赛事链接:https://tianchi.aliyun.com/competition/entrance/231593/introduction?spm=5176.12281925.0.0.7e157137DpLQO6
代码下载:https://github.com/luxuantao/alibaba_tianchi_book
请自己阅读赛题描述和下载代码
1.数据探索 1.1数据说明本赛题提供用户在2016年1月1日至2016年6月30日之间真实线上线下消费行为,预测用户在2016年7月领取优惠券后15天以内的使用情况。
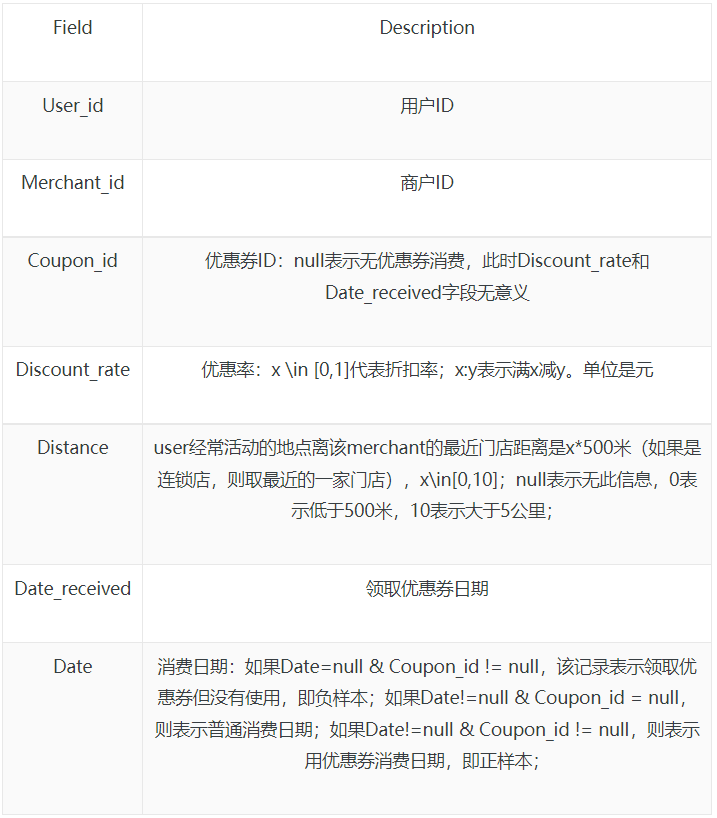
- Table 1: 用户线下消费和优惠券领取行为
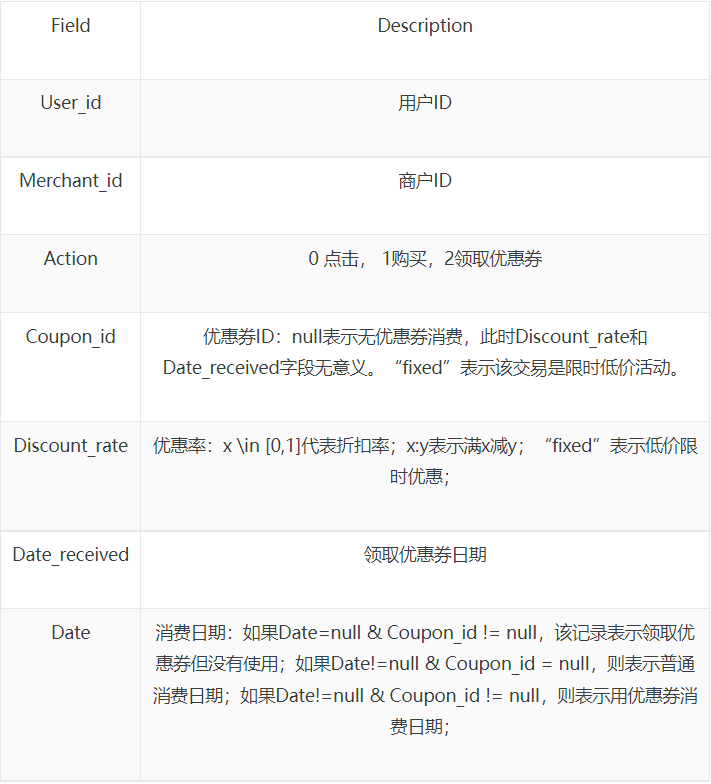
- Table 2: 用户线上点击/消费和优惠券领取行为
- Table 3:用户O2O线下优惠券使用预测样本
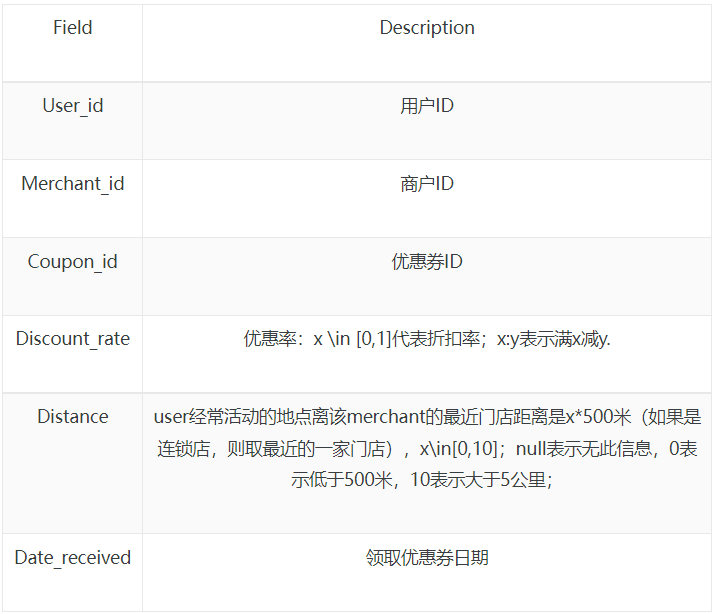
