- 一、Locust 性能测试
- (一). 性能测试工具
- 主流性能测试工具对比
- 认识Locust
- (二) locust 基本用法
- 1.安装locust
- 2.编写用例
- 3. 启动测试
- GUI 模式启动
locust - 命令行模式启动
locust
- GUI 模式启动
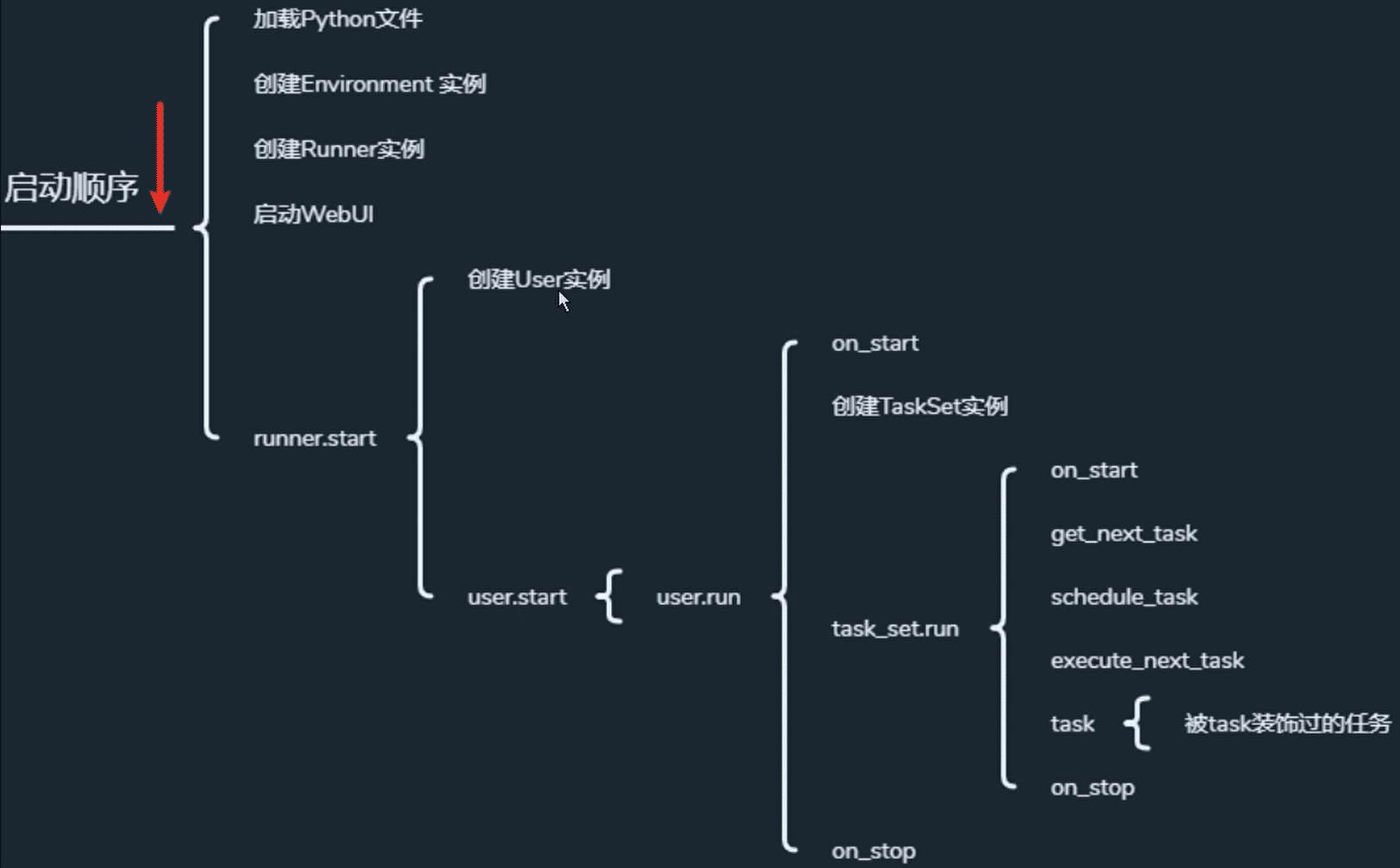
- 4. locust概念
- (三) locust 自定义压测协议 websocket
- 什么是websocket协议 ?
