一、服务器环境
1.四台服务器(最低标准1核2g)
hadoop01 172.16.192.132
hadoop02 172.16.192.133
hadoop03 172.16.192.134
hadoop04 172.16.192.135
2.四台全部修改主机名
hostnamectl set-hostname hadoop01hostnamectl set-hostname hadoop02
hostnamectl set-hostname hadoop03
hostnamectl set-hostname hadoop04
3. 四台主机全部关闭防火墙
内核、外核全部关闭
具体操作比较基础就不写命令了
4. 重启系统
reboot5.编辑/etc/hosts分别给四台主机名映射
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.192.132 hadoop01
172.16.192.133 hadoop02
172.16.192.134 hadoop03
172.16.192.135 hadoop04
6.把所需的安装包导入
上传所需安装包到/opt/目录下
这里导入用rz命令或者xftp都可以

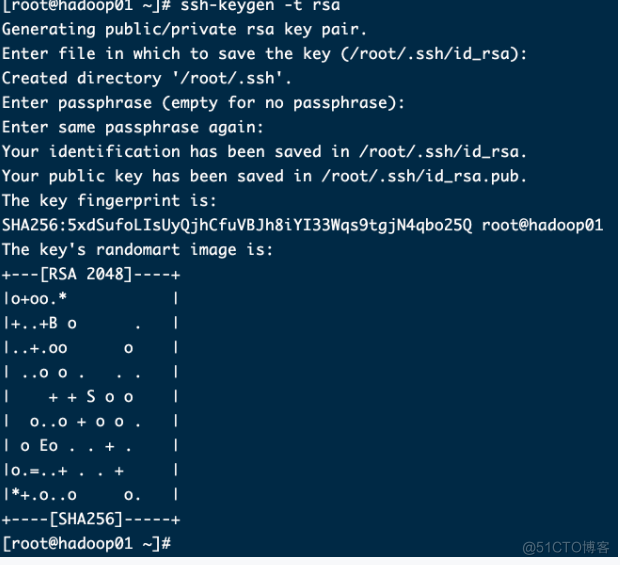
7. 在/root/创建密钥对并拷贝到其他主机 !!这里开始建议四台机器同步操作命令!
ssh-keygen -t rsa(四台机器都输入,这里会跳出来选择确认,三次全部回车即可,见下图)
8、输入
ssh-copy-id hadoop01(这里输入yes,然后输入passwd即可)ssh-copy-id hadoop02(这里输入yes,然后输入passwd即可)
ssh-copy-id hadoop03(这里输入yes,然后输入passwd即可)
ssh-copy-id hadoop04(这里输入yes,然后输入passwd即可)
注意:第8步骤只用操作hadoop01、hadoop02、hadoop03
hadoop04不用操作!
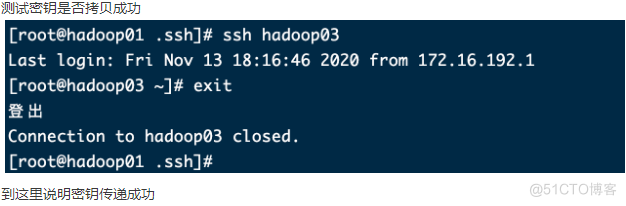
9,测试密钥是否测试成功
二、集群环境
1.在root目录创建bin目录存放脚本
mkdir bincd bin
2.编辑脚本
创建:
touch xrsyncvim xrsync#!/bin/bash
#虚拟机之间传递文件
#1 获取输入参数个数,如果参数个数没有,退出
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2 获取文件名
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录的绝对路径
pdir=`cd -P $(dirname $p1);pwd`
echo pdir=$pdir
#4 获取当前用户名字
user=`whoami`
#5 将文件拷贝到目标机器
for host in hadoop01 hadoop02 hadoop03 hadoop04
do
echo ------------- $host ---------------
rsync -av $pdir/$fname $user@$host:$pdir
done
创建:
touch showjps.shvim showjps.sh#!/bin/bash
#在一台机器上查看所有机器进程
for host in hadoop01 hadoop02 hadoop03 hadoop04
do
echo ----------$host-------------
ssh $host "$*"
done
创建:
touch zkop.sh#!/bin/bash
#关于zookeeper的启动、关闭、状态
···· start stop status
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03 hadoop04
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03 hadoop04
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop01 hadoop02 hadoop03 hadoop04
do
ssh $i "/opt/bigdata/zk345/bin/zkServer.sh status"
done
};;
esac
创建:
touch kakop.shvim kakop.sh#!/bin/bash
#关于kafka的启动关闭脚本
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03 hadoop04
do
echo ------------$i 启动KAFKA-----------------
ssh $i "/opt/bigdata/kafka211/bin/kafka-server-start.sh -daemon /opt/bigdata/kafka211/config/server.properties"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03 hadoop04
do
echo ------------$i 关闭KAFKA-----------------
ssh $i "/opt/bigdata/kafka211/bin/kafka-server-stop.sh"
done
};;
esac
3.给4个脚本777权限
[root@hadoop01 bin]# chmod 777 xrsync[root@hadoop01 bin]# chmod 777 showjps.sh
[root@hadoop01 bin]# chmod 777 zkop.sh
[root@hadoop01 bin]# chmod 777 kakop.sh或者chmod -R 777 /bin/
4.在/opt/目录下创建目录bigdata并解压jdk包到bigdata
mkdir -p /opt/bigdatacd /opt/install
[root@hadoop01 install]# tar xvf jdk-8u131-linux-x64.tar.gz -C /opt/bigdata
[root@hadoop01 bigdata]# mv jdk1.8.0_131/ jdk180
5.配置jdk环境变量
[root@hadoop01 bin]# cd /etc/profile.d/[root@hadoop01 profile.d]# vim env.shexport JAVA_HOME=/opt/bigdata/jdk180
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH[root@hadoop01 profile.d]# source ./env.sh
6.安装rsync -y(4台同操作) 如果用CRT、Xshell同时控制同步操作可以忽视此步骤
yum install rsync -y7.从hadoop01网其他三台虚拟机传jdk及环境变量文件
[root@hadoop01 bin]# xrsync /opt/bigdata/jdk180[root@hadoop01 bin]# xrsync /etc/profile.d/env.sh
同时在其他三台操作:
source /etc/profile.d/env.sh验证是否安装成功
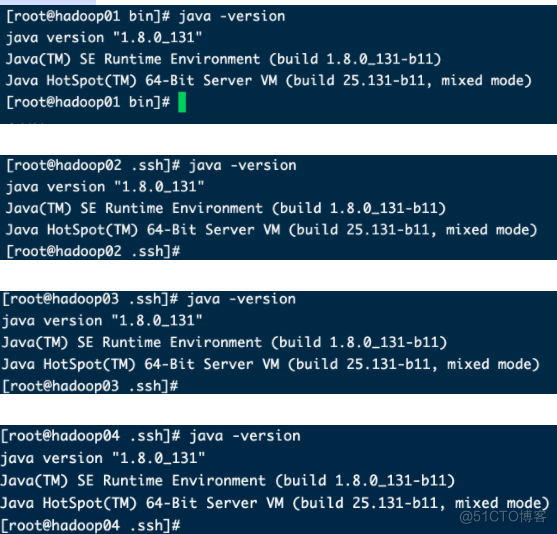
出现如图这样,Java配置成功
8. 解压hadoop包
cd /opt/install[root@hadoop01 install]# tar -xvf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/bigdata
[root@hadoop01 bigdata]# mv hadoop-2.6.0-cdh5.14.2/ hadoop260
9、进入/opt/bigdata/hadoop260/etc/hadoop 目录
vim hadoop-env.sh在最下面添加
export JAVA_HOME=/opt/bigdata/jdk180/vim mapred-env.shexport JAVA_HOME=/opt/bigdata/jdk180/
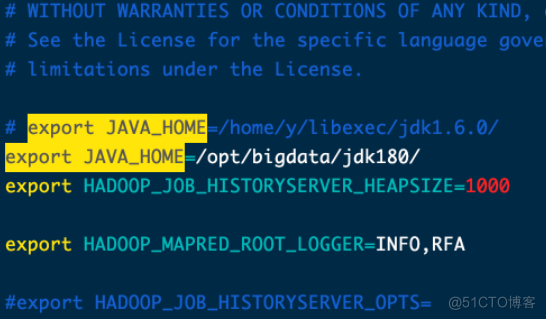
export JAVA_HOME=/opt/bigdata/jdk180/
hadoop01
hadoop02
hadoop03
hadoop04
10,在hadoop260目录下建hadoop2目录
mkdir /opt/bigdata/hadoop260/hadoop211,vim core-site.xml
<configuration><property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop260/hadoop2</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
12,vim hdfs-site.xml
<configuration><property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
</configuration>
13,vim mapred-site.xml
<configuration><property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
14,vim yarn-site.xml
<configuration><!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>pass2</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
15,添加hadoop环境变量
vim /etc/profile.d/env.shexport HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin[root@hadoop01 profile.d]# source /etc/profile.d/env.sh
16,往其他三个虚拟机传配置
[root@hadoop01 hadoop]# xrsync /etc/profile.d/env.sh[root@hadoop01 bigdata]# xrsync hadoop260/
17,启动hadoop(此本步骤在01机器执行)
[root@hadoop01 hadoop260]# hadoop namenode -format[root@hadoop01 hadoop260]# start-dfs.sh
[root@hadoop01 hadoop260]# start-yarn.sh
[root@hadoop01 bin]# showjps.sh jps
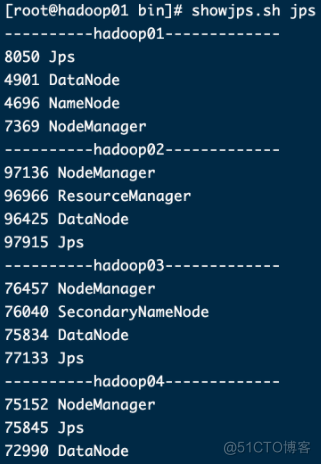
出现这样代表所有的节点启动成功了
三、zookeeper安装
1.解压zookeeper安装包
进入/opt/install目录
[root@hadoop01 ~]#cd /opt/install[root@hadoop01 install]# tar -xvf zookeeper-3.4.5-cdh5.14.2.tar.gz -C /opt/bigdata/
[root@hadoop01 install]# cd /opt/bigdata/
[root@hadoop01 bigdata]# mv zookeeper-3.4.5-cdh5.14.2/ zk345
2.创建myid
[root@hadoop01 bigdata]# cd zk345/[root@hadoop01 zk345]# mkdir zkData
[root@hadoop01 zk345]# cd ./zkData/[root@hadoop01 zkData]# vim myid
1
只输入1保存退出
3.修改配置文件
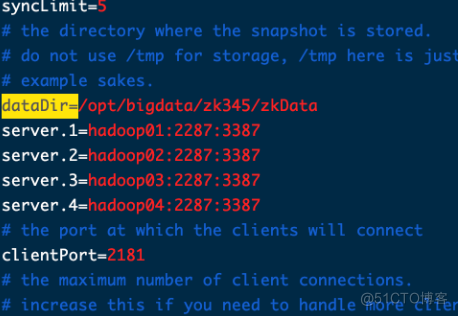
[root@hadoop01 zk345]# cd conf/[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg[root@hadoop01 conf]# vim zoo.cfg
dataDir=/opt/bigdata/zk345/zkData
server.1=hadoop01:2287:3387
server.2=hadoop02:2287:3387
server.3=hadoop03:2287:3387
server.4=hadoop04:2287:3387
4.将zookeeper发送到其他三台机器上,分别配置/opt/bigdata/zk345/zkData下的myid依次为1234
[root@hadoop01 bigdata]# cd /opt/bigdata/[root@hadoop01 bigdata]# xrsync zk345/
在其他三台修改mydi
vim /opt/bigdata/zk345/zkData/myid将其他三台内容里的1修改
比如hadoop01 此文件是1
hadoop02内容改成2
hadoop03内容改成3
hadoop04内容改成4
保存退出
5.配置zookeeper环境变量
[root@hadoop01 bigdata]# vim /etc/profile.d/env.shexport ZOOKEEPER_HOME=/opt/bigdata/zk345
export PATH=$PATH:$ZOOKEEPER_HOME/bin[root@hadoop01 bigdata]# xrsync /etc/profile.d/env.sh
[root@hadoop01 bigdata]# cd /opt/bigdata/
6.启动zookeeper
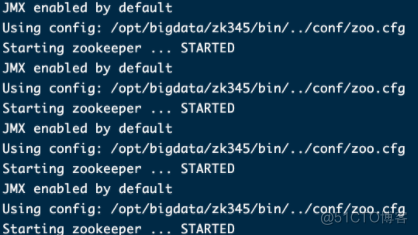
[root@hadoop01 bin]# cd /root/bin/[root@hadoop01 bin]# zkop.sh start
执行后效果图
四、kafka安装
1.解压安装包 进入opt目录的install目录下
[root@hadoop01 install]# tar -xvf kafka_2.11-2.1.1.tgz -C /opt/bigdata/[root@hadoop01 install]# cd /opt/bigdata/
[root@hadoop01 bigdata]# mv kafka_2.11-2.1.1/ kafka211
2.创建日志目录
[root@hadoop01 bigdata]# cd kafka211/[root@hadoop01 kafka211]# mkdir logs
[root@hadoop01 kafka211]# cd logs/[root@hadoop01 logs]# pwd
/opt/bigdata/kafka211/logs
3.修改配置文件
[root@hadoop01 logs]# cd ../config/[root@hadoop01 config]# vim server.propertiesbroker.id=1
log.dirs=/opt/bigdata/kafka211/logs
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181
[root@hadoop01 bigdata]# xrsync kafka211/
broker.id=1(在其他机器上分别设置broker.id按顺序依次对应改为2、3、4)
4.配置Kafka环境变量
[root@hadoop01 bigdata]# vim /etc/profile.d/env.shexport KAFAKA_HOME=/opt/bigdata/kafka211
export PATH=$PATH:$KAFAKA_HOME/bin[root@hadoop01 bigdata]# xrsync /etc/profile.d/env.sh
[root@hadoop01 bigdata]# source /etc/profile.d/env.sh
5.启动Kafka
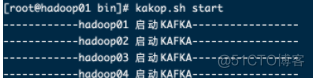
[root@hadoop01 bigdata]# cd /root/bin/[root@hadoop01 bin]# kakop.sh start
集体启动效果如图
单台启动方法(需要进入/opt/bigdata/kafka211/bin执行)
cd /opt/bigdata/kafka211/bin./kafka-server-start.sh -daemon ../config/server.properties
6、运行查看showjps.sh jps
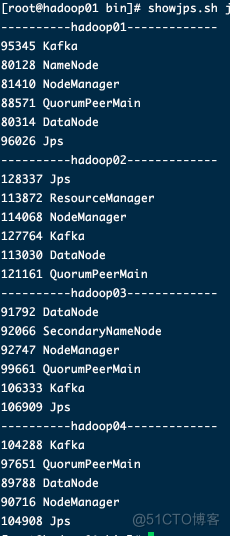
到这里集群搭建完毕
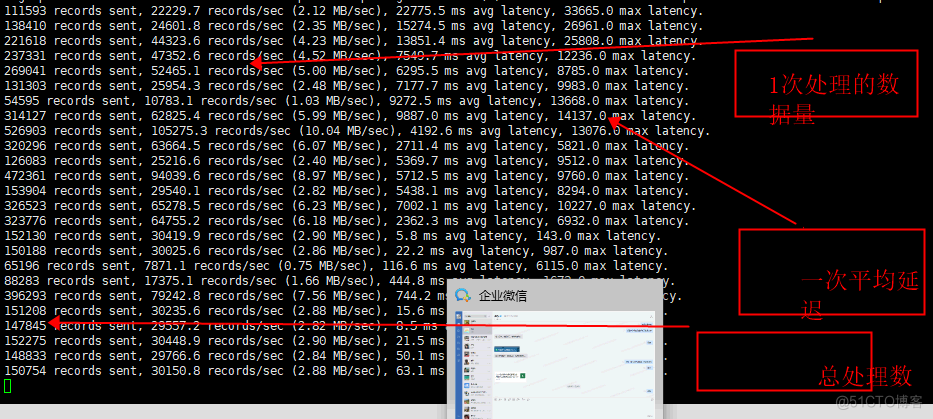
测试Kafka消费
[root@hadoop01 bin]# kafka-topics.sh --create --topic test --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181 --partitions 4 --replication-factor 4会显示结果:Created topic "test".
[root@hadoop01 bin]# kafka-topics.sh --describe --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181 --topic testTopic:test PartitionCount:4 ReplicationFactor:4 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2,3,4 Isr: 1,2,3,4
Topic: test Partition: 1 Leader: 2 Replicas: 2,3,4,1 Isr: 2,3,4,1
Topic: test Partition: 2 Leader: 3 Replicas: 3,4,1,2 Isr: 3,4,1,2
Topic: test Partition: 3 Leader: 4 Replicas: 4,1,2,3 Isr: 4,1,2,3
./kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=192.168.11.145:9092,192.168.11.146:9092,192.168.11.147:9092