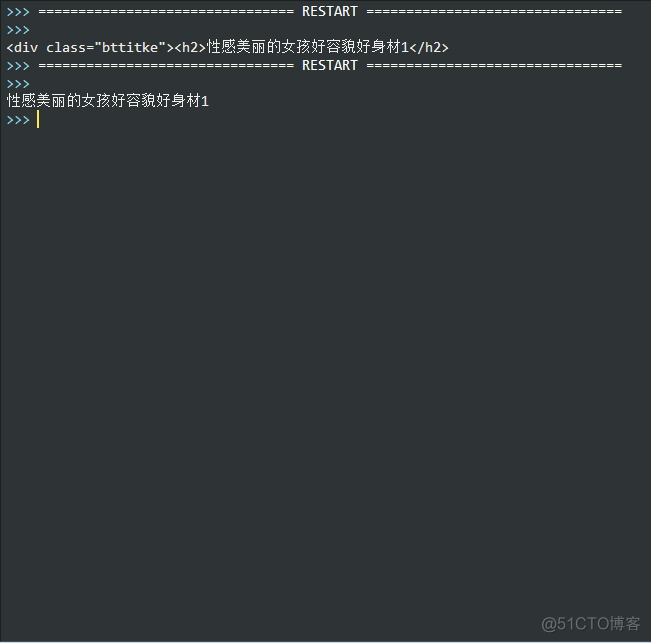
今天写爬虫,爬取MM图片页面的标题时,遇到了一个问题,上图: 看看我的代码: 1 import urllib 2 import urllib2 3 import re 4 5 class JPMSG: 6 7 def __init__(self, baseUrl): 8 self.baseUrl = baseUrl 9 10 def ge
今天写爬虫,爬取MM图片页面的标题时,遇到了一个问题,上图:
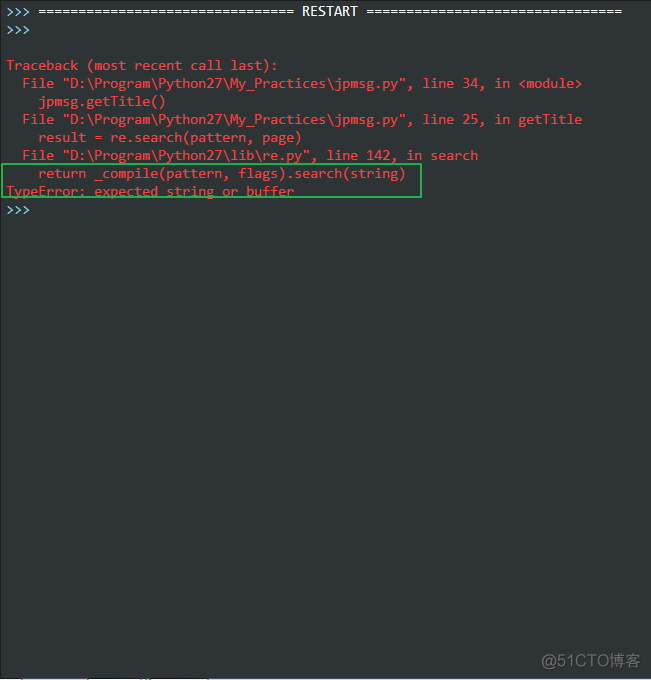
看看我的代码:
1 import urllib2 import urllib2
3 import re
4
5 class JPMSG:
6
7 def __init__(self, baseUrl):
8 self.baseUrl = baseUrl
9
10 def getPage(self, viewNum):
11 try:
12 url = self.baseUrl + str(viewNum) + '.html'
13 request = urllib2.Request(url)
14 response = urllib2.urlopen(request)
15 #print response
16 return response
17 except urllib2.URLError, e:
18 if hasattr(e, "reason"):
19 print "爬取MM图片失败,失败原因", e.reason
20 return None
21
22 def getTitle(self):
23 page = self.getPage(13235)
24 pattern = re.compile('<div class="bttitke"><h2>(.*?)</h2>', re.S)
25 result = re.search(pattern, page)
26 if result:
27 print result.group(0)
28 return result.group(0).strip()
29 else:
30 return None
哈哈,发现问题了吗?原因是我的返回的response没加read(),应该是return response.read()
好了,一波未平,一波又起。上图:
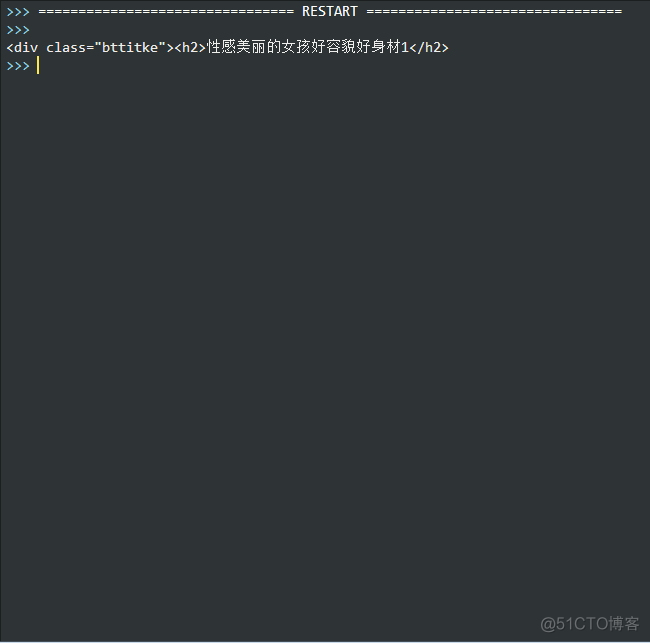
为什么我的正则表达式匹配的标题连标签都匹配下来了,我们要的仅仅是标题啊。
原因就出在print result.group(0)身上,group()的方法,当有多个参数时是以元组形式返回,编号0表示整个匹配的子串,而group(1)才是我们要的第一个也是唯一一个元素。
修改后,我们得到了正确的标题: