文档部署时k8s版本-kubernetes 1.20,docker 版本Docker version 20.10.0
原文
安装前准备
0、如果没有虚拟机,windows电脑使用vmvare,mac电脑使用virtual-box 1、准备3台,2G或更大内存,2核或以上CPU,20G以上硬盘 物理机或云主机或虚拟机 2、系统centos 7.x
环境准备(在3台机运行)
#根据规划设置主机名hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
#在添加hosts
cat >> /etc/hosts << EOF
192.168.56.107 master
192.168.56.108 node1
192.168.56.109 node2
EOF
#本地host同样添加,觉得麻烦的同学可以下载switch-host软件管理本地域名解析
192.168.0.120 master
192.168.0.178 node1
192.168.0.49 node2
#关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
#关闭selinux(在3台机运行)
sed -i 's/enforcing/disabled/' /etc/selinux/config && setenforce 0
#关闭swap
swapoff -a && sed -ri 's/.*swap.*/#&/' /etc/fstab
#时间同步
yum install ntpdate -y && ntpdate time.windows.com
#配置内核参数,将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
安装Docker(在3台机运行)
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3: 更新并安装Docker-CE
sudo yum makecache fast
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo systemctl start docker && systemctl enable docker
# 可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://s2q9fn53.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload && sudo systemctl restart docker
安装kubelet、kubeadm、kubectl(在3台机运行)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install kubectl kubelet kubeadm && systemctl enable kubelet && systemctl start kubelet
部署kubernetes Master
#初始化k8s集群kubeadm init --kubernetes-version=1.20.0 \
--apiserver-advertise-address=192.168.56.107 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.10.0.0/16 --pod-network-cidr=10.122.0.0/16
#提示initialized successfully!表示初始化成功
##注意提示:to start using you cluster,you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#按提示执行以上三条命令(控制台输出信息里面复制的)
#执行完后可以运行,查看node节点情况
kubectl get nodes
#还有一条提示:
#then you can join any number of worker nodes by running the following on each as root
#翻译:然后,您可以通过在每个worker节点上以root身份运行以下命令来连接任意数量的worker节点
#接着把提示如下的语句复制到node节点运行
kubeadm join 192.168.56.107:6443 --token ...
以上条命令(控制台输出信息里面复制的)
#执行下面命令,使kubectl可以自动补充,看你是否需要,选择性执行
source <(kubectl completion bash)
#查看node节点
kubectl get node
#当前node状态均为noReady,属于正常
kubectl get node
#node节点为NotReady,因为corednspod没有启动,缺少网络pod
部署CNI网络插件
#安装flannel网络插件kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
#发送admin.conf到所有节点,可以在任何一个节点管理集群
scp /etc/kubernetes/admin.conf root@node1:/etc/kubernetes/admin.conf
scp /etc/kubernetes/admin.conf root@node2:/etc/kubernetes/admin.conf
#在node节点上加入环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
source /etc/profile
#执行完成以后可以在任意node节点上管理集群,查看节点是否正常
kubectl get nodes
Dashboard简介
在 Kubernetes 社区中,有一个很受欢迎的 Dashboard 项目,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。用户可以用 Kubernetes Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。

部署Dashboard
原文
gi t项目地址
当前部署dashboard版本:v2.2.0,注意检查dashboard版本与kubernetes版本兼容性:
执行yaml文件直接部署
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml查看dashboard运行状态,以deployment方式部署,运行2个pod及2个service:
[root@master test]# kubectl -n kubernetes-dashboard get podsNAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-79c5968bdc-jzdmw 1/1 Running 0 3d12h
kubernetes-dashboard-7448ffc97b-c58w2 1/1 Running 3 5h22m
[root@master test]# kubectl -n kubernetes-dashboard get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.10.180.25 <none> 8000/TCP 3d12h
kubernetes-dashboard NodePort 10.10.238.55 <none> 443:30443/TCP 3d12h
访问dashboard
这里作为演示,使用nodeport方式将dashboard服务暴露在集群外,指定使用30443端口,可自定义:
kubectl patch svc kubernetes-dashboard -n kubernetes-dashboard \-p '{"spec":{"type":"NodePort","ports":[{"port":443,"targetPort":8443,"nodePort":30443}]}}'
查看暴露的service,已修改为nodeport类型:
[root@master test]# kubectl -n kubernetes-dashboard get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.10.180.25 <none> 8000/TCP 3d13h
kubernetes-dashboard NodePort 10.10.238.55 <none> 443:30443/TCP 3d13h
#或者下载yaml文件手动修改service部分
spec:type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30443
selector:
k8s-app: kubernetes-dashboard
登陆dashboard
浏览器访问dashboard:
https://<any_node_ip>:30443Dashboard 支持 Kubeconfig 和 Token 两种认证方式,我们这里选择Token认证方式登录。
官方参考文档:
https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
创建dashboard-adminuser.yaml:
cat > dashboard-adminuser.yaml << EOFapiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
创建登陆用户
kubectl apply -f dashboard-adminuser.yaml说明:上面创建了一个叫admin-user的服务账号,并放在kubernetes-dashboard 命名空间下,并将cluster-admin角色绑定到admin-user账户,这样admin-user账户就有了管理员的权限。默认情况下,kubeadm创建集群时已经创建了cluster-admin角色,我们直接绑定即可。
查看admin-user账户的token
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')把获取到的Token复制到登录界面的Token输入框中,成功登陆dashboard
通过ingress方式将dashboard暴露到集群外是更好的选择,需要自行部署,参考:
trafik
contour
nginx-ingress
metallb
使用dashboard
源文
创建示例deployment,使用nodeport向集群外暴露服务。
