前言 监控指标具体实现举例 Pod性能cAdvisor容器CPU,内存利用率Node性能node-exporter节点CPU,内存利用率K8S资源对象kube-state-metricsPod/Deployment/Service 数据收集 我们这里使用kube-state-metrics对
前言
监控指标 具体实现 举例 Pod性能 cAdvisor 容器CPU,内存利用率 Node性能 node-exporter 节点CPU,内存利用率 K8S资源对象 kube-state-metrics Pod/Deployment/Service数据收集
我们这里使用kube-state-metrics对k8s资源数据进行收集。
架构图
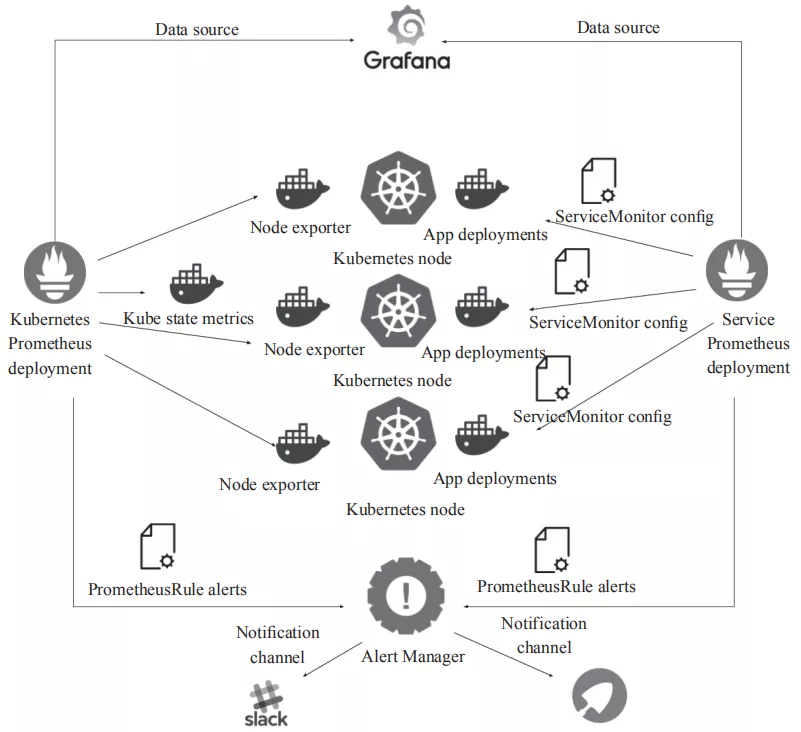
prometheus核心组件
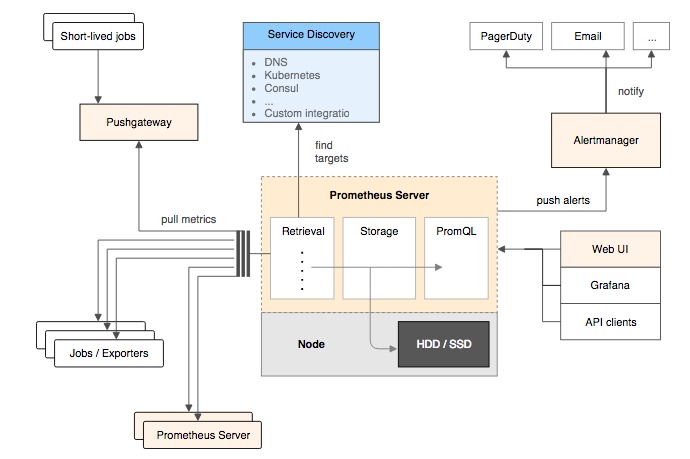
监控指标
指标类别包括:
- CronJob Metrics
- DaemonSet Metrics
- Deployment Metrics
- Job Metrics
- LimitRange Metrics
- Node Metrics
- PersistentVolume Metrics
- PersistentVolumeClaim Metrics
- Pod Metrics
- Pod Disruption Budget Metrics
- ReplicaSet Metrics
- ReplicationController Metrics
- ResourceQuota Metrics
- Service Metrics
- StatefulSet Metrics
- Namespace Metrics
- Horizontal Pod Autoscaler Metrics
- Endpoint Metrics
- Secret Metrics
- ConfigMap Metrics
以pod为例:
- kube_pod_info
- kube_pod_owner
- kube_pod_status_phase
- kube_pod_status_ready
- kube_pod_status_scheduled
- kube_pod_container_status_waiting
- kube_pod_container_status_terminated_reason
- ...