- 选择websocket 客户端
- 创建WebSocketUser
- (四). locust 核心组件
- 核心组件: 2类 ,4个
- 重要的属性:
- (五). locust 扩展增强
- 1. 录制用例
- 2. 数据关联
- 3. 参数化
- 4. 检查点
- 5. 思考时间
- 6. 权重
- 7. 集合点
- 8. 分布式
- 单机主从模式
- 多机主从模式
- 9. 资源监控
- 10. docker 运行locust
- 11. 高性能 FastHttpUser
- (六)附外
- 0. 进程、线程、协程区别
- 1. 更多命令
- 2. 学习路线
- 3. WebSocket与HTTP的关联和差异
- 4. 延伸阅读&知识库
- (一). 性能测试工具
同步Notion :
- https://young-glen.notion.site/Locust-994ec41de38744009814a63822b10eda
问题引言:
- 主流性能工具对比
- 为什么要用locust进行性能测试
- 如何对http接口进行性能测试
- 如何对websocket接口进行性能测试
- locust性能测试报告分析
- locust 核心部件了解
- locust 主要用法详解
- loadrunner : 收费 昂贵
- jmeter: 开源(二次开发) 、基于java、多线程 、使用gui设计用例 ,xml保存 、录制工具
loadRunner vs Jmeter
loadrunner笔记:
- https://mp.weixin.qq.com/s/V0wLFxrw4VIp9jTXVEKlag
定义
Locust是一款易于使用的分布式负载测试工具,完全基于事件,即一个locust节点也可以在一个进程中支持数千并发用户,不使用回调,通过gevent使用轻量级过程(即在自己的进程内运行)。
locust: 开源 、基于python ,非多线程(协程)、“用例即代码” ; 无录制工具、
- python的一个库 ,需要python3.6 及以上环境支持
- 可用做性能测试
- 基于事件,用协程 进行性能测试
- 支持 图形 、no-gui、 分布式等多种运行方式
为什么选择locust
-
基于协程 ,低成本实现更多并发
-
脚本增强(“测试即代码”)
-
使用了requests发送http请求
-
支持分布式
-
使用Flask 提供WebUI
-
有第三方插件、 易于扩展
约定大于配置
1.安装locustpip install locust
locust -v
test_xxx (一般测试框架约定)
dockerfile (docker约定)
locustfile.py (locust约定)
# locustfile.py
eg: 入门示例
from locust import HttpUser, task, between
# User ?
# function 包装task
class MyHttpUser(HttpUser):
wait_time = between(1, 2) # 执行任务 等待时长 检查点 思考时间
@task
def index_page(self):
self.client.get("https://baidu.com/123")
self.client.get("https://baidu.com/456")
pass
总结三步:
- 创建locust.HttpUser 之类
- 为待测试用例添加@locust.task 装饰器
- 使用self.client 发送请求
- 指定 wait_time 属性
GUI 模式启动Locust官方文档(API)解读(全)
- https://cloud.tencent.com/developer/article/1594240#
locust
启动locust
访问:http://[::1]:8089/
指标详解:
- Number of users 模拟用户数
- Spawn rate : 生产数 (每秒)、 =>jmeter : Ramp-Up Period (in seconds)
- Host (e.g. http://www.example.com) => 取决脚本中 绝对地址
- 
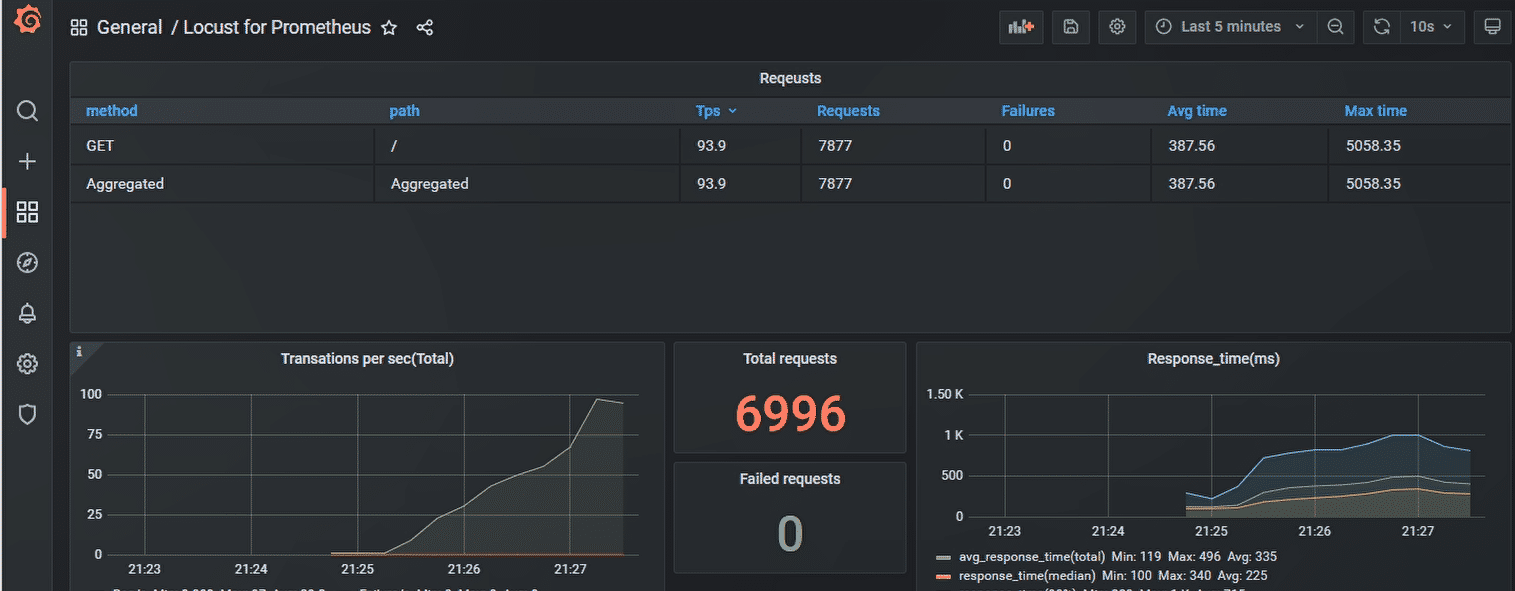
- WebUI 模块说明:
- New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑;