yaml编写参考: https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
https://kubernetes.io/docs/concepts/services-networking/service/#nodeport
默认视图在default命名空间,可自行切换namespace,点击右上角+号创建资源:

有三种方式创建资源,这里使用第一种方式部署一个简单的nginx-app,设置2个副本,nodePort方式暴露服务,粘贴已经编写好的yaml文件点击upload:
apiVersion: apps/v1kind: Deployment
metadata:
name: my-nginx-app
spec:
selector:
matchLabels:
run: my-nginx-app
replicas: 2
template:
metadata:
labels:
run: my-nginx-app
spec:
containers:
- name: my-nginx-app
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: my-nginx-app
labels:
run: my-nginx-app
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30080
selector:
run: my-nginx-app
集群外浏览器访问应用:http://<node_ip>:30080/
点击deployment可以增加应用副本,查看和更新yaml配置,以及删除整个应用:
dashboard超时
默认dashboard登录超时时间是15min,可以为dashboard容器增加-- token-ttl参数自定义超时时间: 参考:https://github.com/kubernetes/dashboard/blob/master/docs/common/dashboard-arguments.md
修改yaml配置超时时间12h:
$ more recommended.yaml...
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
- --token-ttl=43200
...
更新配置:
kubectl apply -f recommended.yaml其他说明:
整个dashboard可以对大部分资源进行性能监控,修改和删除操作,可自行体验
dashboard支持删除node节点,可以选择cluster,node列表中执行操作
dashboard支持暗黑模式,可以在settings中设置
原文
简介
Prometheus介绍
Prometheus 是一套开源的监控 & 报警 & 时间序列数据库的组合,起始是由 SoundCloud 公司开发的。成立于 2012 年,之后许多公司和组织接受和采用 prometheus,他们便将它独立成开源项目,并且有公司来运作.该项目有非常活跃的社区和开发人员,目前是独立的开源项目,任何公司都可以使用它,2016 年,Prometheus 加入了云计算基金会,成为 kubernetes 之后的第二个托管项目.google SRE 的书内也曾提到跟他们 BorgMon 监控系统相似的实现是 Prometheus。现在最常见的 Kubernetes 容器管理系统中,通常会搭配 Prometheus 进行监控
注意:Prometheus-operator 已经改名为 Kube-promethues
Kubernetes Operator介绍
在 Kubernetes 的支持下,管理和伸缩 Web 应用、移动应用后端以及 API 服务都变得比较简单了。其原因是这些应用一般都是无状态的,所以 Deployment 这样的基础 Kubernetes API 对象就可以在无需附加操作的情况下,对应用进行伸缩和故障恢复了。
而对于数据库、缓存或者监控系统等有状态应用的管理,就是个挑战了。这些系统需要应用领域的知识,来正确的进行伸缩和升级,当数据丢失或不可用的时候,要进行有效的重新配置。我们希望这些应用相关的运维技能可以编码到软件之中,从而借助 Kubernetes 的能力,正确的运行和管理复杂应用。
Operator 这种软件,使用 TPR (第三方资源,现在已经升级为 CRD) 机制对 Kubernetes API 进行扩展,将特定应用的知识融入其中,让用户可以创建、配置和管理应用。和 Kubernetes 的内置资源一样,Operator 操作的不是一个单实例应用,而是集群范围内的多实例。
Prometheus Operator 介绍
Kubernetes 的 Prometheus Operator 为 Kubernetes 服务和 Prometheus 实例的部署和管理提供了简单的监控定义。
安装完毕后,Prometheus Operator 提供了以下功能:
创建/毁坏: 在 Kubernetes namespace 中更容易启动一个 Prometheus 实例,一个特定的应用程序或团队更容易使用Operator。
简单配置: 配置 Prometheus 的基础东西,比如在 Kubernetes 的本地资源 versions, persistence, retention policies, 和 replicas。
Target Services 通过标签: 基于常见的 Kubernetes label 查询,自动生成监控 target 配置;不需要学习 Prometheus 特定的配置语言。
架构
Prometheus Operator
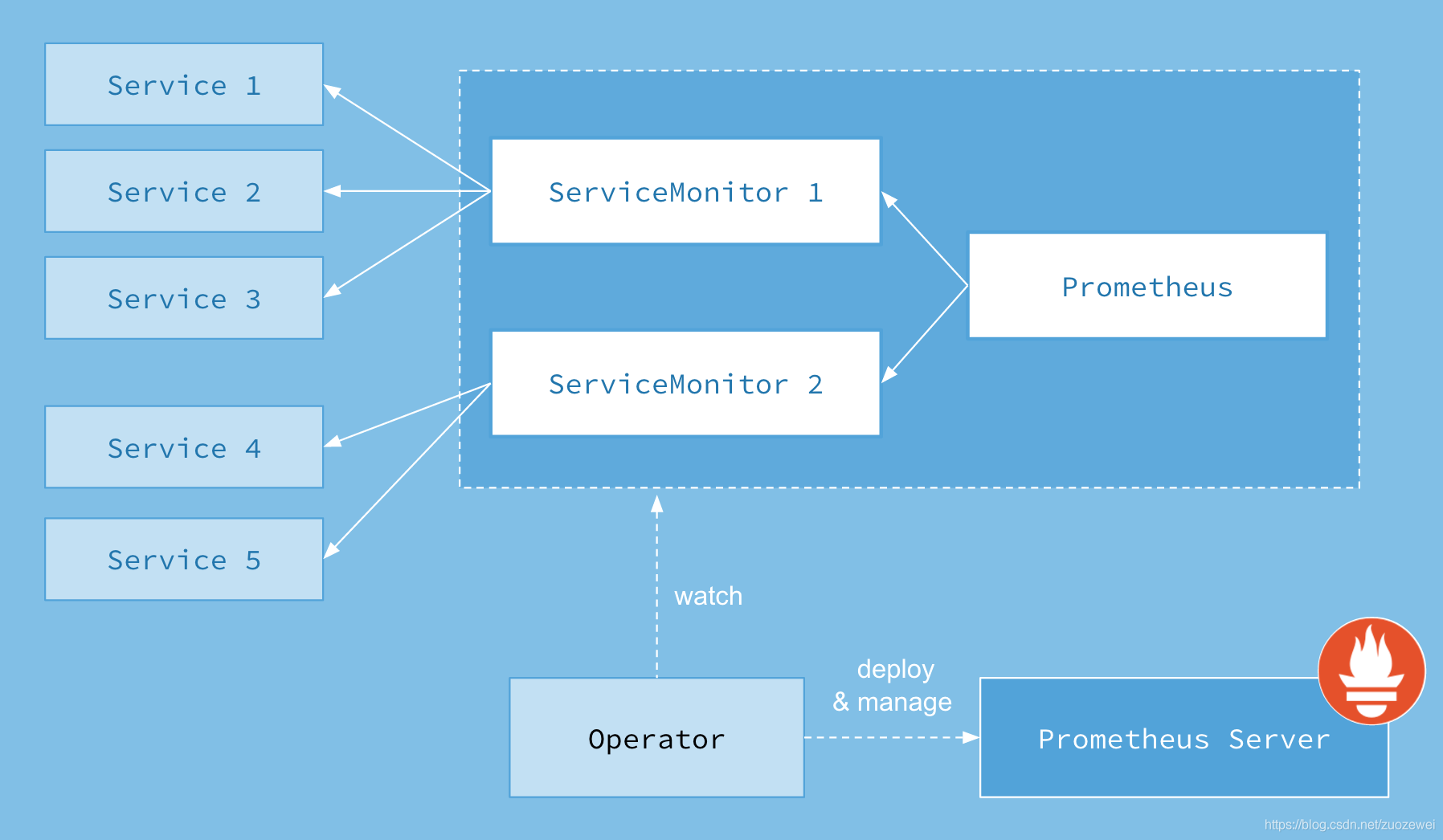
Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如 Node Exporter Service、Mysql Exporter Service 等等。
Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
Prometheus
作为一个监控系统,Prometheus 项目的作用和工作方式,其实可以用如下所示的一张官方示意图来解释:
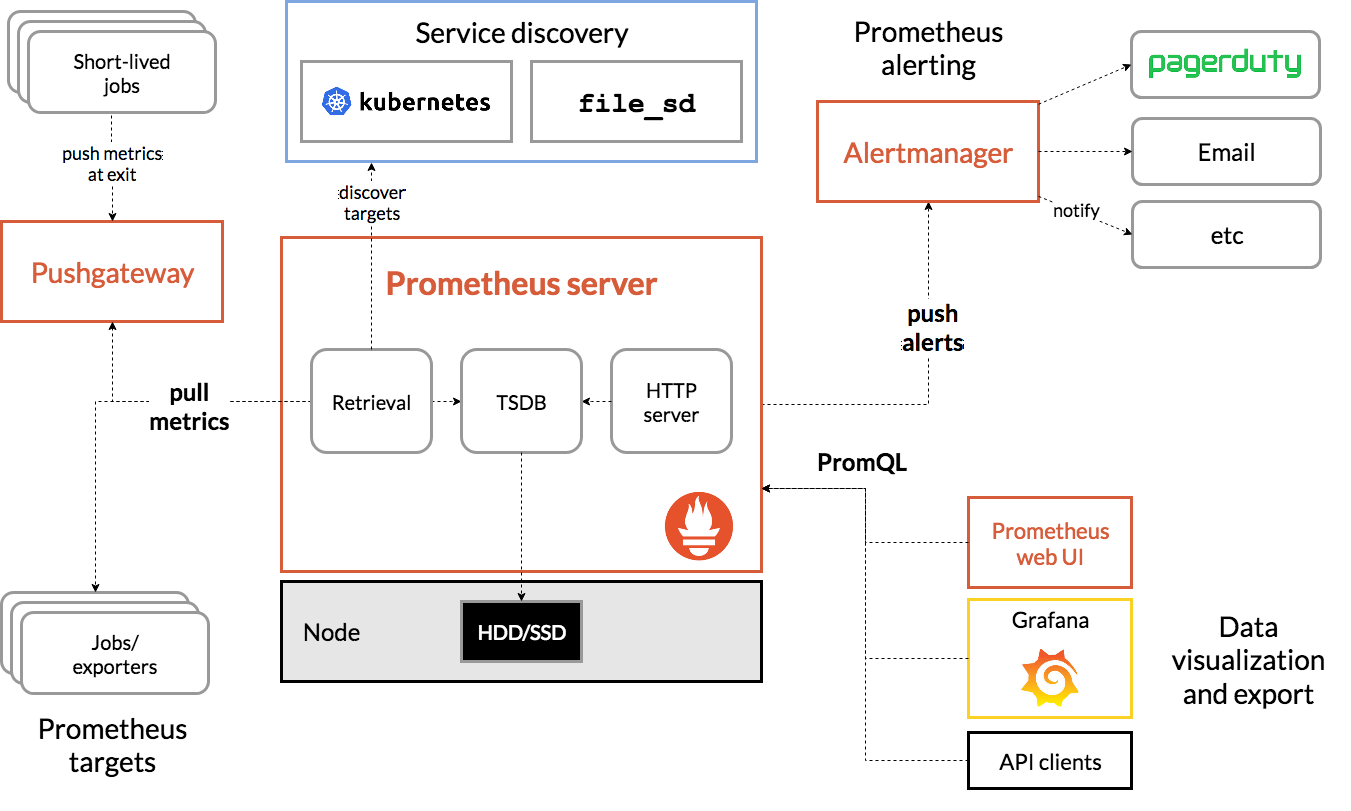
可以看到,Prometheus 项目工作的核心,是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),然后,再把这些数据保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。有了这套核心监控机制, Prometheus 剩下的组件就是用来配合这套机制的运行。比如 Pushgateway,可以允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据。而 Alertmanager,则可以根据 Metrics 信息灵活地设置报警。当然, Prometheus 最受用户欢迎的功能,还是通过 Grafana 对外暴露出的、可以灵活配置的监控数据可视化界面。
安装
系统参数:
Kube-promethues 版本: 0.7.0
Kubernetes 版本: 1.20
项目 Github 地址: https://github.com/coreos/kube-prometheus
拉取
先从 Github 上将源码拉取下来,利用源码项目已经写好的 kubernetes 的 yaml 文件进行一系列集成镜像的安装,如 grafana、prometheus 等等。
从 GitHub 拉取 Prometheus Operator 源码:
wget https://github.com/coreos/kube-prometheus/archive/v0.7.0.tar.gz解压
tar -zxvf v0.6.0.tar.gz将文件进行分类
由于它的文件都存放在项目源码的 manifests 文件夹下,所以需要进入其中进行启动这些 kubernetes 应用 yaml 文件。又由于这些文件堆放在一起,不利于分类启动,所以这里将它们分类。
进入源码的 manifests 文件夹:
cd kube-prometheus-0.6.0/manifests/创建文件夹并且将 yaml 文件分类:
# 创建文件夹mkdir -p node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
# 移动 yaml 文件,进行分类到各个文件夹下
mv *-serviceMonitor* serviceMonitor/
mv grafana-* grafana/
mv kube-state-metrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv node-exporter-* node-exporter/
mv prometheus-adapter* adapter/
mv prometheus-* prometheus/
基本目录结构如下:
$ treemanifests/
├── adapter
│ ├── prometheus-adapter-apiService.yaml
│ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml
│ ├── prometheus-adapter-clusterRoleBinding.yaml
│ ├── prometheus-adapter-clusterRoleServerResources.yaml
│ ├── prometheus-adapter-clusterRole.yaml
│ ├── prometheus-adapter-configMap.yaml
│ ├── prometheus-adapter-deployment.yaml
│ ├── prometheus-adapter-roleBindingAuthReader.yaml
│ ├── prometheus-adapter-serviceAccount.yaml
│ └── prometheus-adapter-service.yaml
├── alertmanager
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-serviceAccount.yaml
│ └── alertmanager-service.yaml
├── grafana
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-pvc.yaml
│ ├── grafana-serviceAccount.yaml
│ └── grafana-service.yaml
├── kube-state-metrics
