- 一、写在前面
- 二、K8S为我们提供了怎样的能力
- 三、架构
- 3.1、MasterNode
- 3.2、WorkerNode
- 四、核心组件
- 4.1、ApiServer
- 4.1.1、概述
- 4.1.2、是集群管理API的统一入口
- 4.1.3、提供了完备的安全认证机制
- 4.1.4、典型使用场景
- 4.1.5、Api Proxy接口
- 4.2、ControllerManager
- 4.2.1、Replication Controller
- 4.2.2、Node Controller
- 4.2.3、ResourceQuota Controller
- 4.2.4、Namespace Controller
- 4.2.5、Service Controller - Endpoint Controller
- 4.3、Scheduler
- 4.4、Kubelet
- 4.4.1、Node管理
- 4.4.2、Pod管理
- 4.4.3、容器健康检查
- 4.5、KubeProxy
- 4.5.1、k8s1.2版本前
- 4.5.2、k8s1.2~1.7版本
- 4.5.3、k8s1.8版本及之后
- 4.1、ApiServer
- 五、网络组件
- 5.1、CoreDNS
- 5.2、CNI网络插件
K8S的文章很多人都写过,若要想好好研读,系统的学习,真推荐去看官方文档。但是若是当上下班路上的爽文,可以看下我的笔记,我也会尽力多写点自己的理解进来。
推荐手机阅读原文,有动态表情图,阅读体验感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
推荐手机阅读原文,有动态表情图,阅读体验感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
推荐手机阅读原文,有动态表情图,阅读体验感更佳:https://mp.weixin.qq.com/s/bL-85BhOj8H5Dis_94lmrQ
大家都知道Docker,我们可以将自己的应用打包制作成Image,然后通过docker run命令将Image启动成Container对外提供服务。
点击查看白日们的Docker网络笔记
点击查看白日梦的视频教程-二十分钟彻底搞懂Docker网络!
基于此,K8S不仅能将用户提供的单个容器运行起来,将其对外暴露出去提供服务。还提供了:路由网关、集群监控、灾难恢复,以及应用的水平扩展等能力。
大家常听过一个词:微服务、云原生应用,如何理解这个词自然也是见仁见智。
如下图是SpringCloud的架构图:
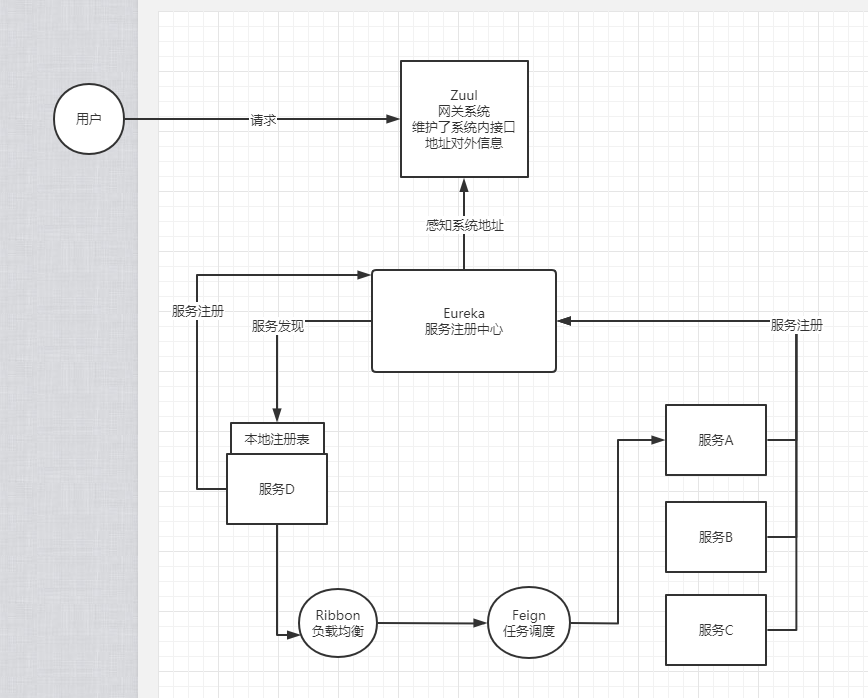
在SpringCloud中有不同的组件,诸如提供服务发现能力的:Eureka、提供负载均衡机制的Ribbon、以及微服务的统一入口Zuul,基于这套框架做过开发的同学都知道,无论是Eureka还是Zuul,无论开发量大小,都需要程序员开发相应的代码,即使这些代码和业务本身并没有什么关系。
而在K8S中,像Eureka的服务发现能力,Zuul的网关能力、以及Ribbon的负载均衡能力,K8S都是原生支持的,开发人员只需要写好自己的业务代码,提供一个可执行的jar包,或者二进制文件即可部署进K8S中就行
当然不仅于此,K8S的服务网格组件如:Istio还提供了流量治理能力,比如按不同的请求头做不同比例的流量分发调度、亦或者是金丝雀发布。
说起容器编排,像Docker的Compose或者是Docker-Swarm都提供了简单的容器编排的能力。
点击查看白日梦的-玩转Docker容器编排-DockerCompose、Docker-Swarm
像Docker-Compose或者Docker-Swarm的通病就是过于以Docker核心,提供的能力也过于简单比如定义谁先启动谁后启动。无法满足比较复杂的场景
而K8S的容器编排设计是站在更高的维度,Docker对于K8S而言只是运行它编排产出的介质,K8S针对不同的编排场景提供了不同的编排资源对象,如提供Deployment编排无状态应用,提供了Cronjob编排定时任务,提供了StatefulSet编排ES、Redis集群这种有状态应用等等,这都是前者所不能及的....
