python已经支持WAV格式的书写,而实时的声音输入输出需要安装pyAudio(http://people.csail.mit.edu/hubert/pyaudio)。最后我们还将使用pyMedia(http://pymedia.org)进行Mp3的解码和播放。
音频信号是模拟信号,我们需要将其保存为数字信号,才能对语音进行算法操作,WAV是Microsoft开发的一种声音文件格式,通常被用来保存未压缩的声音数据。
语音信号有四个重要的参数:声道数、采样频率、量化位数(位深)和比特率。
- 声道数:可以是单声道、双声道 ...
- 采样频率(Sample rate):每秒内对声音信号采样样本的总数目,44100Hz采样频率意味着每秒钟信号被分解成44100份。换句话说,每隔144100144100秒就会存储一次,如果采样率高,那么媒体播放音频时会感觉信号是连续的。
- 量化位数(Bit depth):也称为“位深”,每个采样点中信息的比特(bit)数。1 byte等于8 bit。通常有8bit、16bit、24bit、32bit...
- 比特率(Bit rate):每秒处理多少个Bit。比如一个单声道,用44.1KHz/16Bit的配置来说,它的比特率就为44100*16*1=705600,单位是bit/s(或者bps),因为通常计算出来的数字都比较大,大家就用kbit/s了,也就是705.6kbit/s。在对音频进行压缩时,比特率就成为了我们的一个要选的选项了,越高的比特率,其音质也就越好。一些常用的比特率有:
- 32kbit/s: 一般只适用于语音
- 96kbit/s: 一般用于语音或低质量流媒体
- 128或160kbit/s: 中等比特率质量
- 192kbit/s: 中等质量比特率
- 256kbit/s: 常用的高质量比特率
- 320kbit/s: MP3标准支持的最高水平
如果你需要自己录制和编辑声音文件,推荐使用Audacity,它是一款开源的、跨平台、多声道的录音编辑软件。在我的工作中经常使用Audacity进行声音信号的录制,然后再输出成WAV文件供Python程序处理。
如果想要快速看语音波形和语谱图,推荐使用Adobe Audition,他是Adobe公司开发专门处理音频的专业软件,微博关注vposy,下载地址见置顶。他破解了很多adobe公司的软件,包括PS、PR...
音频格式 WAVWAV格式是微软公司开发的一种无损声音文件格式,也称为波形声音文件,WAV格式支持多种压缩算法、音频位数、采样频率和声道。
WAV 符合 RIFF(Resource Interchange File Format) 规范,所有的WAV都由 44字节 头文件 和 PCM文件 组成,这个文件头包含语音信号的所有参数信息(声道数、采样率、量化位数、比特率....)
44个字节的 头文件由 3个区块组成:
- RIFF chunk:WAV文件标识
- Format chunk: 声道数、采样率、量化位数、等信息
- Data chunk:存放数据
相反的,在PCM文件头部添加44个字节的WAV文件头,就可以生成WAV格式文件
RIFF区块规范的WAVE格式遵循RIFF头
名称 字节数 内容 ChunkID 4 "RIFF" 标识符 ChunkSize 4表示从下个地址开始到文件尾的总字节数
更准确的说:等于整个wav文件大小-8
Format 4 "WAVE" 标识符 FORMAT区块描述声音数据的格式
名称 字节数 内容 Subchunk1ID 4 "fmt " 标识符,最后一位是空格 Subchunk1Size 4 该区块数据的长度(不包含该区块ID和Size的长度) AudioFormat 2 音频格式,PCM音频数据的值为1 NumChannels 2 通道数 SampleRate 4 采样率 ByteRate 4 每秒数据字节数 = SampleRate * NumChannels * BitsPerSample / 8 BlockAlign 2 每个采样点所需的字节数 = NumChannels * BitsPerSample / 8 BitsPerSample 2 量化位数(bit) DATA区块包含数据的大小和实际声音
名称 字节数 内容 Subchunk2ID 4 "data" 标识符 Subchunk2Size 4 该区块数据的长度,(不包含该区块ID和Size的长度),也就是PCM字节数 Data * 音频数据文件实例:
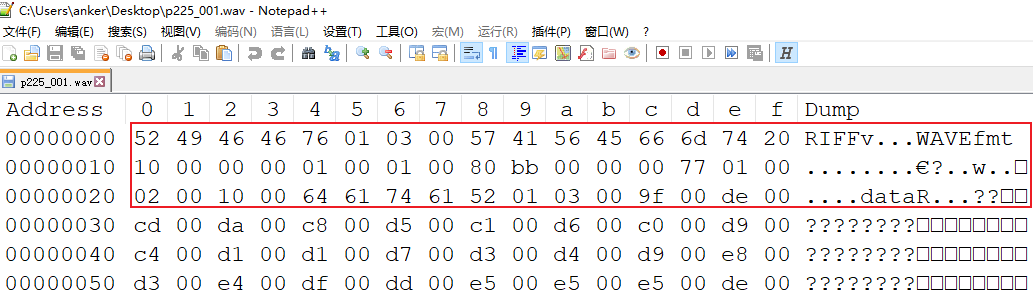
RIFF区块
- ChunkID(4字节 52 49 46 46):对应ASCII中的 RIFF,这里是ASCII码对照表。
- ChunkSize(4字节 76 01 03 00):表示WAV文件的大小,不包含了前面8个字节,所以真正的大小等于文件总字节减去8。76 01 03 00 对应的正序16进制为 00 03 01 76大小为196982
- Format(4字节 57 41 56 45):对应ASCII中的WAVE
FORMAT区块
- Subchunkl ID(4字节 66 6d 74 20):对应ASCII中的fmt
- Subchunkl Size(4字节 10 00 00 00):正序16进制 00 00 00 10 对应16
- AudioFormat(2字节 01 00):正序16进制 00 01,对应数字1,表示编码格式“WAVE_FORMAT_PCM”
- NumChannels(2字节 01 00):正序16进制 00 01,对应数字1,表示声道数为1
- SampleRate(4字节 80 bb 00 00):正序16进制 00 00 bb 80,表示采样率为48000