│ ├── kube-state-metrics-clusterRoleBinding.yaml
│ ├── kube-state-metrics-clusterRole.yaml
│ ├── kube-state-metrics-deployment.yaml
│ ├── kube-state-metrics-serviceAccount.yaml
│ └── kube-state-metrics-service.yaml
├── node-exporter
│ ├── node-exporter-clusterRoleBinding.yaml
│ ├── node-exporter-clusterRole.yaml
│ ├── node-exporter-daemonset.yaml
│ ├── node-exporter-serviceAccount.yaml
│ └── node-exporter-service.yaml
├── prometheus
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-rules.yaml
│ ├── prometheus-serviceAccount.yaml
│ └── prometheus-service.yaml
├── serviceMonitor
│ ├── alertmanager-serviceMonitor.yaml
│ ├── grafana-serviceMonitor.yaml
│ ├── kube-state-metrics-serviceMonitor.yaml
│ ├── node-exporter-serviceMonitor.yaml
│ ├── prometheus-adapter-serviceMonitor.yaml
│ ├── prometheus-operator-serviceMonitor.yaml
│ ├── prometheus-serviceMonitorApiserver.yaml
│ ├── prometheus-serviceMonitorCoreDNS.yaml
│ ├── prometheus-serviceMonitorKubeControllerManager.yaml
│ ├── prometheus-serviceMonitorKubelet.yaml
│ ├── prometheus-serviceMonitorKubeScheduler.yaml
│ └── prometheus-serviceMonitor.yaml
└── setup
├── 0namespace-namespace.yaml
├── prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
├── prometheus-operator-0podmonitorCustomResourceDefinition.yaml
├── prometheus-operator-0prometheusCustomResourceDefinition.yaml
├── prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
├── prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
├── prometheus-operator-0thanosrulerCustomResourceDefinition.yaml
├── prometheus-operator-clusterRoleBinding.yaml
├── prometheus-operator-clusterRole.yaml
├── prometheus-operator-deployment.yaml
├── prometheus-operator-serviceAccount.yaml
└── prometheus-operator-service.yaml
修改Service端口设置
修改 Prometheus Service
修改prometheus Service端口类型为 NodePort,设置 NodePort 端口为 32101:
apiVersion: v1kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 32101
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
修改 Grafana Service
vim grafana/grafana-service.yaml修改 garafana service 端口类型为 NodePort,设置 NodePort 端口为 32102:
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 32102
selector:
app: grafanaprometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,如果 Pod 挂掉了,那么数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,本文持久化存储暂时没做
安装Prometheus Operator
所有文件都在 manifests 目录下执行。
安装Operator