- Statistics:类似于jmeter中Listen的聚合报告;
- Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数;
- Failures:失败请求的展示界面;
- Exceptions:异常请求的展示界面;
- Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions;
locust
locust -f locustfile.py --headless -u 500 -r 10 --host 123 -t 1h5m
框架是通过命令locust运行的,常用参数有:
- -H:指定测试的主机地址(注:会覆盖Locust类指定的主机地址)
- -f:指定测试脚本地址(注:脚本中必须包含一个Locust的衍生类)
- --no-web:不启动web网页,而是直接开始运行测试,需提供属性-c和-r
- -u:并发的用户数,与--no-web一起使用
- -r:每秒启动的用户数,与--no-web一起使用
- -t:运行时间(单位:秒),与--no-web一起使用
- -L:日志级别,默认为INFO
调试命令:locust -f **.py --no-web -u 1 -t 1
运行命令:locust -f **.py
-
父类是个User ?
表示要生成进行负载测试的系统的 HTTP“用户”。
- 性能测试 模拟真实用户
- 每个user相当于一个协程链接 ,进行相关系统交互操作
-
为什么方法,要包装为task
-
task 表示用户要进行的操作
- 访问首页 → 登录 → 增、删改查 → homPage
-
TaskSet : 定义用户将执行的一组任务的类。测试任务开始后,每个Locust用户会从TaskSet中随机挑选 一个任务执行
-
具体的内容: 方法的代码
class MyHttpUser(HttpUser): #用户 # wait_time = lambda self: random.expovariate(1)*1000 wait_time = between(1, 2) # 执行任务 等待时长 检查点 思考时间 @task def index_page(self): # 用户执行操作 self.client.get("https://baidu.com/123") #服务错误、网络错误 self.client.get("https://baidu.com/456") # 断言 、 业务错误
-
什么是websocket协议 ?locust 并非 http 接口测试工具 , 只是内置了 “HttpUser” 示例 ,可以测试任何协议: websocket 、socket 、mqtt (webAPP、Hybrid、Html5 、桌面浏览器) 、rpc
WebSocket是一种在单个TCP连接上进行全双工通信的协议。 WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。ws长连接、 和http有本质不同 ;
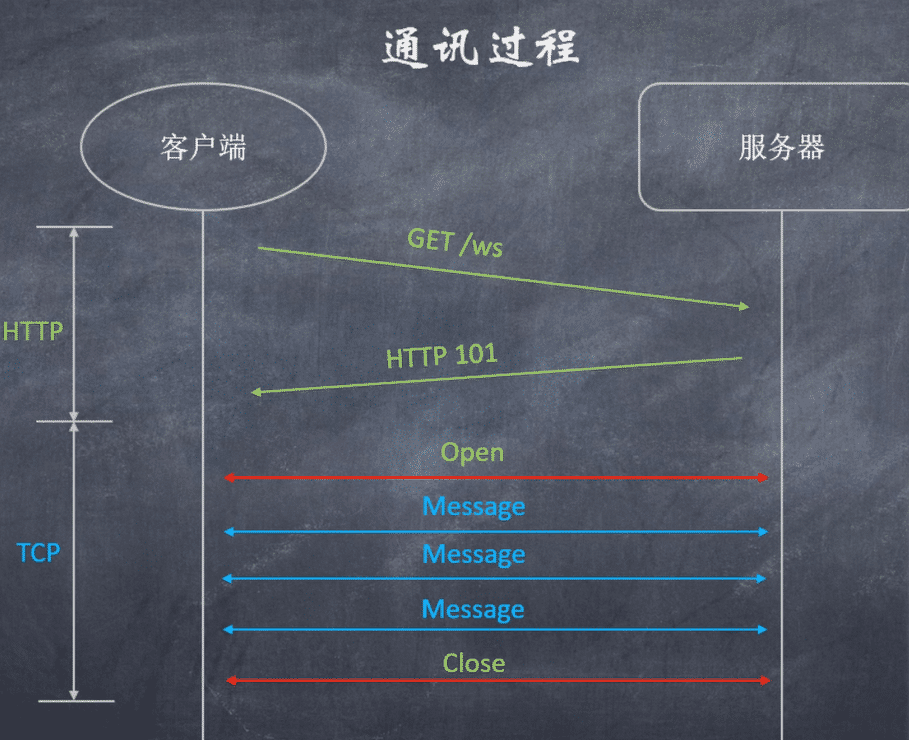
客户端发起,服务器可能接受或拒绝切换到新协议。客户端可使用常用的协议(如HTTP / 1.1)发起请求,请求说明需要切换到HTTP / 2或甚至到WebSocket
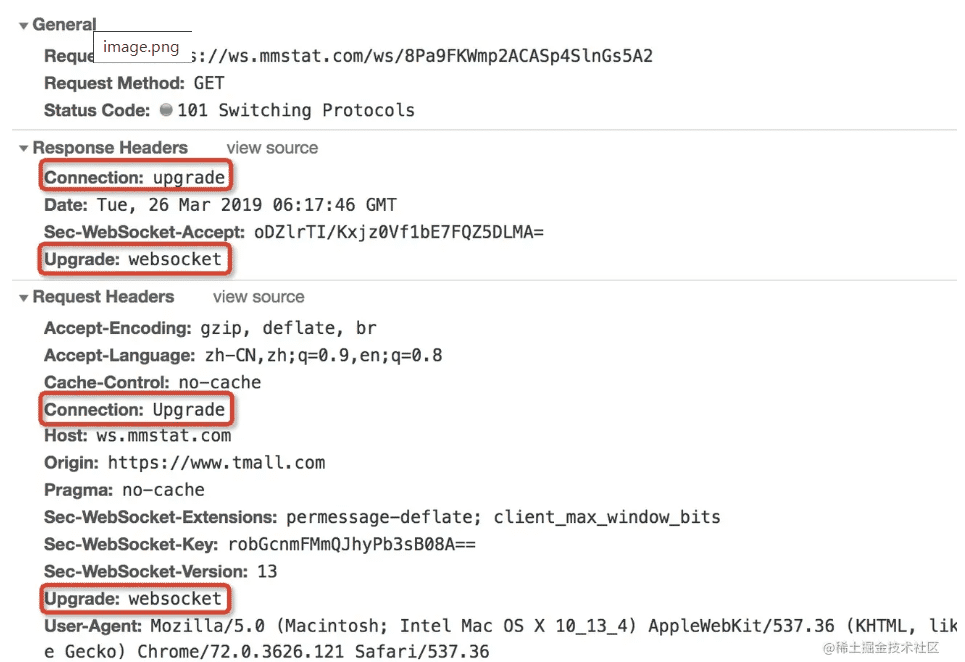
选择websocket 客户端一句话概述:协议“使用HTTP进行握手, 后使用TCP进行会话” 的全双工协议
目前pypi , 2个ws库
- websockets: 提供client , 提供了server ; 使用async 语法
- websocket_client: 仅提供client 、使用(非async)同步语法
-
安装
pip install websocket_client -
使用
创建WebSocketUserimport asyncio import websockets async def hello(): async with websockets.connect('ws://localhost:8765') as websocket: name = input("What's your name? ") await websocket.send(name) print(f" send:>>> {name}") greeting = await websocket.recv() print(f" recv: <<< {greeting}") asyncio.get_event_loop().run_until_complete(hello())-
