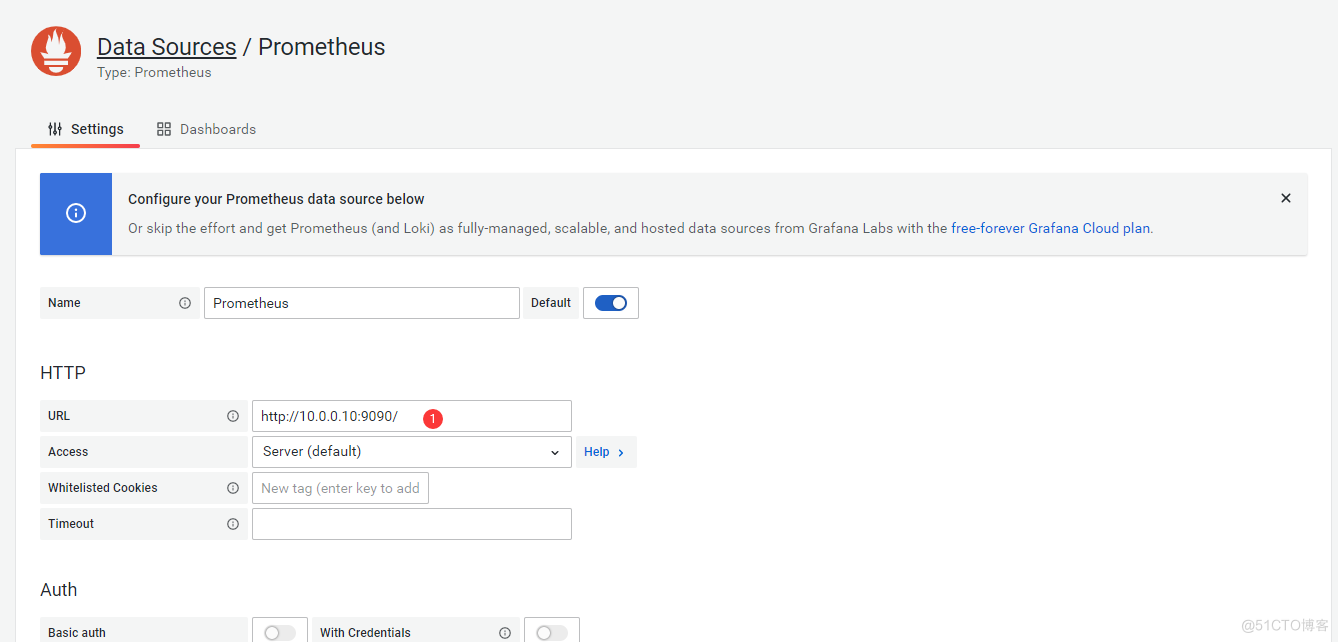
5.导入dashboard模板
#进入官网下载模板 官网:www.grafana.com 模板页面:https://grafana.com/grafana/dashboards #示例用的模板为 8677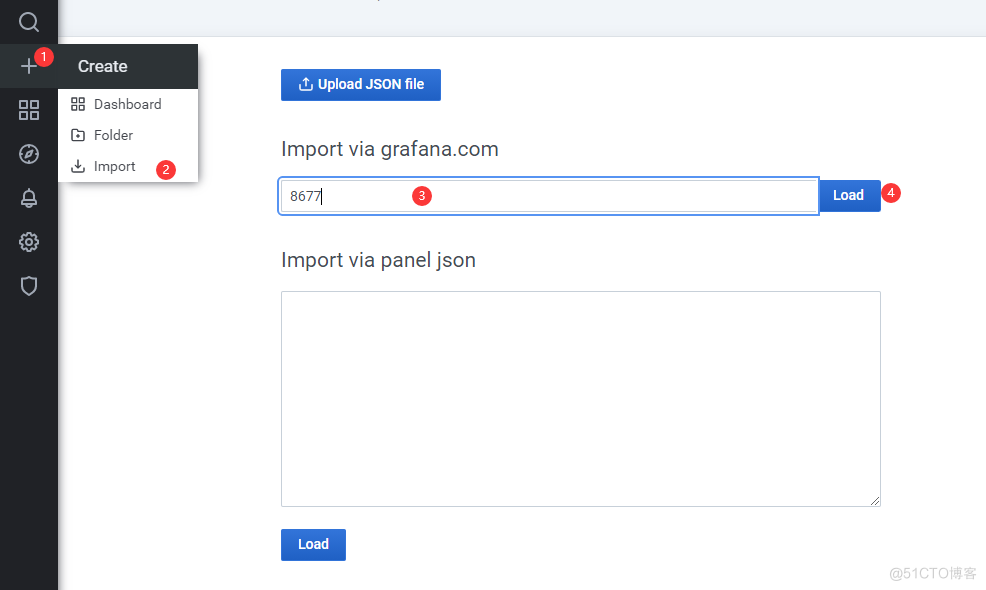
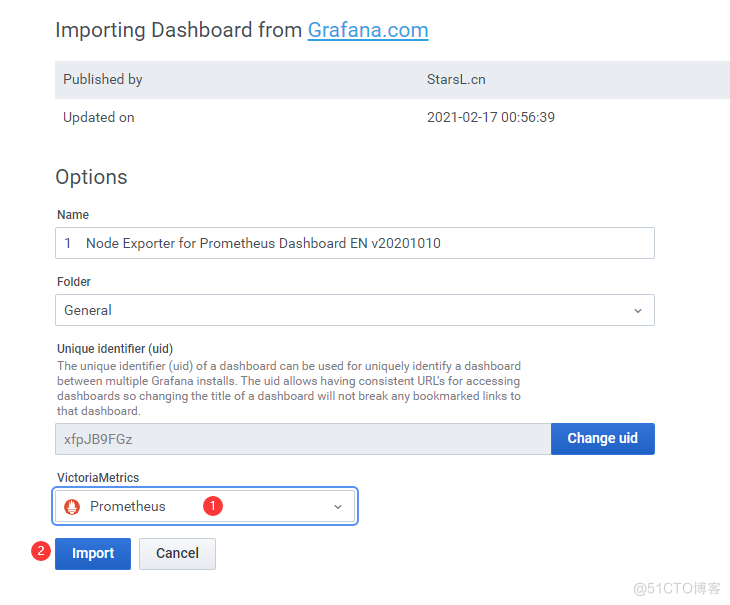
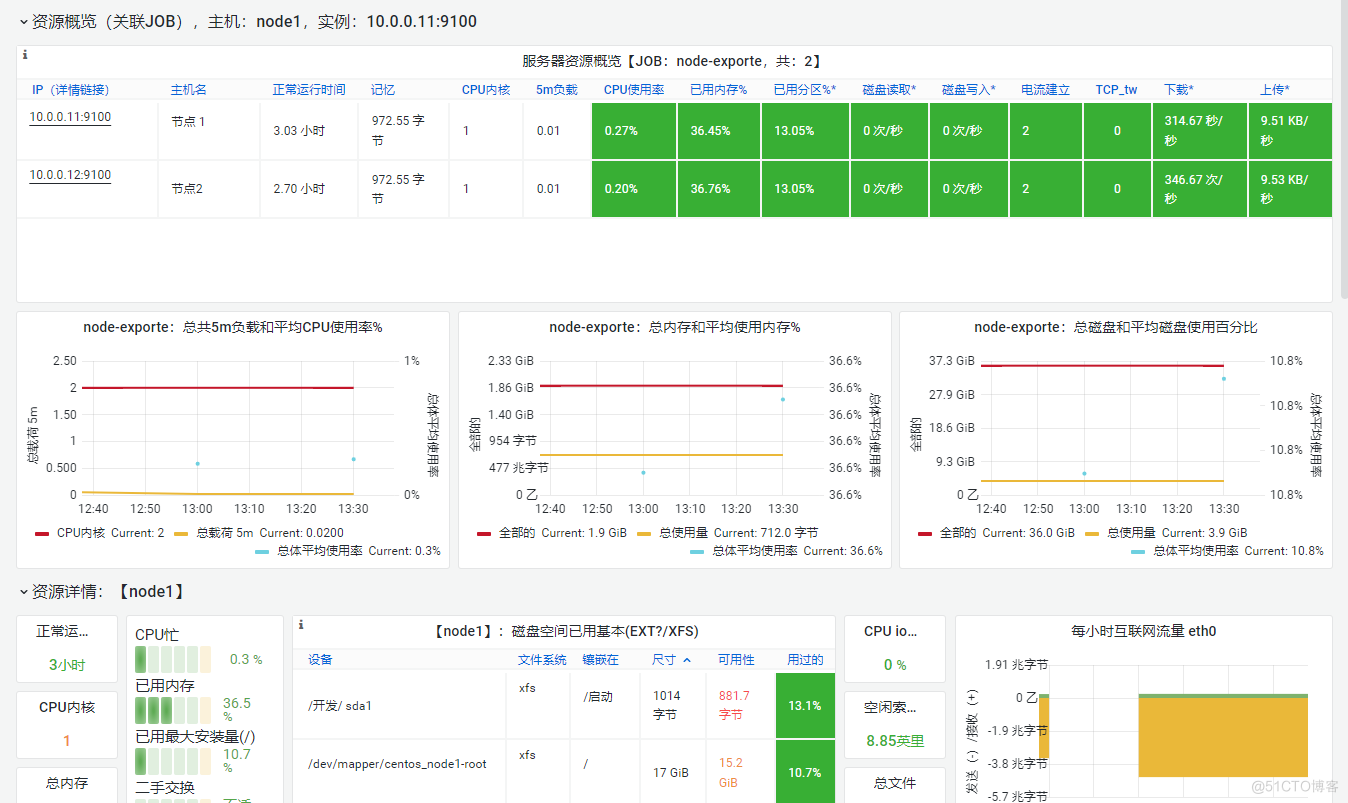
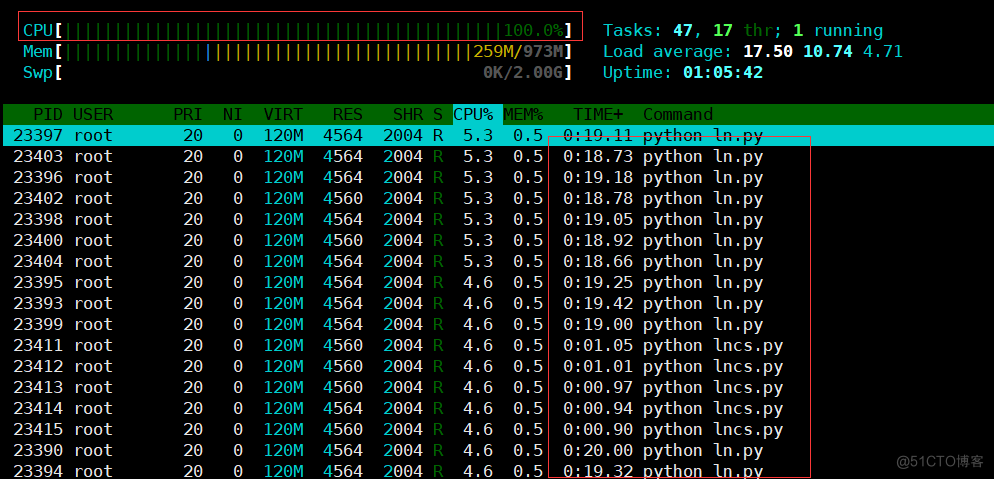
6.模拟CPU沾满,查看Granafna是否能监控到
#编写python循环 vim lncs.py #!/bin/python a = 0 while 1: a+=1 #执行 python lncs.py &
7.Prometheus自动发现
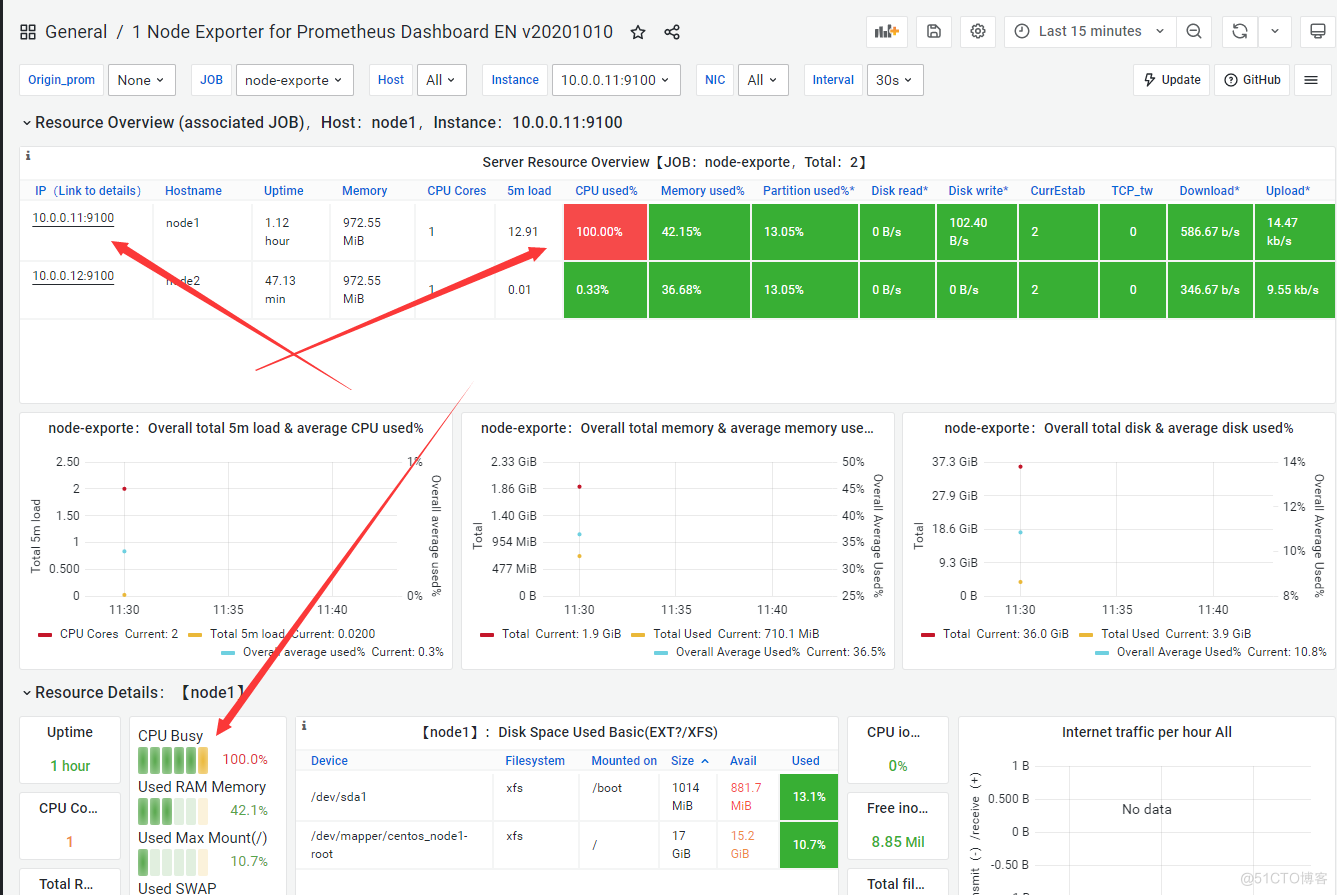
#master节点做hosts解析并分发到其他节点 vim /etc/hosts 10.0.0.10 master 10.0.0.11 node1 10.0.0.12 node2 10.0.0.13 node3 10.0.0.14 node4 scp -rp root@10.0.0.{11..14}:/etc/hosts #部署cadvisor prometheus自动发现 修改配置文件 [root@master prometheus-2.28.1.linux-amd64]# vim prometheus.yml - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node-exporte' static_configs: - targets: ['10.0.0.11:9100','10.0.0.12:9100'] - job_name: 'cadvisor' file_sd_configs: - files: - job/server.json refresh_interval: 10s #创建job文件和server.json文件 mkdir job cd job vim server.json [ { "targets": ["10.0.0.13:9100","10.0.0.14:9100"] } ] #先结束再重启 ps -ef|grep prom kill ./prometheus --config.file="prometheus.yml" & ##切记第一次做自动发现的时候是需要重新启动prometheus.yml文件的,之后只需要修改json文件即可. #下面是自动发现后的效果.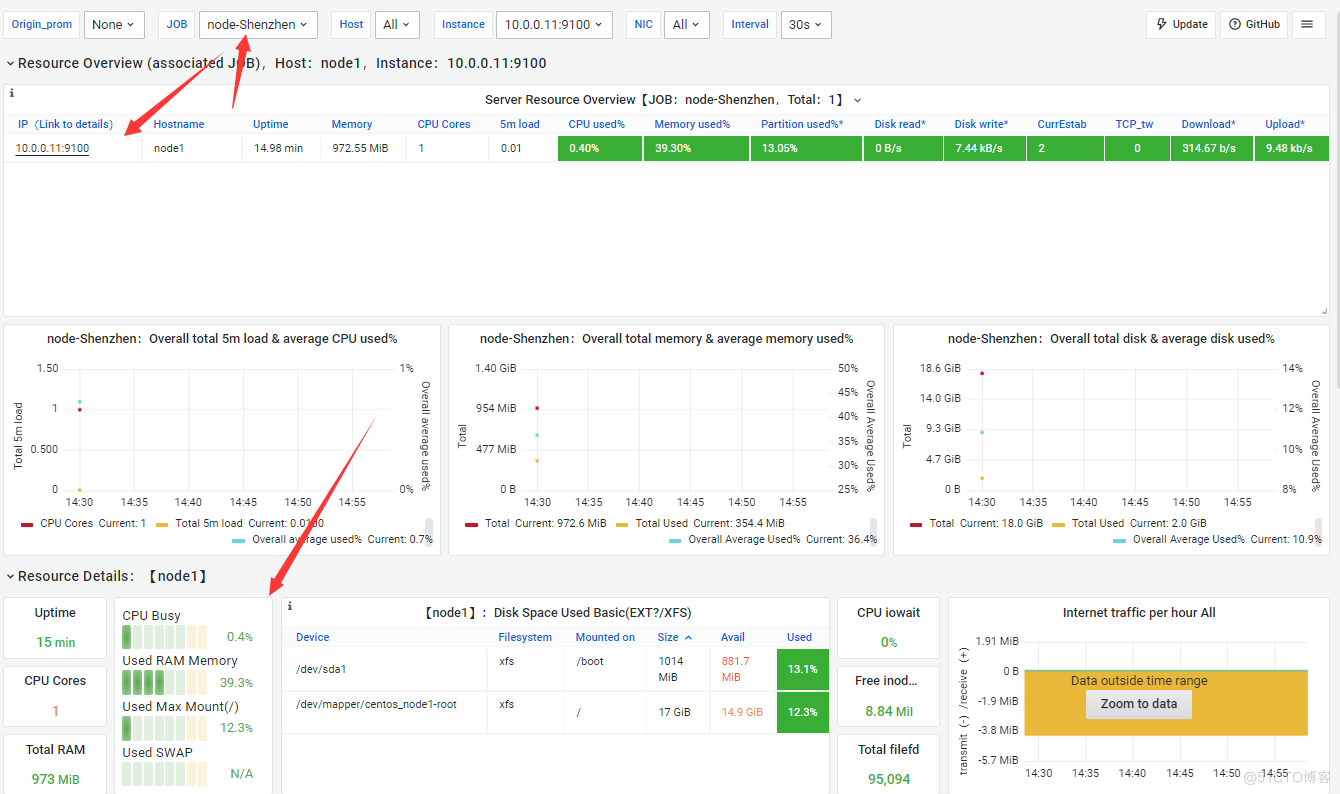
