ClickHouse核心架构设计是怎么样的?ClickHouse核心架构模块分为两个部分:ClickHouse执行过程架构和ClickHouse数据存储架构,下面分别详细介绍。
ClickHouse执行过程架构总的来说,结合目前搜集到的一些资料,可以看到目前ClickHouse核心架构由下图构成,主要的抽象模块是Column、DataType、Block、Functions、Storage、Parser与Interpreter。
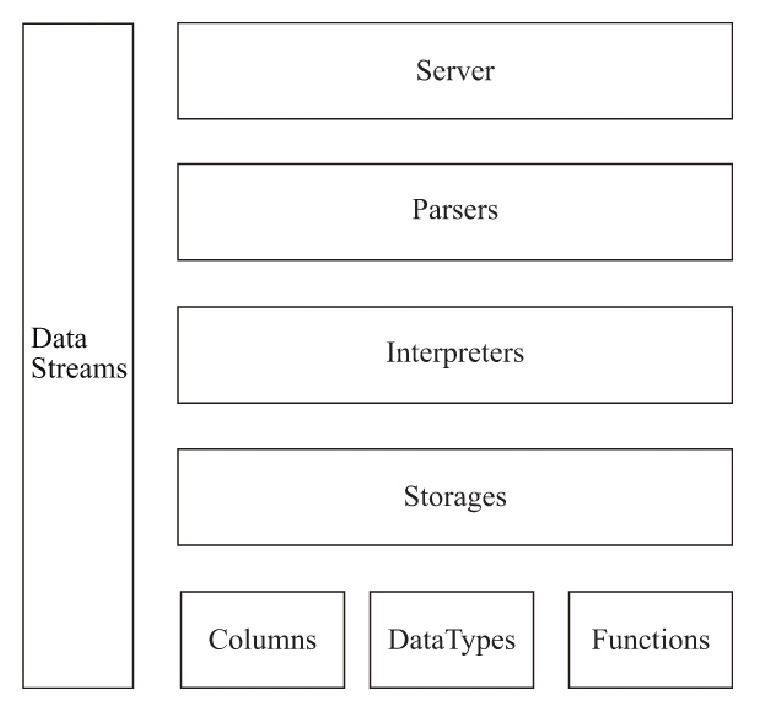
简单来说,就是一条sql,会经由Parser与Interpreter,解析和执行,通过调用Column、DataType、Block、Functions、Storage等模块,最终返回数据,下面是各个模块具体的介绍。
Columns表示内存中的列(实际上是列块),需使用 IColumn 接口。该接口提供了用于实现各种关系操作符的辅助方法。几乎所有的操作都是不可变的:这些操作不会更改原始列,但是会创建一个新的修改后的列。
Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等。
Field表示单个值,有时候也可能需要处理单个值,可以使用Field。Field 是 UInt64、Int64、Float64、String 和 Array 组成的联合。与Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
DataTypeIDataType 负责序列化和反序列化:读写二进制或文本形式的列或单个值构成的块。IDataType直接与表的数据类型相对应。比如,有 DataTypeUInt32、DataTypeDateTime、DataTypeString等数据类型。
IDataType与IColumn之间的关联并不大。不同的数据类型在内存中能够用相同的IColumn实现来表示。比如,DataTypeUInt32和DataTypeDateTime都是用ColumnUInt32或ColumnConstUInt32来表示的。另外,相同的数据类型也可以用不同的IColumn实现来表示。比如,DataTypeUInt8既可以使用ColumnUInt8 来表示,也可以使用过ColumnConstUInt8 来表示。
IDataType仅存储元数据。比如,DataTypeUInt8不存储任何东西(除了vptr);DataTypeFixedString仅存储N(固定长度字符串的串长度)。
IDataType具有针对各种数据格式的辅助函数。比如如下一些辅助函数:序列化一个值并加上可能的引号;序列化一个值用于 JSON 格式;序列化一个值作为 XML 格式的一部分。辅助函数与数据格式并没有直接的对应。比如,两种不同的数据格式 Pretty 和 TabSeparated 均可以使用 IDataType 接口提供的 serializeTextEscaped 这一辅助函数。
BlockBlock是表示内存中表的子集(chunk)的容器,是由三元组:(IColumn,IDataType,列名)构成的集合。在查询执行期间,数据是按 Block进行处理的。如果我们有一个Block,那么就有了数据(在IColumn对象中),有了数据的类型信息告诉我们如何处理该列,同时也有了列名(来自表的原始列名,或人为指定的用于临时计算结果的名字)。
当我们遍历一个块中的列进行某些函数计算时,会把结果列加入到块中,但不会更改函数参数中的列,因为操作是不可变的。之后,不需要的列可以从块中删除,但不是修改。这对于消除公共子表达式非常方便。
Block用于处理数据块。注意,对于相同类型的计算,列名和类型对不同的块保持相同,仅列数据不同。最好把块数据(block data)和块头(block header)分离开来,因为小块大小会因复制共享指针和列名而带来很高的临时字符串开销。
Block Streams块流用于处理数据。我们可以使用块流从某个地方读取数据,执行数据转换,或将数据写到某个地方。IBlockInputStream 具有 read 方法,其能够在数据可用时获取下一个块。IBlockOutputStream 具有 write 方法,其能够将块写到某处。
块流负责:
- 读或写一个表。表仅返回一个流用于读写块。
- 完成数据格式化。比如,如果你打算将数据以Pretty格式输出到终端,你可以创建一个块输出流,将块写入该流中,然后进行格式化。
- 执行数据转换。假设你现在有IBlockInputStream并且打算创建一个过滤流,那么你可以创建一个FilterBlockInputStream并用IBlockInputStream 进行初始化。之后,当你从FilterBlockInputStream中拉取块时,会从你的流中提取一个块,对其进行过滤,然后将过滤后的块返回给你。查询执行流水线就是以这种方式表示的。
IStorage接口表示一张表。该接口的不同实现对应不同的表引擎。比如 StorageMergeTree、StorageMemory等。这些类的实例就是表。
IStorage 中最重要的方法是read和write,除此之外还有alter、rename和drop等方法。read方法接受如下参数:需要从表中读取的列集,需要执行的AST查询,以及所需返回的流的数量。read方法的返回值是一个或多个IBlockInputStream对象,以及在查询执行期间在一个表引擎内完成的关于数据处理阶段的信息。
在大多数情况下,read方法仅负责从表中读取指定的列,而不会进行进一步的数据处理。进一步的数据处理均由查询解释器完成,不由 IStorage 负责。
但是也有值得注意的例外:AST查询被传递给read方法,表引擎可以使用它来判断是否能够使用索引,从而从表中读取更少的数据。有时候,表引擎能够将数据处理到一个特定阶段。比如,StorageDistributed 可以向远程服务器发送查询,要求它们将来自不同的远程服务器能够合并的数据处理到某个阶段,并返回预处理后的数据,然后查询解释器完成后续的数据处理。
Parser与InterpreterParser和Interpreter是非常重要的两组接口:Parser分析器负责创建AST对象;而Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。它们与IStorage一起,串联起了整个数据查询的过程。Parser分析器可以将一条SQL语句以递归下降的方法解析成AST语法树的形式。不同的SQL语句,会经由不同的Parser实现类解析。例如,有负责解析DDL查询语句的ParserRenameQuery、ParserDropQuery和ParserAlterQuery解析器,也有负责解析INSERT语句的ParserInsertQuery解析器,还有负责SELECT语句的ParserSelectQuery等。
Interpreter解释器的作用就像Service服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析AST对象;然后执行“业务逻辑”(例如分支判断、设置参数、调用接口等);最终返回IBlock对象,以线程的形式建立起一个查询执行管道。
Functions函数既有普通函数,也有聚合函数。
普通函数不会改变行数-它们的执行看起来就像是独立地处理每一行数据。实际上,函数不会作用于一个单独的行上,而是作用在以Block 为单位的数据上,以实现向量查询执行。
还有一些杂项函数,比如块大小、rowNumberInBlock,以及跑累积,它们对块进行处理,并且不遵从行的独立性。
ClickHouse 具有强类型,因此隐式类型转换不会发生。如果函数不支持某个特定的类型组合,则会抛出异常。但函数可以通过重载以支持许多不同的类型组合。比如,plus 函数(用于实现+运算符)支持任意数字类型的组合:UInt8+Float32,UInt16+Int8等。同时,一些可变参数的函数能够级接收任意数目的参数,比如concat函数。
实现函数可能有些不方便,因为函数的实现需要包含所有支持该操作的数据类型和IColumn类型。比如,plus函数能够利用C++模板针对不同的数字类型组合、常量以及非常量的左值和右值进行代码生成。
这是一个实现动态代码生成的好地方,从而能够避免模板代码膨胀。同样,运行时代码生成也使得实现融合函数成为可能,比如融合«乘-加»,或者在单层循环迭代中进行多重比较。
由于向量查询执行,函数不会«短路»。比如,如果你写 WHERE f(x) AND g(y),两边都会进行计算,即使是对于 f(x) 为 0 的行(除非f(x)是零常量表达式)。但是如果 f(x) 的选择条件很高,并且计算 f(x) 比计算 g(y) 要划算得多,那么最好进行多遍计算:首先计算 f(x),根据计算结果对列数据进行过滤,然后计算 g(y),之后只需对较小数量的数据进行过滤。
ClickHouse数据存储架构ClickHouse数据存储架构由分片(Shard)组成,而每个分片又通过副本(Replica)组成。ClickHouse分片有限免两个特点。
- ClickHouse的1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部署2个服务节点。
- 分片只是一个逻辑概念,其物理承载还是由副本承担的。
下面是cluster拥有1个shard(分片)和2个replica(副本),且副本由192.37.129.6服务节点和192.37.129.7服务节承载。从本质上看,这个配置是是一个分片一个副本,因为分片最终还是由副本来实现,所以这个其中一个副本是属于分片,分片是一个逻辑概念,它指的是其中的一个副本,这个和Elasticsearch中的分片和副本的概念有所不同。
<ch_cluster>
<shard>
<replica>
<host>192.37.129.6</host>
<port>9000</port>
</replica>
<replica>
<host>192.37.129.7</host>
<port>9000</port>
</replica>
</shard>
</ch_cluster>
ClickHouse经典中文文档分享
资料参考:ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计