- Table 4:选手提交文件字段,其中user_id,coupon_id和date_received均来自Table 3,而Probability为预测值

我们的目标是要预测用户优惠券的线下使用情况,线上数据我们重点关注与用户相关的特征(是作为线下数据的一个辅助),线下我们关注的特征数据就比较多了。
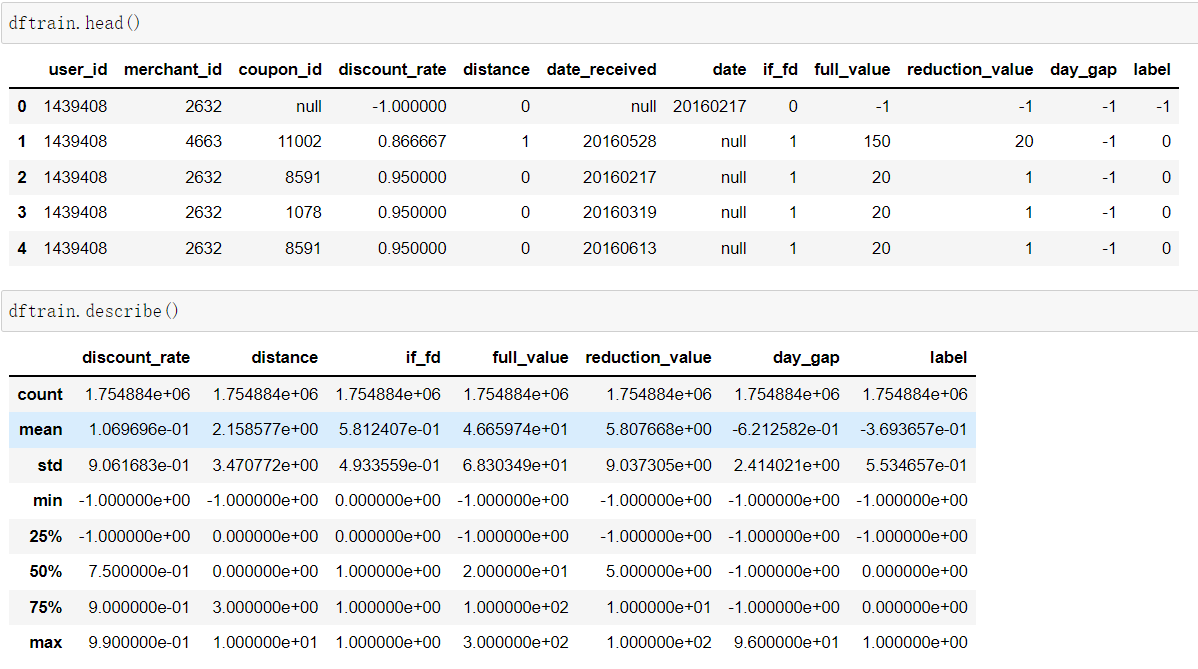
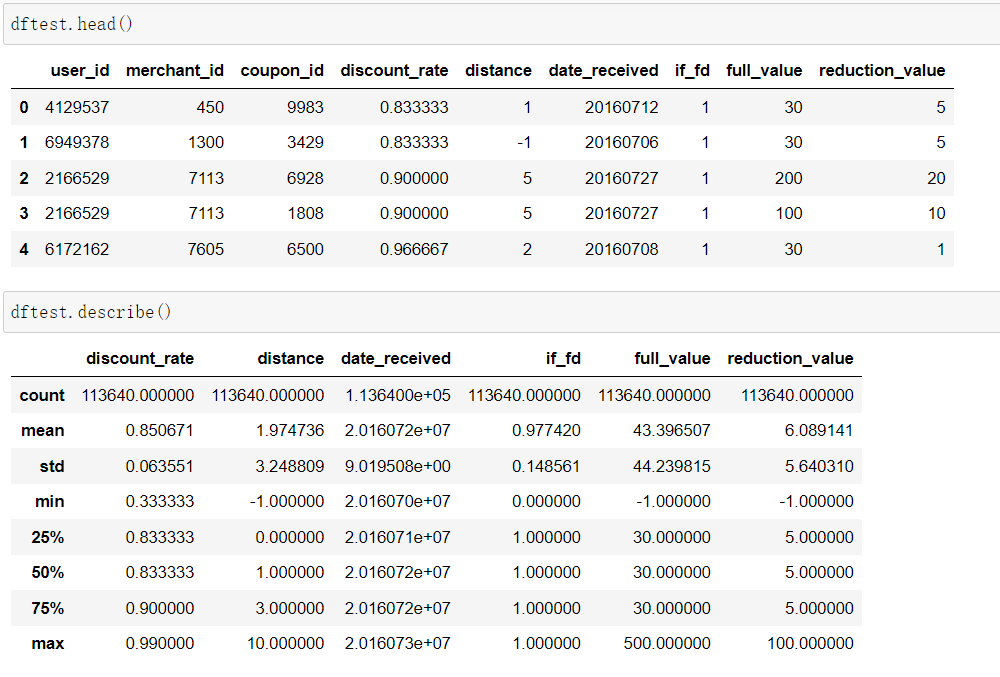
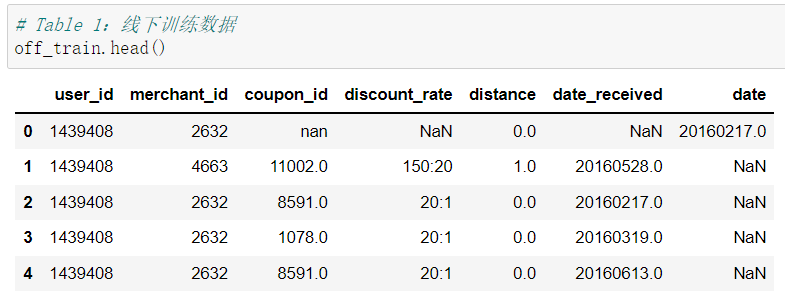
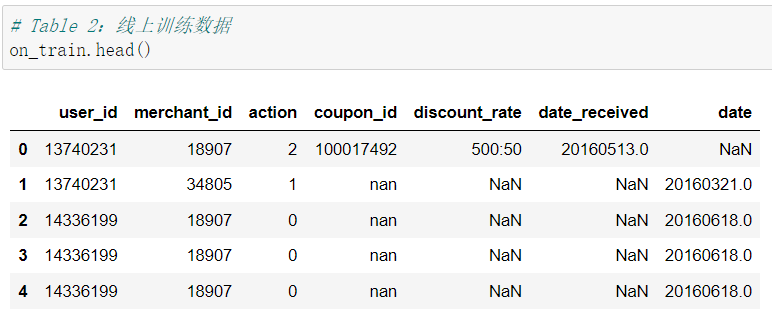
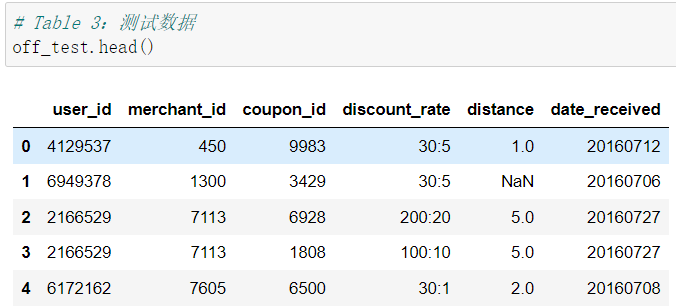
首先我们先看看整理好的Table 1.2.3 的数据大概都长什么样儿。
- Table 1:线下训练数据
- Table 2:线上训练数据
- Table 3:测试数据