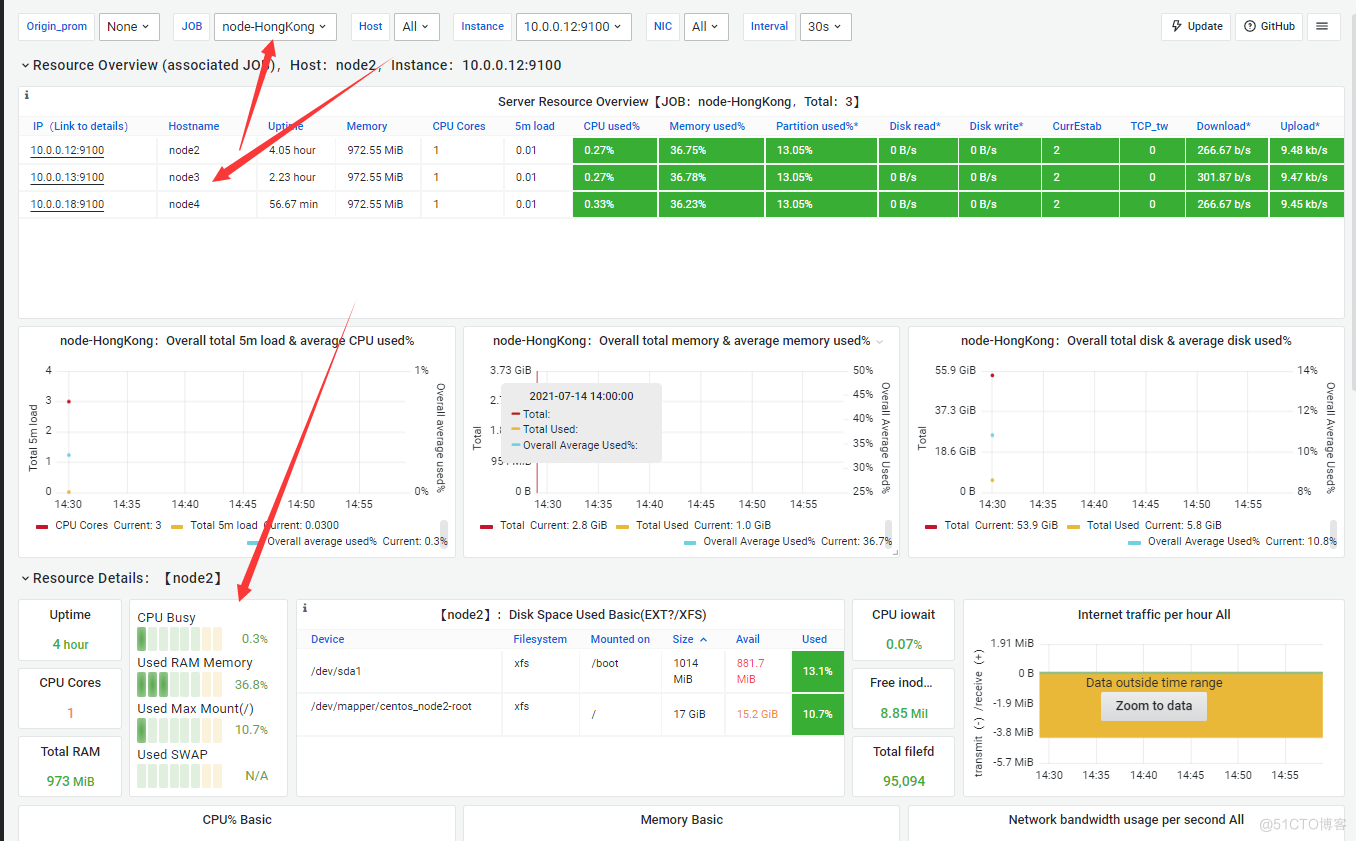
8.Prometheus及node_exporte启动问题
Prometheus和node_exporter本身启动非常简单的,但是在实际场景有时还是会遇到机房断电或者重启的情况,这样当重新启动系统时,Prometheus和node_exporter就被关掉了又需要手动启动程序.因此最好是设置为开机自启动.8.1 方法一:简单粗暴,写入rc.local
在/etc/rc.local文件中编辑需要执行的脚本或者命令 /opt/node_exproter/node_exproter 如果将命令写成脚本,在rc.local执行脚本的话,还需要给这个脚本赋予可执行权限哦 /start_node_exporter.sh chmod +x start_node_exporter.sh8.2 方法二:设置为服务,使用systemctl来管理
1.下载prometheus和node_exporter,目录自定义 2.创建node_exporter组合用户,用于运行node_exporter和prometheus(也可以不创建,不会有影响的) 3.创建一个prometheus.service文件/node_exporter.service文件 4.启动,并且配置开机启动创建Prometheus组和用户
#创建Prometheus组和用户 sudo groupadd -r prometheus sudo useradd -r -g prometheus -s /sbin/nologin -M -c "prometheus Daemons" prometheus创建services文件
##创建services文件 #注意:编写以下内容(如果没创建prometheus组合用户,则Service的User和Group就不用写): #Prometheus.service vim /etc/systemd/system/prometheus.service [Unit] Description=Prometheus Monitoring System Documentation=Prometheus Monitoring System #prometheus的路径,根据自己程序所放置的路径填写 [Service] ExecStart=/opt/prometheus/prometheus \ --config.file=/opt/prometheus/prometheus.yml \ --web.listen-address=:9090 [Install] WantedBy=multi-user.target #node_exporter.service vim /etc/systemd/system/node_exporter.service [Unit] Description=node_exporter Monitoring System Documentation=node_exporter Monitoring System After=network.target #node_exporter的路径,根据自己程序所放置的路径填写 [Service] ExecStart=/opt/node_exporter/node_exporter \ --web.listen-address=:9100 \ [Install] WantedBy=multi-user.targetsystemctl管理prometheus和node_exporter
systemctl daemon-reload systemctl start prometheus #开启服务prometheus systemctl enable prometheus #将服务设置为开机自启动 systemctl daemon-reload systemctl start node_exporter #开启服务node_exporter systemctl enable node_exporter #将服务设置为开机自启动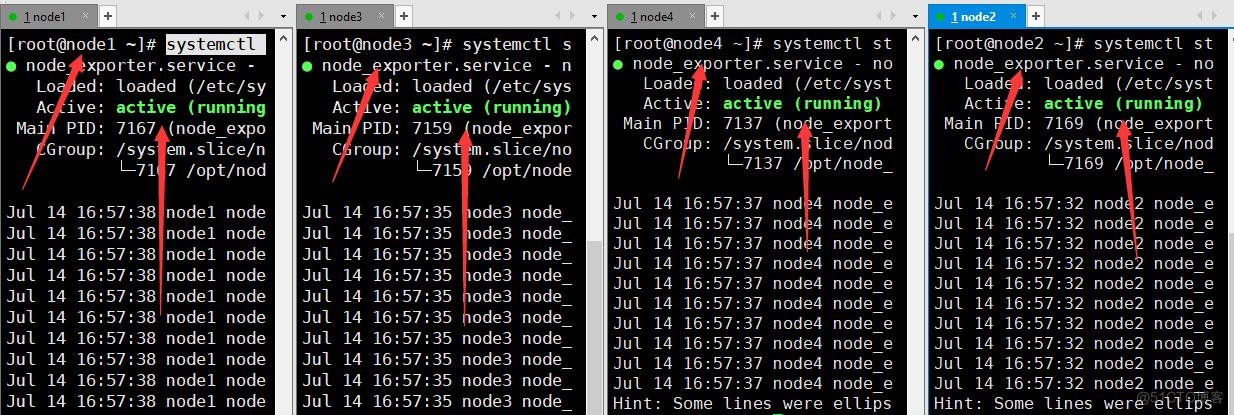
9.AlterManager邮件报警
9.1 安装AlterManager
#alterManager邮件报警 先下载软件包到/opt并且解压出来 https://prometheus.io/download/#alertmanager tar xf alertmanager-0.22.2.linux-amd64.tar.gz cd alertmanager-0.22.2.linux-amd64.tar.gz cp alertmanager.yml alertmanager.yml.bak #编写配置文件 vim alertmanager.yml global: resolve_timeout: 5m smtp_from: 'xxxxxxxx@qq.com' smtp_smarthost: 'smtp.qq.com:465' smtp_auth_username: 'xxxxxxxx@qq.com' smtp_auth_password: 'xxxxxxxxxxxxxxxx' #邮箱授权码 smtp_require_tls: false smtp_hello: 'qq.com' route: group_by: ['alertname'] group_wait: 5s group_interval: 5s repeat_interval: 5m receiver: 'email' receivers: - name: 'email' email_configs: - to: 'xxxxxxxx@qq.com' send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] #启动 ./alertmanager --config.file="alertmanager.yml" &9.2 prometheus配置报警规则
#去prometheus文件目录下 修改prometheus的配置文件 vim prometheus.yml # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 10.0.0.10:9093 #此ip地址为本机ip地址 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "/opt/prometheus/hy/node_Shenzhen.yml" #设置报警规则文件 # - "second_rules.yml" #编写报警规则 [root@master]# vim /opt/prometheus/hy/node_down.yml igroups: - name: node-up rules: - alert: node-up expr: up{job="node-exporter"} == 0 for: 15s labels: severity: 1 team: node annotations: summary: "{{ $labels.instance }} 已停止运行超过 15s!" #结束prometheus并且重新启动 systemctl restart prometheus systemctl status prometheus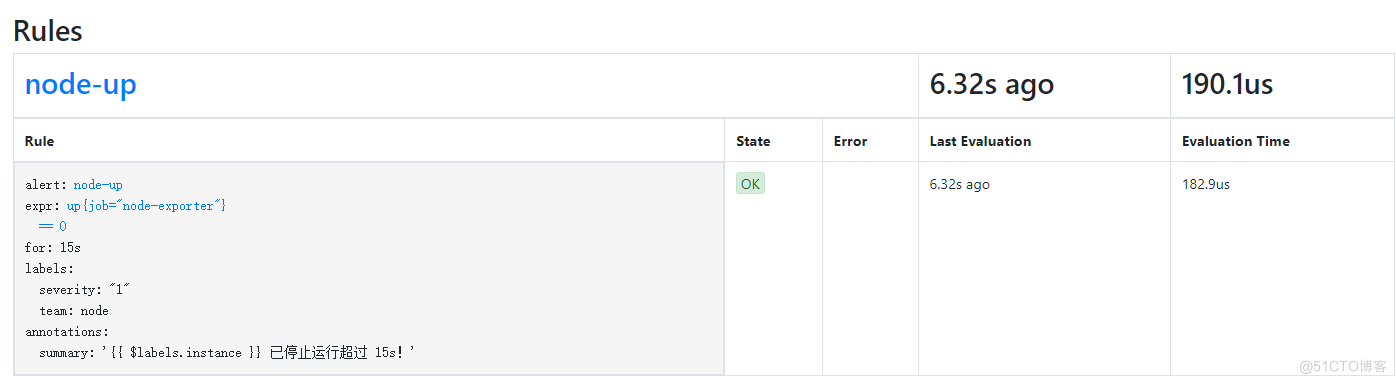
9.3 模拟宕机规则自动触发并且发送邮件
#node1[10.0.0.11] systemctl stop node_exporte # 停止服务后,等待 15s 之后可以看到 Prometheus target 里面 node-exproter 状态为 unhealthy 状态,等待 15s 后,alert 页面由绿色 node-up (0 active) Inactive 状态变成了黄色 node-up (1 active) Pending 状态,继续等待 15s 后状态变成红色 Firing 状态,向 AlertManager 发送报警信息,此时 AlertManager 则按照配置规则向接受者发送邮件告警.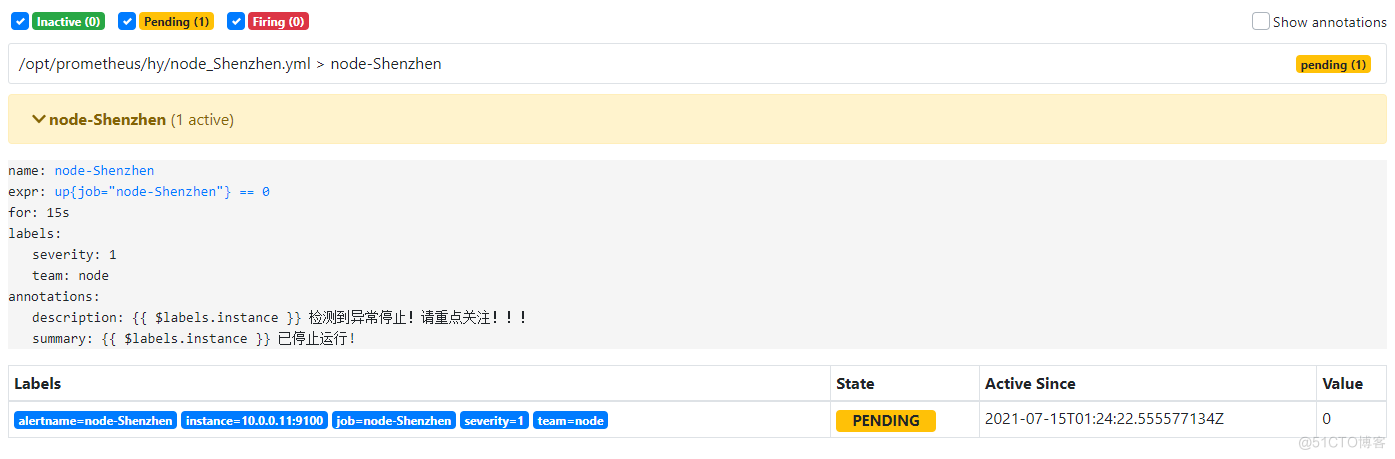
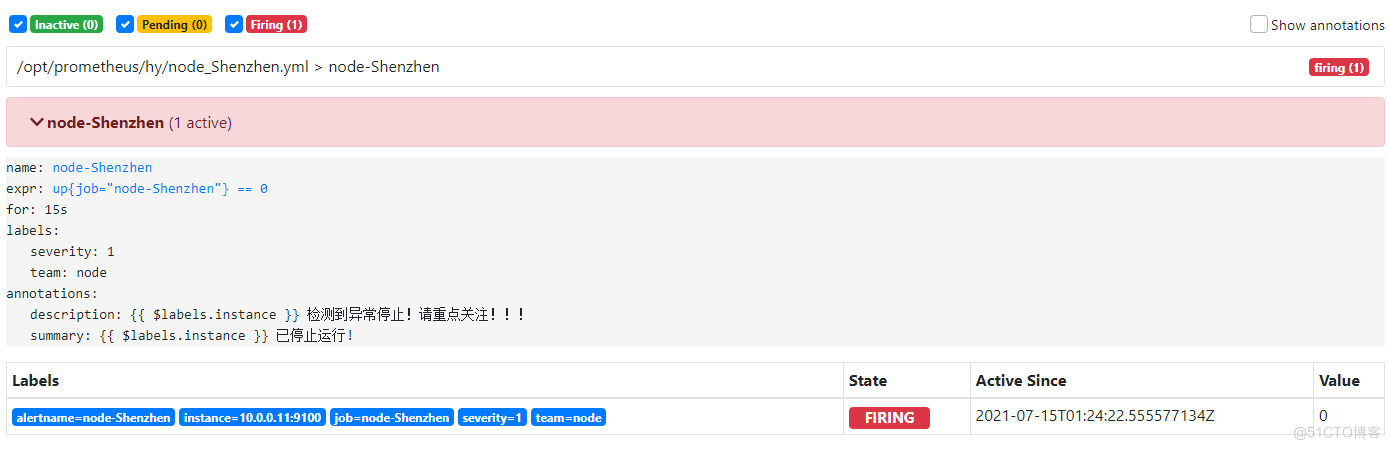
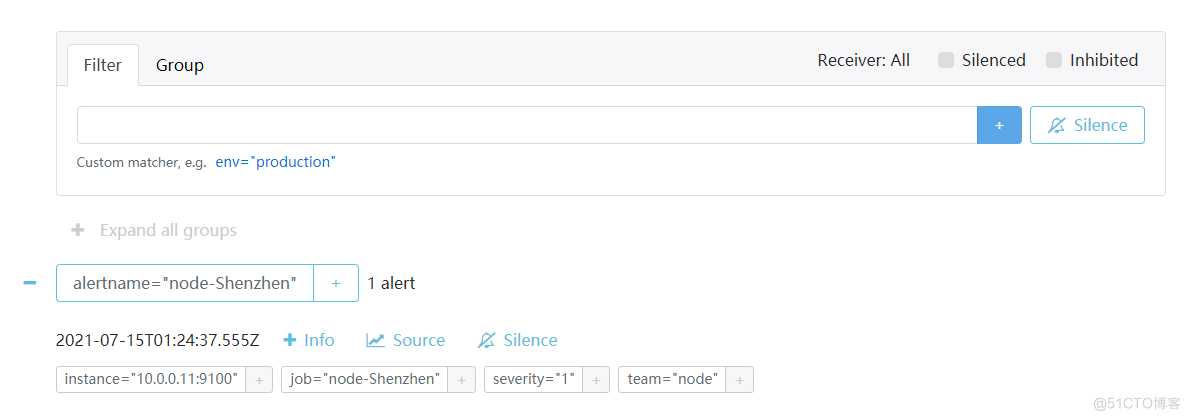
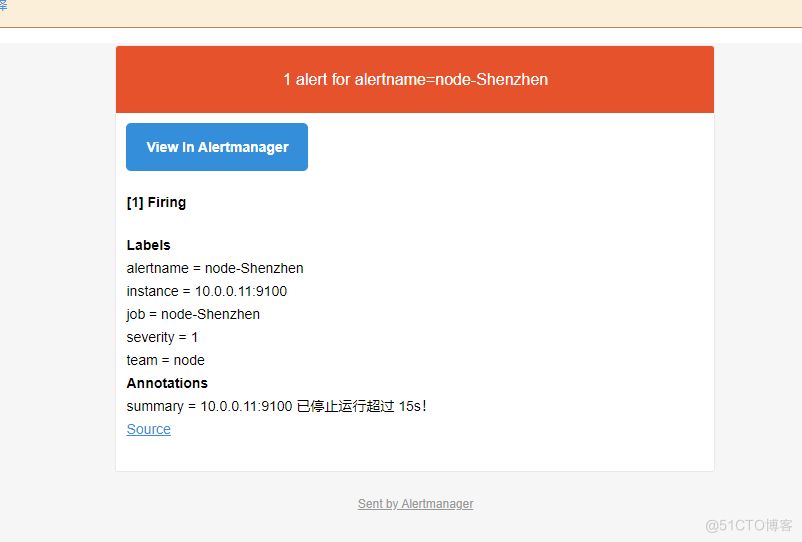
9.4 报警成功,把AlterManager设置为systemctl启动
#编写配置文件 vim /etc/systemd/system/altermanager.service [Unit] Description=AlterManager Monitoring System Documentation=AlterManager Monitoring System [Service] ExecStart=/opt/alertmanager/alertmanager \ --config.file=/opt/alertmanager/alertmanager.yml \ --web.listen-address=:9093 [Install] WantedBy=multi-user.target #启动服务 systemctl daemon-reload systemctl start alertmanager #开启服务alertmanager systemctl enable alertmanager #将服务设置为开机自启动
10.AlterManager钉钉报警
10.1 配置钉钉报警机器人
#先进入钉钉创建报警群组--添加报警机器人--创建webhook--保存自动生成的秘钥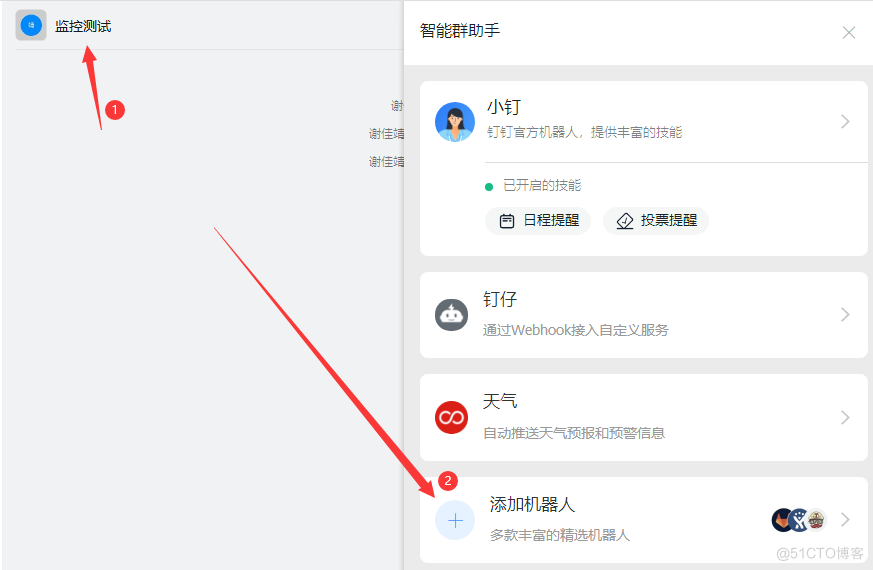

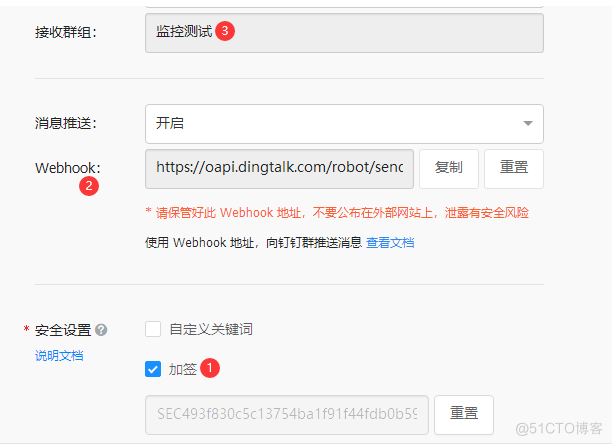
10.2 下载钉钉报警插件并且编写配置文件
#访问github下载最新的插件(prometheus-webhook-dingtalk) https://github.com/timonwong/prometheus-webhook-dingtalk/releases/tag/v1.4.0 #解压并且修改配置文件 tar xf prometheus-webhook-dingtalk-1.4.0.linux-amd64.tar.gz #修改配置文件 vim config.example.yml targets: webhook1: url: https://oapi.dingtalk.com/robot/send?access_token=218f5850a3****************************************************** #Webhook地址 # secret for signature secret: SEC493f830********************************************************#秘钥 # webhook2: # url: https://oapi.dingtalk.com/robot/send?access_token= # webhook_legacy: # url: https://oapi.dingtalk.com/robot/send?access_token= # # Customize template content # message: # # Use legacy template # title: '{{ template "legacy.title" . }}' # text: '{{ template "legacy.content" . }}' # webhook_mention_all: # url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx # mention: # all: true webhook_mention_users: url: https://oapi.dingtalk.com/robot/send?access_token=218f5850a3****************************************************** #Webhook地址 mention: mobiles: ['钉钉账户/手机号码']10.3 配置Altermanater配置文件
#再配置altermanater的配置文件 vim alertmanager.yml global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 5s group_interval: 5s repeat_interval: 5m receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://localhost:8060/dingtalk/webhook1/send' #多次翻车 send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']10.4 模拟宕机,测试钉钉能否自动报警
#然后启动dingtalk,alertmanager,Prometheus就行了 systemctl restart prometheus systemctl restart alertmanager ./prometheus-webhook-dingtalk --config.file="config.yml" #node1[10.0.0.11] systemctl stop node_exporte ##下面就是报警信息以及解决信息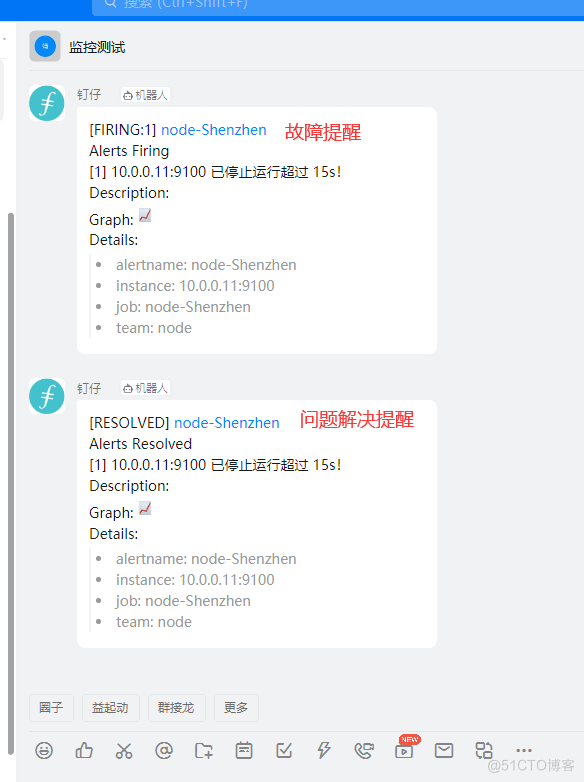
10.5 报警成功,把钉钉报警服务设置为systemctl启动