创建专用客户端链接
-
设计统计结果
-
设定成功、失败条件
pyfile:
TimeoutError(10060, '[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。') 1.请求服务器的反爬机制导致的,请求不被接受的 ; ip限制
→ 网页访问验证 - 2. http的连接数超过最大限制。
headers的Connection参数默认为keep-alive,之前所有请求的链接都一直存在,占用了后续的链接请求 3. 网站服务器太差 → 修改中间件配置(SLB、nginx 、ApiGateway 熔断、限流 ~
→timeout 超时时间
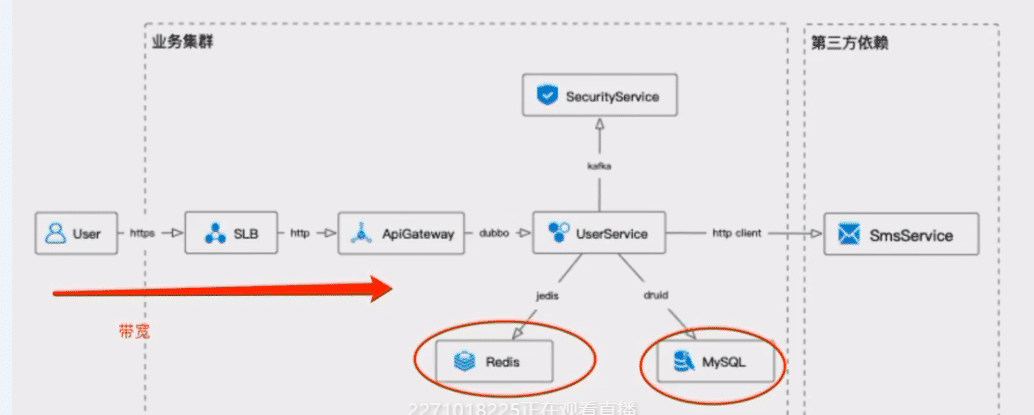 ........... 9大策略和6大指标 、
........... 硬件(计算机体系机构)、操作系统(OS\JVM)、文件系统、网络通信、数据库系统、中间件(transaction、message、app)、应用程序本身
........... 9大策略和6大指标 、
........... 硬件(计算机体系机构)、操作系统(OS\JVM)、文件系统、网络通信、数据库系统、中间件(transaction、message、app)、应用程序本身
-
本地:
netsh winsock reset→ 重启
初步结果:
1. RPS xxxx 左右
2. 最大用户数 xxx
> 表示:当前允许最大用户数请求,但是无法全部返回结果
-
User : 在locust中User类表示一个用户。locust将为每一个被模拟的用户生成一个User类实例,而我们可以在User类中定义一些常见的属性来定义用户的行为。
- HttpUser
-
Task: 用户行为
- SequentialTaskSet
- TaskSet:
- tasks属性将多个TaskSet子类嵌套在一起
- 类中相互嵌套
- User类中嵌入TaskSet类,作为User的子类
-
Events : locust提供的事件钩子,用于一些再运行过程中执行特定时间的操作。
-
wait_time
> 三种时间间隔表达式
-
固定时间, 由constant(wait)函数提供
-
区间随机时间: `between(min_wait, max_wait)函数
-
自适应节奏时间:
constant_pacing用于确保任务每 X 秒(最多)运行一次
-
-
task: 任务(用户行为)
- tasks :
- 用户类的用户行为方法上添加@task修饰
- 引用外部用户行为方法时 使用tasks实现
- tasks :
-
weight
测试中,存在多个User Class,默认情况下locust将为每个User Class的实例的数量是相同的。通过设置weight属性,来控制locust为我们的User Class生成不同数量的实例。
- locustfile07.py
→ Python代码
2. 数据关联 不支持 , →插件增强
locustfile05.py
使用变量方式进行传递
3. 参数化locustfile09.py
locust参数化:引入队列的概念 queue ,实现方式是将参数推入队列,测试时依次取出,全部取完后 locust 会自动停止。若是使用参数循环压测,需要将取出的参数再推入队尾。
- 变量
- CSV
- 队列
- 。。
locust默认情况下会使用默认的检查点,比如当接口超时、链接失败等原因是,会自动判断失败
原理:
- 使用self.client提供的catch_response=True`参数, 添加locust提供的ResponseContextManager类的上下文方法手动设置检查点。
- ResponseContextManager里面的有两个方法来声明成功和失败,分别是
success和failure。其中failure方法需要我们传入一个参数,内容就是失败的原因。
locustfile10.py
from requests import codes
from locust import HttpUser, task, between
class DemoTest(HttpUser):
host = 'https://www.baidu.com'