kubectl apply -f setup/查看 Pod,等 pod 创建起来在进行下一步:
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-7649c7454f-64wzg 2/2 Running 0 9h这会创建一个名为 monitoring 的命名空间,以及相关的 CRD 资源对象声明和 Prometheus Operator 控制器。前面中我们介绍过 CRD 和 Operator 的使用,当我们声明完 CRD 过后,就可以来自定义资源清单了,但是要让我们声明的自定义资源对象生效就需要安装对应的 Operator 控制器,这里我们都已经安装了,所以接下来就可以来用 CRD 创建真正的自定义资源对象了。其实在 manifests 目录下面的就是我们要去创建的 Prometheus、Alertmanager 以及各种监控对象的资源清单。
安装其它组件
没有特殊的定制需求我们可以直接一键安装:
kubectl apply -f adapter/kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
查看 Pod 状态:
kubectl get pods -n monitoringNAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 3d11h
alertmanager-main-1 2/2 Running 0 8h
alertmanager-main-2 2/2 Running 0 3d11h
grafana-7854c79446-nqfnm 1/1 Running 0 6h6m
kube-state-metrics-587bfd4f97-dz78p 3/3 Running 0 3d10h
node-exporter-6xqhk 2/2 Running 2 3d11h
node-exporter-bxtbc 2/2 Running 0 3d11h
node-exporter-djr27 2/2 Running 0 3d11h
prometheus-adapter-7587b45c69-p2h8c 1/1 Running 0 5h37m
prometheus-k8s-0 2/2 Running 1 6h
prometheus-k8s-1 2/2 Running 1 6h
prometheus-operator-7649c7454f-64wzg 2/2 Running 0 9h
查看Prometheus & Grafana
查看Prometheus
打开地址:http://node_ip:32101 查看 Prometheus 采集的目标,看其各个采集服务状态有没有错误。

可以看到已经监控上了很多指标数据了,上面我们可以看到 Prometheus 是两个副本,我们这里通过 Service 去访问,按正常来说请求是会去轮询访问后端的两个 Prometheus 实例的,但实际上我们这里访问的时候始终是路由到后端的一个实例上去,因为这里的 Service 在创建的时候添加了 SessionAffinity:ClientIP 这样的属性,会根据 ClientIP 来做 Session 亲和性,所以我们不用担心请求会到不同的副本上去。
查看Grafana
打开地址:http://node_ip:32102 查看 Grafana 图表,看其 Kubernetes 集群是否能正常显示。
默认用户名:admin
默认密码:admin
可以看到各种仪表盘:

小结
安装 Prometheus 之后,我们就可以按照 Metrics 数据的来源,来对 Kubernetes 的监控体系做一个简要的概括:
第一种是宿主机(node)的监控数据。这部分数据的提供,需要借助 Node Exporter 。一般来说,Node Exporter 会以 DaemonSet 的方式运行在宿主机上。其实,所谓的 Exporter,就是代替被监控对象来对 Prometheus 暴露出可以被“抓取”的 Metrics 信息的一个辅助进程。而 Node Exporter 可以暴露给 Prometheus 采集的 Metrics 数据, 也不单单是节点的负载(Load)、CPU 、内存、磁盘以及网络这样的常规信息,它的 Metrics 指标很丰富,具体你可以查看Node Export列表
第二种是来自于 Kubernetes 的 API Server、kubelet 等组件的 /metrics API。除了常规的 CPU、内存的信息外,这部分信息还主要包括了各个组件的核心监控指标。比如,对于 API Server 来说,它就会在 /metrics API 里,暴露出各个 Controller 的工作队列(Work Queue)的长度、请求的 QPS 和延迟数据等等。这些信息,是检查 Kubernetes 本身工作情况的主要依据。
第三种是 Kubernetes 相关的监控数据。这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。其中,容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务。在 kubelet 启动后,cAdvisor 服务也随之启动,而它能够提供的信息,可以细化到每一个容器的 CPU 、文件系统、内存、网络等资源的使用情况。需要注意的是,这里提到的是 Kubernetes 核心监控数据。
文章源码