三、架构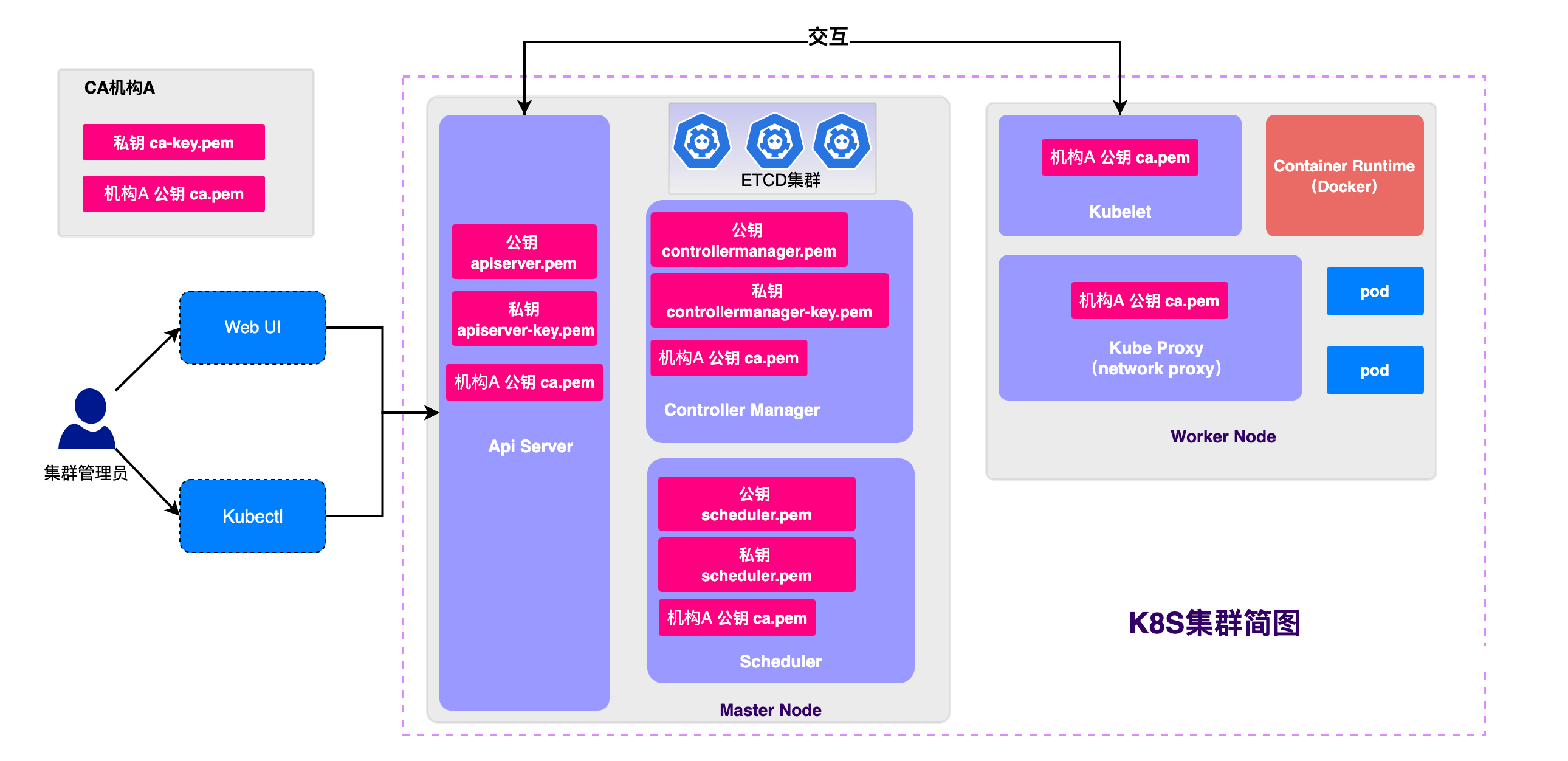
K8S架构简图如上,分为MasterNode、WorkNode两大部分和五大组件,一开始接触这些概念难免会有些陌生,但是本质上这些组件都是K8S的开发者对各种能力的抽象和封装,下文会展开介绍
tip:上图中很多xxx.pem文件是K8S的https安全认证依赖的证书,想进一步了解原理可以阅读这篇笔记:十二张图,从零礼哦啊姐对称加密/非对称加密/CA认证/以及K8S各组件证书颁发原由
3.1、MasterNode和Redis或者Nginx这种由二进制文件启动后得到一个对外提供服务的守护进程不同,K8S中的MasterNode其实并不是一个二进制文件启动后得到的对外提供服务的守护进程,它本质上是一个抽象的概念。
MasterNode包含3个程序,分别是:
- ApiServer
- 提供HTTP Rest接口,是集群中各种核心资源的CRUD的统一入口,是集群中各个组件交互的核心枢纽
- 集群资源配额的统一入口
- 提供了完备的集群安全机制
- ControllerManager
- 实时监控集群中如Service等各种资源的状态变化,不断尝试将它们的副本数量维持在一个期望的状态。
- Scheduler:
- 负责调度功能,如:为Pod找到一个合适的宿主机器
和MasterNode类似,WorkerNode本质也并不是一个独立的应用程序,它包含两个组件,如下
- kubelet
- Node节点管理
- Pod管理,同容器运行时交互下发容器的创建/关闭命令
- 容器健康状态检查
- kube-proxy