wait_time = between(2, 15)
def on_start(self):
# 通过手动传入catch_response=True 参数手动设置检查点
with self.client.get('/', catch_response=True) as r:
if r.status_code == codes.bad:
r.success()
else:
r.failure("请求百度首页失败了哦哦")
@task
def search_locust(self):
with self.client.get('/s?ie=utf-8&wd=locust', catch_response=True) as r:
if r.status_code == codes.ok:
r.success()
else:
r.failure("搜索locust失败了哦哦")

- wait_time
- between
- constant
- 第一种:方法上指定
locust默认是随机执行taskset里面的task的。
权重通过在@task参数中设置,如代码中hello:world:item是1:3:2,实际执行时的代码,在user中tasks会将任务生成列表[hello,world,world,world,item,item]
@tag 装饰器 :# locust -f locustfile06.py --tags tag1
task不止一个时,可以通过@tag给task打标签进行分类,在执行测试时,通过--tags name执行指定带标签的task
# locustfile06.py
import time
from locust import HttpUser, task, between, TaskSet, tag
class QuickstartUser(TaskSet):
wait_time = between(1, 5)
# wait_time = constant(3) #固定时间
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@tag("tag1", "tag2")
@task(3)
def view_items(self):
for item_id in range(10):
#self.client.request_name="/item?id=[item_id]"#分组请求
# 将统计的10条信息分组到名为/item条目下
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={"username": "foo", "password": "bar"})
class MyUserGroup(HttpUser):
""" 定义线程组 """
tasks = [QuickstartUser] # tasks 任务列表
host = "http://www.baidu.com"
-
第二种:在属性中指定
文件中存在多个用户类场景,
- 命令行上没有指定用户类,Locust 将生成相同数量的每个用户类。
- 可以通过将它们作为命令行参数传递来指定要使用同一 locustfile 中的哪些用户类:
locust -f locustfile07.py QuickstartUser2
# locustfile07.py
import time
from locust import HttpUser, task, between, TaskSet, tag, constant
class QuickstartUser1(HttpUser):
host = "http://www.baidu.com"
wait_time = constant(4)
weight = 3 #属性中指定
@task
def hello_world(self):
self.client.get("/hello1")
self.client.get("/world1")
def on_start(self):
self.client.post("/login1", json={"username": "foo", "password": "bar"})
class QuickstartUser2(HttpUser):
host = "http://www.baidu.com"
wait_time = between(1, 5)
weight = 1
@task
def hello_world(self):
self.client.get("/hello2")
self.client.get("/world2")
def on_start(self):
self.client.post("/login2", json={"username": "foo", "password": "bar"})
什么是集合点?
集合点用以同步虚拟用户,以便恰好在同一时刻执行任务。在[测试计划]中,可能会要求系统能够承受1000 人同时提交数据,可以通过在提交数据操作前面加入集合点,这样当虚拟用户运行到提交数据的集合点时,就检查同时有多少用户运行到集合点,如果不到1000 人,已经到集合点的用户在此等待,当在集合点等待的用户达到1000 人时,1000 人同时去提交数据,从而达到测试计划中的需求。
注意:框架本身没有直接封装集合点的概念 ,间接通过gevent并发机制,使用gevent的锁来实现
semaphore是一个内置的计数器:
每当调用acquire()时,内置计数器-1
每当调用release()时,内置计数器+1
计数器不能小于0,当计数器为0时,acquire()将阻塞线程直到其他线程调用release()
两步骤:
- all_locusts_spawned 创建钩子函数
- 将locust实例挂载到监听器 events.spawning_complete.add_listener
- Locust实例准备完成时触发
示例代码:
# locustfile08.py
import os
from locust import HttpUser, TaskSet, task,between,events
from gevent._semaphore import Semaphore
all_locusts_spawned = Semaphore()
all_locusts_spawned.acquire()# 阻塞线程
def on_hatch_complete(**kwargs):
"""
Select_task类的钩子方法
:param kwargs:
:return:
"""
all_locusts_spawned.release() # # 创建钩子方法
events.spawning_complete.add_listener(on_hatch_complete) #挂在到locust钩子函数(所有的Locust示例产生完成时触发)
n = 0
class UserBehavior(TaskSet):
def login(self):
global n
n += 1
print("%s个虚拟用户开始启动,并登录"%n)
def logout(self):
print("退出登录")
def on_start(self):
self.login()
all_locusts_spawned.wait() # 同步锁等待
@task(4)
def test1(self):
url = '/list'
param = {
"limit":8,
"offset":0,
}
with self.client.get(url,params=param,headers={},catch_response = True) as response:
print("用户浏览登录首页")
@task(6)
def test2(self):
url = '/detail'
param = {
'id':1
}
with self.client.get(url,params=param,headers={},catch_response = True) as response:
print("用户同时执行查询")
@task(1)
def test3(self):
"""
用户查看查询结果
:return:
"""
url = '/order'
param = {
"limit":8,
"offset":0,
}
with self.client.get(url,params=param,headers={},catch_response = True) as response:
print("用户查看查询结果")
def on_stop(self):
self.logout()
class WebsiteUser(HttpUser):
host = 'http://www.baidu.com'
tasks = [UserBehavior]
wait_time = between(1, 2)
