列表,字符串,字典,操作符,文件,函数,面向对象的部分基础知识 1.列表 列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。 列表的数据项不需要具有相
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可

代码理解:列表的索引,列表数据的增删改,以及列表推导式的使用
# 列表
all_in_list=[0.3,'hello','True']
print('列表数据为:',end='')
print(all_in_list)
# 正向索引从开始
res=all_in_list[0]
print('all_in_list[0]的值为:',end='')
print(res)
# 反向所有从-1开始
res=all_in_list[-2]
print('all_in_list[-2]的值为:',end='')
print(res)
# 列表的切片,左闭右开
res=all_in_list[0:2]
print('all_in_list[0:2]的切片值为:',end='')
print(res)
# 末尾新增元素
all_in_list.append('hello world')
# 指定位置前插入元素,成为指定位置上的元素
all_in_list.insert(0,'pre-hello')
print('添加新元素后为:',end='')
print(all_in_list)
# 删除元素
all_in_list.remove('hello world')
# 删除前两个元素
del all_in_list[:2]
print('删除元素后为:',end='')
print(all_in_list)
# 修改元素值
all_in_list[0]=100
print('修改元素后为:',end='')
print(all_in_list)
# for循环
x=[]
for i in range(10):
x.append(i)
print('for循环添加元素后为:',end='')
print(x)
#列表推导式
b=[i for i in range(1,11)]
c=[i**2 for i in range(1,11)]
d=[i**2 for i in range(1,11) if i%2==0]
print('各个列表推导式的值为:',end='')
print(b)
print(c)
print(d)
#练习1:求曲边梯形的面积
import math
n=10000
width=2*math.pi/n
# 方法一:利用for循环构建核心数据结构
x=[]
y=[]
for i in range(n):
x.append(i*width)
for i in x:
y.append(abs(math.sin(i)))
S=sum(y)*width
print('方法一曲边梯形的面积为:',end='')
print(S)
# 方法二:利用列表推导式构建核心数据结构
s=[abs(math.sin(i*width))*width for i in range(n)]
print('方法二曲边梯形的面积为:',end='')
print(sum(s))
代码运行结果

Python语言常用以下类型的运算符:算术运算符、比较关系操作符、赋值操作符、逻辑操作符
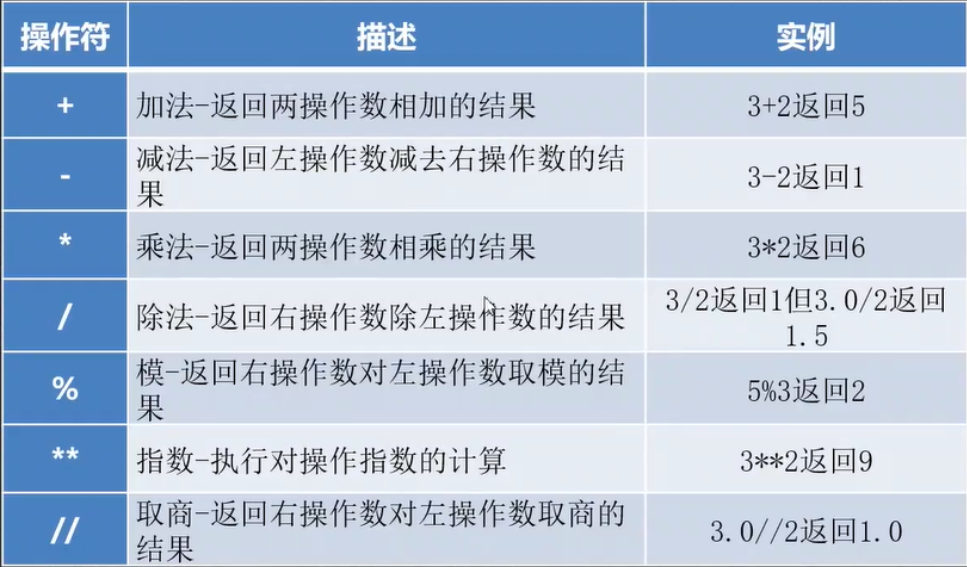



代码理解:逻辑控制符、字符串的包含in、条件判断语句、冒泡排序的交换值操作
# Python逻辑控制符
res=1<2
print('1<2的正确性:',end='')
print(res)
res=1<2<3
print('1<2<3的正确性:',end='')
print(res)
res='Name'=='name'
print("'Name'=='name'的正确性:",end='')
print(res)
res='M' in 'magic'
print("'M'在'magic'里的正确性:",end='')
print(res)
# 条件判定语句
if 1<2:
print('如果1<2正确,则输出:', end='')
print('1.hello')
if 1<0:
print('如果1<0正确,则输出:', end='')
print('2.hello')
else:
print('如果1<0不正确,则输出:', end='')
print('2.world')
if 1<0:
print('如果1<0正确,则输出:', end='')
print('3.hello')
elif 2<1:
print('如果1<0不正确,但2<1正确,则输出:', end='')
print('3.world')
else:
print('如果1<0不正确,且2<1也不正确,则输出:', end='')
print('3.hehe')
# 冒泡排序
x=[1,2,6,0.3,2,0.5,-1,2.4]
print('冒泡排序前值为:', end='')
print(x)
n=len(x)
for i in range(n):
for j in range(i):
if x[j]>x[i]:
# 交换值
x[i],x[j]=x[j],x[i]
print('冒泡排序后值为:', end='')
print(x)
代码运行结果

字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:d = {key1 : value1, key2 : value2 }
代码理解:根据字典索引值,修改值,添加值,删除值,以及字典推导式生成字典
# 字典
dic={'h':'hello',0.5:[0.2,0.3],'w':'world'}
print('字典数据为:',end='')
print(dic)
#根据键索引值
res=dic['h']
print("dic['h']对应的值为:",end='')
print(res)
# 根据键修改一个元素
dic['h']=100
print("修改后的字典为:",end='')
print(dic)
# 添加一个元素
dic['hw']='hello world'
print("添加一个键值后的字典为:",end='')
print(dic)
# 同时添加多个元素
dic.update({1:2,3:4})
print("添加多个键值后的字典为:",end='')
print(dic)
# 根据键删除某个元素
del dic['h']
print("删除键值后的字典为:",end='')
print(dic)
# 字典推导式
a={i:i**2 for i in range(10)}
print("使用字典推导式生成的字典为:",end='')
print(a)
代码运行结果

字符串是 Python 中最常用的数据类型。我们可以使用引号 ( ' 或 " ) 来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。

代码理解:字符串带换行和不带换行的两种生成方式、字符串的索引,拼接基本操作、字符串分割、字符串全转为小写
# 字符串,双引号字符串和单引号无区别
string="My name"
print('生成的字符串为:'+string)
# 三引号可以进行换行
string='''My
name
'''
print('生成的有换行的字符串为:'+string)
string='My name'
print('单引号与双引号生成的字符串相同,它为:'+string)
print(string)
# 索引字符串第一个元素
print('字符串第一个元素为:'+string[0])
# 索引字符串前两个元素
print('字符串前两个元素为:'+string[:2])
# 重复两次字符串
print('重复两次字符串为:'+string*2)
# 拼接字符串
print('拼接字符串为:',end='')
print(string+' is xxx')
# 分割字符串,根据逗号进行分割, 返回结果为列表
res=string.split(sep=',')
print('根据逗号进行分割字符串后为:',end='')
print(1,string)
# 将字符串字母全部变成小写
res=string.lower()
print('将字符串字母全部变成小写为:',end='')
print(res)
代码运行结果




代码理解
# 文件操作
f=open("Walden.txt","r")
# 读取文件内容
txt=f.read()
print(txt)
# 读取文件内容的前100行
txt=f.read(100)
print(txt)
f.close()
# 逐行读取文件内容,并返回列表
f=open("Walden.txt","r")
txt_lines=f.readlines()
print(txt_lines)
f.close()
#练习3:读取小说中的单词频次
import re
f=open("Walden.txt","r")
# 读取进来的数据类型是字符串
txt=f.read()
f.close()
# 将字符串中字符变为小写
txt=txt.lower()
# 去除小说中的标点符号
txt=re.sub('[,.?:“\’!-]','',txt)
# 单词分割
words=txt.split()
word_sq={}
for i in words:
if i not in word_sq.keys():
word_sq[i]=1
else:
word_sq[i]+=1
# 排序
res=sorted(word_sq.items(),key=lambda x:x[1],reverse=True)
print(res)
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
代码理解
#函数自定义
#第一种方式
def Sum(x,y):
return x+y
# 第二种方式,函数的简单自定义
# 返回x的平方
y=lambda x:x**2
# 返回x的第一个元素
y1=lambda x:x[1]
res=Sum(1,2)
print(res)
res=y(10)
print(res)
res=y1(['hello',0])
print(res)
#练习4:自定义求序列偶数个数的函数
def su(x):
z=0
for i in x:
if i%2==0:
z+=1
return z
res=su([1,2,3,4,5,6])
print(res)
面向对象的一些基本特征:
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
代码理解
# 方法与函数的区别
all_in_list=[2.5,'hello','world',3]
string='My name'
all_in_list.append('hehe')
#对于字符串对象而言,是没有append方法的
#string.append('Y’)
res=string.split()
# split是一个方法,是字符串对象才有的一种方法
#all_in_list.split()
print(all_in_list)
print(res)
# 面向对象
class Human:
def __init__(self,ag=None,se=None):
# 类的属性
self.age=ag
self.sex=se
# 类的方法
def square(self,x):
return x**2
zhangfei=Human(ag=23,se='男')
res=zhangfei.square(10)
print(res)
res=zhangfei.age
print(res)
res=zhangfei.sex
print(res)