 作为SpringData JPA系列内容的第二篇,此处以SpringBoot项目为基准,讲一下集成SpringData JPA的相关要点,带你快速的上手SpringData JPA,并用实例演示常见的DB操作场景,让你分分钟轻松玩转JPA。
作为SpringData JPA系列内容的第二篇,此处以SpringBoot项目为基准,讲一下集成SpringData JPA的相关要点,带你快速的上手SpringData JPA,并用实例演示常见的DB操作场景,让你分分钟轻松玩转JPA。
大家好,又见面了。
这是Spring Data JPA系列的第2篇,在上一篇《Spring Data JPA系列1:JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?给你个选择SpringDataJPA的理由!》中,我们对JPA的基本概念有了一个整体的了解,也对JAVA中进行DB操作的一些周边框架、概念等有了初步的感知。同时也给出了SpringData JPA与MyBatis的选择判断依据。
那么,如果你已经决定使用SpringData JPA来作为项目中DB操作的框架,具体应该如何去做呢?
作为SpringData JPA系列内容的第二篇,此处以SpringBoot项目为基准,讲一下集成SpringData JPA的相关要点,带你快速的上手SpringData JPA,并用实例演示常见的DB操作场景,让你分分钟轻松玩转JPA。
SpringBoot集成SpringData JPA 依赖引入SpringBoot项目工程,在pom.xml中引入相关依赖包即可:
<!-- 数据库相关操作 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
SpringData JPA提供了部分注解,可以添加在Application入口程序类上方,来满足相关诉求。当然如果没有额外的特殊诉求,则可以什么都不需要加。
@SpringBootApplication
// 可选,指定扫描的表映射实体Entity的目录,如果不指定,会扫描全部目录
//@EntityScan("com.veezean.demo.entity")
// 可选,指定扫描的表repository目录,如果不指定,会扫描全部目录
//@EnableJpaRepositories(basePackages = {"com.veezean.demo.repository"})
// 可选,开启JPA auditing能力,可以自动赋值一些字段,比如创建时间、最后一次修改时间等等
@EnableJpaAuditing
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
这里@EntityScan和@EnableJpaRepositories被注释掉了,且默认的情况下是不需要添加这个配置的,JPA会自动扫描程序所在包内的所有定义的Entity和Repository对象并加载。但是,某些比较大型的项目里面,我们可能会封装一个common jar作为项目公共依赖,然后再分出若干子项目,每个子项目里面依赖common jar,这个时候如果想要加载common jar里面定义的Entity和Repository,就需要用到这两个注解。
在application.properties中配置一些数据库连接信息,如下:
spring.datasource.url=jdbc:mysql://<ip>:<port>/vzn-demo?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai
spring.datasource.username=vzn-demo
spring.datasource.password=<password>
#Java代码实体字段命名与数据库表结构字段之间的名称映射策略
spring.jpa.hibernate.naming.implicit-strategy=org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl
#下面配置开启后,会禁止将驼峰转为下划线
#spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
spring.jpa.open-in-view=false
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
# 控制是否可以基于程序中Entity的定义自动创建或者修改DB中表结构
spring.jpa.properties.hibernate.hbm2ddl.auto=update
# 控制是否打印运行时的SQL语句与参数信息
spring.jpa.show-sql=true
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.idle-timeout=600000
spring.datasource.hikari.max-life-time=1800000
通过前面的几个步骤的操作,便完成了SpringData JPA与项目的集成对接。本章节介绍下在业务代码里面应该如何使用SpringData JPA来完成一些DB交互操作。
Table对应Entity编写编写数据库中Table对应的JAVA实体映射类,并通过相关注解,来描述字段的一些附加约束信息。
- 用户表实体
@Data
@Entity
@Table(name = "user")
@EntityListeners(value = AuditingEntityListener.class)
public class UserEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String workId;
private String userName;
@ManyToOne(optional = false)
@JoinColumn(name = "department")
private DepartmentEntity department;
@CreatedDate
private Date createTime;
@LastModifiedDate
private Date updateTime;
}
- 部门表实体
@Data
@Entity
@Table(name = "department")
@EntityListeners(value = AuditingEntityListener.class)
public class DepartmentEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String deptName;
@CreatedDate
private Date createTime;
@LastModifiedDate
private Date updateTime;
}
这里可以看到,所谓的Entity,其实也就是一个普通的JAVA数据类,只是与普通的JAVA数据类相比,多了一些注解。没错!SpringData JPA正式通过各种注解,来完成对各个字段的定义与行为约束,以及完成表间关联关系(比如外键)。
自定义Repository编写常见的一些注解以及含义功能说明,在本文的末尾表格里面进行了梳理,此处不赘述。
继承JpaRepository接口提供自定义Repository接口类,在自定义接口类中,添加业务需要的定制化的DB操作接口。这里定制的时候,可以基于SpringData JPA的命名规范进行接口方法的命名即可,无需关注其具体实现,也不需要提供实现类。
- 用户repository
@Repository
public interface UserRepository extends JpaRepository<UserEntity, Long> {
List<UserEntity> findAllByDepartment(DepartmentEntity department);
UserEntity findFirstByWorkId(String workId);
List<UserEntity> findAllByDepartmentInAndUserNameLike(List<DepartmentEntity> departmentIds, String userName);
@Query(value = "select * from user where user_name like ?1", nativeQuery = true)
List<UserEntity> fuzzyQueryByName(String userName);
}
上述代码里面,演示了2种自定义接口的策略:
- 基于SpringData JPA的命名规范,直接定义接口
- 使用自定义的SQL语句进行个性化定制,这种适用于一些需要高度定制化处理的场景
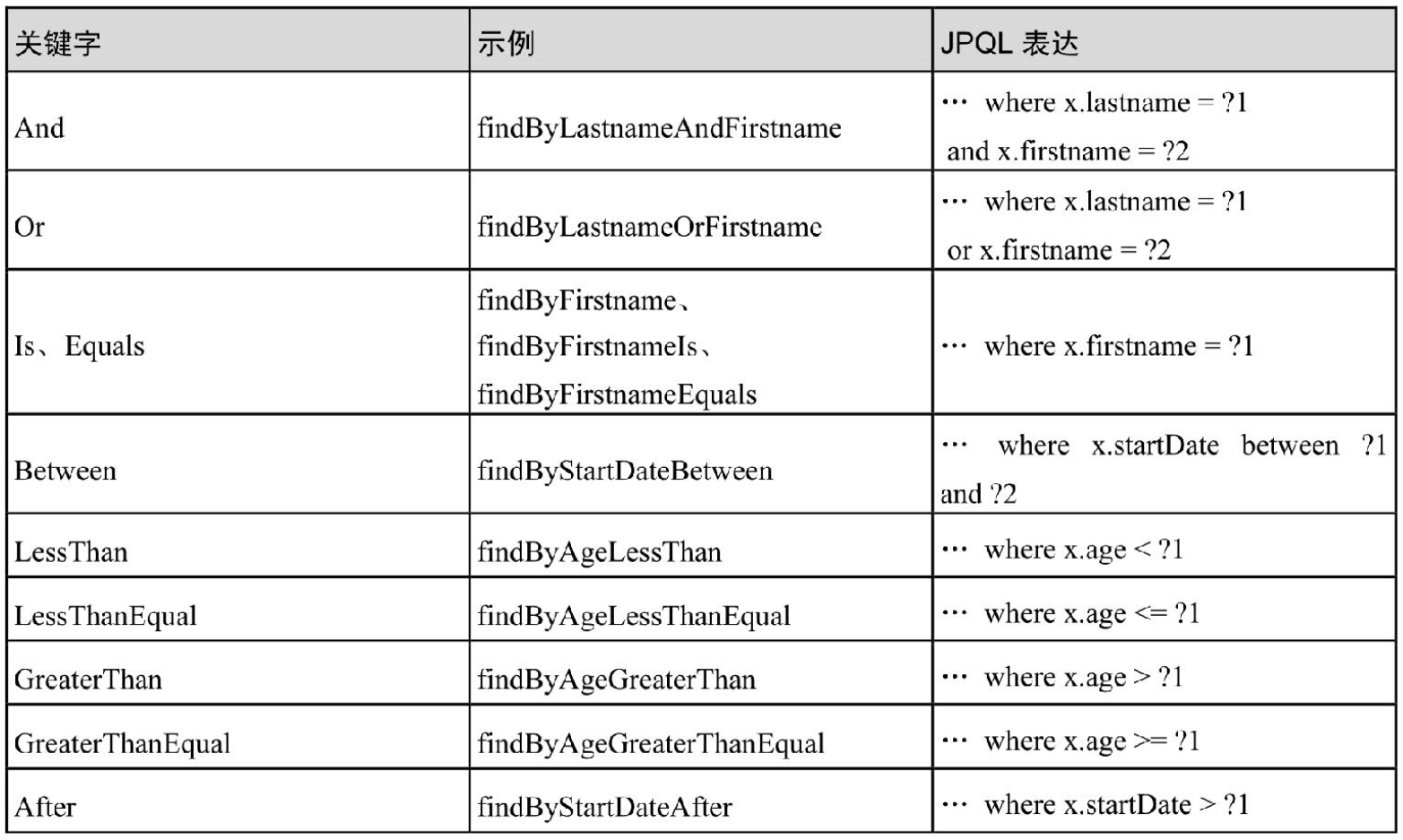
业务层执行DB操作 写入数据JPA中支持的一些命名关键字与命名示例,参见本文后面梳理的表格。
SpringData JPA写操作逻辑很简单,只有一个save方法即可,如果批量写入操作,使用saveAll方法即可。
- 会判断ID,如果唯一ID已存在,则按照update逻辑执行;
- 如果唯一ID记录不存在,则按照insert逻辑执行。
public void testUser() {
DepartmentEntity deptEntity1 = new DepartmentEntity();
deptEntity1.setDeptName("研发部门");
deptEntity1.setId(1L);
DepartmentEntity deptEntity2 = new DepartmentEntity();
deptEntity2.setDeptName("产品部门");
deptEntity2.setId(2L);
// 写入部门信息
departmentRepository.save(deptEntity1);
departmentRepository.save(deptEntity2);
departmentRepository.flush();
UserEntity entity1 = new UserEntity();
entity1.setWorkId("123456");
entity1.setDepartment(deptEntity1);
entity1.setUserName("王小二");
UserEntity entity2 = new UserEntity();
entity2.setWorkId("234567");
entity2.setDepartment(deptEntity1);
entity2.setUserName("王小五");
UserEntity entity3 = new UserEntity();
entity3.setWorkId("345678");
entity3.setDepartment(deptEntity1);
entity3.setUserName("刘大壮");
UserEntity entity4 = new UserEntity();
entity4.setWorkId("345678");
entity4.setDepartment(deptEntity2);
entity4.setUserName("张三");
// 写入用户信息
userRepository.saveAll(Stream.of(entity1, entity2, entity3, entity4).collect(Collectors.toList()));
userRepository.flush();
}
执行调用后,查看数据库,可见数据已经写入DB中:
- Department表

- User表

从上面可以看出,代码里面其实并没有对create_time和update_time字段进行赋值,但是数据存储到DB的时候,这两个字段被自动赋值了,这个主要是因为开启了自动Audit能力,主要2个地方的代码有关系:
1、Application启动类上的注解,开启允许JPA自动Audit能力
@EnableJpaAuditing
2、Entity类上添加注解
@EntityListeners(value = AuditingEntityListener.class)
3、Entity中具体字段上加上对应注解:
@CreatedDate
private Date createTime;
@LastModifiedDate
private Date updateTime;
常见的数据查询操作,代码层面实现调用如下:
public void testUser() {
DepartmentEntity deptEntity1 = new DepartmentEntity();
deptEntity1.setDeptName("研发部门");
deptEntity1.setId(1L);
DepartmentEntity deptEntity2 = new DepartmentEntity();
deptEntity2.setDeptName("产品部门");
deptEntity2.setId(2L);
// 获取所有用户列表 --- JPA默认提供的方法
List<UserEntity> userEntities = userRepository.findAll();
log.info("findAll result :{}", userEntities);
// 获取符合条件用户列表 --- 定制方法: 根据部门字段查询符合条件列表
List<UserEntity> userEntitiesInDept = userRepository.findAllByDepartment(deptEntity1);
log.info("findAllByDepartment result count:{}", userEntitiesInDept);
// 获取符合条件用户 --- 定制方法: 根据工号查询用户信息
UserEntity userEntity = userRepository.findFirstByWorkId("123456");
log.info("findFirstByWorkId result: {}", userEntity);
// 多条件查询符合条件用户列表 --- 定制方法: 根据部门与名称字段复合查询
List<UserEntity> fuzzyQueryUsers = userRepository.findAllByDepartmentInAndUserNameLike(Stream.of(deptEntity1,
deptEntity2).collect(Collectors.toList()),
"王%");
log.info("findAllByDepartmentInAndUserNameLike result count: {}", fuzzyQueryUsers);
}
从上面的演示代码可以看出,SpringData JPA的一个很大的优势,就是Repository层可以简化大部分场景的代码编码事务,遵循一定的方法命名规范,即可实现相关的能力。
比如:
List<UserEntity> findAllByDepartmentInAndUserNameLike(List<DepartmentEntity> departmentIds, String userName);
看方法名就直接可以知道这个具体的DB操作逻辑:在给定的部门列表里面查询所有名称可以模糊匹配上的人员列表!至于如何去具体实现,这个开发人员无需关注、也不需要去写对应SQL语句!
藏在配置中的小技能在前面章节中有介绍集成SpringData JPA涉及到的一些常见配置,此处对其中部分配置的含义与功能进行一个补充介绍。
控制是否自动基于代码Entity定义自动创建变更数据库表结构spring.jpa.properties.hibernate.hbm2ddl.auto=update
如果设置为update,程序运行之后,会自动在DB中将Table创建出来,并且相关约束条件(比如自增主键、关联外键之类的)也会一并创建并设置上去,如下示意,左侧的代码自动创建出右侧DB中的表结构:

补充说明:
虽然这个功能比较方便,但是强烈建议在生产环境上关闭此功能。因为DB表结构改动变更,对于生产环境而言,是一个非常重大的操作,一旦出问题甚至会影响到实际数据。为了避免造成不可逆的危害,保险起见,还是人工手动操作变更下比较好。
控制是否打印相关操作的SQL语句spring.jpa.show-sql=true
如果设置为true,则会在日志中打印每次DB操作所执行的最终SQL语句内容,这个比较适合与开发过程中的问题定位分析,生产环境上建议关闭(影响性能)。
如果开启后,打印的日志示例如下:
2022-06-14 14:30:50.329 INFO 23380 --- [io-48080-exec-3] o.a.c.c.C.[.[localhost].[/veezean-demo] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2022-06-14 14:30:50.329 INFO 23380 --- [io-48080-exec-3] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2022-06-14 14:30:50.337 INFO 23380 --- [io-48080-exec-3] o.s.web.servlet.DispatcherServlet : Completed initialization in 8 ms
Hibernate: insert into department (create_time, dept_name, update_time) values (?, ?, ?)
Hibernate: insert into department (create_time, dept_name, update_time) values (?, ?, ?)
Hibernate: insert into user (create_time, department, update_time, user_name, work_id) values (?, ?, ?, ?, ?)
Hibernate: insert into user (create_time, department, update_time, user_name, work_id) values (?, ?, ?, ?, ?)
Hibernate: insert into user (create_time, department, update_time, user_name, work_id) values (?, ?, ?, ?, ?)
Hibernate: insert into user (create_time, department, update_time, user_name, work_id) values (?, ?, ?, ?, ?)
2022-06-14 14:30:50.544 INFO 23380 --- [io-48080-exec-3] o.h.h.i.QueryTranslatorFactoryInitiator : HHH000397: Using ASTQueryTranslatorFactory
通过前面内容的介绍以及相关示例代码的演示,可以看出SpringData JPA中有很多情况都是借助不同注解来约定一些属性或者处理逻辑策略的,且在自定义接口方法的时候,需要遵循SpringData JPA固有的一套命名规范才行。
这里对一些高频易用的注解与常见的接口方法命名规范进行梳理介绍。
常用注解
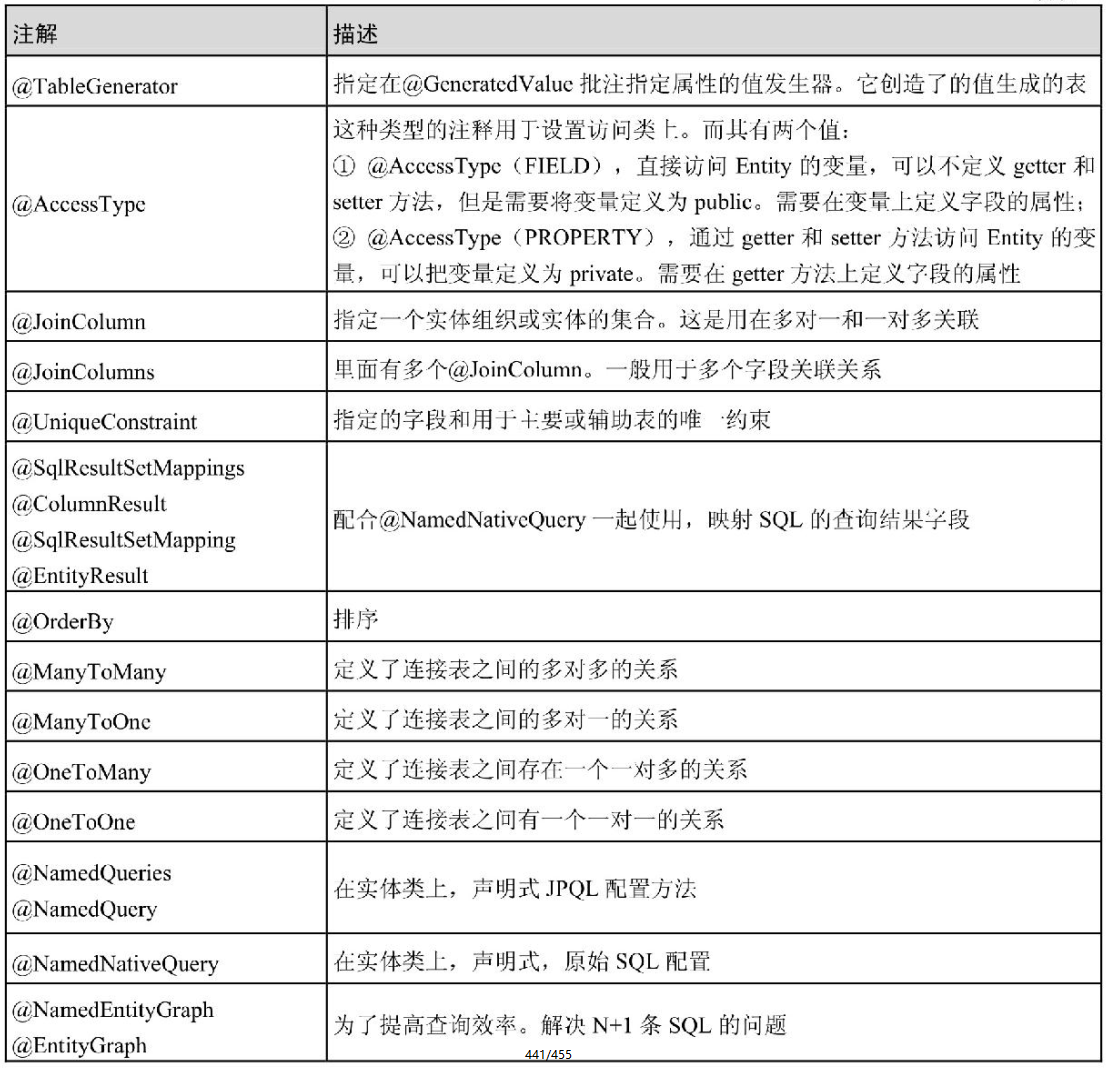
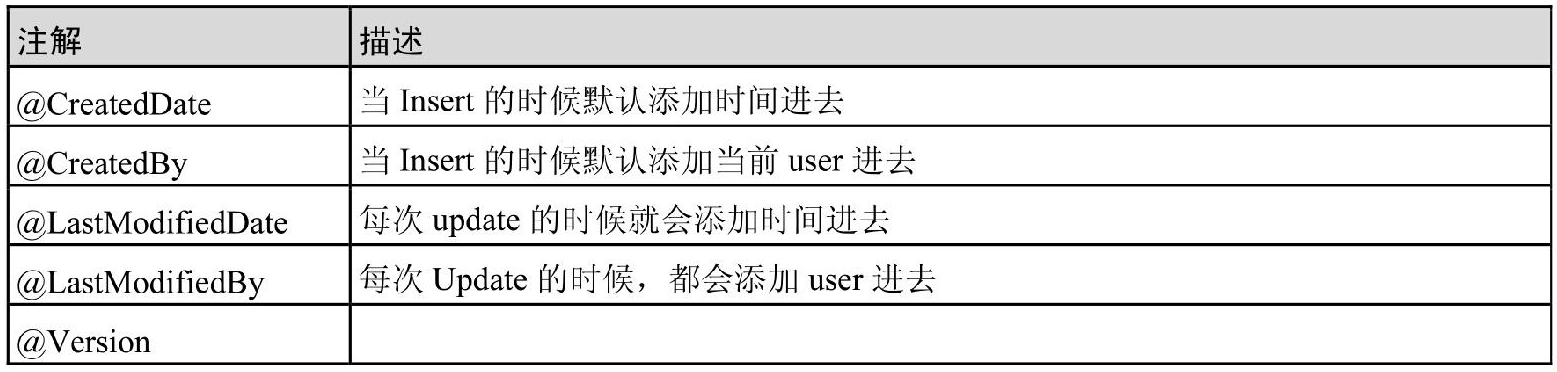
DB里面一些关键字对应的SpringData JPA中命名关键字列举如下:

好啦,本篇内容就介绍到这里。
跟着本篇内容,可以让你顺利的完成SpringBoot项目与JPA的集成配置,以及对项目中如何使用JPA进行代码开发有了个整体的感知,可以应付大部分场景的基础业务代码开发诉求。
本系列教程是按照由面到点、由浅入深的逻辑进行内容编排的。在本系列的下一篇内容中,我会进一步对SpringData JPA中的一些核心类型与核心方法进行剖析,让你不仅仅停留在简单使用层面,更能对JPA有个深度的了解、达到精通级别。如果感兴趣的话,欢迎关注我的后续系列文档。
如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
补充
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第二篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为5篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA用法与技能探究》系列涵盖内容:
- 开篇介绍 —— 《Spring Data JPA系列1:JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?给你个选择SpringDataJPA的理由!》
- 快速上手 —— 《Spring Data JPA系列2:SpringBoot集成JPA详细教程,快速在项目中熟练使用JPA》
- 深度进阶 —— 《JPA核心类型与用法介绍》
- 可靠保障 —— 《聊一聊数据库的事务,以及Spring体系下对事务的使用》
- 周边扩展 —— 《JPA开发辅助效率提升方案介绍》
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注。
期待与你一起探讨,一起成长为更好的自己。
