Summary: leaderboard 现存第一名 TCP,非常simple的设置 取得了很好的效果
论文链接:Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline
代码链接:https://github.com/OpenPerceptionX/TCP 作者回复预计9月开
jg刷到的时候 我旁边看了一眼 这些框架图为什么这么熟… 后面仔细看才发现喔 吸取各家之长处了 简单传感器的高分 真绝啊
1. Motivation对于端到端的驾驶任务,一般是从预测出轨迹,然后用控制器跟随;另一种则是直接预测controller输出;由两种方法启发,作者时候:可以吸取各自优点,然后提出本文方法
Contribution- 调研尝试了两种方法,然后提出了结合的pipeline
- multi-step control 预测使得 temporal reasoning
- CARLA排行榜第一名 (排名榜查看时间June 25, 2022 )
专家使用的是Roach 【用RL训练出的一种专家策略】,这里 小声提一句 我收集了一下现有开源的专家【Roach, SEED, AUTO, MMFN】,然后给了一个repo carla-expert 来给大家做收集用… 感兴趣可以去点个star;如果后面你想做这个任务 肯定是可以用上的,毕竟第一次做任务的时候 我一个月都在搞数据那一环
原来e2e也可以写公式 涨见识,大概就是学到的策略和专家数据的loss 在整个数据集\(\mathrm{D}=\{(x,a^*)\}\)下 取最小的
\[\arg \min _{\theta} \mathbb{E}_{\left(\mathrm{x}, \mathbf{a}^{*}\right) \sim \mathrm{D}}\left[\mathcal{L}\left(\mathbf{a}^{*}, \pi_{\theta}(\mathbf{x})\right)\right] \tag{1} \]2.1 框架- 整体前面encoder框架 可以对比着CILRS
- Loss设计可以看看Roach一文