- ByteRate(4字节 00 77 01 00):正序16进制 00 01 77 00,表示传输速率为96000
- BlockAlign(2字节 02 00):正序16进制 00 02,每个采样所需的2字节数
- BitsPerSample(2字节 10 00):正序16进制 00 10,采样大小为16 Bits
DATA区块
- Subchunk2ID(4字节 64 61 74 61):表示为ASCII的data,开始数据区
- Subchunk2 Size(4字节 52 01 03 00):正序16进制 00 03 01 52,PCM字节数,大小为196946
- wav文件(wav字节-44字节):pcm音频数据
因为wav比pcm多44个字节的文件头,也就是说44字节后的信息,就是pcm数据
版本1:C语言实现wave to pcm


#include <stdio.h> /** * wav2pcm ***.wav **.pcm * @param argc 命令行参数的长度 * @param argv 命令行参数,argv[0]是程序名称 * @return */ int main(int argc, char *argv[]) { FILE *wavfile; FILE *pcmfile; char buf[1024]; int read_len; if (argc != 3) { printf("usage:\n" "\t wav2pcm ***.wav **.pcm\n"); } wavfile = fopen(argv[1], "rb"); if (wavfile == NULL) { printf("!Error: Can't open wavfile.\n"); return 1; } pcmfile = fopen(argv[2], "wb"); if (pcmfile == NULL) { printf("!Error: Can't open pcmfile.\n"); return 1; } fseek(wavfile, 44, SEEK_SET); // 将文件指针移动到文件开头,后移44字节 while ((read_len = fread(buf, 1, sizeof(buf), wavfile)) != 0) { fwrite(buf, 1, read_len, pcmfile); } fclose(pcmfile); fclose(wavfile); return 0; }wav2pcm.c
版本2:shell实现 wave to pcm
dd if=1.wav of=1.pcm bs=1 skip=44wav2pcm.sh
版本3:使用python的
def wav2pcm(wavfile, pcmfile, data_type=np.int16): f = open(wavfile, "rb") f.seek(0) # 移动文件读取指针到指定位置 data = np.fromfile(f, dtype=data_type, offset=44) # 从文本或二进制文件中的数据构造一个数组 data.tofile(pcmfile) f.close()View Code
还有一个github开源代码:wavutils
当我们读取pcm数据的时候,我们需要弄清楚语音每个采样点的位深是多少bit,一般来说是16bit,那么我们去pcm数据的时候就应该2个字节的去取,应该创建short的buf。
#include <stdio.h> int main() { FILE *pcmfile; int frame_len = 480; // 帧长 short buf[frame_len]; // 每个采样点2字节 int read_len; char pcmpath[]="../p225_001.pcm"; pcmfile = fopen(pcmpath, "rb"); if (pcmfile == NULL) { printf("!Error: Can't open wavfile.\n"); return 1; } while (feof(pcmfile)==0){ read_len = fread(buf, sizeof(short), frame_len, pcmfile); for (int i = 0; i < read_len; i++) { printf("%d ", buf[i]); } } fclose(pcmfile); return 0; }读取pcm数据 PCM、RAW、SAM
RAW、PCM(Pulse Code Modulation)、SAM 都是一种存储 原始数据 的音频文件格式,未经过任何编码和压缩处理,他们的本质一样,只是文件扩展名不同,也可以没有扩展名。与WAV或AIFF的大小相比,这音频文件不包含任何标题信息(采样率、位深度、通道数)。
如果在PCM文件的前面添加WAV文件头,就可以生成WAV格式文件。
如果是16位的话,pcm每个采样点的值在0~$2^{15}-1$,因为第一位是符号位。所以我们有时候用librosa读取的音频每个采样点都是0~1之间的,如果该音频是16bit的,如果想将他换成short型应该乘以$2^{15}$。
pcm转wav版本一:代码参考自:https://github.com/pliu6/pcm2wav
/** * https://github.com/pliu6/pcm2wav */ #include <stdlib.h> #include <string.h> #include <stdio.h> typedef struct { unsigned char chunk_id[4]; /*{'R', 'I', 'F', 'F'}*/ unsigned int chunk_size; unsigned char format[4]; } FIFFChunk; typedef struct { unsigned char chunk_id[4]; /* {'f', 'm', 't', ' '} */ unsigned int chunk_size; unsigned short audio_format; // 2字节 unsigned short channels; // 4字节 unsigned int sample_rate; // 4字节 unsigned int byte_rate; // 4字节 unsigned short block_align; // 2字节 unsigned short bits_per_sample; // 2字节 } FormatChunk; typedef struct { unsigned char chunk_id[4]; /* {'d', 'a', 't', 'a'} */ unsigned int chunk_size; } DataChunk; // pcm2wav ***.pcm ***.wav 通道 采样率 量化位数 int main(int argc, char *argv[]) { FILE *pcmfile, *wavfile; long pcmfile_size; FIFFChunk fiffchunk; FormatChunk formatchunk; DataChunk datachunk; int read_len; char buf[1024]; if (argc != 6) { printf("usage:\n" "\t%s pcmfile wavfile channel samplerate bitspersample\n", argv[0]); return 1; } pcmfile = fopen(argv[1], "rb"); if (pcmfile == NULL) { printf("!Error: Can't open pcmfile.\n"); return 1; } fseek(pcmfile, 0, SEEK_END); // 将文件指针移动到文件最后 pcmfile_size = ftell(pcmfile); // 返回给定流 stream 的当前文件位置(字节) fseek(pcmfile, 0, SEEK_SET); // 将文件指针移动到文件开头 wavfile = fopen(argv[2], "wb"); if (wavfile == NULL) { printf("!Error: Can't create wavfile.\n"); return 1; } /* *********** RIFF区块 ********************* */ strncpy(fiffchunk.chunk_id,"RIFF", 4); fiffchunk.chunk_size = pcmfile_size+36; strncpy(fiffchunk.format,"WAVE",4); fwrite(&fiffchunk, sizeof(fiffchunk), 1, wavfile); /* *********** FORMAT区块 ********************* */ strncpy(formatchunk.chunk_id,"fmt ", 4); formatchunk.chunk_size = sizeof(FormatChunk) - 8; // 不包含该区块ID和Size的长度 formatchunk.audio_format = 1; /* 未压缩的 */ formatchunk.channels = atoi(argv[3]); // 通道数,字符串转换成整型 formatchunk.sample_rate = atoi(argv[4]); // 采样率 formatchunk.bits_per_sample = atoi(argv[5]); // 量化位数 formatchunk.byte_rate = formatchunk.sample_rate * formatchunk.channels * (formatchunk.bits_per_sample >> 3); // 每秒数据字节数=SampleRate * NumChannels * BitsPerSample/8 formatchunk.block_align = formatchunk.channels * (formatchunk.bits_per_sample >> 3); // 每个样本需要的字节数 fwrite(&formatchunk, 1, sizeof(formatchunk), wavfile); /* *********** DATA区块 ********************* */ strncpy(datachunk.chunk_id, "data",4); datachunk.chunk_size = pcmfile_size; fwrite(&datachunk, 1, sizeof(datachunk.chunk_id) + sizeof(datachunk.chunk_size), wavfile); while ((read_len = fread(buf, 1, sizeof(buf), pcmfile)) != 0) { fwrite(buf, 1, read_len, wavfile); } fclose(pcmfile); fclose(wavfile); }pcm2wav.c
