-
论文地址:https://arxiv.org/abs/1808.01244
-
论文代码:https://github.com/princeton-vl/CornerNet
CornerNet将目标检测定义为左上角点和右下角点的检测。网络结构如图1所示,通过卷积网络预测出左上角点和右下角点的热图,然后将两组热图组合输出预测框,彻底去除了anchor box的需要。论文通过实验也表明CornerNet与当前的主流算法有相当的性能,开创了目标检测的新范式。
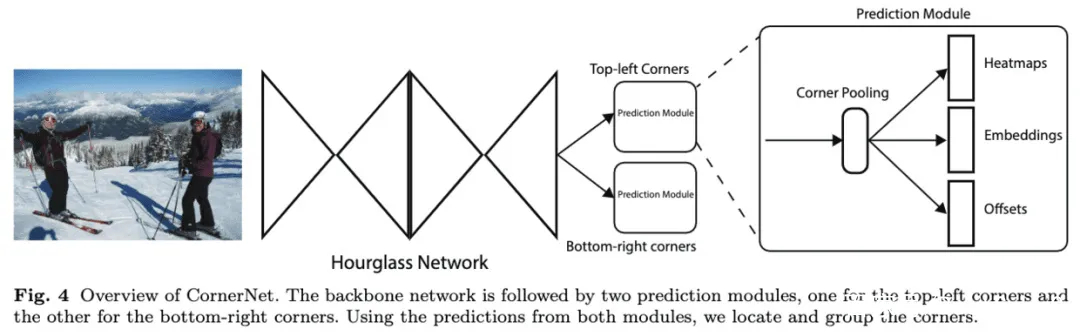
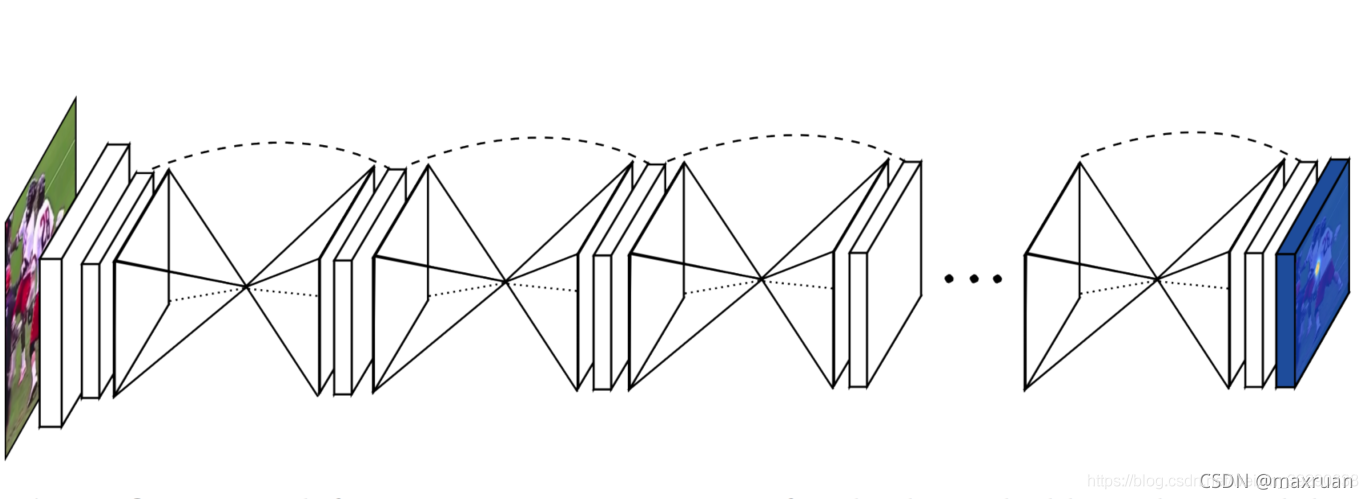
CornerNet的结构如上图所示,使用hourglass网络作为主干网络,通过独立的两个预测模块输出两组结果,分别对应左上角点和右下角点,每个预测模块通过corner池化输出用于最终预测的热图、embedding向量和偏移。
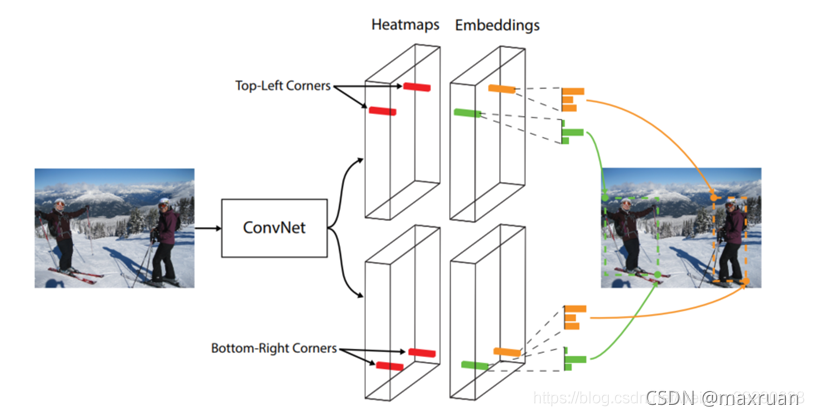
Heatmaps预测哪些点最有可能是Corners点,Embeddings用于表征属于相同对象的corner的相似度。它们的通道数都为C,C是object的类别数 (不包括background) 。最后的Offsets用于对corner的位置进行修正。
hourglass 结构:
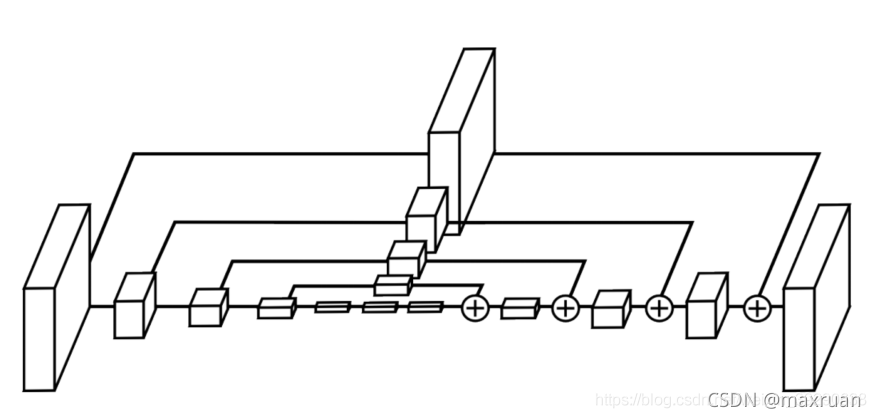
Hourglass先由卷积和池化将feature maps下采样到一个很小的尺度,之后再用nearest neighbor upsampling的方法进行上采样,将feature maps还原到最开始的尺度。不难看出,下采样和上采样是对称的,并且在每个upsampling层都有一个skip connection,skip connection上是一个residual modules。
使用这种沙漏结构的目的是为了反复获取不同尺度下图片所包含的信息。例如一些局部信息,包括脸部和手部信息。沙漏结构可以获取局部信息和全局信息。
1)、Hourglass在下采样时不再进行max-pooling,而是在卷积时通过stride=2进行下采样。
2)、 在每个skip connection,有两个residual modules。
3)、图片进入Hourglass前,进行了2次下采样。
CornerNet 主干网络由多个hourglass组成。
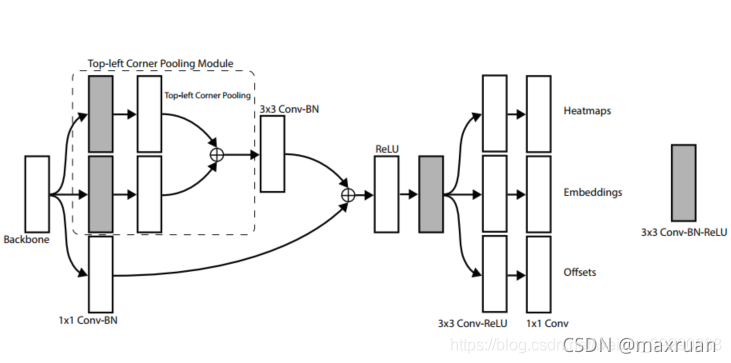
上面两条支路经过33的卷积后,进行corner pooling,相加汇集成1路,随后再进行3x3的卷积和batch normalization;最下面的支路进行11的卷积和batch normalization 后,与上路相加后送入到Relu函数中。随后,再对feature maps进行33的卷积,接着分三路33的卷积+Relu后产生了Heatmaps, Embeddings, Offsets三组feature maps。
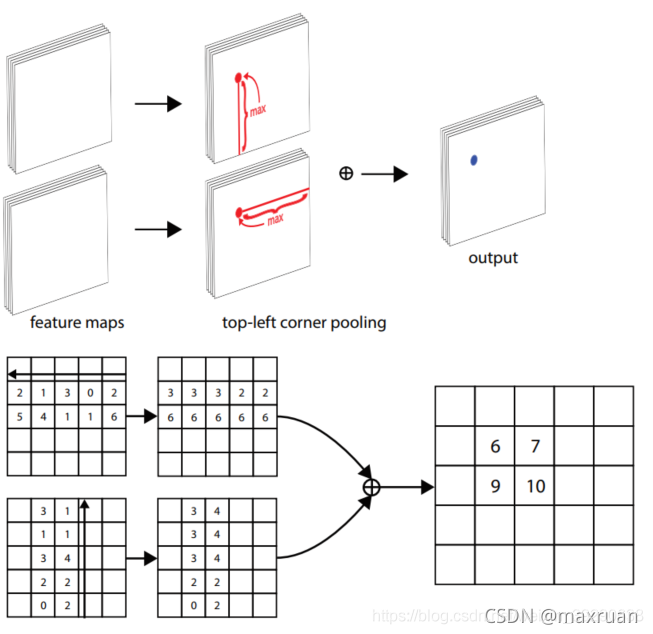
corner-pooling 希望把最大响应的点移动到角点上。上图中的coner pooling值是这么计算的:在横向上,从左到右来看(位置从0到n),位置0的结果为位置0到n的最大值,同理位置1的结果为位置1到n中的最大值
corner pooling的动机其实为了更好地适应corner的检测。在目标检测的任务中,object的corner往往在object之外,所以corner的检测不能根据局部的特征,而是应该对该点所在行的所有特征与列的所有特征进行扫描
有一点值得注意的是,池化时不能直接对整行或整列进行max pooling,当一张图上有多个目标时,这样会导致误检。
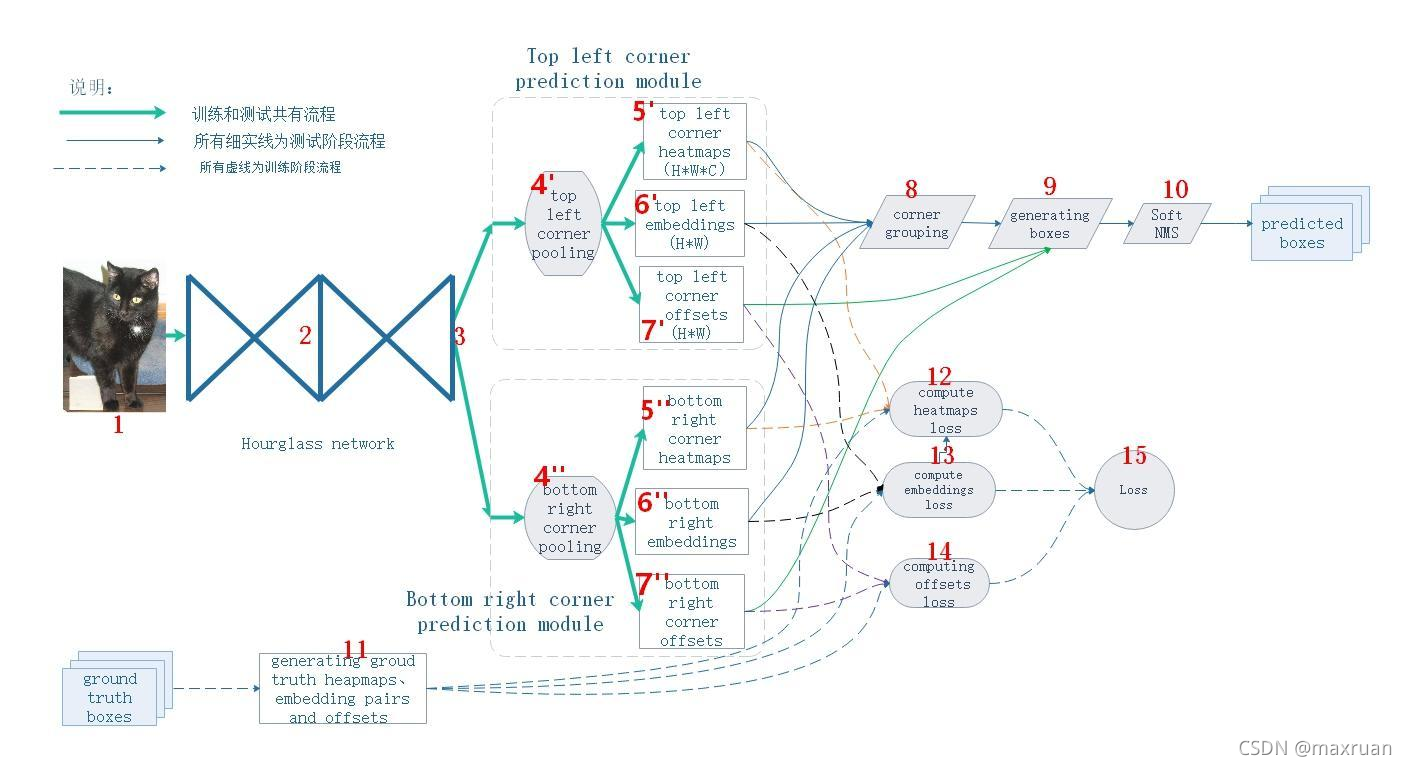
cornerNet 输出3条分支,每条分支对应一个loss。
1、headmap, 角点预测位置。
分母为所有gt boxes数,(在feature map所有点上使用,不只在ground truth点处使用)
pcij 表示第c 个通道的(i,j)位置的值。ycij 表示对应的ground truth。N表示目标数量。ycij 等于其他目标值说说明(i,j)不是类别c的目标角点。 但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。
每个通道上的ground truth是一个binary mask,表明当前位置上是否有左上角点。显然,这种情况下在每个类别的特征图上同样会有大量的像素点是负样本,但是即使把左上角点或者右下角点预测在正确角点的一定范围内,同样可以产生非常接近ground truth boxes的包围框,故而ground truth中并不是简单的0/1编码,而是对于在ground truth点周围的一定半径范围内,会产生以正确角点为中心的二维高斯分布,距离正确角点越近 ,则ground truth label越大,否则越小(但并不会完全等于0)
为什么要对不同负样本点的损失函数采取不同权重值?
这是因为headmap 带有一定的位置回归色彩,有些角点虽然没有落在ycij=1的位置上,但由角点生成的框基本正确地预测了位置,因此是有用的预测框。如此要么设为ignore ,要么为给定一定权重的正样本。我认为设为给定权重的正样本,可以使得样本更加均衡。
ycij 成高斯分布,使得在正样本和负样本之间形成一个过度区域。
ycij 计算方式:
以真实的角点为中心为1,往边上辐射值逐渐变小。但是怎么变化呢?也就是在这里高斯分布怎么变化呢?圆圈内的点的数值是以圆心往外呈二维的高斯分布exp(-(x2+y2)/2σ^2),σ=1/3设置的这里x,y为以真实坐标为原点新建坐标系。
2、offset
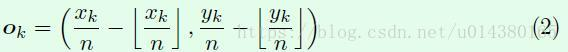
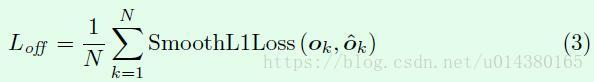
首先明确offset的ground truth值是什么?这是因为为了减少计算复杂度,预测出的heatmap的特征图分辨率大多数情况下是小于输入图像的分辨率(相当于对输入图像进行下采样),而为原本的ground truth boxes便焦点编码到heatmap上的位置必须是整数点(通常是原始分辨率上的gt boxes坐标除以下采样倍数,再向下取整),故而编码后的位置坐标再映射回原来的输入图像,会不够准确,这时就会引入偏移量,故offset的ground truth 编码也是与heat map具有相同分辨率和相同通道数的
3、embedding,一对一关联。如何找到一个目标的两个角点。
pull loss:让属于同一个ground truth boxes的两个角点处的embedding vector距离越近越好(方差越小越好),pull loss最小值为0
push loss:计算出所有ground truth boxes对应两个角点处的embedding vector,并求出每个gt boxes的平均向量 e_k,k=1,2,...N
让不属于同一个gt boxes的e_k间距越大越好。push loss最小值为0
基于不同角点的embedding vector之间的距离找到每个目标的一对角点,如果一个左上角角点和一个右下角角点属于同一个目标,那么二者的embedding vector之间的距离应该很小。

最终,总的损失为 :
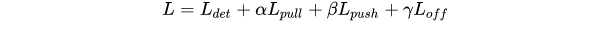
作者在实验中设置各loss权重参数分别为0.1,0.1,1.
预测部分(1)在heatmap层后接3*3的max pooling层进行非极大值抑制(NMS)。
(2)取top 100的top-left和bottom-right corner。
(3) corner位置根据offset调整。
(4) embedding L1距离,距离大于0.5或非同类别被剔除。
(5) top-left和bottom-right corner的平均score作为检测的score。
(6) 输入图不resize,保持原始分辨率,pad it with 0
(7)原始图像和fliped图像均测试,结合两个的结果,通过soft-nms抑制冗余检测,最多检测100个目标。
(8)平均测试速度单张图片244ms, Titan X (PASCAL) GPU。
瓶颈:detecting corner
heatmap:漏检corner,则检测不出box。
embeding:匹配错corner则box错。
offset:tight box。
https://blog.csdn.net/long630576366/article/details/120279525
https://blog.csdn.net/WYXHAHAHA123/article/details/88423948