if __name__ == '__main__':
os.system("locust -f locustfile08.py")
Locust 通过协程实现单机大量并发,但对多核 CPU 的支持并不好,可通过在一台机器上启动多个 Locust 实例实现对多核 CPU 的利用(单机分布式) ,同理:单台计算机不足以模拟所需的用户数量,Locust 也支持在多台计算机上进行分布式负载测试。
一种是单机设置master和slave模式,另外一种是有多个机器,其中一个机器设置master,其它机器设置slave节点
单机主从模式注意:主节点master计算机和每个work工作节点计算机都必须具有 Locust 测试脚本的副本。
其中 slave 的节点数要小于等于本机的处理器数
步骤: 以单台计算机为例(既当做主控机,也当做工作机器)
-
Step1:→ 启动locust master节点
locust -f locustfile07.py --master -
Step2:→ 每个工作节点 locust -f locustfile07.py --worker
- 选择其中一台电脑,启动master节点,因为主节点无法操作别的节点,所以必须在其它机器上启动从属Locust节点,后面跟上--worker参数,以及 --master-host(指定主节点的IP /主机名)。
locust -f locustfile07.py --master
- 其它机器上(环境和主节点环境一致,都需要有locust的运行环境和脚本),启动 slave 节点,设置 --master-host
locust -f locustfile.py --worker --master-host=192.168.x.xx
更多参数介绍
- --master
将 locust 设置为 master 模式。Web 界面将在此节点上运行。
- --worker
将locuster设置为worker模式。
- --master-host= X. X. X. X
可选择与-- worker一起使用,以设置主节点的主机名/IP (默认值为127.0.0.1)
- --master-port
可选地与-- worker一起用于设置主节点的端口号(默认值为5557)。
-
-master-bind-host= X. X. X. X
可选择与--master一起使用。 确定主节点将绑定到的网络接口。 默认为*(所有可用接口)。 -
--master-bind-port=5557
可选择 与--master一起使用。 确定主节点将侦听的网络端口。 默认值为5557。 -
--expect-workers= X
在使用--headless启动主节点时使用。 然后主节点将等待,直到 X worker节点已经连接,然后测试才开始。
拉取镜像:
docker pull locustio/locust
运行容器:
docker run -p 8089:8089 -v $PWD:/mnt/locust locustio/locust -f /mnt/locust/locustfile.py

Docker Compose:
version: '3'
services:
master:
image: locustio/locust
ports:
- "8089:8089"
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile.py --master -H http://master:8089
worker:
image: locustio/locust
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile.py --worker --master-host master
Locust 的默认 HTTP 客户端使用python-requests。如果您计划以非常高的吞吐量运行测试并且运行 Locust 的硬件有限,那么它有时效率不够。Locust 还附带FastHttpUser使用geventhttpclient代替。它提供了一个非常相似的 API,并且使用的 CPU 时间显着减少,有时将给定硬件上每秒的最大请求数增加了 5 到 6 倍。
在相同的并发条件下使用FastHttpUser能有效减少对负载机的资源消耗从而达到更大的http请求。
比对结果如下:
locustfile11.py
HttpUser:


对比:FastHttpUser