输入:一帧图片;当前帧的速度,high command,目标点等
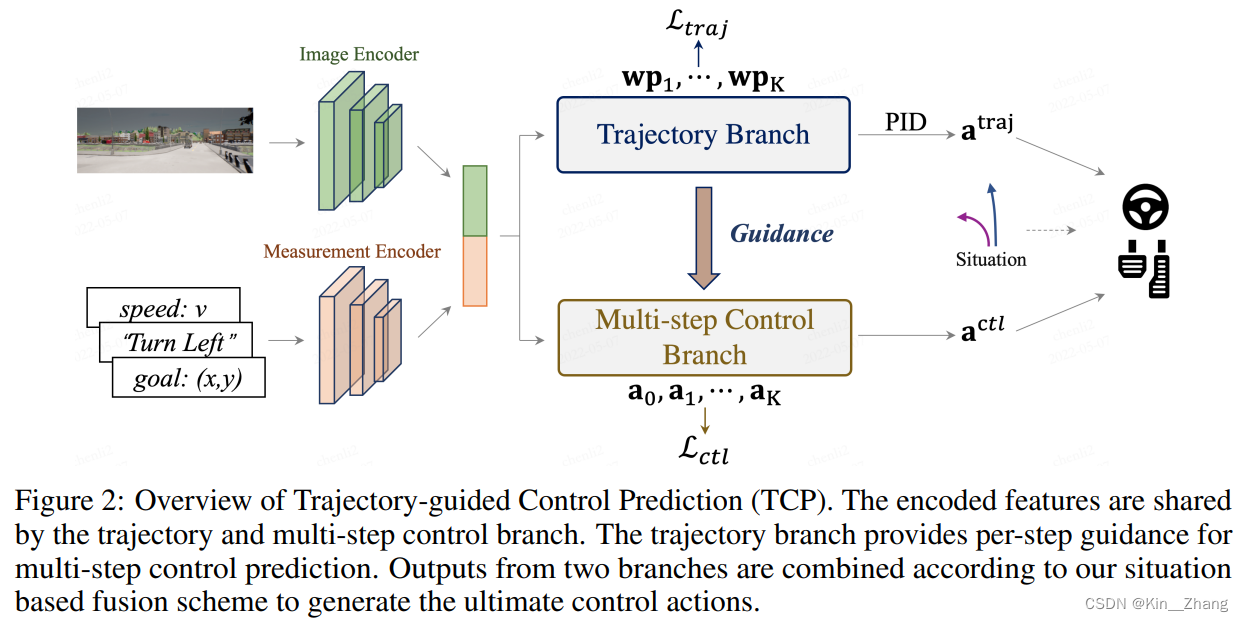
网络细节,在附录和正文里有简洁的说明:
- 相机尺寸是900x256,FOV直接拉满为100
- K = 4 也就是选未来四步steps 的动作/轨迹进入
- Image Encoder 使用的是有预训练的 ResNet-34
- measurement encoder则是一个MLP [全文并未仔细说明具体几层;暂且认为和CILRS一致设置 也就是 根据输入的num 对应相应数量的linear到encoder里] → 128
- 各自encoder的输出 concat到一起 组成 \(\bf{j}^{traj}\) → 256
接下来 两个branch都直接取共同输出的feature进入各自的分支
-
见loss 部分, 各自loss 相加,直接.backward()
和[16]一样将 \(\bf{j}^{traj}\) 送到GRU里,应该是和transfuser的操作一样,大概是下图这个感觉:
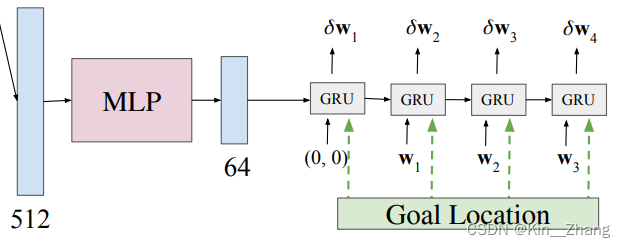
摘自 transfuser 一文
其中 因为有 experts的真值 (x,y) 轨迹点作为参考,所以可以算loss
注意看整体框架图,其中得到这些轨迹点后,使用的是两个横纵向PID进行轨迹到控制量的传递,不同于之前的方法,这里的PID控的是横纵向error,大部分以前方法基本都是一个速度控制(给定一个速度),一个转向控制为主
2.3 Multi-Step Control Branch这里提出了一个比较重要的点:之前这种 基于当前的输入 预测下一个输出,整体输出都是独立同分布假设。但实际上 当前输入与历史输入,和未来输出之间并不是独立的。 对比与用MDP(马尔科夫决策过程)和RL进行回溯/往前,提出了一种更为简单的方式
首先单看主框架图里对应的淡黄色模块,
temporal module输入是 \(\mathbf{j}_{\mathrm{t}}^{\text {ctl }}\) 和 \(\mathbf a_t^{ctl}\) concat后的,其中:
\[\mathbf{j}_{\mathrm{t}}^{\text {ctl }}=\operatorname{MLP}\left(\text { Concat }\left[\operatorname{Sum}\left(\operatorname{Softmax}\left(\mathbf{w}_{\mathrm{t}}\right) \odot \mathbf{F}\right), \mathbf{h}_{\mathrm{t}}^{\text {ctl }}\right]\right) \]其中\(\bf w_t\)是由t时刻的 hidden state concat在一起的,如下图公式:
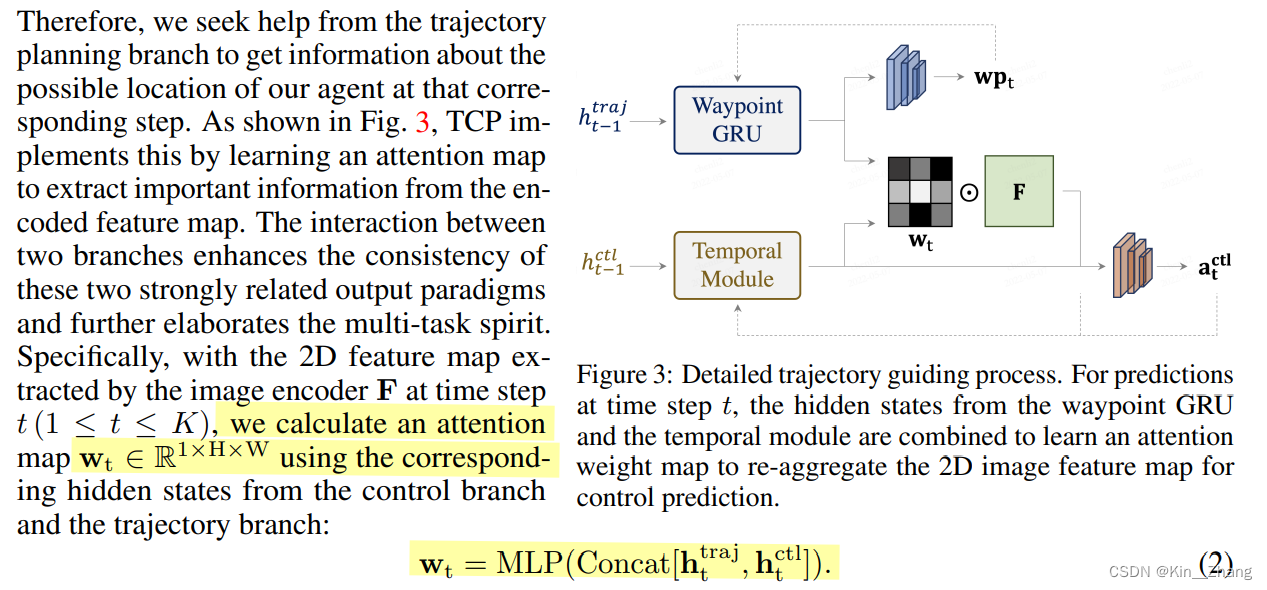
而\(\mathbf h_t^{traj}, \mathbf h_t^{ctl}\)是从各自的Trajectory Branch和Control Branch而来
问题区:
-
图三中两个模块都是GRU实现的,hidden state从每个GRU里得到
-
是的
-
是MLP hidden state都是各自GRU里来的,图三中输出前的两个均为MLP
主要为三种,轨迹、控制和附加loss
对于轨迹:

其中与transfuser不同的是加入了feature的loss进来,j是128维度的
对于控制:

对于附加,从image feature 加了速度预测head L1 loss 和一个value predict 预测expected return 同[55]一样,L2 Loss
然后三个loss 相加:
\[\mathcal{L}=\lambda_{t r a j} \cdot \mathcal{L}_{t r a j}+\lambda_{c t l} \cdot \mathcal{L}_{c t l}+\lambda_{a u x} \cdot \mathcal{L}_{a u x} \]问题区:
-
roach 做法,由BEV下的gt 做的不同的输入,但是不知道是直接收集的expert的feature还是说用BEV输入到这个网络做的loss
融合的方法也挺工程的,直接判断 过去1s内的steer 绝对值相加 是否超过0.1,如果超过则认为你正在执行转弯,就切换到 以轨迹分支为主;否则以多步控制分支为主

实验和结果 个人觉得作者有点省事了… 因为直接抽的leaderboard,但是!CARLA排行榜不同于其他的地方是:数据集是你自己创建的,一般情况下,大家都会多多少少去用自己的数据集训练出来其他方法的agent 在同一个expert training下的对比… 【大概意思呢就是:实验条件并不一致,虽然从线上来说你是好的 但是可能其他人只用了你1/2的数据…】
不过 这并不能说明方法不有效,毕竟 这可是一个相机能干到的分数啊,我深表佩服!以下仅仅是截图一下各个实验表格和可视化的,因为太熟悉这个任务了 就不再说明了,感兴趣 想尝试一下榜的可以看看 相关CARLA leaderbaord配置教学文章 其中包含了指标说明
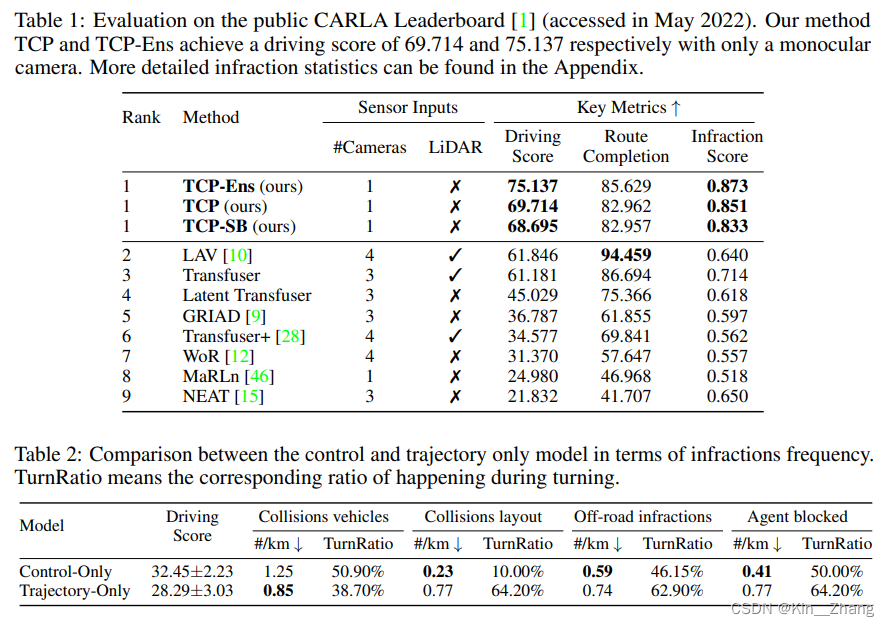
一些在自己方法下 控制变量的 消融实验
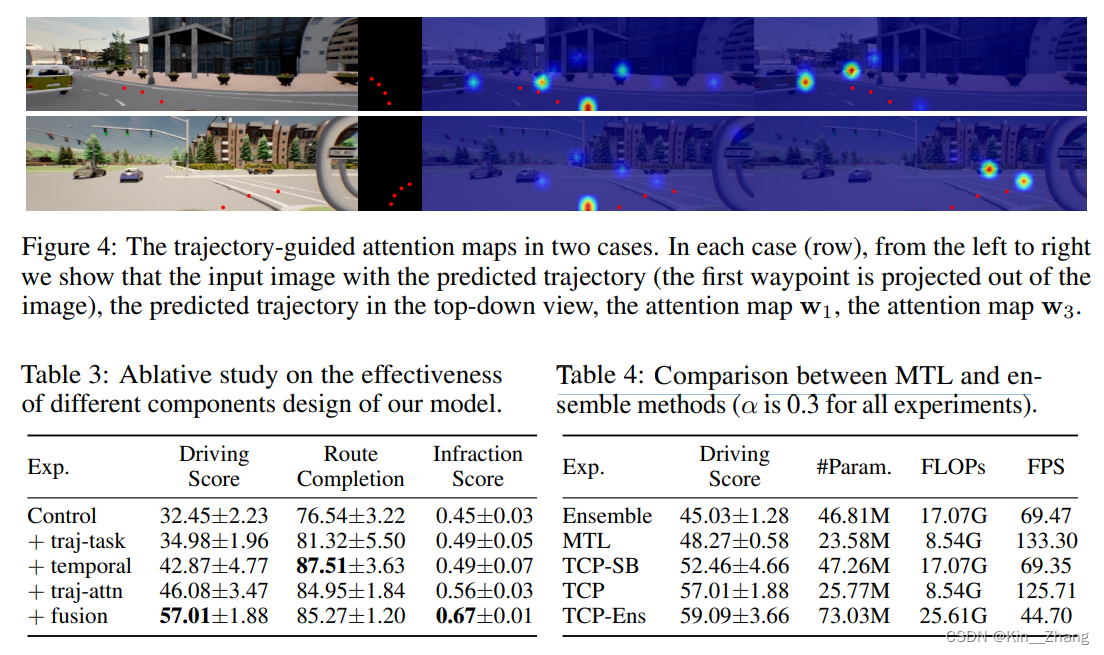
此部分碎碎念 有些在前面实验中念完了 hhhh 来自jg的碎碎念:对CARLA leaderboard的完全过拟合 hhhh 毕竟这种方法是真的不会在车上尝试的吧… LAV的方法至少有条件是可以在实车上测一波,从可解释性上会强很多 比如 找原因啥的,但是LAV真的太太太大了,这个方法 第一次成绩匿名的时候 我觉得不可能.. 还自己quick setting了一波一个相机的实验 但是效果并不好 (当时TCP文章还没挂出来哈)… 所以后面看看有没有机会 看文章简单复现一下
PS 现在大家的数据集 真是一个比一个高,自己当时做的时候 100K帧数据都不到… LAV 390K,TCP 420K,现在想来 好像知道自己分数为啥差距这么大了 也是一个到后面有点玩不懂的任务,不过planning也就这一个任务… 榜单可以刷刷
赠人点赞 手有余香