部署 kube-state-metrics
默认会在kube-system命名空间下创建对应的资源,最好不要更换yaml文件中的命名空间。
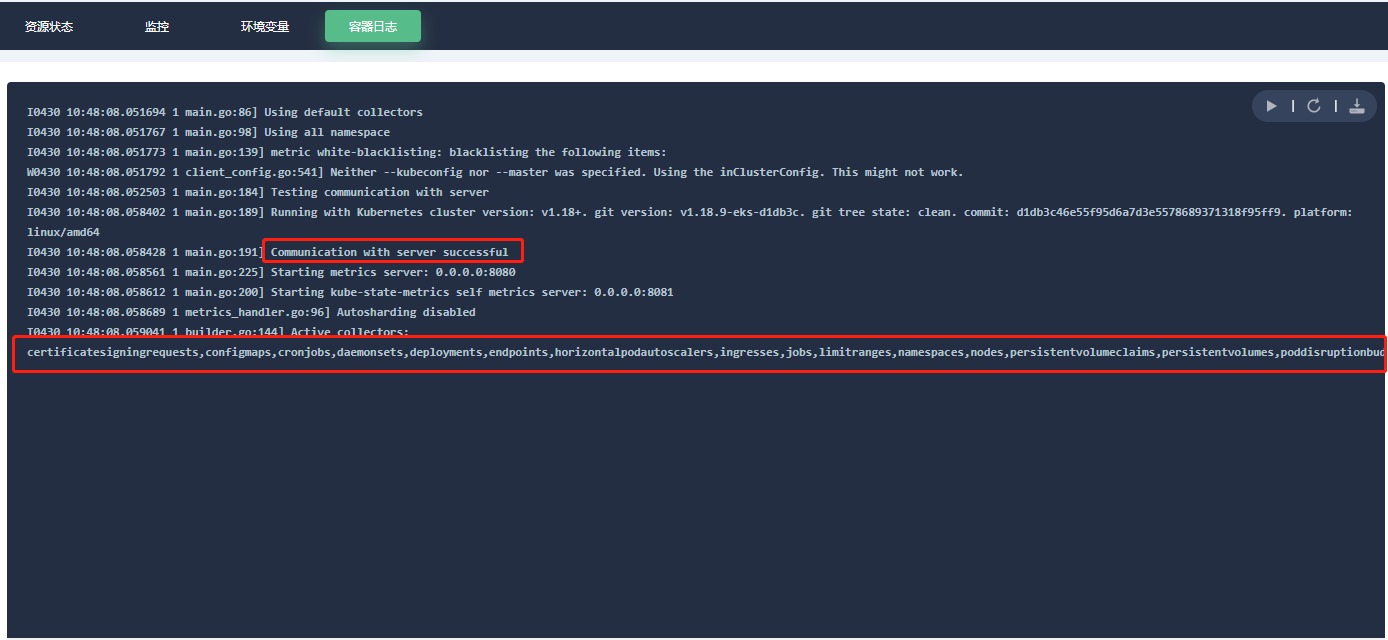
# 获取yml文件 git clone https://gitee.com/tengfeiwu/kube-state-metrics_prometheus_wechat.git # 部署kube-state-metrics kubectl apply -f kube-state-metrics-configs # 查看pod状态 kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE kube-state-metrics-c698dc7b5-zstz9 1/1 Running 0 32m获取kube-state-metrics-c698dc7b5-zstz9容器日志,如图:
数据对接prometheus
当prometheus准备好了之后,添加对应的采集job即可:
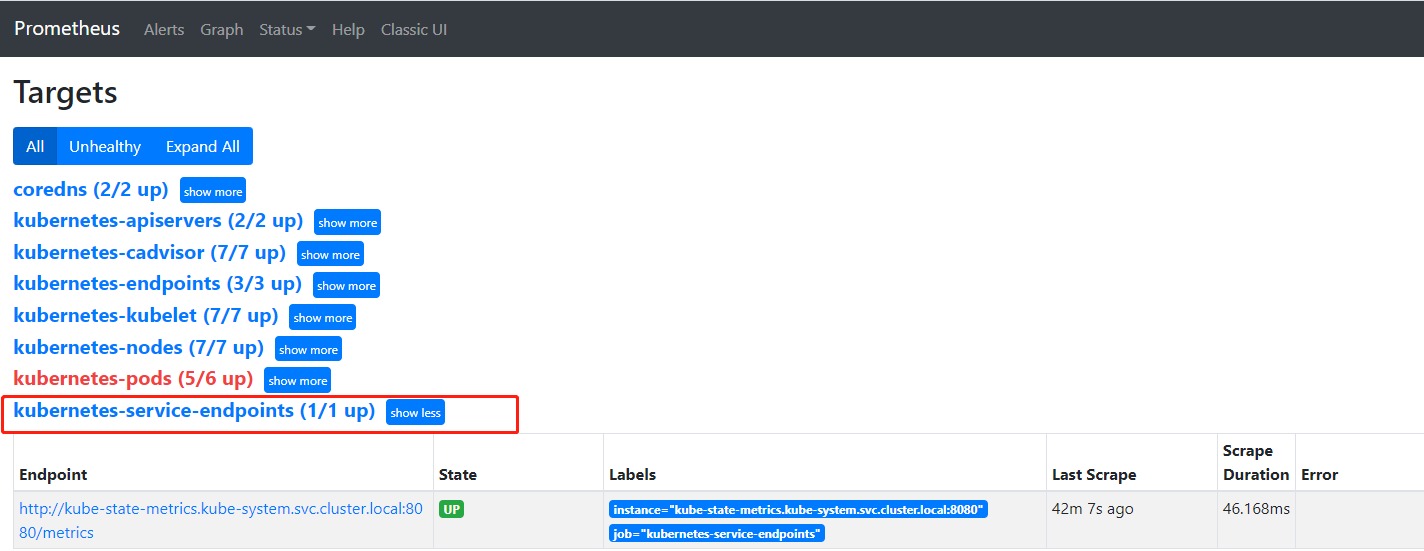
# 添加在sidecar/cm-kube-mon-sidecar.yaml最后 - job_name: 'kube-state-metrics' static_configs: - targets: ['kube-state-metrics.kube-system.svc.cluster.local:8080'] # 重新apply configmap文件,无需reload prometheus,已配置热更新 kubectl apply -f sidecar/cm-kube-mon-sidecar.yaml打开promethues的web看一下target里的配置是否生效,如下图:
数据对接Grafana
当Grafana准备好之后,我们在Grafana中导入选定/自定义的dashboard,添加Prometheus数据源,即可:
prometheus报警规则
修改sidecar/rules-cm-kube-mon-sidecar.yaml配置文件,添加如下报警指标。
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-rules namespace: kube-mon data: alert-rules.yaml: |- groups: - name: White box monitoring rules: - alert: Pod-重启 expr: changes(kube_pod_container_status_restarts_total{pod !~ "analyzer.*"}[10m]) > 0 for: 1m labels: severity: 警告 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Pod: {{ $labels.pod }} Restart" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" pod: "{{ $labels.pod }}" container: "{{ $labels.container }}" - alert: Pod-未知错误/失败 expr: kube_pod_status_phase{phase="Unknown"} == 1 or kube_pod_status_phase{phase="Failed"} == 1 for: 1m labels: severity: 紧急 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Pod: {{ $labels.pod }} 未知错误/失败" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" pod: "{{ $labels.pod }}" container: "{{ $labels.container }}" - alert: Daemonset Unavailable expr: kube_daemonset_status_number_unavailable > 0 for: 1m labels: severity: 紧急 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Daemonset: {{ $labels.daemonset }} 守护进程不可用" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" daemonset: "{{ $labels.daemonset }}" - alert: Job-失败 expr: kube_job_status_failed == 1 for: 3m labels: severity: 警告 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Job: {{ $labels.job_name }} Failed" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" job: "{{ $labels.job_name }}" - alert: Pod NotReady expr: sum by (namespace, pod, cluster_id) (max by(namespace, pod, cluster_id)(kube_pod_status_phase{job=~".*kubernetes-service-endpoints",phase=~"Pending|Unknown"}) * on(namespace, pod, cluster_id)group_left(owner_kind) topk by(namespace, pod) (1, max by(namespace, pod,owner_kind, cluster_id) (kube_pod_owner{owner_kind!="Job"}))) > 0 for: 3m labels: severity: 警告 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "pod: {{ $labels.pod }} 处于 NotReady 状态超过15分钟" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" - alert: Deployment副本数 expr: (kube_deployment_spec_replicas{job=~".*kubernetes-service-endpoints"} !=kube_deployment_status_replicas_available{job=~".*kubernetes-service-endpoints"}) and (changes(kube_deployment_status_replicas_updated{job=~".*kubernetes-service-endpoints"}[5m]) == 0) for: 3m labels: severity: 警告 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Deployment: {{ $labels.deployment }} 实际副本数和设置副本数不一致" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" deployment: "{{ $labels.deployment }}" - alert: Statefulset副本数 expr: (kube_statefulset_status_replicas_ready{job=~".*kubernetes-service-endpoints"} !=kube_statefulset_status_replicas{job=~".*kubernetes-service-endpoints"}) and (changes(kube_statefulset_status_replicas_updated{job=~".*kubernetes-service-endpoints"}[5m]) == 0) for: 3m labels: severity: 警告 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Statefulset: {{ $labels.statefulset }} 实际副本数和设置副本数不一致" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" statefulset: "{{ $labels.statefulset }}" - alert: 存储卷PV expr: kube_persistentvolume_status_phase{phase=~"Failed|Pending",job=~".*kubernetes-service-endpoints"} > 0 for: 2m labels: severity: 紧急 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "存储卷PV: {{ $labels.persistentvolume }} 处于Failed或Pending状态" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" persistentvolume: "{{ $labels.persistentvolume }}" - alert: 存储卷PVC expr: kube_persistentvolumeclaim_status_phase{phase=~"Failed|Pending|Lost",job=~".*kubernetes-service-endpoints"} > 0 for: 2m labels: severity: 紧急 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "存储卷PVC: {{ $labels.persistentvolumeclaim }} Failed或Pending状态" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" persistentvolumeclaim: "{{ $labels.persistentvolumeclaim }}" - alert: k8s service expr: kube_service_status_load_balancer_ingress != 1 for: 2m labels: severity: 紧急 service: prometheus_bot receiver_group: "{{ $labels.k8scluster}}_{{ $labels.namespace }}" annotations: summary: "Service: {{ $labels.service }} 服务负载均衡器入口状态DOWN!" k8scluster: "{{ $labels.k8scluster}}" namespace: "{{ $labels.namespace }}" persistentvolumeclaim: "{{ $labels.service }}" - alert: 磁盘IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 3m labels: severity: 警告 annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 网络流入 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 3m labels: severity: 警告 annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}" - alert: 网络流出 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 3m labels: severity: 警告 annotations: summary: "{{$labels.mountpoint}} 流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 1m labels: severity: 紧急 annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 1m labels: severity: 紧急 annotations: summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!" description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"更新sidecar/rules-cm-kube-mon-sidecar.yaml配置文件,如下:
# 稍等待一分钟左右,prometheus已定义热更新,无需apply kubectl apply -f rules-cm-kube-mon-sidecar.yaml对接AlertManager
部署微信告警
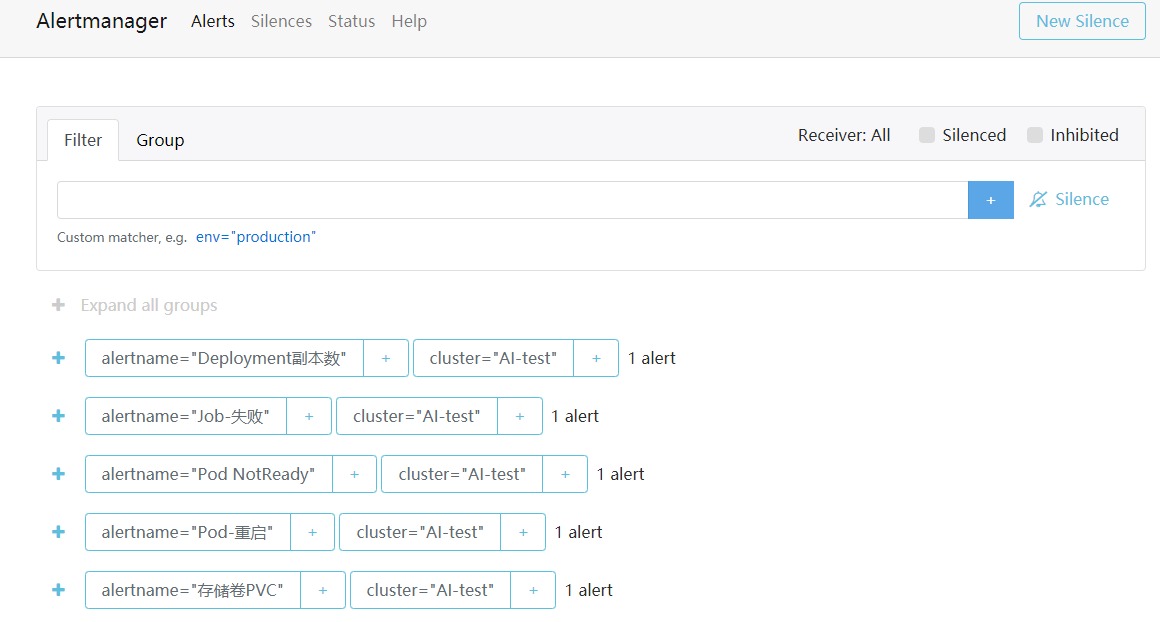
# 获取yml文件 git clone https://gitee.com/tengfeiwu/kube-state-metrics_prometheus_wechat.git && cd thanos/AlertManager # 部署AlertManager ## 更改为自己wechat信息 kubectl apply -f cm-kube-mon-alertmanager.yaml kubectl apply -f wechat-template-kube-mon.yaml kubectl apply -f deploy-kube-mon-alertmanager.yaml kubectl apply -f svc-kube-mon-alertmanager.yaml查看报警状态
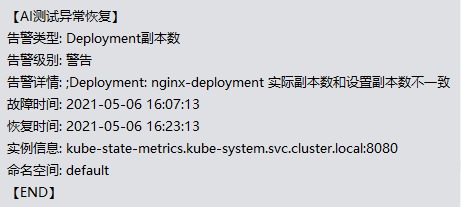
微信报警和恢复信息
报警信息

恢复信息