Serial:单线程收集器、在进行垃圾收集的时候需要暂停其他线程。优点:简单高效。适用于新生代。复制算法
SerialOld:是Serial收集器的l老年代版本,,也是一个单线程收集器,不同的是采用标记-整理算法。也会去暂停其他线程。标记整理算法
ParNew:Serial收集器的多线程版本,也就是多线程收集,还是会暂停其他线程,但是时间短了。复制算法(以上三种为什么要暂停,为了保证该回收会被回收)
Parall Scanvenge:是一个新生代收集器,使用的复制算法,而且是并行多线程收集器。更关注系统的吞吐量(吞吐量=运行用户代码时间/(运行用户代码的时间+垃圾收集时间))。吞吐量越大,垃圾收集时间越短。(可以直接设置吞吐量大小,可以设置最大的垃圾收集停顿时间)
Parall Old:Parall Scanvenge收集器的老年代版本,使用多线程和标记整理进行垃圾回收。
CMS:以获取最短回收停顿时间为目标的收集器,采用的是标记清除
并发类收集器和并行类收集器:垃圾收集线程与我们的业务一起跑的收集器称为并发类垃圾收集器,多线程全跑的收集器称为并行类收集器。
标记 清除:标记非常耗时:先找到GCroot(这一步不是很耗时) 找到与之直接关联的引用链对象并标记
1、初始标记:找到所有与GCRoot以及与之直接相关联的对象。这一步不是很耗时所以可以打断其他线程再去标记(引用链上对象先不找,因为我不知道这条引用链有多长,可能会非常耗时)。注意这一步默认使用的是多线程(调优点:如果你在业务代码中没有什么多线程代码可以将这个设置为单线程,减少了线程创建的开销,提升性能)
2、并发标记:可以将引用链上的对象放在这里去找,虽然耗时但是我们是并发执行,不影响用户。但是在我进行并发标记时间我们的对象可能会引用关系发生变化。我们需要将发生变化的进行标记。
3、重新标记:对引用关系发生变化的进行重新标记,需要暂停其他线程,不是很耗时。
4、并发清除:会导致一部分垃圾产生,只能留给下次清除
所以他是以最短回收时间为目的。耗时的就并发执行,不耗时就暂停其他线程执行。缺点:会产生大量空间碎片,因为它使用的是标记清除算法。
这个是它常规的过程,所有的并发收集器都会有一个异常收集过程:并发失败,就比如并发标记的时候产生的垃圾太多了超过堆空间,就会强制进入并发失败模式,会直接暂停所有线程并且切换到Serial去清除。
G1: 降低停顿时间,可以设置这个停顿时间(思路:我不一定要把垃圾收集干净,只要对象还能放进来,我就可以先不收集。会优先去收集价值比较高的垃圾)。可以变相解决空间碎片
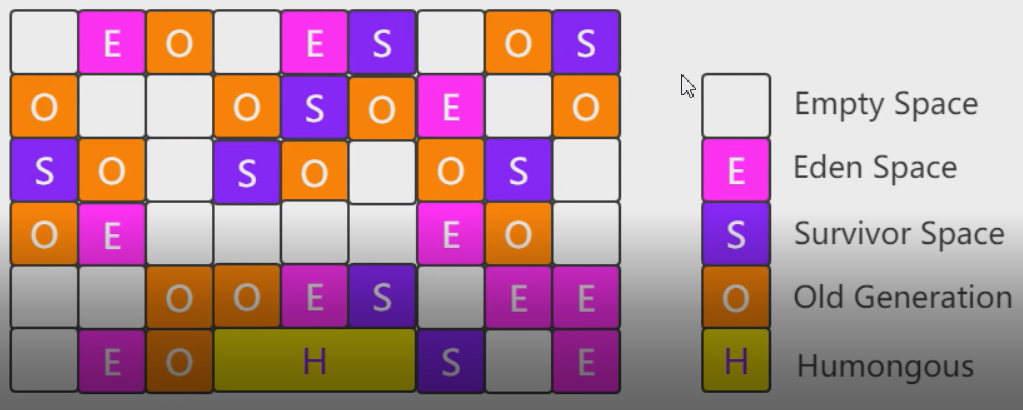
使用G1收集器时,java堆的内存布局与其他收集器有很大区别,他将整个java堆划分为了多个大小相等的独立区域,虽然还保留新生代和老年代的概念,但是他们之间不再有物理隔离,他们都是一部分独立区域的集合。每个独立区域大小相等在1-32M之间,但是必须保证是2的N次幂。如果对象太大会放入H中。独立区域的大小可以设置。
1、初始标记:找到所有与GCRoot以及与之直接相关联的对象。这一步不是很耗时所以可以打断其他线程再去标记(引用链上对象先不找,因为我不知道这条引用链有多长,可能会非常耗时)。注意这一步默认使用的是多线程(调优点:如果你在业务代码中没有什么多线程代码可以将这个设置为单线程,减少了线程创建的开销,提升性能)
2、并发标记:可以将引用链上的对象放在这里去找,虽然耗时但是我们是并发执行,不影响用户。但是在我进行并发标记时间我们的对象可能会引用关系发生变化。我们需要将发生变化的进行标记。
3、重新标记:对引用关系发生变化的进行重新标记,需要暂停其他线程,不是很耗时。
4、筛选回收:对各个独立的回收价值和成本进行排序,根据用户期望根据用户期望的停顿时间制定回收计划。
如何选择合适的垃圾回收器
-
优先调整堆的大小让服务器自己来选择
-
如果内存小于100M,使用串行收集器
-
-
如果允许停顿时间超过1秒,选择并行或JVM自己选