这里我们需要确定每个数据的数据边界,也就是从几年几月几号到几年几月几号,这样方便后续的数据整理对应,于是需要对数据日期范围情况进行初步探索。
- 数据集领券日期范围
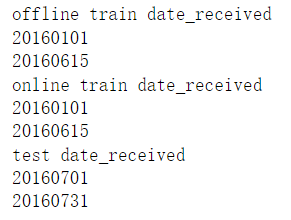
- 查看训练集的用卷日期范围
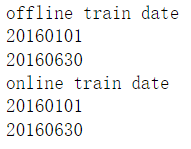
通过探索可以发现训练数据的用券数据是到6月30日,而领券日期并不是到6月30日,而是到6月15日,这在设计滑窗结构的时候需要注意(滑窗结构后续会讲解)。
1.3训练集与测试集的相关性在机器学习比赛及实际应用的时候,不同数据的价值是不一样的,同时也并不是所有得到的数据都是有用的。对测试集和训练集数据的重合情况进行探查对于后续的特征构建的思路有很大的指导作用。
- 对用户(user_id)在训练集和测试集的重合情况进行探索发现:

- 对商家(merchant_id)在训练集和测试集的重合情况进行探索发现:

- 对优惠券(coupon_id)在训练集和测试集的重合情况进行探索发现:

最后我们总结如下:
- 测试集的用户ID与Offline训练集重复占比0.999以上,与Online训练集重复占比0.565。
- 测试集的商家ID与Offline训练集重复占比0.999以上,与Online训练集没有重复。
- 测试集的优惠券ID与训练集都没有重复。
结论:Online数据价值比较低,后续特征提取将以Offline训练集为主。在提取优惠券统计特征的时候不能通过ID进行合并。 在后续可视化分析中将主要在Offline训练集及测试集之间进行。
1.4将特征数值化给定的数据中,除了折扣和距离,其他的数据都为文本,需要先对其进行数据化才能进行探索,也就是对数据先进行清洗。
- 计算折扣率,将满减和折扣统一
因为discount_rate为null的时候一般都是没有使用优惠券,这个时候折扣应该是1。discount_rate的数据有2种模式,第一种就是x \in [0,1]代表折扣率;第二种x:y表示满x减y。
- 整理日期,并获取Label,输入内容为Date:Date_received
整理好后,重新进行数据分析: