众所周知,spring 从 2.5 版本以后开始支持使用注解代替繁琐的 xml 配置,到了 springboot 更是全面拥抱了注解式配置。平时在使用的时候,点开一些常见的等注解,会发现往往在一个注解上总会出现一些其他的注解,比如 @Service:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component // @Component
public @interface Service {
@AliasFor(annotation = Component.class)
String value() default "";
}
大部分情况下,我们可以将 @Service 注解等同于 @Component 注解使用,则是因为 spring 基于其 JDK 对元注解的机制进行了扩展。
在 java 中,元注解是指可以注解在其他注解上的注解,spring 中通过对这个机制进行了扩展,实现了一些原生 JDK 不支持的功能,比如允许在注解中让两个属性互为别名,或者将一个带有元注解的子注解直接作为元注解看待,或者在这个基础上,通过 @AlisaFor 或者同名策略让子注解的值覆盖元注解的值。
笔者今天将基于 spring 5.2.x 的源码研究 spring 如何实现这套功能的。
入口
我们从最常用的 AnnotatedElementUtils#findMergedAnnotation 方法开始。
在 spring 中, 常见的get表示从某个元素直接声明的注解中获取注解,而 find 语义表示从一个元素的直接以及间接声明的注解中查找注解。换而言之,即从包括该元素的注解、注解的元注解、接口或类的复杂层级结构中查找。MergedAnnotation 则表示一个存在层级结构的根注解聚合得到的“合并注解”,这个注解的各项属性将会因为根注解和元注解的层级结构而有所不同。
findMergedAnnotation 从语义上理解,就是从一个元素以及全部他的接口或父类中,获取指定类型的注解,然后将这些注解和注解上可能存在的元注解聚合为合并注解并返回。
该方法实现如下:
public static <A extends Annotation> A findMergedAnnotation(AnnotatedElement element, Class<A> annotationType) {
// 1、下述任意情况下直接获取元素上声明的注解:
// a.查找的注解属于java、javax或者org.springframework.lang包
// b.被处理的元素属于java包,或被java包中的对象声明,或者就是Ordered.class
if (AnnotationFilter.PLAIN.matches(annotationType) ||
AnnotationsScanner.hasPlainJavaAnnotationsOnly(element)) {
return element.getDeclaredAnnotation(annotationType);
}
// 2、将元素上的全部注解合成MergedAnnotation
return findAnnotations(element)
// 3、从MergedAnnotation获取与该类型对应的MergedAnnotations
.get(annotationType, null, MergedAnnotationSelectors.firstDirectlyDeclared())
// 4、根据MergedAnnotation通过动态代理生成一个注解实例
.synthesize(MergedAnnotation::isPresent).orElse(null);
}
此处实际一个四步:
- 判断是否可以直接获取元素声明的注解,否则则执行
find; - 将元素上的注解聚合成一个
MergedAnnotations; - 从元素上的聚合注解中获得与查找的
annotationType对应的合成MergedAnnotations; - 根据获得的
MergedAnnotation通过动态代理生成一个注解实例;
在第一步,确定是否可以直接从元素上直接获取声明的注解从而避免性能消耗较大的 find。
此处通过注解过滤器 AnnotationFilter来过滤注解,该类是一个函数式接口,用于匹配传入的注解实例、类型或名称。
@FunctionalInterface
public interface AnnotationFilter {
// 根据实例匹配
default boolean matches(Annotation annotation) {
return matches(annotation.annotationType());
}
// 根据类型匹配
default boolean matches(Class<?> type) {
return matches(type.getName());
}
// 根据名称匹配
boolean matches(String typeName);
}
AnnotationFilter默认提供三个可选的静态实例:
PLAIN:类是否属于java.lang、org.springframework.lang包;JAVA:类是否属于java、javax包;ALL:任何类;
此处过滤器选择了 PLAIN,即当查找的注解属于 java.lang、org.springframework.lang 包的时候就不进行查找,而是直接从被查找的元素直接声明的注解中获取。这个选择不难理解,java.lang包下提供的都是诸如@Resource或者 @Target 这样的注解,而springframework.lang包下提供的则都是 @Nonnull 这样的注解,这些注解基本不可能作为有特殊业务意义的元注解使用,因此默认忽略也是合理的。
实际上,PLAIN 也是大部分情况下的使用的默认过滤器。
若要查找的注解不属于 java.lang、org.springframework.lang 包,还需要确认被处理的元素。
这里使用了AnnotationsScanner工具类,它的作用跟名字一样,就是从各种 AnnotatedElement 以及复杂的嵌套层级中扫描并解析注解。
此处AnnotationsScanner.hasPlainJavaAnnotationsOnly(element) 这一段代码如下:
static boolean hasPlainJavaAnnotationsOnly(@Nullable Object annotatedElement) {
if (annotatedElement instanceof Class) {
// 1.1 如果是类,则声明它不能是java包下的,或者Ordered.class
return hasPlainJavaAnnotationsOnly((Class<?>) annotatedElement);
}
else if (annotatedElement instanceof Member) {
// 1.2 如果是类成员,则声明它的类不能是java包下的,或者Ordered.class
return hasPlainJavaAnnotationsOnly(((Member) annotatedElement).getDeclaringClass());
}
else {
return false;
}
}
// 1.1
static boolean hasPlainJavaAnnotationsOnly(Class<?> type) {
return (type.getName().startsWith("java.") || type == Ordered.class);
}
// 1.2
static boolean hasPlainJavaAnnotationsOnly(Class<?> type) {
return (type.getName().startsWith("java.") || type == Ordered.class);
}
简而言之,就是被查询的元素如果是或者属于 java 包下的类以及 Ordered.class,则不进行查询。
由于 java 包下的代码都是标准库,自定义的元注解不可能加到源码中,因此只要类属于 java包,则我们实际上是可以认为它是不可能有符合 spring 语义的元注解的。
总结一下查找注解这一步操作:
当任意下述任意条件时,不进行 find,则是直接从元素上声明的注解中获取注解:
- 判断要查找的注解是否属于
java.lang、org.springframework.lang包; - 被查找的元素如果是否是或者属于
java包下的类以及Ordered.class;
当上述条件皆不符合时,继续进行 find,也就是下述过程。
findAnnotations会经过多层的调用,实际上最终目的是创建一个 MergedAnnotations ,并且确定它的四个属性:
- 注解源
element,即要被查找的元素; - 查找策略
searchStrategy,即MergedAnnotations.SearchStrategy枚举; - 重复容器注解
repeatableContainers,即@Repeatable指定的对应容器注解; - 注解过滤器
annotationFilter,同上文,用于过滤注解;
这里返回的是 MergedAnnotations 的实现类 TypeMappedAnnotations:
// AnnotatedElementUtils
private static MergedAnnotations findAnnotations(AnnotatedElement element) {
// 1、配置重复注解容器:空容器
// 2、配置查找策略:查找类、全部父类以及其父接口
return MergedAnnotations.from(element, SearchStrategy.TYPE_HIERARCHY, RepeatableContainers.none());
}
// MergedAnnotations
static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy,
RepeatableContainers repeatableContainers) {
// 3、配置注解过滤器:过滤属于`java`、`javax`或者`org.springframework.lang`包的注解
return from(element, searchStrategy, repeatableContainers, AnnotationFilter.PLAIN);
}
static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy,
RepeatableContainers repeatableContainers, AnnotationFilter annotationFilter) {
Assert.notNull(repeatableContainers, "RepeatableContainers must not be null");
Assert.notNull(annotationFilter, "AnnotationFilter must not be null");
return TypeMappedAnnotations.from(element, searchStrategy, repeatableContainers, annotationFilter);
}
// TypeMappedAnnotations
// 4、创建聚合注解:TypeMappedAnnotations
static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy,
RepeatableContainers repeatableContainers, AnnotationFilter annotationFilter) {
// 该元素若符合下述任一情况,则直接返回空注解:
// a.被处理的元素属于java包、被java包中的对象声明,或者就是Ordered.class
// b.只查找元素直接声明的注解,但是元素本身没有声明任何注解
// c.查找元素的层级结构,但是元素本身没有任何层级结构
// d.元素是桥接方法
if (AnnotationsScanner.isKnownEmpty(element, searchStrategy)) {
return NONE;
}
// 5、返回一个具体的实现类实例
return new TypeMappedAnnotations(element, searchStrategy, repeatableContainers, annotationFilter);
}
RepeatableContainers抽象类表示某个可重复注解与他的某个容器注解之间的对应关系,即常见的下述写法:
// 可重复的注解
@Repeatable(RepeatableContainerAnnotation.class)
@interface RepeatableAnnotation {}
// 可重复注解的容器注解
@interface RepeatableContainerAnnotation {
RepeatableAnnotation[] value() default {};
}
此处 RepeatableContainerAnnotation 就是 RepeatableAnnotation 的容器注解,他们就对应一个RepeatableContainers实例。
实际场景中甚至可能还存在 RepeatableContainerAnnotation 的容器注解......以此类推,无限套娃。因此,RepeatableContainers 实际上是一个树结构,通过 parent 变量持有当前容器注解与容器注解的容器注解的对应关系。
一个RepeatableContainers中会通过 parent 成员变量持有他的容器注解,而容器注解同样被封装为 RepeatableContainers,若它也存在对应容器注解,则它也会通过 parent 变量持有他的容器注解......以此类推。
它的结构大概如下:
// 顶层抽象类
public abstract class RepeatableContainers {
@Nullable
private final RepeatableContainers parent; // 容器注解
@Nullable
Annotation[] findRepeatedAnnotations(Annotation annotation) {
if (this.parent == null) {
return null;
}
return this.parent.findRepeatedAnnotations(annotation); // 返回父节点的findRepeatedAnnotations方法返回值
}
}
// 实现类
private static class ExplicitRepeatableContainer extends RepeatableContainers {
private final Class<? extends Annotation> repeatable; // 可重复的注解
private final Class<? extends Annotation> container; // 容器注解
private final Method valueMethod; // 容器注解的value方法
// 获取可重复注解
@Override
@Nullable
Annotation[] findRepeatedAnnotations(Annotation annotation) {
// 若容器注解的value方法返回值就是可重复注解,说明容器注解就是该可重复注解的直接容器
if (this.container.isAssignableFrom(annotation.annotationType())) {
return (Annotation[]) ReflectionUtils.invokeMethod(this.valueMethod, annotation);
}
// 否则说明存在嵌套结构,当前容器注解实际上放的也是一个容器注解,继续递归直到找到符合条件的容器注解为止
return super.findRepeatedAnnotations(annotation);
}
}
// 实现类
private static class StandardRepeatableContainers extends RepeatableContainers {
private static final Map<Class<? extends Annotation>, Object> cache = new ConcurrentReferenceHashMap<>();
private static final Object NONE = new Object();
private static StandardRepeatableContainers INSTANCE = new StandardRepeatableContainers();
StandardRepeatableContainers() {
super(null);
}
@Override
@Nullable
Annotation[] findRepeatedAnnotations(Annotation annotation) {
Method method = getRepeatedAnnotationsMethod(annotation.annotationType());
if (method != null) {
return (Annotation[]) ReflectionUtils.invokeMethod(method, annotation);
}
return super.findRepeatedAnnotations(annotation);
}
@Nullable
private static Method getRepeatedAnnotationsMethod(Class<? extends Annotation> annotationType) {
Object result = cache.computeIfAbsent(annotationType,
StandardRepeatableContainers::computeRepeatedAnnotationsMethod);
return (result != NONE ? (Method) result : null);
}
private static Object computeRepeatedAnnotationsMethod(Class<? extends Annotation> annotationType) {
AttributeMethods methods = AttributeMethods.forAnnotationType(annotationType);
// 只有一个名为value的属性
if (methods.hasOnlyValueAttribute()) {
Method method = methods.get(0);
Class<?> returnType = method.getReturnType();
// 返回值是可重复注解类型的数组,并且可重复注解上存在@Repeatable注解
if (returnType.isArray()) {
Class<?> componentType = returnType.getComponentType();
if (Annotation.class.isAssignableFrom(componentType) &&
componentType.isAnnotationPresent(Repeatable.class)) {
return method;
}
}
}
return NONE;
}
}
在默认情况下,返回一个名为 NONE 的实例,该容器注解实例表示查找的注解不存在对应容器注解。
查找策略MergedAnnotations.SearchStrategy 是一个内部的枚举类,他提供以下选项:
-
DIRECT:只查找元素上直接声明的注解,不包括通过@Inherited继承的注解; -
INHERITED_ANNOTATIONS:只查找元素直接声明或通过@Inherited继承的注解; -
SUPERCLASS:查找元素直接声明或所有父类的注解; -
TYPE_HIERARCHY:查找元素、所有父类以及实现的父接口的全部注解; -
TYPE_HIERARCHY_AND_ENCLOSING_CLASSES:查找封闭类以及其子类。封闭类是 JDK17 的新特性,可参考 详解 Java 17中的新特性:“密封类”,本章将不过多涉及该内容;
当不指定时,默认的查找策略为TYPE_HIERARCHY,即查找元素、所有父类以及实现的父接口的全部注解。
同上,这里使用了默认的 PLAIN 过滤器,用于过滤属于 java.lang、org.springframework.lang 包的注解。
MergedAnnotations本身实现了Iterable接口,用于表示一组处于聚合状态的 MergedAnnotation,而MergedAnnotation 就是对应我们实际上的合并注解,举个例子:
假如我们有个 Foo.class,类上存在 @AnnotationA 与 @AnnotationB 两个注解,这两个注解又都有一大堆的元注解。此时 @AnnotationA 与 @AnnotationB 则各表示一个 MergedAnnotation,而 MergedAnnotations 表示 Foo.class 上的两个MergedAnnotation。
MergedAnnotations提供了四个比较重要的静态方法:
get:用于从聚合注解中获取某个指定类型的合并注解;stream:用于从聚合注解中获取多个指定类型的合并注解构成的 stream 流;isPresent:某个类型的合并注解是否在该聚合中存在;from:解析某个带有注解的元素获得对应的聚合注解;
TypeMappedAnnotations 则为该接口的主要实现类,这一步最终返回的就是一个TypeMappedAnnotations的实例。
总结一下findAnnotations这一步操作,根本目的就是获得一个TypeMappedAnnotations 实现,步骤如下:
- 配置重复注解容器:这里指定了一个
NONE,即注解没有对应的容器注解; - 配置查找策略:这里指定查找类、全部父类以及其父接口;
- 配置注解过滤器:这里指定类型为
PLAIN,默认过滤属于java、javax或者org.springframework.lang包的注解; - 创建聚合注解:这里根据上述配置创建了一个
TypeMappedAnnotations实例;
在第三步,将通过 MergedAnnotations#get 方法获得指定类型对应的合并注解 MergedAnnotation实例,这里我们以实现类 TypeMappedAnnotations 为例:
@Override
public <A extends Annotation> MergedAnnotation<A> get(Class<A> annotationType,
@Nullable Predicate<? super MergedAnnotation<A>> predicate,
@Nullable MergedAnnotationSelector<A> selector) {
// 1、若该注解无法通过过滤,即该注解若属于 `java.lang`、`org.springframework.lang` 包,则直接返回空注解
if (this.annotationFilter.matches(annotationType)) {
return MergedAnnotation.missing();
}
// 2、使用MergedAnnotationFinder扫描并获取注解
MergedAnnotation<A> result = scan (
annotationType, new MergedAnnotationFinder<>(annotationType, predicate, selector)
);
return (result != null ? result : MergedAnnotation.missing());
}
@Nullable
private <C, R> R scan(C criteria, AnnotationsProcessor<C, R> processor) {
if (this.annotations != null) {
// a.若指定了查找的注解,则扫描这些注解以及其元注解的层级结构
R result = processor.doWithAnnotations(criteria, 0, this.source, this.annotations);
return processor.finish(result);
}
if (this.element != null && this.searchStrategy != null) {
// b.未指定查找的注解,则直接扫描元素以及其父类、父接口的层级结构
return AnnotationsScanner.scan(criteria, this.element, this.searchStrategy, processor);
}
return null;
}
在创建合并注解 MergedAnnotation 时,需要传入一个选择器MergedAnnotationSelector。
MergedAnnotationSelector本质上就是一个比较器,用于从两个注解中选择出一个权重更高的注解,此处的“权重”实际就是指注解离被查找元素的距离,距离越近权重就越高,举个例子:
假如现在有个被查找元素 Foo.class,他上面有一个注解@A,@A上还有一个元注解 @B,此时@A距离Foo.class的距离是 0 ,即@A 是在 Foo.class 上直接声明的,而@B距离Foo.class的距离就是 1 ,当 @A 与 @B 二选一的时候,距离更近的@A的权重就更高,换而言之,就是更匹配。
他在MergedAnnotationSelectors中提供了Nearest和FirstDirectlyDeclared两个默认的实现,也基本都遵循这个规则:
// 距离优先选择器
private static class Nearest implements MergedAnnotationSelector<Annotation> {
@Override
public boolean isBestCandidate(MergedAnnotation<Annotation> annotation) {
return annotation.getDistance() == 0; // 若注解是否被元素直接声明
}
@Override
public MergedAnnotation<Annotation> select(
MergedAnnotation<Annotation> existing, MergedAnnotation<Annotation> candidate) {
// 若候选注解离元素的距离比当前注解更近,则返回候选注解,否则返回当前注解
if (candidate.getDistance() < existing.getDistance()) {
return candidate;
}
return existing;
}
}
// 直接声明注解选择器
private static class FirstDirectlyDeclared implements MergedAnnotationSelector<Annotation> {
@Override
public boolean isBestCandidate(MergedAnnotation<Annotation> annotation) {
return annotation.getDistance() == 0; // 若注解是否被元素直接声明
}
// 若当前注解没有被元素直接声明,而候选注解被元素直接声明时返回候选注解,否则返回已有注解
@Override
public MergedAnnotation<Annotation> select(
MergedAnnotation<Annotation> existing, MergedAnnotation<Annotation> candidate) {
if (existing.getDistance() > 0 && candidate.getDistance() == 0) {
return candidate;
}
return existing;
}
}
回到 MergedAnnotations#get() 方法,这里出现了一个新类 MergedAnnotationFinder,它是TypeMappedAnnotations 中的一个内部类,它实现了 AnnotationsProcessor 接口,是注解处理器的一种,会在查找到注解后被回调。
当调用他的 doWithAnnotations 方法时,他将会把入参的注解包括对应的所有元注解解析为一堆 AnnotationTypeMapping,然后遍历并筛选出所需要的注解类型对应的 AnnotationTypeMapping,再封装为一堆对应的 MergedAnnotation,最后再用选择器从里面选择出最匹配的 MergedAnnotation并返回。
对应代码如下:
private class MergedAnnotationFinder<A extends Annotation>
implements AnnotationsProcessor<Object, MergedAnnotation<A>> {
// 要查找的注解类型
private final Object requiredType;
// 过滤器
@Nullable
private final Predicate<? super MergedAnnotation<A>> predicate;
// 选择器,作用类似于比较器,用于从两个注解中获得一个权重更高的注解实例
private final MergedAnnotationSelector<A> selector;
// 最终的返回结构
@Nullable
private MergedAnnotation<A> result;
MergedAnnotationFinder(Object requiredType, @Nullable Predicate<? super MergedAnnotation<A>> predicate,
@Nullable MergedAnnotationSelector<A> selector) {
this.requiredType = requiredType;
this.predicate = predicate;
// 若不指定选择器,则默认使用MergedAnnotationSelectors.Nearest
// 当存在两个相同注解式,选择层级更低的,即离根注解更近的注解
this.selector = (selector != null ? selector : MergedAnnotationSelectors.nearest());
}
@Override
@Nullable
public MergedAnnotation<A> doWithAggregate(Object context, int aggregateIndex) {
return this.result;
}
@Override
@Nullable
public MergedAnnotation<A> doWithAnnotations(Object type, int aggregateIndex,
@Nullable Object source, Annotation[] annotations) {
for (Annotation annotation : annotations) {
// 找到至少一个不被过滤的、并且可以合成合并注解的注解实例
if (annotation != null && !annotationFilter.matches(annotation)) {
MergedAnnotation<A> result = process(type, aggregateIndex, source, annotation);
if (result != null) {
return result;
}
}
}
return null;
}
@Nullable
private MergedAnnotation<A> process(
Object type, int aggregateIndex, @Nullable Object source, Annotation annotation) {
// 1、若要查找的注解可重复,则先找到其容器注解,然后获取容器中的可重复注解并优先处理
Annotation[] repeatedAnnotations = repeatableContainers.findRepeatedAnnotations(annotation);
if (repeatedAnnotations != null) {
return doWithAnnotations(type, aggregateIndex, source, repeatedAnnotations);
}
// 2、解析注解与注解的映射关系
AnnotationTypeMappings mappings = AnnotationTypeMappings.forAnnotationType(
annotation.annotationType(), repeatableContainers, annotationFilter);
// 遍历已解析好的AnnotationTypeMapping实例,并找到相同注解类型的AnnotationTypeMapping接着将其封装为MergedAnnotation
// 然后继续下一次寻找,若还有匹配的结果,则根据选择器从中找到更合适的结果,最终返回一个最匹配结果
for (int i = 0; i < mappings.size(); i++) {
AnnotationTypeMapping mapping = mappings.get(i);
if (isMappingForType(mapping, annotationFilter, this.requiredType)) {
// 3、尝试创建一个合并注解
MergedAnnotation<A> candidate = TypeMappedAnnotation.createIfPossible(
mapping, source, annotation, aggregateIndex, IntrospectionFailureLogger.INFO);
// 4、若合并注解创建成功,且过滤器匹配通过
if (candidate != null && (this.predicate == null || this.predicate.test(candidate))) {
// a.合并注解是最匹配的结果
if (this.selector.isBestCandidate(candidate)) {
return candidate;
}
// b.使用选择器从上一结果和当前结果中选择一个权重更高的注解,做为新的结果
updateLastResult(candidate);
}
}
}
return null;
}
private void updateLastResult(MergedAnnotation<A> candidate) {
MergedAnnotation<A> lastResult = this.result;
this.result = (lastResult != null ? this.selector.select(lastResult, candidate) : candidate);
}
@Override
@Nullable
public MergedAnnotation<A> finish(@Nullable MergedAnnotation<A> result) {
return (result != null ? result : this.result);
}
}
在 MergedAnnotationFinder#process()方法中出现了 AnnotationTypeMappings ,该类型表示一个注解与其元注解之间关联关系 AnnotationTypeMapping的集合。直白点说,AnnotationTypeMappings用于描述一个注解有哪些元注解,元注解又有哪些元注解。
AnnotationTypeMapping是整个元注解机制实现的核心,除了注解关系的映射外,它还为属性别名等机制提供支持,这部分内容将在后文更详细的介绍。
AnnotationTypeMappings.forAnnotationType静态方法用于创建一个AnnotationTypeMappings实例:
static AnnotationTypeMappings forAnnotationType(Class<? extends Annotation> annotationType,
RepeatableContainers repeatableContainers, AnnotationFilter annotationFilter) {
// 针对可重复注解的容器缓存
if (repeatableContainers == RepeatableContainers.standardRepeatables()) {
return standardRepeatablesCache.computeIfAbsent(annotationFilter,
key -> new Cache(repeatableContainers, key)).get(annotationType);
}
// 针对不可重复注解的容器缓存
if (repeatableContainers == RepeatableContainers.none()) {
return noRepeatablesCache.computeIfAbsent(annotationFilter,
key -> new Cache(repeatableContainers, key)).get(annotationType);
}
// 创建一个AnnotationTypeMappings实例
return new AnnotationTypeMappings(repeatableContainers, annotationFilter, annotationType);
}
出于减少重复的解析操作的目的,AnnotationTypeMappings 类维护了 noRepeatablesCache 和 standardRepeatablesCache 两个 Map 集合用于存储已经解析好的注解类和其可重复注解容器的映射关系。
最终调用的 AnnotationTypeMappings 实例构造方法如下:
private AnnotationTypeMappings(RepeatableContainers repeatableContainers,
AnnotationFilter filter, Class<? extends Annotation> annotationType) {
this.repeatableContainers = repeatableContainers; // 可重复注解的容器
this.filter = filter; // 过滤
this.mappings = new ArrayList<>(); // 映射关系
addAllMappings(annotationType); // 解析当前类以及其元注解的层次结构中涉及到的全部映射关系
this.mappings.forEach(AnnotationTypeMapping::afterAllMappingsSet); // 映射关系解析完后对别名的一些校验
}
显而易见,addAllMappings() 方法就是最关键的步骤,这个方法将用于将元注解的类型跟声明元注解的数据源进行绑定。
举个例子,假如现在有一个注解 @A,上面还有一个元注解 @B,@B上又存在一个元注解 @C则解析流程如下:
- 解析注解
@A,由于其已经是根注解了,故此时数据源为null,将数据源与他的元注解@A封装为一个AnnotationTypeMapping,这里称为M1。则M1即为元注解@A与数据源的映射; - 解析上一步得到的数据源,也就是
M1,然后获其中元注解@A上的元注解@B,然后将数据源M1与@B再封装为一个AnnotationTypeMapping,这里称为M2。则M2即为元注解@B与M1——或者说@A——的映射; - 以此类推,广度优先遍历到最后一层;
最终,所有的注解的映射 M1 ,M2,M3都被添加到了 AnnotationTypeMappings的 mapping集合,并且 M1 和 M2 以及 M3也按照 @A 和 @B的关系建立了关系,就像一个 LinkedHashMap。
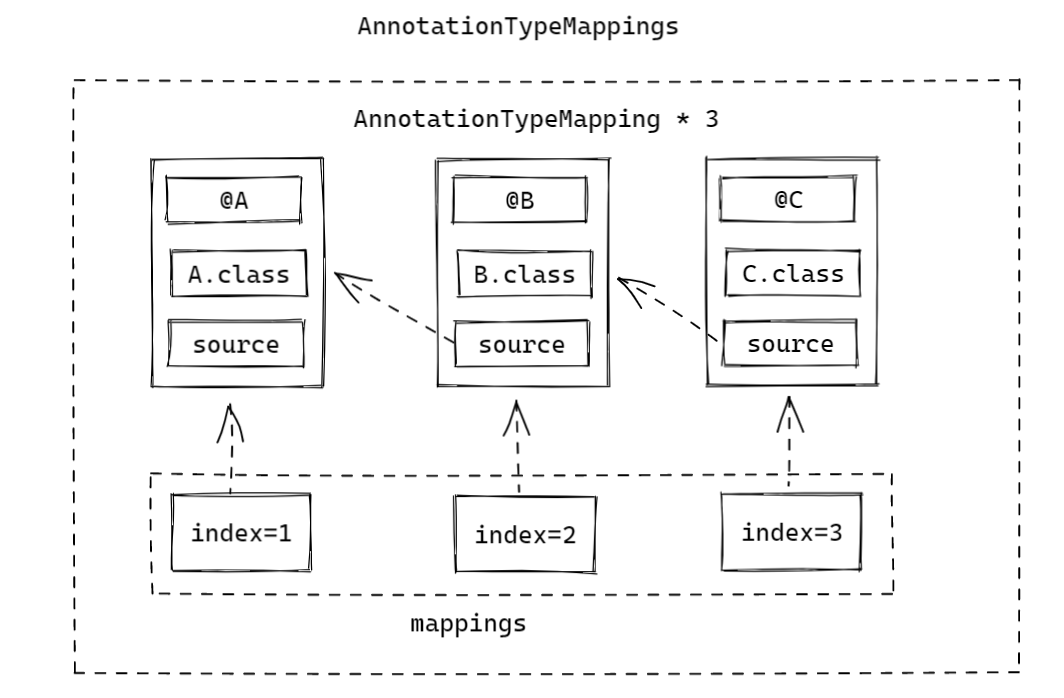
具体代码如下:
private void addAllMappings(Class<? extends Annotation> annotationType) {
// 广度优先遍历注解和元注解
Deque<AnnotationTypeMapping> queue = new ArrayDeque<>();
addIfPossible(queue, null, annotationType, null); // 1.1 添加待解析的元注解
while (!queue.isEmpty()) {
AnnotationTypeMapping mapping = queue.removeFirst();
this.mappings.add(mapping);
// 继续解析下一层
addMetaAnnotationsToQueue(queue, mapping); // 1.2 解析的元注解
}
}
// 1.1 添加待解析的元注解
private void addIfPossible(Deque<AnnotationTypeMapping> queue, @Nullable AnnotationTypeMapping source,
Class<? extends Annotation> annotationType, @Nullable Annotation ann) {
try {
// 将数据源、元注解类型和元注解实例封装为一个AnnotationTypeMapping,作为下一次处理的数据源
queue.addLast(new AnnotationTypeMapping(source, annotationType, ann));
}
catch (Exception ex) {
AnnotationUtils.rethrowAnnotationConfigurationException(ex);
if (failureLogger.isEnabled()) {
failureLogger.log("Failed to introspect meta-annotation " + annotationType.getName(),
(source != null ? source.getAnnotationType() : null), ex);
}
}
}
// 1.2 解析的元注解
private void addMetaAnnotationsToQueue(Deque<AnnotationTypeMapping> queue, AnnotationTypeMapping source) {
// 获取当前注解上直接声明的元注解
Annotation[] metaAnnotations = AnnotationsScanner.getDeclaredAnnotations(source.getAnnotationType(), false);
for (Annotation metaAnnotation : metaAnnotations) {
// 若已经解析过了则跳过,避免“循环引用”
if (!isMappable(source, metaAnnotation)) {
continue;
}
// a.若当前正在解析的注解是容器注解,则将内部的可重复注解取出解析
Annotation[] repeatedAnnotations = this.repeatableContainers.findRepeatedAnnotations(metaAnnotation);
if (repeatedAnnotations != null) {
for (Annotation repeatedAnnotation : repeatedAnnotations) {
// 1.2.1 判断是否已经完成映射
if (!isMappable(source, repeatedAnnotation)) {
continue;
}
addIfPossible(queue, source, repeatedAnnotation);
}
}
// b.若当前正在解析的注解不是容器注解,则将直接解析
else {
addIfPossible(queue, source, metaAnnotation);
}
}
}
// 1.2.1 判断是否已经完成映射
private boolean isMappable(AnnotationTypeMapping source, @Nullable Annotation metaAnnotation) {
return (metaAnnotation != null && !this.filter.matches(metaAnnotation) &&
!AnnotationFilter.PLAIN.matches(source.getAnnotationType()) &&
!isAlreadyMapped(source, metaAnnotation));
}
private boolean isAlreadyMapped(AnnotationTypeMapping source, Annotation metaAnnotation) {
Class<? extends Annotation> annotationType = metaAnnotation.annotationType();
// 递归映射表,确定这个注解类型是否在映射表的树结构中存在
// 这个做法相当于在循环引用中去重
AnnotationTypeMapping mapping = source;
while (mapping != null) {
if (mapping.getAnnotationType() == annotationType) {
return true;
}
mapping = mapping.getSource();
}
return false;
}
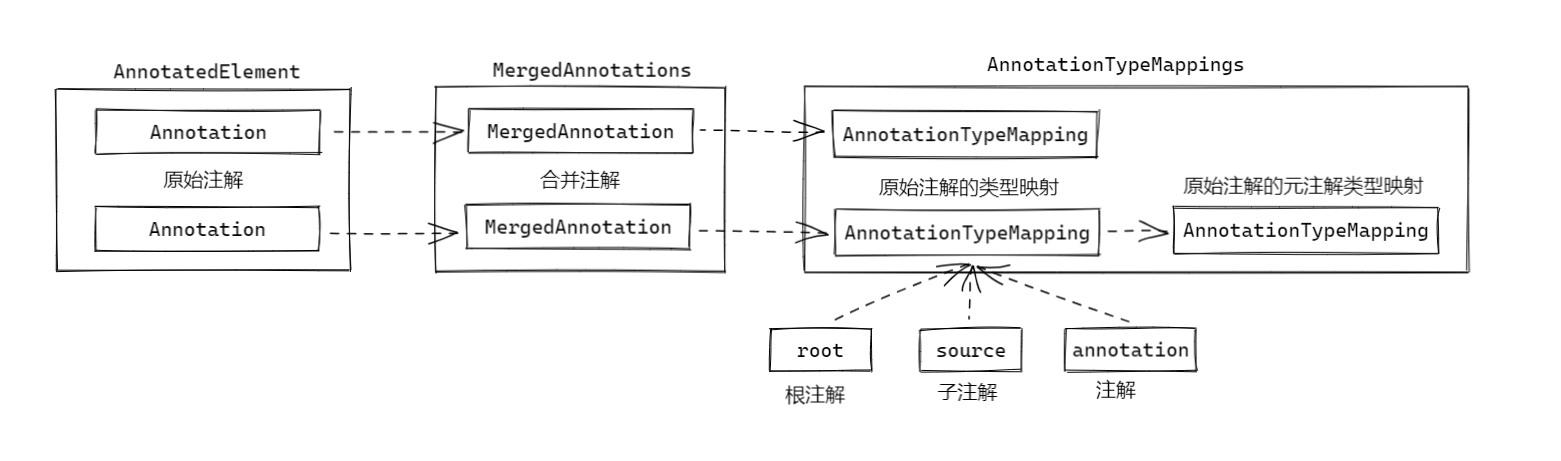
当获得聚合注解 MergedAnnotations 后,再通过 get 方法获取到指定的合并注解这个过程,需要经过下述四个过程。
- 在聚合注解
MergedAnnotations中根据传入的注解过滤器AnnotationFilter以及一些校验,从指定的注解或数据源的层级结构中获取待解析的注解; - 创建一个注解处理器
MergedAnnotationFinder,然后再为其创建一个注解选择器MergedAnnotationSelector,该处理器将用于处理上一个步骤扫描到的待解析注解; - 遍历待解析注解,然后使用注解处理器
MergedAnnotationFinder处理:- 先根据注解的类型创建一个聚合的注解类型映射表
AnnotationTypeMappings,该表用于表示一个数据源上所有注解以及元注解之间的层级关系; - 聚合的注解类型映射表
AnnotationTypeMappings会根据广度优先遍历待解析的注解的层级结构,然后依次以数据源上的某个注解作为根注解,然后它和它的某个元注解的映射关系封装为AnnotationTypeMapping; - 若
AnnotationTypeMapping对应的注解仍然存在元注解,就继续一层一层的递归,直到整个层级结构都被转为AnnotationTypeMapping并且记录到AnnotationTypeMappings为止,此时每个根注解对应的AnnotationTypeMappings都维持着一个类似链表的接口,元注解的AnnotationTypeMapping会持有声明它的数据源注解的AnnotationTypeMapping引用;
- 先根据注解的类型创建一个聚合的注解类型映射表
MergedAnnotationFinder将遍历并递归所有AnnotationTypeMapping,筛选出所有匹配的AnnotationTypeMapping,接着再将其封装为MergedAnnotation,最后使用MergedAnnotationSelector从中选择出一个最合适的——总体来说离根注解越近越合适——作为get的查询结果。
由于 spring 提供了基于 @AliasFor 注解的别名机制,允许注解内部的属性互为别名,或者与它的元注解中的属性互为别名,这一步同样在AnnotationTypeMapping创建时完成,由于涉及到内容较多,因此作为单独的一节描述。
根据@AlisaFor 作用与注解内和注解外,造成的效果可以简单分为两种:
- 镜像:当同一注解类中的两个属性互为别名时,则对两者任一属性赋值,等同于对另一属性赋值;
- 覆写:当子注解和元注解中的两个属性互为别名时,对子注解中的属性赋值,将覆盖元注解中的属性;
其中,镜像效果依赖于 MirrorSet,而覆写的效果依赖于 AnnotationTypeMapping 中各种 mapping 结尾的变量,这些数据结构共同维护的同注解与不同注解间的属性映射关系,这些都在AnnotationTypeMapping的构造方法中完成:
AnnotationTypeMapping(@Nullable AnnotationTypeMapping source,
Class<? extends Annotation> annotationType, @Nullable Annotation annotation) {
this.source = source; // 声明当前元注解类型的数据源
this.root = (source != null ? source.getRoot() : this); // 根节点
this.distance = (source == null ? 0 : source.getDistance() + 1); // 距离根节点的距离
this.metaTypes = merge( // 到当前元注解为止前面合并了多少元注解
source != null ? source.getMetaTypes() : null,
annotationType);
// 当前元注解与类型
this.annotationType = annotationType;
this.annotation = annotation;
// 当前元注解的属性
this.attributes = AttributeMethods.forAnnotationType(annotationType);
// 属性别名与相关的值缓存
this.mirrorSets = new MirrorSets();
this.aliasMappings = filledIntArray(this.attributes.size());
this.conventionMappings = filledIntArray(this.attributes.size());
this.annotationValueMappings = filledIntArray(this.attributes.size());
this.annotationValueSource = new AnnotationTypeMapping[this.attributes.size()];
this.aliasedBy = resolveAliasedForTargets();
// 初始化别名属性,为所有存在别名的属性建立MirrorSet
processAliases();
// 为当前注解内互为并名的属性建立属性映射
addConventionMappings();
// 为跨注解互为别名的属性建立属性映射
addConventionAnnotationValues();
this.synthesizable = computeSynthesizableFlag();
}
在 AnnotationTypeMapping 创建时,将会通过反射把当前的元注解全部属性的获取方法解析出来,然后封装为一个聚合属性 AttributeMethods 并赋值给同名变量,在构造函数中对应代码 :
this.attributes = AttributeMethods.forAnnotationType(annotationType)
AttributeMethods 内部维护了一个方法的数组,并以此提供基于下标或方法名称访问注解属性的能力。
这里尤其需要注意的是,或许是出于性能考虑,spring 在元注解属性映射这边的代码实现,几乎全部都是依靠数组记录变量,然后依靠下标来传递引用关系。
所以这里需要特别记住一点,在后续几乎所有数组的下标,都与AttributeMethods中属性方法的数组下标对应,即某个属性在属性方法数组中的下标 index = 1 ,则后续所有相关数组下标为 1 的位置,都与该属性有关。
首先,spring 将AttributeMethods中所有的带有@AliasFor注解的属性方法取出,然后解析注解并生成别名属性映射表 aliasedBy,这一段在构造函数中对应:
this.aliasedBy = resolveAliasedForTargets();
而 resolveAliasedForTargets 对应实现如下:
private Map<Method, List<Method>> resolveAliasedForTargets() {
Map<Method, List<Method>> aliasedBy = new HashMap<>();
for (int i = 0; i < this.attributes.size(); i++) {
// 遍历当前注解的属性方法,并获取其中的带有@AliasFor的方法
Method attribute = this.attributes.get(i);
AliasFor aliasFor = AnnotationsScanner.getDeclaredAnnotation(attribute, AliasFor.class);
if (aliasFor != null) {
// 获取别名指定的注解类中的方法,并建立别名属性 -> [属性1]的映射集合
Method target = resolveAliasTarget(attribute, aliasFor);
aliasedBy.computeIfAbsent(target, key -> new ArrayList<>()).add(attribute);
}
}
return Collections.unmodifiableMap(aliasedBy);
}
private Method resolveAliasTarget(Method attribute, AliasFor aliasFor) {
return resolveAliasTarget(attribute, aliasFor, true);
}
resolveAliasTarget 最终将获得@AlisaFor注解所指定的别名方法,具体如下:
private Method resolveAliasTarget(Method attribute, AliasFor aliasFor, boolean checkAliasPair) {
if (StringUtils.hasText(aliasFor.value()) && StringUtils.hasText(aliasFor.attribute())) {
throw new AnnotationConfigurationException(String.format(
"In @AliasFor declared on %s, attribute 'attribute' and its alias 'value' " +
"are present with values of '%s' and '%s', but only one is permitted.",
AttributeMethods.describe(attribute), aliasFor.attribute(),
aliasFor.value()));
}
// 1、若Annotation指定的是Annotation,则认为目标就是当前注解类
Class<? extends Annotation> targetAnnotation = aliasFor.annotation();
if (targetAnnotation == Annotation.class) {
targetAnnotation = this.annotationType;
}
// 2、获取alisaFrom#attribute,若为空则再获取alisaFrom#value
String targetAttributeName = aliasFor.attribute();
if (!StringUtils.hasLength(targetAttributeName)) {
targetAttributeName = aliasFor.value();
}
if (!StringUtils.hasLength(targetAttributeName)) {
targetAttributeName = attribute.getName();
}
// 3、从指定类中获得别名指定指定的注解属性对应的方法
Method target = AttributeMethods.forAnnotationType(targetAnnotation).get(targetAttributeName);
if (target == null) {
// a.校验是否能找到别名方法
if (targetAnnotation == this.annotationType) {
throw new AnnotationConfigurationException(String.format(
"@AliasFor declaration on %s declares an alias for '%s' which is not present.",
AttributeMethods.describe(attribute), targetAttributeName));
}
throw new AnnotationConfigurationException(String.format(
"%s is declared as an @AliasFor nonexistent %s.",
StringUtils.capitalize(AttributeMethods.describe(attribute)),
AttributeMethods.describe(targetAnnotation, targetAttributeName)));
}
// b.校验别名与原属性对应的方法是否不为一个方法
if (target.equals(attribute)) {
throw new AnnotationConfigurationException(String.format(
"@AliasFor declaration on %s points to itself. " +
"Specify 'annotation' to point to a same-named attribute on a meta-annotation.",
AttributeMethods.describe(attribute)));
}
// c.校验别名与原属性对应的方法返回值是否一致
if (!isCompatibleReturnType(attribute.getReturnType(), target.getReturnType())) {
throw new AnnotationConfigurationException(String.format(
"Misconfigured aliases: %s and %s must declare the same return type.",
AttributeMethods.describe(attribute),
AttributeMethods.describe(target)));
}
// d.若有必要,则再校验声明别名方法的注解是@AlisaFor指定的注解类型
if (isAliasPair(target) && checkAliasPair) {
AliasFor targetAliasFor = target.getAnnotation(AliasFor.class);
if (targetAliasFor != null) {
Method mirror = resolveAliasTarget(target, targetAliasFor, false);
if (!mirror.equals(attribute)) {
throw new AnnotationConfigurationException(String.format(
"%s must be declared as an @AliasFor %s, not %s.",
StringUtils.capitalize(AttributeMethods.describe(target)),
AttributeMethods.describe(attribute), AttributeMethods.describe(mirror)));
}
}
}
return target;
}
在这一步,他做了以下逻辑处理:
- 确定别名属性所在的注解类:若
@AlisaFor#annotation属性保持默认值Annotation.class,则认为别名属性所在的注解就是当前解析的注解; - 确定别名属性对应的方法名:优先获取
alisaFrom#attribute同名属性,若alisaFrom#attribute为空则获取alisaFrom#value同名方法; - 获取别名属性对应的方法;
- 校验该别名方法对应方法是否不是当前注解属性的方法;
- 校验别名方法返回值类型与当前注解属性的方法返回值类型是否一致;
- 校验声明该方法的类就是注解指定的注解类;
最终,完成这一步后,将构建出以别名方法作为 key,当前注解中对应的原始属性的方法作为 value的别名属性-原始属性映射表 aliasedBy。
在第二步在aliasedBy中加载了当前注解中所有别名属性与注解中原始属性的映射关系后,将根据此进一步组织注解属性与别名的映射关系。此步骤对应构造函数中的代码片段如下:
this.mirrorSets = new MirrorSets();
this.aliasMappings = filledIntArray(this.attributes.size());
this.conventionMappings = filledIntArray(this.attributes.size());
this.annotationValueMappings = filledIntArray(this.attributes.size());
this.annotationValueSource = new AnnotationTypeMapping[this.attributes.size()];
// 初始化别名属性,为所有存在别名的属性建立MirrorSet
processAliases();
processAliases 是直接入口:
private void processAliases() {
List<Method> aliases = new ArrayList<>();
// 遍历当前注解中的属性,处理属性与其相关的别名
for (int i = 0; i < this.attributes.size(); i++) {
aliases.clear(); // 复用集合避免重复创建
aliases.add(this.attributes.get(i));
// 1.收集注解
collectAliases(aliases);
if (aliases.size() > 1) {
// 2.处理注解
processAliases(i, aliases);
}
}
}
从功能来说,这段代码分为采集注解和处理注解两部分:
搜集以当前注解属性作为别名的子注解属性
private void collectAliases(List<Method> aliases) {
AnnotationTypeMapping mapping = this;
while (mapping != null) {
int size = aliases.size();
for (int j = 0; j < size; j++) {
List<Method> additional = mapping.aliasedBy.get(aliases.get(j)); // 获取以该属性作为别名的子类属性
if (additional != null) {
aliases.addAll(additional);
}
}
mapping = mapping.source; // 继续向声明当前元注解的子注解递归
}
}
收集注解这一步,将以当前元注解的某个属性为根属性,从当前元注解向子注解递归,并最终收集到全部直接或间接以当前根属性作为别名的子类属性。
比如,假如A.name的别名是 B.name,B.name的别名是 C.name,则从 C.name 开始向子注解递归,最终在 aliases 集合中收集到的就是 [C.name, B.name, A.name]。
当然,加入 A.name 还存在一个别名 A.alisaName,则实际最终在 aliases 集合中收集到的就是 [C.name, C.alisaName, B.name, A.name]。
处理注解
处理注解的 processAliases 增体流程依然是从当前元注解递归向子注解进行,并且处理过程中的逻辑大体分为三部分:
- 第一部分,若根注解——即最小的子注解——存在以元注解属性作为别名的原始属性,则以根注解属性覆盖元注解中的属性,并在该元注解的成员变量
aliasMappings中记录根注解原始属性的下标; - 第二部分,为各级注解中同一注解内互为别名的字段,以及根注解中不存在的、且不同注解间互为别名的字段建立镜像映射关系表
MirrorSet; - 第三部分,根据
MirrorSet,构建各级注解中被作为别名属性的属性,与调用时实际对应的注解属性及子类注解实例的映射表annotationValueMappingsannotationValueSource;
private void processAliases(int attributeIndex, List<Method> aliases) {
// 1.若根注解——即最小的子注解——存在以元注解属性作为别名的原始属性,则以根注解属性覆盖元注解中的属性,并在该元注解的成员变量`aliasMappings` 中记录根注解原始属性的下标;
int rootAttributeIndex = getFirstRootAttributeIndex(aliases); // 若根注解中存在以aliases任意属性作为别名的属性,则返回跟注解的属性方法下标
// 从当前元注解向子注解递归
AnnotationTypeMapping mapping = this;
while (mapping != null) {
// 若根注解中存在以aliases任意属性作为别名的属性,且当前处理的注解不是根注解
// 则将当前处理的注解aliasMappings与设置为根注解中对应属性的值
// 即使用子注解的值覆盖元注解的值
if (rootAttributeIndex != -1 && mapping != this.root) {
for (int i = 0; i < mapping.attributes.size(); i++) {
if (aliases.contains(mapping.attributes.get(i))) {
mapping.aliasMappings[i] = rootAttributeIndex; // 在aliasMappings记录根注解元素属性下标
}
}
}
// 2.为各级注解中同一注解内互为别名的字段,以及根注解中不存在的、且不同注解间互为别名的字段建立镜像映射关系表MirrorSet
mapping.mirrorSets.updateFrom(aliases);
mapping.claimedAliases.addAll(aliases);
// 3.根据MirrorSet,构建各级注解中被作为别名属性的属性,与调用时实际对应的注解属性及子类注解实例的映射表annotationValueMappings和annotationValueSource
if (mapping.annotation != null) {
int[] resolvedMirrors = mapping.mirrorSets.resolve(null, mapping.annotation, ReflectionUtils::invokeMethod);
for (int i = 0; i < mapping.attributes.size(); i++) {
if (aliases.contains(mapping.attributes.get(i))) {
this.annotationValueMappings[attributeIndex] = resolvedMirrors[i];
this.annotationValueSource[attributeIndex] = mapping;
}
}
}
mapping = mapping.source; // 向子注解递归
}
}
private int getFirstRootAttributeIndex(Collection<Method> aliases) {
// 获取根注解的属性,若根注解中存在以aliases任意属性作为别名的属性,则返回跟注解的属性方法下标
AttributeMethods rootAttributes = this.root.getAttributes();
for (int i = 0; i < rootAttributes.size(); i++) {
if (aliases.contains(rootAttributes.get(i))) {
return i;
}
}
return -1;
}
第一部分没什么好说的,第二与第三部分存在嵌套的逻辑,因此将在下一小结详细介绍。
4、构建同注解内属性与别名的显式映射关系承接上文,在 processAliases 中关于根注解中不存在的属性的映射,在元注解的逻辑中是基于 MirrorSet 实现的,同一个注解类中不同属性的映射关系的构建过程实际上就是构建 MirrorSet 的过程:
private void processAliases(int attributeIndex, List<Method> aliases) {
// 从当前元注解向子注解递归
AnnotationTypeMapping mapping = this;
while (mapping != null) {
// 1.若根注解——即最小的子注解——存在以元注解属性作为别名的原始属性,则以根注解属性覆盖元注解中的属性,并在该元注解的成员变量`aliasMappings` 中记录根注解原始属性的下标;
// ... ...
// 构建 MirrorSet
mapping.mirrorSets.updateFrom(aliases);
mapping.claimedAliases.addAll(aliases);
// 3.根据MirrorSet,构建各级注解中被作为别名属性的属性,与调用时实际对应的注解属性及子类注解实例的映射表annotationValueMappings和annotationValueSource
// ... ...
mapping = mapping.source; // 向子注解递归
}
}
由于 AnnotationTypeMapping 本身在初始化时也一并初始化了一个 MirrorSets 实例用于管理 MirrorSet,因此在代码中直接调用updateFrom 即可:
// code in MirrorSets
void updateFrom(Collection<Method> aliases) {
MirrorSet mirrorSet = null;
int size = 0;
int last = -1;
// 遍历当前元注解的全部属性
for (int i = 0; i < attributes.size(); i++) {
Method attribute = attributes.get(i);
// 若当前元注解的属性有被作为别名,则在MirrorSets.assigned数组中与当前属性方法相同下标的位置设置一个MirrorSet实例
if (aliases.contains(attribute)) {
size++;
if (size > 1) {
if (mirrorSet == null) {
mirrorSet = new MirrorSet();
this.assigned[last] = mirrorSet;
}
this.assigned[i] = mirrorSet;
}
last = i;
}
}
// 参数mirrorSet,并更新集合
if (mirrorSet != null) {
mirrorSet.update();
Set<MirrorSet> unique = new LinkedHashSet<>(Arrays.asList(this.assigned));
unique.remove(null);
this.mirrorSets = unique.toArray(EMPTY_MIRROR_SETS);
}
}
updateFrom的逻辑简单的概况一下,就是遍历所有的元注解对应的AnnotationTypeMapping,然后如果每个注解中存在作为别名的属性,则在 ``AnnotationTypeMapping.MirrorSets.assigned数组中与该属性方法对应的数组下标处设置一个MirrorSet` 实例,表示该属性是别名属性。
然后再调用 MirrorSet#update 方法:
void update() {
this.size = 0;
Arrays.fill(this.indexes, -1);
for (int i = 0; i < MirrorSets.this.assigned.length; i++) {
if (MirrorSets.this.assigned[i] == this) {
this.indexes[this.size] = i;
this.size++;
}
}
}
可见 MirrorSet 会记录该实例在 assigned 数组中出现的位置,然后将其记录在 indexes 数组中,由于 assigned 数组与 AttributeMethod 中属性方法数组一一对应,因此 indexes 数组实际就是相同注解中互为别名的属性,互为别名的属性通过同一个 MirrorSet 实例绑定在了一起。
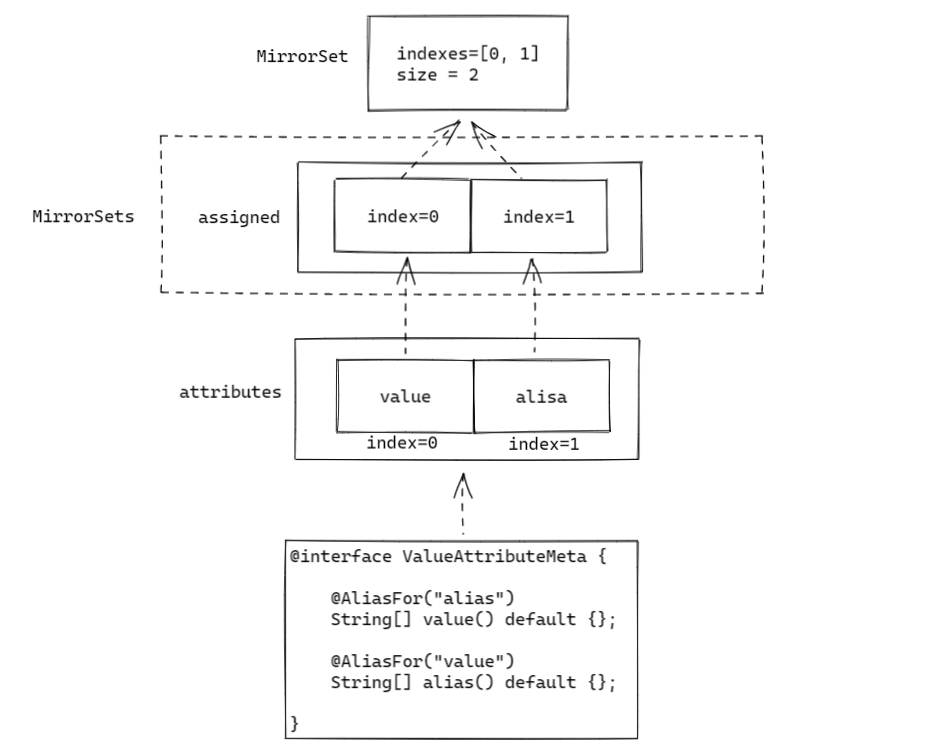
仍然承接上文,继续解析 processAliases 的第三部分逻辑,这里实际上还是分为两部分:
- 第一部分:从同一注解中互为别名的属性里面选出一个最终有效的属性,作为他们实际属性值的来源;
- 第二部分:处理不同注解中互为别名的属性,为其设置好对应的数据源与数据源中原始属性的下标
源码如下:
private void processAliases(int attributeIndex, List<Method> aliases) {
// 1.若根注解——即最小的子注解——存在以元注解属性作为别名的原始属性,则以根注解属性覆盖元注解中的属性,并在该元注解的成员变量`aliasMappings` 中记录根注解原始属性的下标;
// ... ...
// 2.为各级注解中同一注解内互为别名的字段,以及根注解中不存在的、且不同注解间互为别名的字段建立镜像映射关系表MirrorSet
// ... ...
// 3.根据MirrorSet,构建各级注解中被作为别名属性的属性,与调用时实际对应的注解属性及子类注解实例的映射表annotationValueMappings和annotationValueSource
if (mapping.annotation != null) {
int[] resolvedMirrors = mapping.mirrorSets.resolve(null, mapping.annotation, ReflectionUtils::invokeMethod);
for (int i = 0; i < mapping.attributes.size(); i++) {
if (aliases.contains(mapping.attributes.get(i))) {
this.annotationValueMappings[attributeIndex] = resolvedMirrors[i];
this.annotationValueSource[attributeIndex] = mapping;
}
}
}
mapping = mapping.source; // 向子注解递归
}
处理同注解内互为别名的字段
这一步主要依靠 resolve 方法完成,先调用了 MirrorSets 的 resolve :
int[] resolve(@Nullable Object source, @Nullable Object annotation, ValueExtractor valueExtractor) {
// 获取当前注解的各属性下标,默认每个属性都从自身取值
int[] result = new int[attributes.size()];
for (int i = 0; i < result.length; i++) {
result[i] = i;
}
// 遍历所有MirrorSet实例
for (int i = 0; i < size(); i++) {
MirrorSet mirrorSet = get(i);
// 从同一个注解中一堆互为别名的属性中获取一个最终有效的属性的方法下标,然后所有的属性都以这个属性的值为准
int resolved = mirrorSet.resolve(source, annotation, valueExtractor);
for (int j = 0; j < mirrorSet.size; j++) {
result[mirrorSet.indexes[j]] = resolved;
}
}
return result;
}
// 1.2.2.1 获取别名映射 in MirrorSets
Method get(int index) {
int attributeIndex = this.indexes[index];
return attributes.get(attributeIndex);
}
然后调用 MirrorSet 的 resolve :
<A> int resolve(@Nullable Object source, @Nullable A annotation, ValueExtractor valueExtractor) {
int result = -1;
Object lastValue = null; // 最近一个的有效属性值
// 遍历与当前注解属性属性互为别名的全部属性
for (int i = 0; i < this.size; i++) {
// 获取属性值
Method attribute = attributes.get(this.indexes[i]);
Object value = valueExtractor.extract(attribute, annotation);
boolean isDefaultValue = (value == null ||
isEquivalentToDefaultValue(attribute, value, valueExtractor));
// 如果属性值是默认值,或者与最后有效值相同,则记录该属性下标后返回
// 以此类推,如果一组互为别名的属性全部都是默认值,则前面的属性——即离根注解最近的——的默认值会作为最终有效值
if (isDefaultValue || ObjectUtils.nullSafeEquals(lastValue, value)) {
if (result == -1) {
result = this.indexes[i];
}
continue;
}
// 如果属性值不是默认值,并且与最近一个的有效属性值不同, 则抛出异常
// 这里实际要求一组互为别名的属性中,只允许一个属性的值是非默认值
if (lastValue != null && !ObjectUtils.nullSafeEquals(lastValue, value)) {
String on = (source != null) ? " declared on " + source : "";
throw new AnnotationConfigurationException(String.format(
"Different @AliasFor mirror values for annotation [%s]%s; attribute '%s' " +
"and its alias '%s' are declared with values of [%s] and [%s].",
getAnnotationType().getName(), on,
attributes.get(result).getName(),
attribute.getName(),
ObjectUtils.nullSafeToString(lastValue),
ObjectUtils.nullSafeToString(value)));
}
result = this.indexes[i];
lastValue = value;
}
return result;
}
这里的逻辑应该是比较清晰的,首先,如果同一个注解内存在多个互为别名的属性,则需要有一个唯一有效的最终属性,所有互为别名的属性应当以这个最终属性的值为准。
对应到代码中,则就是通过遍历 MirrorSet 中互为别名的字段,然后根据下述规则找到最终属性:
- 如果所有属性都只有默认值,则离根注解最近的属性最为最终属性;
- 如果所有属性中存在属性有非默认值,则该属性就作为默认属性,若出现多个有非默认值的属性,则直接报错;
然后返回这个最终属性的下标。
将 MirrorSets 中的全部 MirrorSet 按上述过程处理后,我们会得到这个注解中每个属性的最终属性,对应到代码:
int[] resolvedMirrors = mapping.mirrorSets.resolve(null, mapping.annotation, ReflectionUtils::invokeMethod);
实际上得到的 resolvedMirrors 就是与注解中属性方法对应的最终属性集合。
我们举个例子,假如现在有 A,B,C,D,E 五个属性,其中 A 和 B、C 和 D 互为别名,则经过 MirrorSets#resolve 方法最终得到的 resolvedMirrors 如下图:
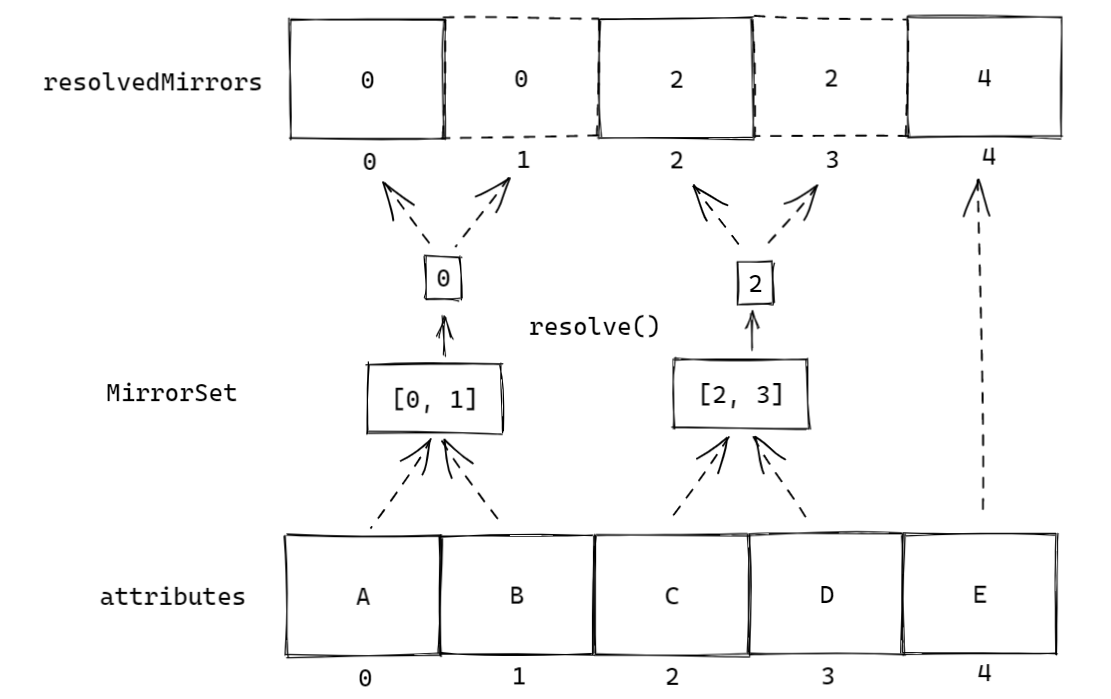
把resolvedMirrors翻译一下,就是 A 和 B 取值时都取 A 的值,C 和 D 取值时都取 C 的值,而 E 取值照样取 E 的值。
处理不同注解中互为别名的属性
理解了 resolvedMirrors 是个什么玩意后,我们继续回到 processAliases 方法的代码:
// 获取当前元注解中互为别名的属性对应的实际取值的最终属性
// aliases表示从元注解到子注解中所有跨注解互为别名的属性
int[] resolvedMirrors = mapping.mirrorSets.resolve(null, mapping.annotation, ReflectionUtils::invokeMethod);
for (int i = 0; i < mapping.attributes.size(); i++) {
// 若当前注解中存在别名属性 i
if (aliases.contains(mapping.attributes.get(i))) {
// 则该属性取值时,从annotationValueSource[i]获取目标注解,然后再从目标注解的resolvedMirrors[i]属性获取对应的值
this.annotationValueMappings[attributeIndex] = resolvedMirrors[i];
this.annotationValueSource[attributeIndex] = mapping;
}
}
这里的逻辑也很清晰,假如子注解 @A 的 x 属性是其元注解 @B 的属性 y 的别名时,当我们获取 @B.y(),则实际到的是 @A.x()。
回到代码中,为了实现这个效果,这里通过下标 i 表示别名属性,然后再在 annotationValueSource[i] 记录的实际取值的注解实例,接着又在 annotationValueMappings[i] 记录了要从实际取值的注解实例中的那个属性取值。
举个例子,假如现在有注解 @B 和其元注解 @A,@A 的属性 X 是元注解 @B 属性 C 的别名,则从 @A 开始解析后, 最终我们可以在 A.class 中得到下图结果:
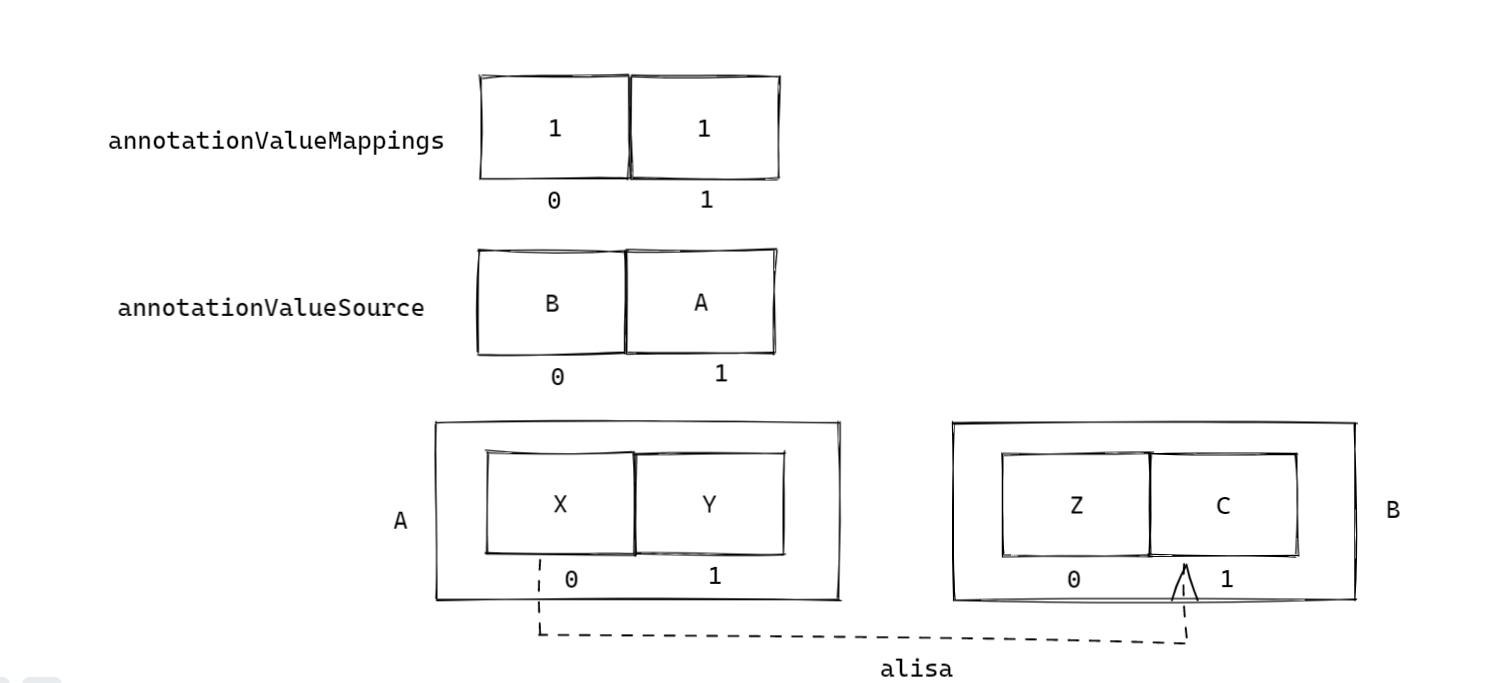
由于 @A.X() 存在跨注解别名 @B.C(),则 X 的对应 AttributeMethods[0] ,则其下标0 对应的 annotationValueSource[0] 存放的就是 @B 的实例,然后 annotationValueMappings[0] 存放的就是 @B.C() 在 @B 中的方法索引 1。
现在,通过 annotationValueMappings,annotationValueSource以及 AttributeMethods这三个成员变量,任何一个使用@AlisaFor 注解配置了别名的属性都可以找到真正对应的值。
使用 @AlisaFor 注解在 spring 中称为显式别名,对应的还有一个隐式别名,也就是只要子注解和元注解的属性名称相同,则就会使用子注解的属性值覆盖元注解的属性值,即子注解的属性会强制作为元注解属性的别名。
这个隐式映射的优先级高于显式映射,换而言之,如果你在子注解为一个元注解通过@AlisaFor 指定了显式别名,但是偏偏子注解中海油一个属性与这个元注解中的属性同名,则最终取值时,优先取子注解中的同名字段,而不是通过 @AlisaFor 指定的别名字段。
在 AnnotationTypeMapping 的构造函数中,共分为两步:
// 为元注解与根注解同名的属性强制设置别名
addConventionMappings();
// 为元注解与非根注解的子注解的同名的属性设置别名
addConventionAnnotationValues();
为元注解与根注解同名的属性强制设置别名
这一步将遍历当前注解中的属性,然后判断是否在根注解中存在同名属性,若存则直接将 conventionMappings 中对应下标的位置设置为根注解对应属性的下标。
private void addConventionMappings() {
if (this.distance == 0) {
return;
}
AttributeMethods rootAttributes = this.root.getAttributes();
int[] mappings = this.conventionMappings;
for (int i = 0; i < mappings.length; i++) {
// 遍历当前注解的属性,判断是否在根注解存在
String name = this.attributes.get(i).getName();
int mapped = rootAttributes.indexOf(name);
// 若存在,并且该属性不为“value”
MirrorSet mirrors = getMirrorSets().getAssigned(i);
if (!MergedAnnotation.VALUE.equals(name) && mapped != -1) {
mappings[i] = mapped;
// 若该属性还有别名,则让该属性和全部别名属性都从根注解取值
if (mirrors != null) {
for (int j = 0; j < mirrors.size(); j++) {
mappings[mirrors.getAttributeIndex(j)] = mapped;
}
}
}
}
}
为元注解与非根注解的子注解的同名的属性设置别名
这一步将从当前注解向不包括根注解在内的子注解递归:
- 若自注解中存在同名字段,则将与当前属性对应位置的
annotationValueSource和annotationValueMappings设置为该子注解和该注解中同名属性的方法下标; - 若子注解的子注解中仍然存在同名注解,则选择一个离根注解最近的子注解,重复上述过程;
- 重复上述两步直到全部子注解递归完毕;
private void addConventionAnnotationValues() {
// 遍历当前注解的全部属性
for (int i = 0; i < this.attributes.size(); i++) {
Method attribute = this.attributes.get(i);
boolean isValueAttribute = MergedAnnotation.VALUE.equals(attribute.getName());
AnnotationTypeMapping mapping = this;
// 从当前注解向非根注解的子注解递归
while (mapping != null && mapping.distance > 0) {
// 若当前方法在子注解中存在,则将annotationValueMappings和annotationValueSource替换为该子注解和子注解的属性
// 由于替换前会比较annotationValueSource中注解距离根注解的距离,
// 所以之前设置的根注解属性不受影响,因为跟注解距离为0,优先级总是最高的
int mapped = mapping.getAttributes().indexOf(attribute.getName());
if (mapped != -1 && isBetterConventionAnnotationValue(i, isValueAttribute, mapping)) {
this.annotationValueMappings[i] = mapped;
this.annotationValueSource[i] = mapping;
}
mapping = mapping.source;
}
}
}
private boolean isBetterConventionAnnotationValue(int index, boolean isValueAttribute,
AnnotationTypeMapping mapping) {
if (this.annotationValueMappings[index] == -1) {
return true;
}
int existingDistance = this.annotationValueSource[index].distance;
return !isValueAttribute && existingDistance > mapping.distance;
}
设置当前注解的可合成标记
这一步很简单,就是判断当前注解是否可以被用于合成 MergedAnnotation ,依据是三点:
- 当前注解是否存在别名字段;
- 当前注解是否是元注解,并且子类注解中有属性是当前注解属性的别名;
- 如果当前注解的属性中有为注解类型的属性,那么这个属性对应的类型是否符合上述两点;
private boolean computeSynthesizableFlag() {
// 是否有属性存在@AlisaFor注解
for (int index : this.aliasMappings) {
if (index != -1) {
return true;
}
}
if (!this.aliasedBy.isEmpty()) {
return true;
}
// 是否有属性被子注解的别名覆盖
for (int index : this.conventionMappings) {
if (index != -1) {
return true;
}
}
// 是否存在注解类型的属性字段
if (getAttributes().hasNestedAnnotation()) {
AttributeMethods attributeMethods = getAttributes();
for (int i = 0; i < attributeMethods.size(); i++) {
Method method = attributeMethods.get(i);
Class<?> type = method.getReturnType();
if (type.isAnnotation() || (type.isArray() && type.getComponentType().isAnnotation())) {
Class<? extends Annotation> annotationType =
(Class<? extends Annotation>) (type.isAnnotation() ? type : type.getComponentType());
AnnotationTypeMapping mapping = AnnotationTypeMappings.forAnnotationType(annotationType).get(0);
if (mapping.isSynthesizable()) {
return true;
}
}
}
}
return false;
}
属性映射实际上是在 AnnotationTypeMapping 被创建时完成的,这过程分为下述五个步骤:
- 先通过反射获取当前注解的全部属性方法,然后封装为聚合属性
AttributeMethods对象,该对象获取并通过下标来访问属性方法; - 然后,
AnnotationTypeMapping将会遍历AttributeMethods中的方法,若属性方法上存在@AliasFor注解,则会解析注解,并通过反射获取注解指定的类上的别名属性对应的方法,并与当前注解中的对应属性方法一并添加到名为aliasBy的 Map 集合中建立别名属性和当前注解属性的映射关系; - 遍历当前注解中已经注册到
aliasBy中的别名属性,然后拿着这个属性继续向子注解递归,一直到将子类中直接或间接作为该属性别名的属性全部收集完毕; - 拿着收集到的别名属性,继续从当前元注解项子注解递归,然后在处理每一层的注解时:
- 同一注解中互为别名的属性建立
MirrorSet,然后从中选择出最后实际用于取值的最终属性,MirrorSet关联的一组互为别名的属性取值时都从该最终属性获取值; - 遍历全部属性,分别在
annotationValueSource和annotationValueMappings中与该属性在AttributeMethods中下标对应的位置,记录要调用哪个注解实例和该要在注解实例中最终调用的属性;
- 同一注解中互为别名的属性建立
- 处理完
@AlisaFor声明的显示别名后,将会为子注解与元注解中的同名属性设置隐式别名:- 遍历属性,若元注解中存在与根注解同名的属性,则将根注解中同名属性的对应下标设置到
conventionMappings中; - 遍历属性,将元注解中的
annotationValueSource和annotationValueMappings,分别替换为存在同名属性,且距离根注解最近的非根子注解与该子注解同名属性的下标,;
- 遍历属性,若元注解中存在与根注解同名的属性,则将根注解中同名属性的对应下标设置到
这一步对应的 MergedAnnotation.synthesize() 方法,借助 JDK 的动态代理根据 MergedAnnotation 生成对应的注解实例:
@Override
public Optional<A> synthesize(Predicate<? super MergedAnnotation<A>> condition)
throws NoSuchElementException {
return (condition.test(this) ? Optional.of(synthesize()) : Optional.empty());
}
@Override
public A synthesize() {
if (!isPresent()) {
throw new NoSuchElementException("Unable to synthesize missing annotation");
}
A synthesized = this.synthesizedAnnotation;
if (synthesized == null) { // 只合成一次,后续合成都直接使用第一次的结果
synthesized = createSynthesized();
this.synthesizedAnnotation = synthesized;
}
return synthesized;
}
@Override
@SuppressWarnings("unchecked")
protected A createSynthesized() {
// 如果查找的类型本身就已经是代理类了,就返回注解返回它本身
if (getType().isInstance(this.rootAttributes) && !isSynthesizable()) {
return (A) this.rootAttributes;
}
// 使用动态代理生成代理类
return SynthesizedMergedAnnotationInvocationHandler.createProxy(this, getType());
}
static <A extends Annotation> A createProxy(MergedAnnotation<A> annotation, Class<A> type) {
ClassLoader classLoader = type.getClassLoader();
InvocationHandler handler = new SynthesizedMergedAnnotationInvocationHandler<>(annotation, type);
// 为注解通过动态代理生成对象,生成的代理类实现SynthesizedAnnotation.class接口作为标识
Class<?>[] interfaces = isVisible(classLoader, SynthesizedAnnotation.class) ?
new Class<?>[] {type, SynthesizedAnnotation.class} : new Class<?>[] {type};
return (A) Proxy.newProxyInstance(classLoader, interfaces, handler);
}
方法代理
SynthesizedMergedAnnotationInvocationHandler 本身实现了 InvocationHandler,当调用动态代理生成的注解实例的属性方法时,将会通过 invoke 方法获得代理的属性方法:
@Override
public Object invoke(Object proxy, Method method, Object[] args) {
if (ReflectionUtils.isEqualsMethod(method)) { // 代理equals方法
return annotationEquals(args[0]);
}
if (ReflectionUtils.isHashCodeMethod(method)) { // 代理hashCode方法
return annotationHashCode();
}
if (ReflectionUtils.isToStringMethod(method)) { // 代理toString方法
return annotationToString();
}
if (isAnnotationTypeMethod(method)) { // 代理annotationType方法
return this.type;
}
if (this.attributes.indexOf(method.getName()) != -1) { // 获取注解属性
return getAttributeValue(method);
}
throw new AnnotationConfigurationException(String.format(
"Method [%s] is unsupported for synthesized annotation type [%s]", method, this.type));
}
这里 SynthesizedMergedAnnotationInvocationHandler 分别提供了equals、hashCode、toString、annotationType、注解的属性方法等五个不同类的代理方法。
获取属性值
这里我们重点关注代理类是如何通过 getAttributeValue 获取注解的属性的。
private Object getAttributeValue(Method method) {
// 缓存属性值
Object value = this.valueCache.computeIfAbsent(method.getName(), attributeName -> {
// 获取方法返回值类型
Class<?> type = ClassUtils.resolvePrimitiveIfNecessary(method.getReturnType());
// 根据方法名与方法返回值确定要获取的属性
return this.annotation.getValue(attributeName, type).orElseThrow(
() -> new NoSuchElementException("No value found for attribute named '" + attributeName +
"' in merged annotation " + this.annotation.getType().getName()));
});
// Clone non-empty arrays so that users cannot alter the contents of values in our cache.
if (value.getClass().isArray() && Array.getLength(value) > 0) {
value = cloneArray(value);
}
return value;
}
该方法实际调用的是 MergedAnnotation 的 getAttributeValue 方法,这里我们以其实现类 TypeMappedAnnotation 为例:
@Override
@Nullable
protected <T> T getAttributeValue(String attributeName, Class<T> type) {
int attributeIndex = getAttributeIndex(attributeName, false); // 1.通过属性名获取属性在AttributeMethods中的下标
return (attributeIndex != -1 ? getValue(attributeIndex, type) : null); // 2.根据下标获取属性值
}
@Nullable
private <T> T getValue(int attributeIndex, Class<T> type) {
// 获取属性方法
Method attribute = this.mapping.getAttributes().get(attributeIndex);
// 调用属性方法,并且允许子注解使用别名机制覆盖元注解的属性
Object value = getValue(attributeIndex, true, false);
if (value == null) {
value = attribute.getDefaultValue();
}
return adapt(attribute, value, type); // 类型转换
}
@Nullable
private Object getValue(int attributeIndex, boolean useConventionMapping, boolean forMirrorResolution) {
AnnotationTypeMapping mapping = this.mapping; // 默认从当前注解开始获取对应都属性
if (this.useMergedValues) {
// 1.尝试从根注解中获取值
// 1.1.a 若根注解中存在@AlisaFor显式指定别名属性,则获取该属性下标
int mappedIndex = this.mapping.getAliasMapping(attributeIndex);
if (mappedIndex == -1 && useConventionMapping) {
// 1.1.b 若根注解中不存在@AlisaFor显式指定别名属性,则尝试查找作为隐式别名的同名属性的下标
mappedIndex = this.mapping.getConventionMapping(attributeIndex);
}
// 1.2 若根注解中存在作为元注解别名的属性,则从跟注解中获取对应的属性
if (mappedIndex != -1) {
mapping = mapping.getRoot();
attributeIndex = mappedIndex;
}
}
// 2.如果当前注解内存在互为别名的属性,则从映射关系中获取实际用于取值的最终属性
if (!forMirrorResolution) {
attributeIndex =
(mapping.getDistance() != 0 ? this.resolvedMirrors : this.resolvedRootMirrors)[attributeIndex];
}
// 3. 根据下标从注解中获取属性值
if (attributeIndex == -1) {
return null;
}
// 3.a 从根注解中取值
if (mapping.getDistance() == 0) {
Method attribute = mapping.getAttributes().get(attributeIndex);
Object result = this.valueExtractor.extract(attribute, this.rootAttributes);
return (result != null ? result : attribute.getDefaultValue());
}
// 3.b 从元注解中取值
return getValueFromMetaAnnotation(attributeIndex, forMirrorResolution);
}
@Nullable
private Object getValueFromMetaAnnotation(int attributeIndex, boolean forMirrorResolution) {
Object value = null;
if (this.useMergedValues || forMirrorResolution) {
// 根据该注解的属性映射获取值
// 即从annotationValueSource获取对应注解实例,然后再从annotationValueMappings中获取该注解对应的属性下标
// 最终返回调用结果
value = this.mapping.getMappedAnnotationValue(attributeIndex, forMirrorResolution);
}
// 如果根据属性映射获取到的值为null,再尝试直接调用本身
if (value == null) {
Method attribute = this.mapping.getAttributes().get(attributeIndex);
value = ReflectionUtils.invokeMethod(attribute, this.mapping.getAnnotation());
}
return value;
}
这边的逻辑很清晰,即算上别名属性的处理后共分为三步:
- 先尝试从根注解中获取别名值,即通过
AnnotationTypeMapping.root和AnnotationTypeMapping.conventionMapping获取; - 如果不成功,再尝试通过常规的属性映射获取别名值,即
AnnotationTypeMapping.annotationValueSource和AnnotationTypeMapping.annotationValueMappings获取; - 如果还是不成功,就直接从当前注解本身获取对应属性值;
当我们希望通过一个已经组装好的 MergedAnnotation 中获取在注解层级中存在的某个特定的注解时,spring 会通过 JDK 代理将该 MergedAnnotation 变为接口代理类实例,这个代理类实现了我们指定的注解对应的接口。
而当我们向正常的注解那样去获取注解的属性时,实际上代理类会将方法改为通过 MergedAnnotation#getAttribute 实现,该实现基于构建 MergedAnnotation 的 AnnotationTypeMapping 实例,它将根据属性名获取对应的属性在 AttributeMethods 中的下标,然后根据下标以及之前解析得到的各种属性映射关系,确定最终要调用哪个注解实例的哪个属性方法,然后最终再返回改属性值;
回顾整个流程,当我们打算从某个元素上获取 spring 所支持的元注解时,大体步骤如下:
-
从指定元素上解析直接声明的注解,然后聚合为
MergedAnnotations,然后调用MergedAnnotations#get方法,尝试获取一个MergedAnnotation; -
此时,针对元素上的每一个根注解,都会按广度优先扫描并解析注解和其元注解间的映射关系,并将每一个注解都封装为
AnnotationTypeMapping,并通过成员变量
root与source分别维护对子注解和根注解的引用; -
AnnotationTypeMapping创建时,会先解析注解属性与属性间的映射关系,步骤包括:-
将注解中的属性封装为
AttributeMethods,此后注解中的属性即对应AttributeMethods中的方法下标; -
解析带有
@AlisaFor注解的属性,然后将收集在名为alisaBy的 Map 集合变量中,再解析
alisaBy变量中每一个存在别名的方法,从元注解递归到根注解,获得注解间存在直接或间接别名关系的属性,同一注解内的属性,通过
MirrorSet建立属性在AttributeMethods中对应下标的映射关系,全部互为别名的属性最终聚合为MirrorSets。遍历
MirrorSets中的MirrorSet,然后最终从每一组互为别名的属性中,选择出其中最终用于取值的最终属性; -
在非根子注解中存在别名——包括
@AlisaFor指定或属性名相同——的元注解属性,通过annotationValueSource和annotationValueMappings数组在对应元注解属性的下标处,记录子注解与子注解指定的别名属性下标; -
在根注解中存在对应同名属性的元注解属性,通过
conventionMappings数组在对应元注解属性的下标处,记录根注解指定的别名属性下标;
-
-
根注解与其元注解都解析为
AnnotationTypeMapping后,以根注解为单位将AnnotationTypeMapping聚合为AnnotationTypeMappings; -
根据要获取的注解类型,从
AnnotationTypeMappings中筛选出对应的一批AnnotationTypeMapping,然后将其全部转为MergedAnnotation,再使用选择器MergedAnnotationSelector从这一批MergedAnnotation选择出最终——一般是离根注解最近的那个——的结果; -
调用
MergedAnnotation#synthesize方法,借助动态代理,生成指定注解类型的代理实例,此时即获取到了所需的“元注解”; -
当从代理实例中获取属性值时,对应的方法会被代理到
MergedAnnotation#getAttributeValue方法,该方法将根据属性名从MergedAnnotation对应的AnnotationTypeMapping的AttributeMethods得到指定属性的下标,然后根据下标再从AnnotationTypeMapping中获取真正的属性值:- 若该属性在根注解中存在,则通过下标取出
conventionMappings数组对应位置存放的根注解属性下标,然后从根注解中获取对应属性值; - 若该属性不做根注解中存在,则尝试通过下标取出
annotationValueSource和annotationValueMappings数组存放的对应别名注解和要获取的别名注解属性下标,最后返回该别名注解中的对应别名属性; - 若上述操作获取到的属性值为空,或该属性不存在别名,则直接从该注解中获取对应的属性值;
- 若该属性在根注解中存在,则通过下标取出