- 通过为Service资源的ClusterIP生成iptable或ipvs规则,实现将K8S内部的服务暴露到集群外面去
四、核心组件 4.1、ApiServer 4.1.1、概述既然WorkNode也是抽象的概念,那么若在MasterNode启动kube-proxy和kubelet进程,那么MasterNode也会拥有WorkNode的能力,双重角色,但生产环境不推荐这样搞。
APIServer有完备的集群安全验证机制,提供了对K8S中如Pod、Service等资源CRUD等HttpRest接口,是集群中各个组件之间数据交互的核心枢纽。
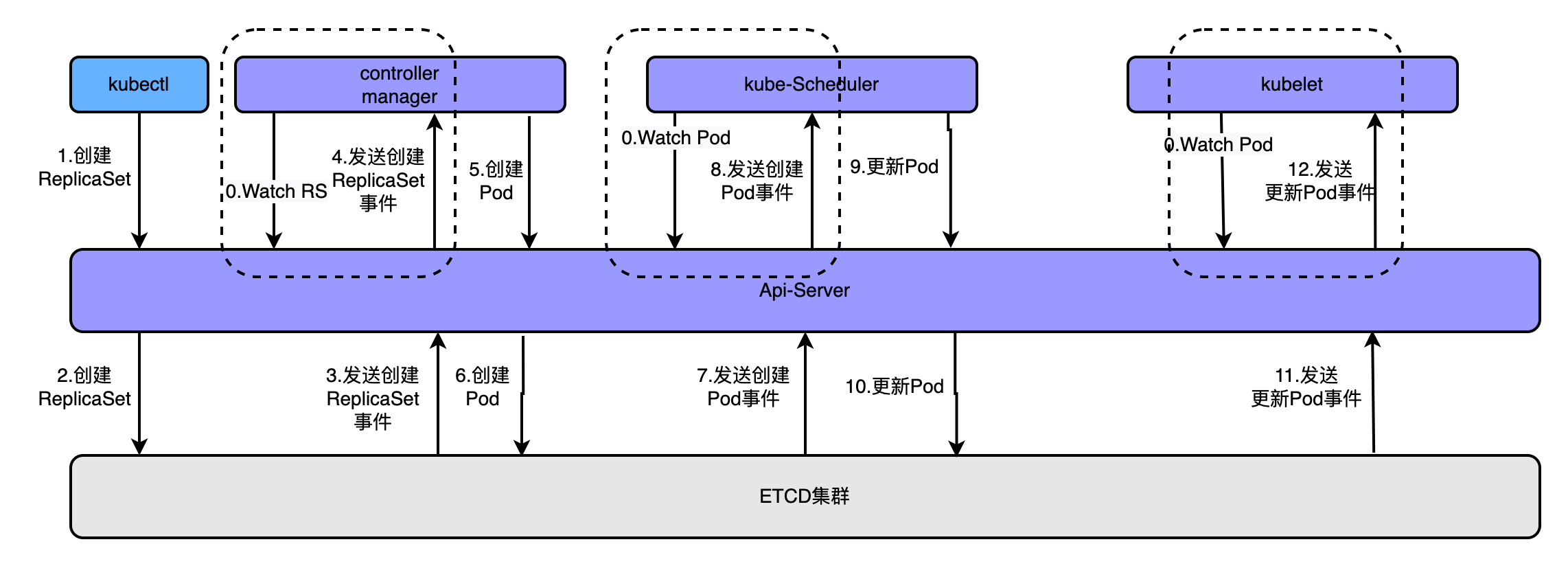
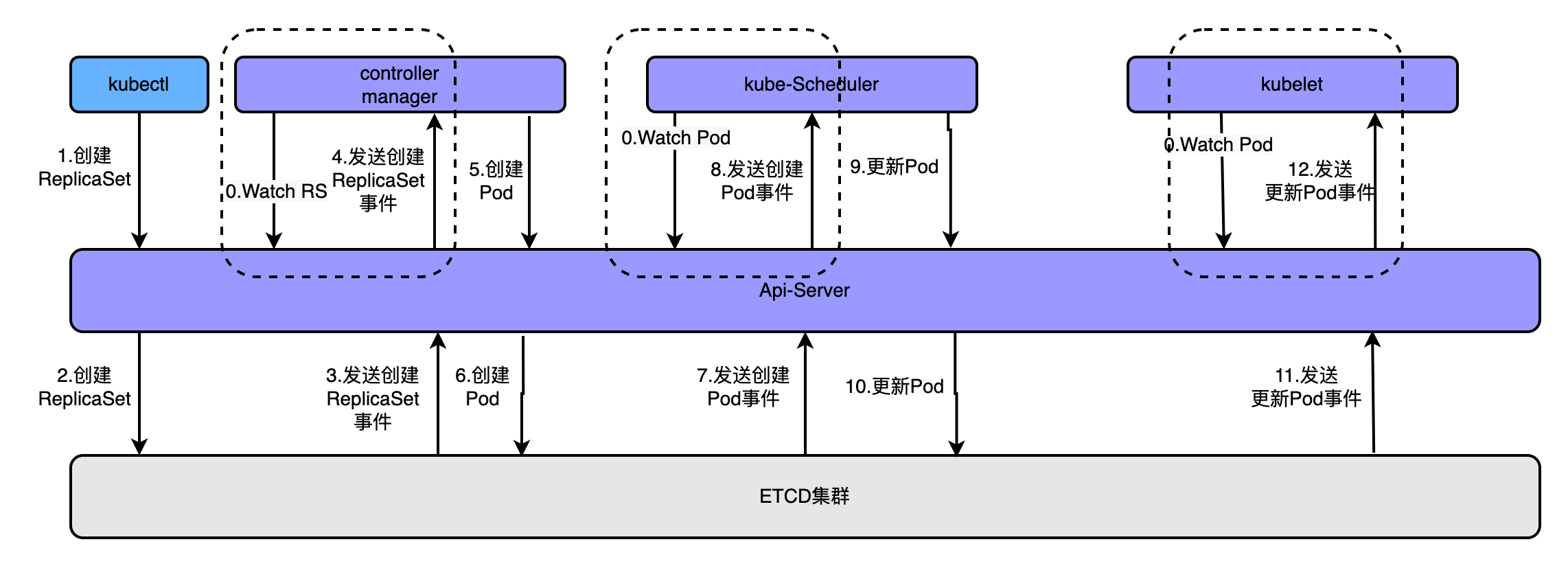
4.1.2、是集群管理API的统一入口为了更好的理解这个概念可以看如下图
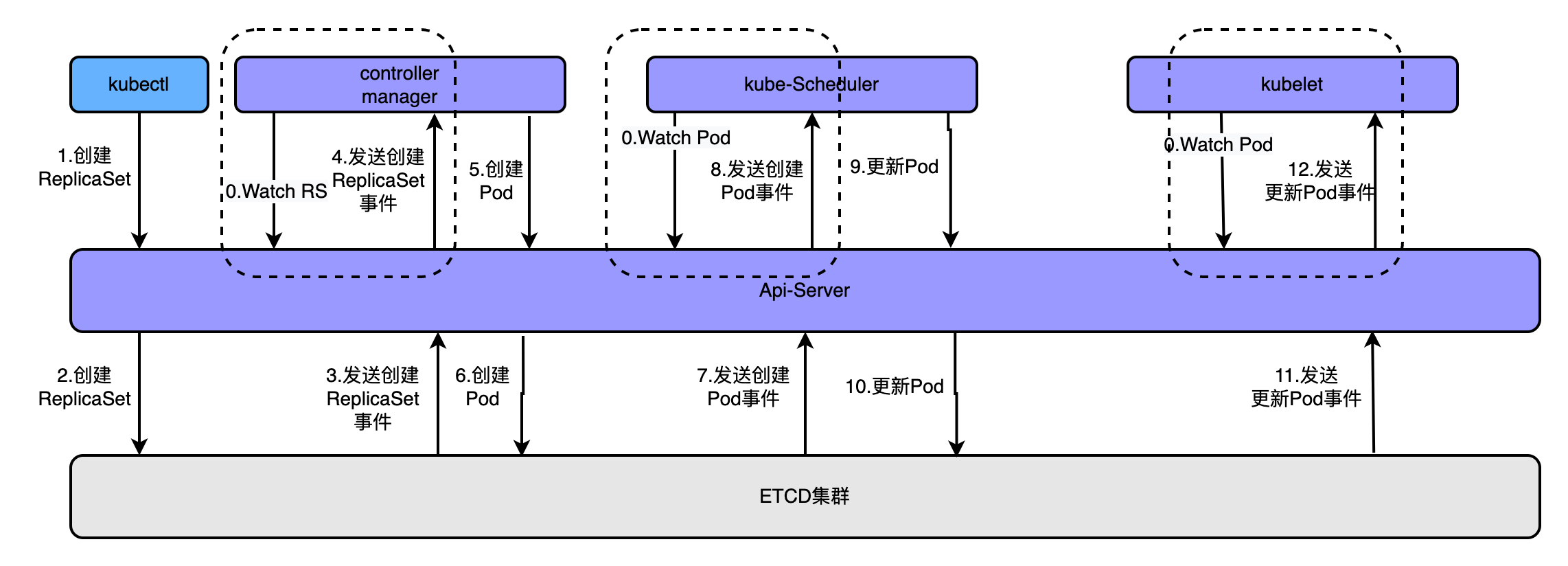
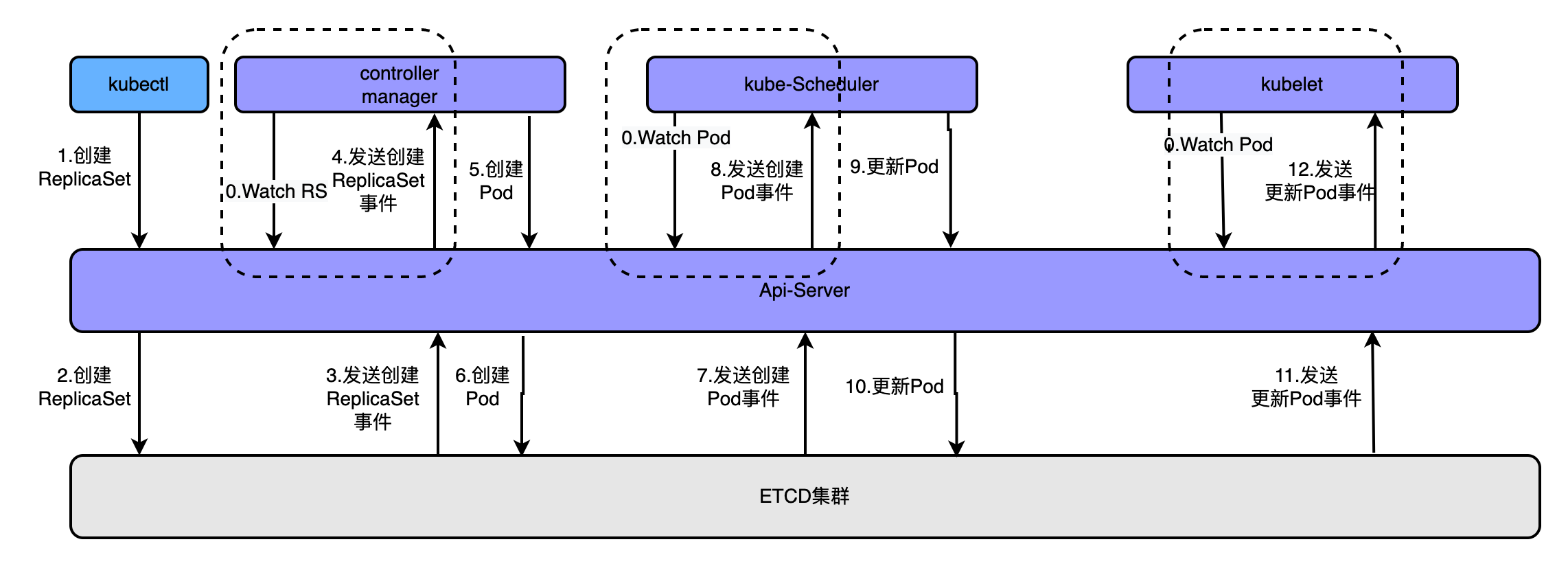
通过kubectl命令执行创建kubectl apply -f rs.yaml创建pod时,经历的流程如上图,大概流程为
- apiserver接收kubectl的创建资源的请求
- apiserver将创建请求写入ECTD
- apiserver接收到etcd的回调事件
- apiserver将回调事件发送给ControllerManager
- controllerManager中的ReplicationController处理本次请求,创建RS,然后它会调控RS中的Pod的副本数量处于期望值,比期望值小就新创建Pod,于是它告诉ApiServer要创建Pod