进程:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程: 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程: 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
、
-
进程与线程比较:
-
进程用于独立的地址空间 ;线程依附于进程(先有进程后有线程) ,可以共享进程的地址空间
-
进程之间不共享全局变量 , 线程之间共享全局变量
-
线程是cpu 调度的基本单位; 进程是操作系统分配资源资源的最小单位
-
进程之间相互独立 ,都可并发执行 (核数大于线程数)
-
多进程运行其中某个进程挂掉不会影响其他进程运行, 多线程开发中当前进程挂掉 依附于当前进程中的多线程进行销毁
-
-
线程与协程比较
-
一个线程可包含多个协程 ,一个进程也可单独拥有多个协程
-
线程、进程 同步机制 ,协程异步
-
协程保留最近一次调用时状态,每次过程重入相当于唤醒
-
线程的切换由操作系统负责调度,协程由用户自己进行调度
-
资源消耗:线程的默认Stack大小是1M,而协程更轻量,接近1K。
-
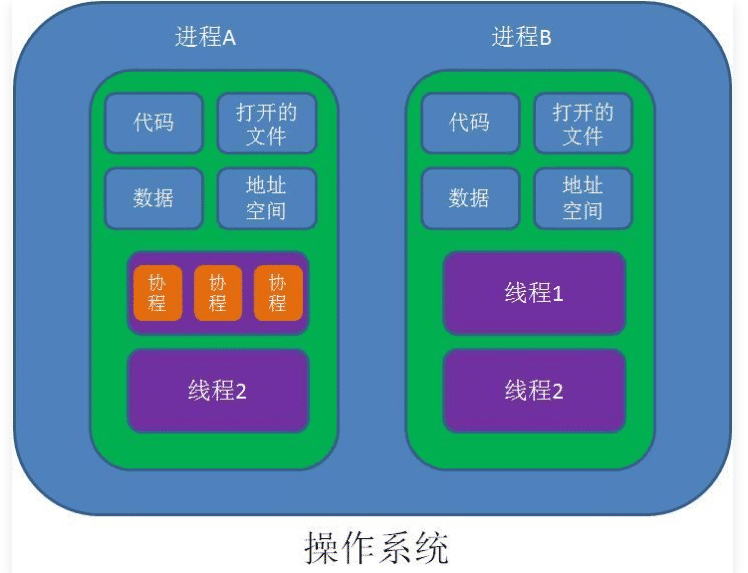
线程: 轻量级的进程 协程: 轻量级的线程 (用户态)
更多查阅:
- 一文读懂什么是进程、线程、协程
- https://cloud.tencent.com/developer/article/1546730
- Processes, threads, and coroutines
- https://subscription.packtpub.com/book/programming/9781788627160/1/ch01lvl1sec02/processes-threads-and-coroutines#:~:text=Processes%2C threads%2C and coroutines When you start an,detail the relationship between processes%2C threads%2C and coroutines.
- Comparison of Process , Thread and Coroutines
- https://functional.works-hub.com/learn/comparison-of-process-thread-and-coroutines-becf6
如果Locust文件位于与locustfile.py在不同的子目录/或者文件名不一样,则使用参数-f+文件名:
$ locust -f locust_files/my_locust_file.py
要在多个进程中运行Locust,我们可以通过指定--master:
$ locust -f locust_files/my_locust_file.py --master
启动任意数量的从属进程:
$ locust -f locust_files/my_locust_file.py --slave
如果要在多台机器上运行Locust,则在启动从属服务器时还必须指定主服务器主机(在单台计算机上运行Locust时不需要,因为主服务器主机默认为127.0.0.1):
$ locust -f locust_files/my_locust_file.py --slave --master-host=192.168.0.100
还可以在配置文件(locust.conf或~/.locust.conf)或以LOCUST_前缀的env vars中设置参数
例如:(这将与上一个命令执行相同的操作)
$ LOCUST_MASTER_HOST=192.168.0.100 locust
注意:要查看所有可用选项,请键入:locust —help
https://docs.locust.io/en/stable/what-is-locust.html
3. WebSocket与HTTP的关联和差异相同:
- 建立在TCP之上,通过TCP协议来传输数据。
- 都是可靠性传输协议
- 都是应用层协议。
不同:
- WebSocket是HTML5中的协议,支持持久连接,HTTP不支持持久连接
- HTTP是单向协议,只能由客户端发起,做不到服务器主动向客户端推送信息
参考资料:https://github.com/locustio/locust/wiki/Articles
