!
层次聚类顾名思义,是按照层次来进行聚类,其中不同的层次构成了树状结构的不同层级,叶子节点则对应真实的样本点,示意如下
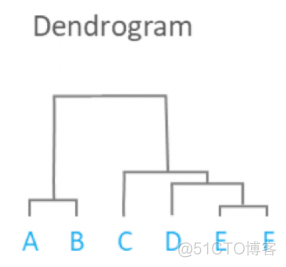
对于这颗聚类树而言,其构建方式可以分为以下两种
1. 自下而上,由叶子节点开始,将相似样本划分为不同的子cluster,然后对cluster也按照相似度组成更大的cluster, 直到根节点为止,该方法也叫做凝聚法Agglomerative
2. 自上而下,从根节点开始,将一组样本不断拆分成不同的子cluster,直到叶子节点为止,该方法也叫做分裂法Divisive
目前,应用最广泛的是凝聚法,该方法的核心步骤是以下两种距离的计算
1. 样本间距离
距离的衡量可以有多种方式,比如最常用的欧氏距离,对于凝聚法而言,首先计算样本间的距离矩阵,然后根据距离近的样本聚集在一起。
2. cluster间距离
对于样本而言,其多个特征可以看做不同维度的数值,直接套用距离公式计算即可得到两个样本间的距离;对于cluster而言,每个cluster下面包含了多个样本,此时就需要采取特定的距离定量策略,常用的策略有以下3种
1. single linkage, 将两组数据中距离最近的两个样本点的距离作为cluster之间的距离
2. complete linkage,将两组数据中距离最远的两个样本点的距离作为cluster之间的距离
3. average linkage,将两组数据中的样本两两求解距离,最后计算均值,作为两个cluster之间的距离
从定义可以看出,以上三种方法分别考虑了最小,最大和平均值,其中最小,最大都容易受到异常值点的干扰,而均值则计算量较大。
下面通过一个例子来看下凝聚法的运算过程,首先有5个样本的数据,第一步计算距离矩阵,结果如下
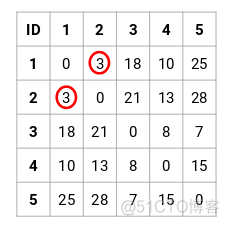
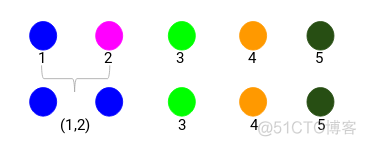
可以看到,距离矩阵中最小值为3,为样本1与样本2之间的距离,所以可以先将1和2聚为一类,图示如下
然后将(1,2)这个cluster与其他样本计算距离矩阵,结果如下
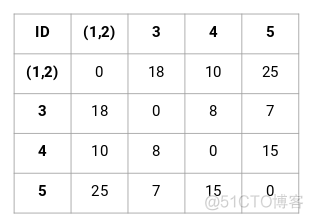
最小值为7,是样本3和样本5的距离,所以将3和5聚为一类,接下来就是计算(1,2), (3,5), 4这3组样本的距离,同样是距离最近的聚为一类。各个层级的聚类过程示意如下
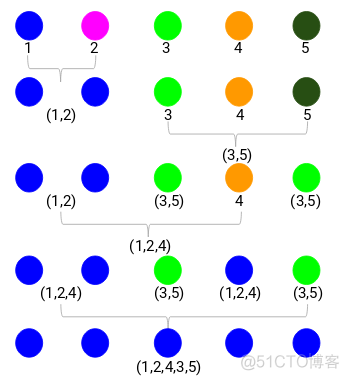
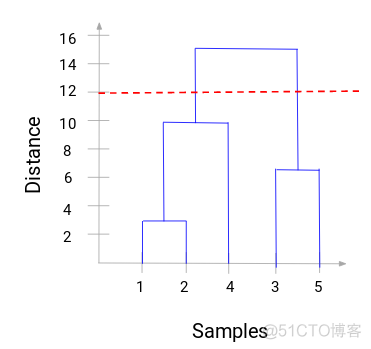
最终可以绘制如下所示的聚类树
在scikit-learn中,使用层次聚类的代码如下
>>> from sklearn.cluster import AgglomerativeClustering>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],[4, 2], [4, 4], [4, 0]])
>>> clustering = AgglomerativeClustering().fit(X)
>>> clustering
AgglomerativeClustering()
>>> clustering.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
labels_属性表示样本对应的cluster。和k-means聚类一样,层次聚类的原理也比较简单,但是更加适用于类别较多,数据量较大的样本。
·end·

一个只分享干货的
生信公众号