[Unit] Description=Prometheus-webhook-dingtalk Monitoring System Documentation=Prometheus-webhook-dingtalk Monitoring System [Service] ExecStart=/opt/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk \ --config.file=/opt/prometheus-webhook-dingtalk/config.yml \ --web.listen-address=:8060 [Install] WantedBy=multi-user.target #启动服务 systemctl daemon-reload systemctl start prometheus-webhook-dingtalk #开启服务prometheus-webhook-dingtalk systemctl enable prometheus-webhook-dingtalk #将服务设置为开机自启动11.总结
至此Prometheus+Grafana+AlterManager+钉钉报警基础架构就已经搭建成功了.12.扩展
12.1 自定义配置prometheus报警规则
修改Prometheus配置文件
#编辑Prometheus配置文件 [root@master prometheus]# vim prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: - 10.0.0.10:9093 rule_files: - "/opt/prometheus/conf/*.yml" scrape_configs: - job_name: 'prometheus' scrape_interval: 10s static_configs: - targets: ['localhost:9090'] - job_name: 'DMC_HOST' file_sd_configs: - files: - job/server.json refresh_interval: 10s参数形式配置主机列表
#参数形式配置主机列表[Prometheus自动发现主机] vim /opt/prometheus/job/server.json [ { "targets": ["10.0.0.11:9100"], "labels": { "service": "node_Shenzhen" } }, { "targets": ["10.0.0.12:9100","10.0.0.13:9100","10.0.0.14:9100"], "labels": { "service": "node_HongKong" } } ]编写多样化报警规则
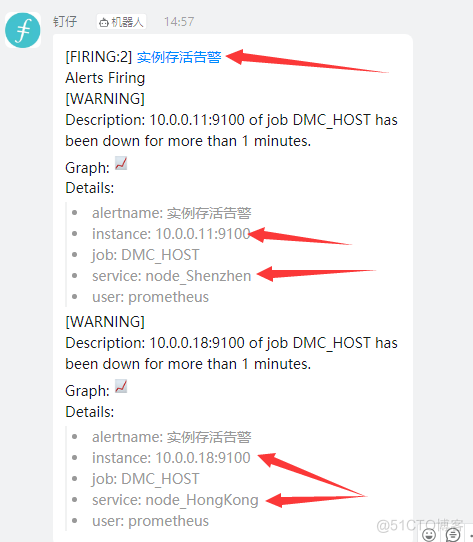
#服务器存活报警规则 vim /opt/prometheus/conf/node_down.yml groups: - name: 实例存活告警规则 rules: - alert: 实例存活告警 expr: up == 0 for: 1m labels: user: prometheus severity: warning annotations: description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes." #内存报警规则 vim /opt/prometheus/conf/memory_over.yml groups: - name: 内存报警规则 rules: - alert: 内存使用率告警 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80 for: 1m labels: user: prometheus severity: warning annotations: description: "服务器: 内存使用超过80%!(当前值: {{ $value }}%)" #磁盘报警规则 vim /opt/prometheus/conf/disk_over.yml groups: - name: 磁盘报警规则 rules: - alert: 磁盘使用率告警 expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80 for: 1m labels: user: prometheus severity: warning annotations: description: "服务器: 磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)" #CPU报警规则 vim /opt/prometheus/conf/cpu_over.yml groups: - name: CPU报警规则 rules: - alert: CPU使用率告警 expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 90 for: 1m labels: user: prometheus severity: warning annotations: description: "服务器: CPU使用超过90%!(当前值: {{ $value }}%)"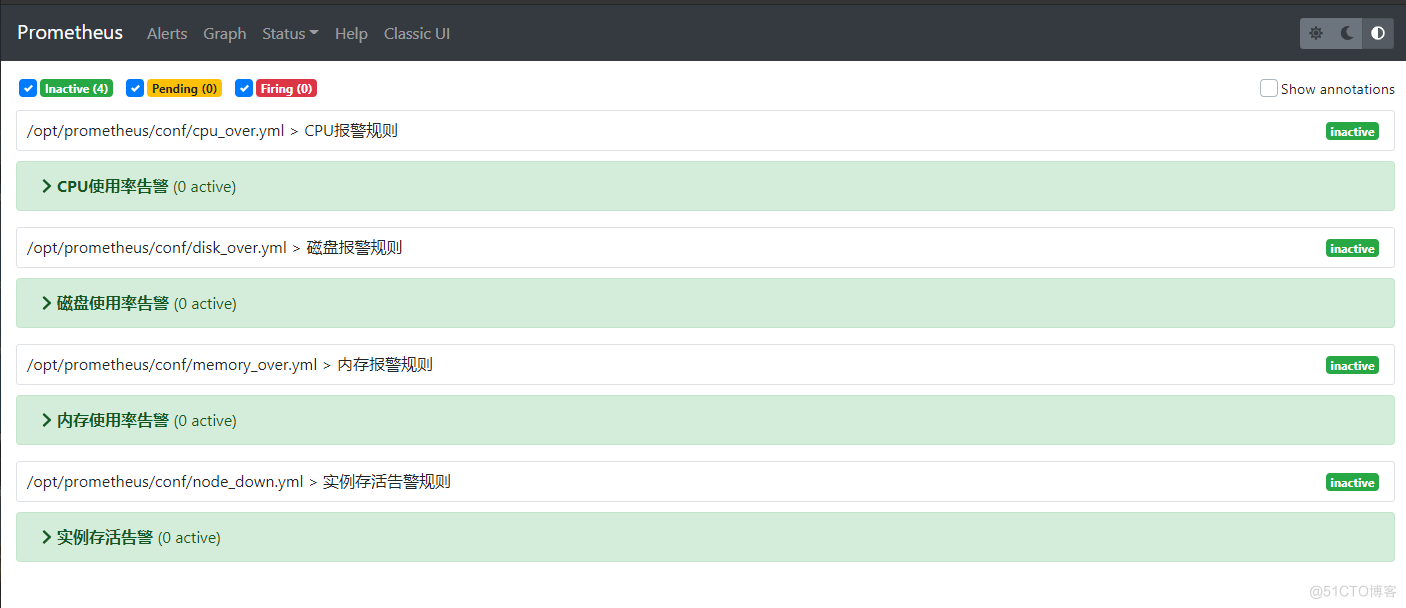
测试新编写的报警规则是否能正常使用
#node1[10.0.0.11] systemctl stop node_exporter #node4[10.0.0.18] systemctl stop node_exporter