版本二:代码参考自:https://github.com/jwhu1024/pcm-to-wav
/** * https://github.com/jwhu1024/pcm-to-wav */ #include <stdio.h> #include <stdlib.h> #include <string.h> typedef struct { unsigned char chunk_id[4]; // RIFF string unsigned int chunk_size; // overall size of file in bytes (36 + data_size) unsigned char sub_chunk1_id[8]; // WAVEfmt string with trailing null char unsigned int sub_chunk1_size; // 16 for PCM. This is the size of the rest of the Subchunk which follows this number. unsigned short audio_format; // format type. 1-PCM, 3- IEEE float, 6 - 8bit A law, 7 - 8bit mu law unsigned short num_channels; // Mono = 1, Stereo = 2 unsigned int sample_rate; // 8000, 16000, 44100, etc. (blocks per second) unsigned int byte_rate; // SampleRate * NumChannels * BitsPerSample/8 unsigned short block_align; // NumChannels * BitsPerSample/8 unsigned short bits_per_sample; // bits per sample, 8- 8bits, 16- 16 bits etc unsigned char sub_chunk2_id[4]; // Contains the letters "data" unsigned int sub_chunk2_size; // NumSamples * NumChannels * BitsPerSample/8 - size of the next chunk that will be read } wav_header_t; char *dummy_get_raw_pcm(char *p, int *bytes_read) { long lSize; char *pcm_buf; size_t result; FILE *fp_pcm; fp_pcm = fopen(p, "rb"); if (fp_pcm == NULL) { printf("File error"); exit(1); } // obtain file size: fseek(fp_pcm, 0, SEEK_END); // 将文件指针移动到文件最后 lSize = ftell(fp_pcm); // 返回给定流 stream 的当前文件位置(字节) rewind(fp_pcm); // 将文件指针移动到文件开头 // 分配内存来包含整个文件 pcm_buf = (char *) malloc(sizeof(char) * lSize); if (pcm_buf == NULL) { printf("Memory error"); exit(2); } // 将文件复制到pcm_buf中: result = fread(pcm_buf, 1, lSize, fp_pcm); if (result != lSize) { printf("Reading error"); exit(3); } *bytes_read = (int) lSize; return pcm_buf; } void get_wav_header(int raw_sz, wav_header_t *wh) { // RIFF chunk strcpy(wh->chunk_id, "RIFF"); wh->chunk_size = 36 + raw_sz; // fmt sub-chunk (to be optimized) strncpy(wh->sub_chunk1_id, "WAVEfmt ", strlen("WAVEfmt ")); wh->sub_chunk1_size = 16; wh->audio_format = 1; wh->num_channels = 1; wh->sample_rate = 16000; wh->bits_per_sample = 16; wh->block_align = wh->num_channels * wh->bits_per_sample / 8; wh->byte_rate = wh->sample_rate * wh->num_channels * wh->bits_per_sample / 8; // data sub-chunk strncpy(wh->sub_chunk2_id, "data", strlen("data")); wh->sub_chunk2_size = raw_sz; } void dump_wav_header(wav_header_t *wh) { printf("=========================================\n"); printf("chunk_id:\t\t\t%s\n", wh->chunk_id); printf("chunk_size:\t\t\t%d\n", wh->chunk_size); printf("sub_chunk1_id:\t\t\t%s\n", wh->sub_chunk1_id); printf("sub_chunk1_size:\t\t%d\n", wh->sub_chunk1_size); printf("audio_format:\t\t\t%d\n", wh->audio_format); printf("num_channels:\t\t\t%d\n", wh->num_channels); printf("sample_rate:\t\t\t%d\n", wh->sample_rate); printf("bits_per_sample:\t\t%d\n", wh->bits_per_sample); printf("block_align:\t\t\t%d\n", wh->block_align); printf("byte_rate:\t\t\t%d\n", wh->byte_rate); printf("sub_chunk2_id:\t\t\t%s\n", wh->sub_chunk2_id); printf("sub_chunk2_size:\t\t%d\n", wh->sub_chunk2_size); printf("=========================================\n"); } // pcm-to-wav ./time.pcm ./***.wav int main(int argc, char *argv[]) { int raw_sz = 0; FILE *fwav; wav_header_t wheader; // 文件头 结构体变量声明 memset(&wheader, '\0', sizeof(wav_header_t)); // 清除内存位置 // check argument if (argc != 2) return -1; // dummy raw pcm data char *pcm_buf = dummy_get_raw_pcm("./time.pcm", &raw_sz); // construct wav header get_wav_header(raw_sz, &wheader); // 给文件头赋 初值 dump_wav_header(&wheader); // 打印文件头 信息 // write out the .wav file fwav = fopen(argv[1], "wb"); fwrite(&wheader, 1, sizeof(wheader), fwav); fwrite(pcm_buf, 1, raw_sz, fwav); fclose(fwav); if (pcm_buf) free(pcm_buf); return 0; }pcm2wav.c
版本三:使用python的wave库
def pcm2wav(pcm_file, wav_file, channels=1, bits=16, sample_rate=16000): f = open(pcm_file, 'rb') pcmdata = f.read() f.close() if bits % 8 != 0: raise ValueError("bits % 8 must == 0. now bits:" + str(bits)) wavfile = wave.open(wav_file, 'wb') wavfile.setnchannels(channels) # 通道数 wavfile.setsampwidth(bits // 8) # 位深 wavfile.setframerate(sample_rate) # 采样率 wavfile.writeframes(pcmdata) # 数据 wavfile.close()View Code
还有一个github开源代码:wavutils
其他音频格式
MP3
MP3利用MPEG Audio Layer3 压缩方式进行压缩,所以简称为MP3,是一种有损压缩格式。 MPEG Audio Layer 3 压缩技术可以将音乐以1:10 甚至 1:12 的压缩率,能够在音质丢失很小的情况下把文件压缩到更小的程度。由于MP3体积小,音质高互联网上音乐几乎都是这种格式。但Mp3最高比特率320K,高频部分一刀切是他的缺点,对音质要求高的话还是建议wav格式。
ARM格式全称Adaptive Multi-Rate 和 Adaptive Multi-Rate Wideband,主要用于移动设备的音频,压缩比比较大,但相对其他的压缩格式质量比较差,多用于人声,通话,是一种有损压缩格式。
Ogg全称应该是OGG Vobis(ogg Vorbis) 是一种新的音频压缩格式,类似于MP3等现有的音乐格式。相对于MP3压缩技术它是完全免费、开放和没有专利限制的,是一种有损压缩格式。
AAC(Advanced Audio Coding),中文称为“高级音频编码”,出现于1997年,基于 MPEG-2的音频编码技术,是一种有损压缩技术。
LAC即是Free Lossless Audio Codec的缩写,为无损音频压缩编码,由于不会丢失任何音频信息可以利用算法恢复原始编码,前景广阔。
微软官方 对WAV格式的 解释
音频文件格式
WAV文件格式详解
音频格式简介和PCM转换成WAV
wave文件(*.wav)格式、PCM数据格式
wav文件格式分析与详解