- apiserver将创建pod的请求写入etcd集群
- apiserver接收etcd的创建pod的回调事件
- apiserver将创建pod的回调事件发送给scheduler,由它为pod挑选一个合适的宿主node
- scheduler告诉apiserver,这个pod可以调度到哪个node上
- apiserver将scheduler告诉他的事件写入etcd
- apiserver接收到etcd的回调,将更新pod的事件发送给对应node上的kubelet进程
- kubelet通过CRI接口同容器运行时(Docker)交互,维护更新对应的容器。
ApiServer采用https+ca签名证书强制双向认证,也就说是想顺利访问通ApiServer的接口需要持有对应的证书
进一步了解Https/CA原理可以阅读这篇笔记:十二张图,从零理解对称加密/非对称加密/CA认证/以及K8S各组件证书颁发原由
4.1.4、典型使用场景比如在K8S内部搭建一个Elasticsearch的集群,每个pod中运行一个Pod,想搭集群的前提是得先知道有哪些运行着ES的Pod的ip地址。获取的途径只有一个:问ApiServer要。
那应用程序怎么知道ApiServer的地址呢?如下:
K8S中的Service占用单独的网段(启用ipvs的前提下,我的service网段为:192.168.0.0)
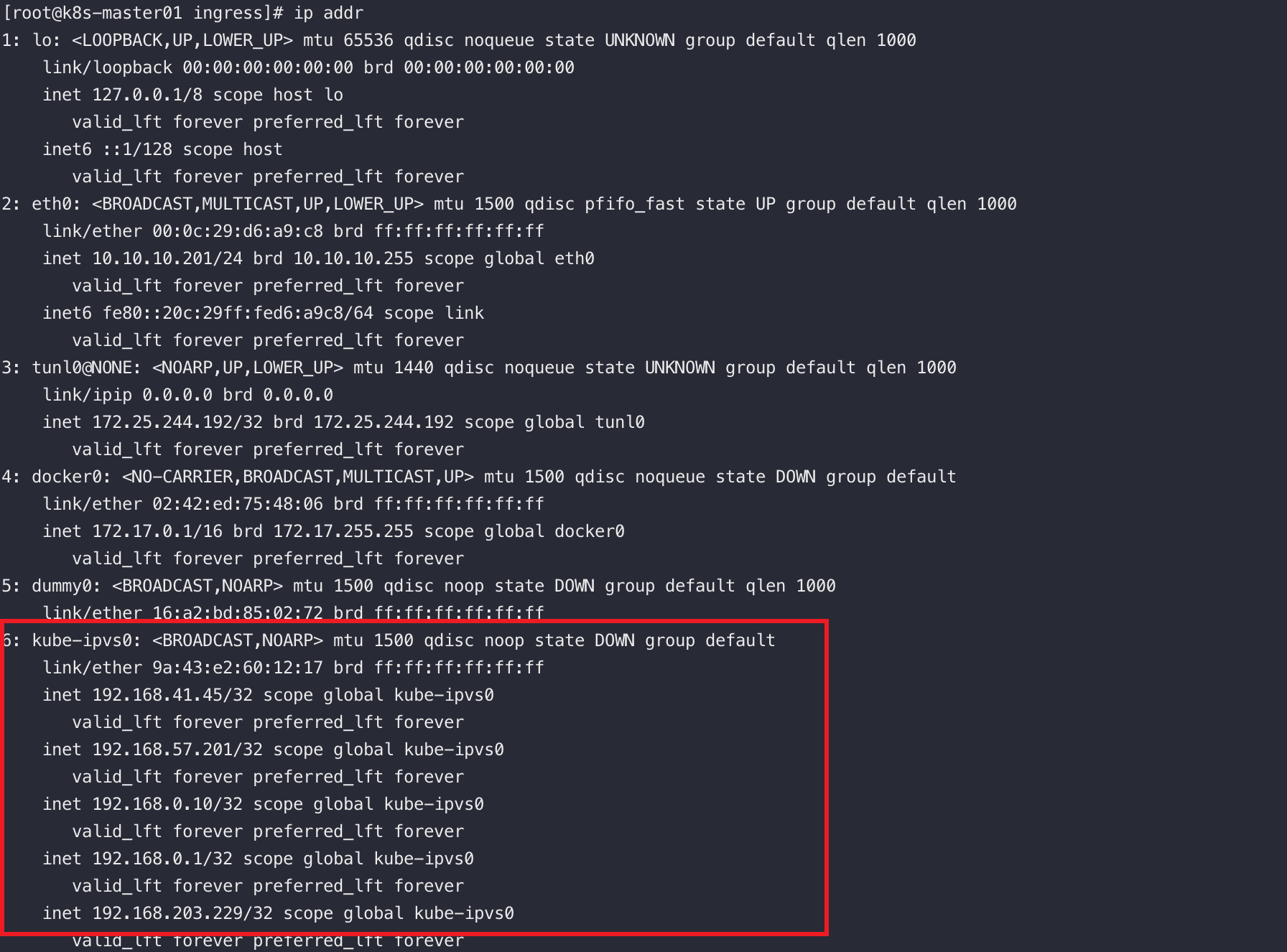
当我们安装完K8S集群后,在default命名空间中会有个默认的叫kubernetes的Service,这个service使用的service网段的第一个地址,而且这个service是ApiServer的service,换句话说,通过这个service可以访问到apiserver

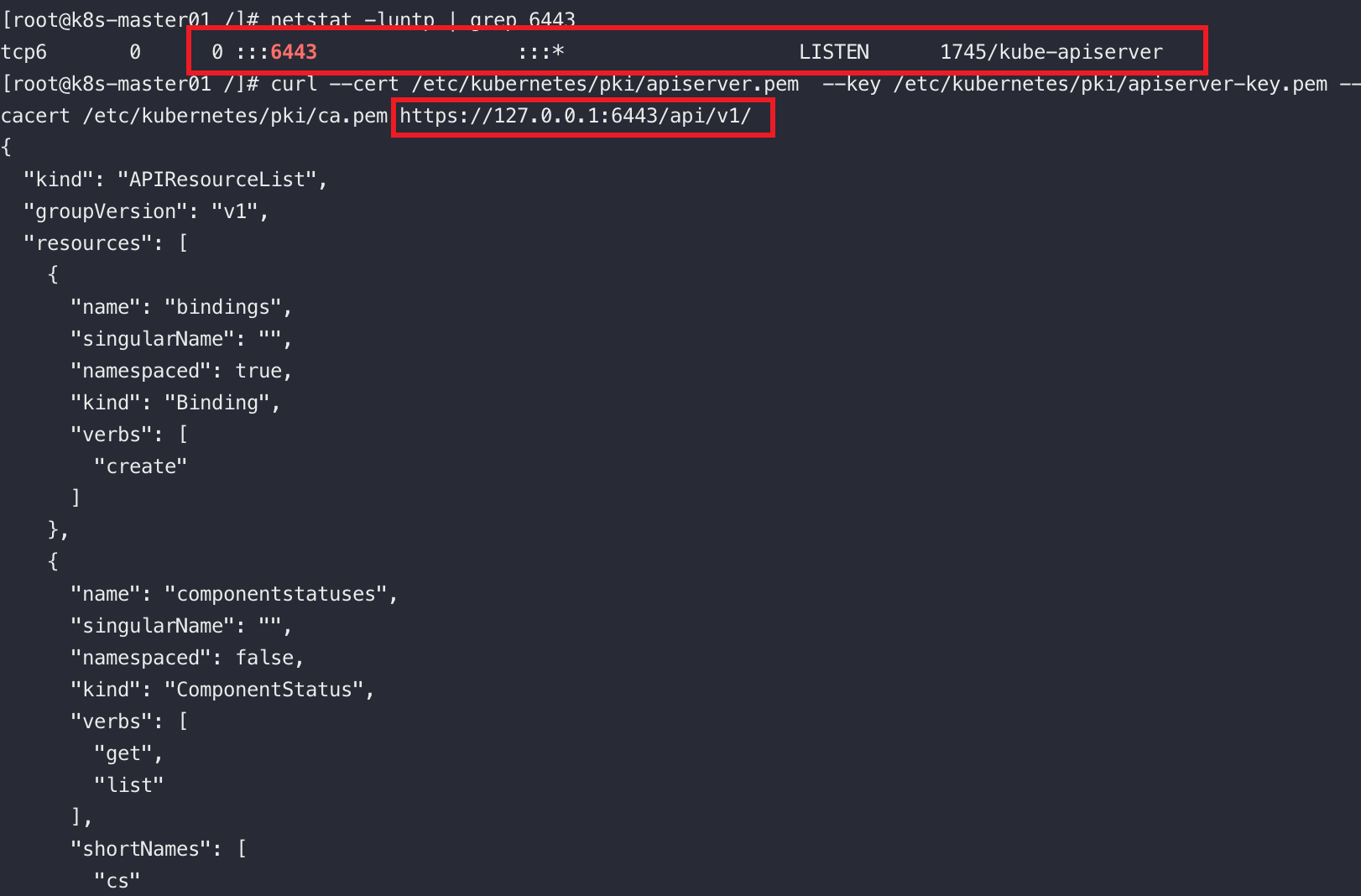
可以通过如下命令访问到本地的apiserver
curl --cert /etc/kubernetes/pki/admin.pem \
--key /etc/kubernetes/pki/admin-key.pem \
--cacert /etc/kubernetes/pki/ca.pem https://127..0.1:6443/api/v1/
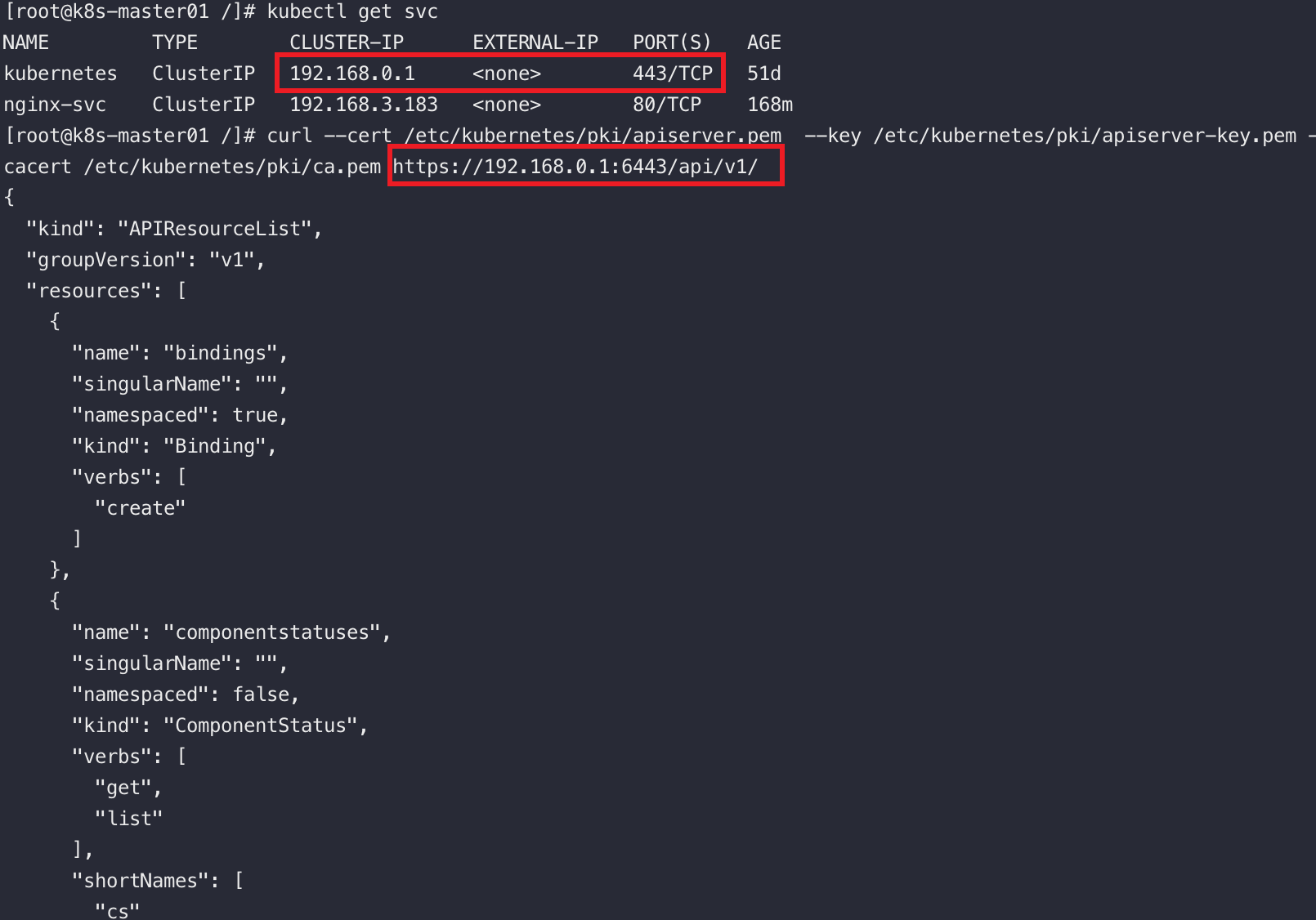
将回环地址换成名为kubernetes的service的cluster-ip也能访问到api-server
curl --cert /etc/kubernetes/pki/admin.pem --key /etc/kubernetes/pki/admin-key.pem --cacert /etc/kubernetes/pki/ca.pem https://192.168.0.1:6443/api/v1/
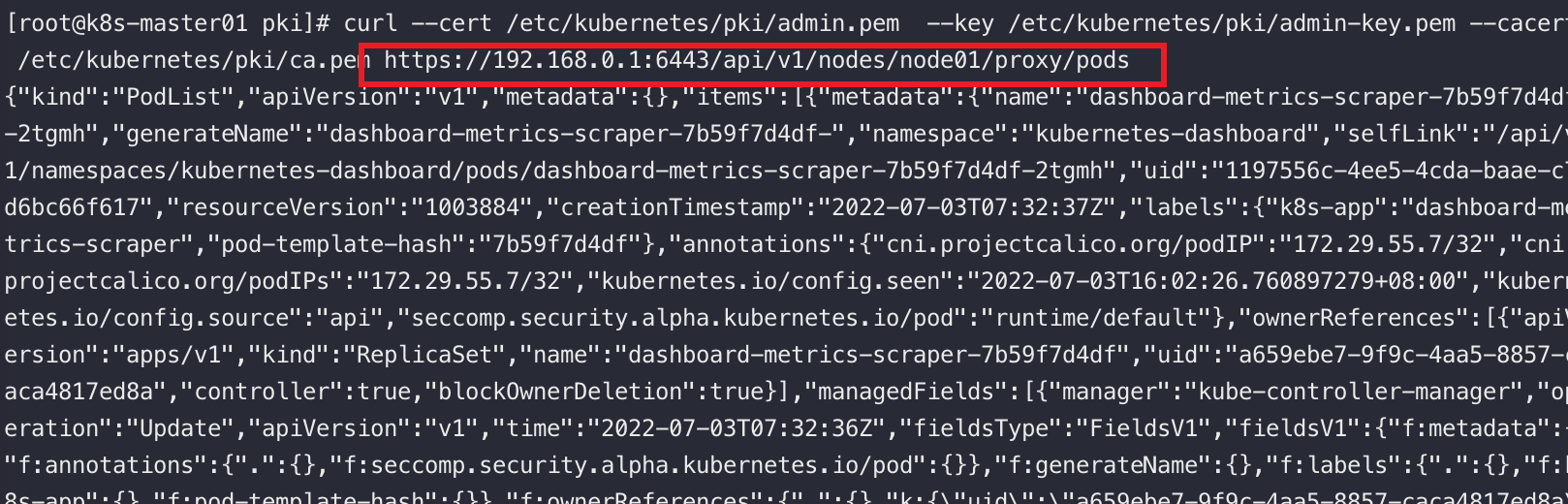
ApiServer提供了一种特殊的Restful接口,它本身不处理这些请求而将请求转发给对应的Kubelet处理
如:关于Node相关的接口
# 查询指定节点上所有的pod信息
/api/v1/nodes/{nodename}/proxy/pods
# 查询指定节点上物理资源的统计信息
/api/v1/nodes/{nodename}/proxy/stats
# 查询指定节点上的摘要信息
/api/v1/nodes/{nodename}/proxy/spec
更多接口查询官网~
关于Pod的接口
# 访问pod
/api/v1/namespace/{namespace-name}/pods/{name}/proxy
# 访问pod指定路径
/api/v1/namespace/{namespace-name}/pods/{name}/{path:*}
借助上图理解Controller的作用,它是K8S自动化管理各类资源的核心组件,所谓的自动化管理,其实就是实时监控集群中各类资源的状态的变化,不断的尝试将各类资源的副本数调整为期望值~
ControllerManager细分为8种Controller,如下
4.2.1、Replication Controller- 确保任何时候ReplicaSet管理的Pod副本数量都为期望值
- 实际值高于期望值告诉apisever应该关闭多余的pod,反之亦然
- 只有当Pod的重启策略为Always,Replication Controller才会管理
- Replication Controller通过标签管理Pod,若pod标签被改,pod将脱离管控
- 提供重新调度、弹性扩/缩容、滚动更新能力
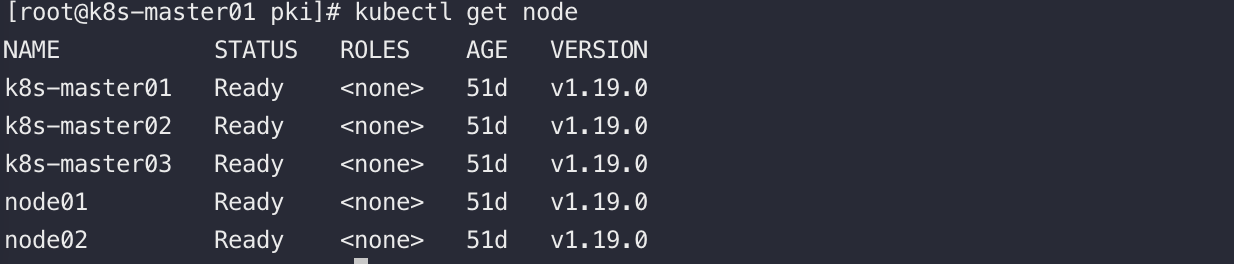
我们通过kubectl工具请求K8S的ApiServer获取集群中的Node信息,如下
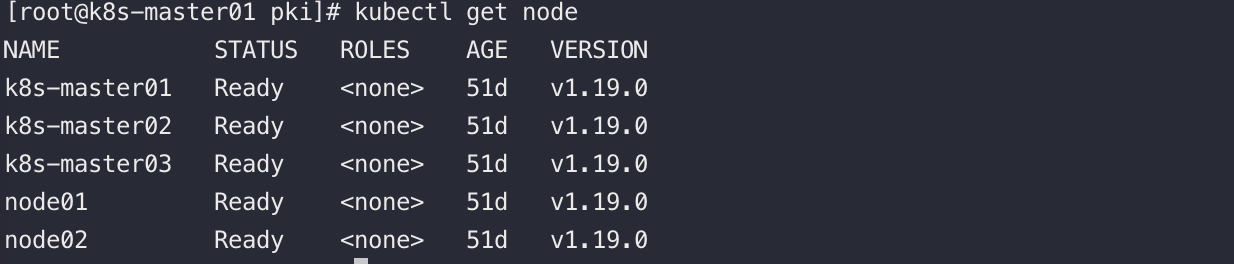
可以看到集群中所有的节点和它的状态都是Ready
apiserver是如何知道集群中有哪些节点的呢?答案是:kubelet上报给apiserver,再经由watch机制转发Node Controller,由Node Controller统一实现对集群中Node的管理。若节点长时间异常,NodeControler会删除该节点,节点上的资源重新调度到正常的节点中~
4.2.3、ResourceQuota ControllerResourceQuota Controller的功能是确保:指定资源对象数量在任何时候都不要超过指定的最大数量,进而保证由于业务设计的缺陷导致整个系统的紊乱甚至宕机。
使用示例:将ResourceQuota创建到哪个namespace中,便对哪个namespace生效
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
# ==对象数量配额==
# 最多创建的cm数
configmaps: "10"
# 最多创建的pvc数
persistentvolumeclaims: "4"
# 最多启动的pod数
pods: "4"
# 在该命名空间中允许存在的 ReplicationController 总数上限。
replicationcontrollers: "20"
# 最多创建的secret数
secrets: "10"
# 最多创建的service数
services: "10"
# 在该命名空间中允许存在的 LoadBalancer 类型的 Service 总数上限。
services.loadbalancers: "2"
# 在该命名空间中允许存在的 NodePort 类型的 Service 总数上限。
services.nodeports: 2
# ==存储型==
# 所有 PVC,存储资源的需求总量不能超过该值。
requests.storage: 40Gi
# 在命名空间的所有 Pod 中,本地临时存储请求的总和不能超过此值。
requests.ephemeral-storage: 512Mi
# 在命名空间的所有 Pod 中,本地临时存储限制值的总和不能超过此值。
limits.ephemeral-storage: 40Gi
# ephemeral-storage 与 requests.ephemeral-storage 相同。
# ==cpu、memory==
# 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。
limits.cpu: 1
# 所有非终止状态的 Pod,其内存限额总量不能超过该值。
limits.memory: 16Gi
# 所有非终止状态的 Pod,其 CPU 需求总量(pod中所有容器的request cpu)不能超过该值。
requests.cpu: 0.5
# 所有非终止状态的 Pod,其内存需求总量(pod中所有容器的request cpu)不能超过该值。
requests.memory: 512Mi
# cpu: 0.5 和requests.cpu相同
# memory: 512Mi 和 requests.memory相同
目前支持的资源配额如下
- 容器级别
- 限制容器的CPU、内存
- Pod级别
- 对Pod中所有的容器的可用之和资源统一限制
- Namespace级别
- Pod数量
- RC的数量
- Service数量
- ResourceQuota的数量
- Secret数量
- 可持有的PV的数量等
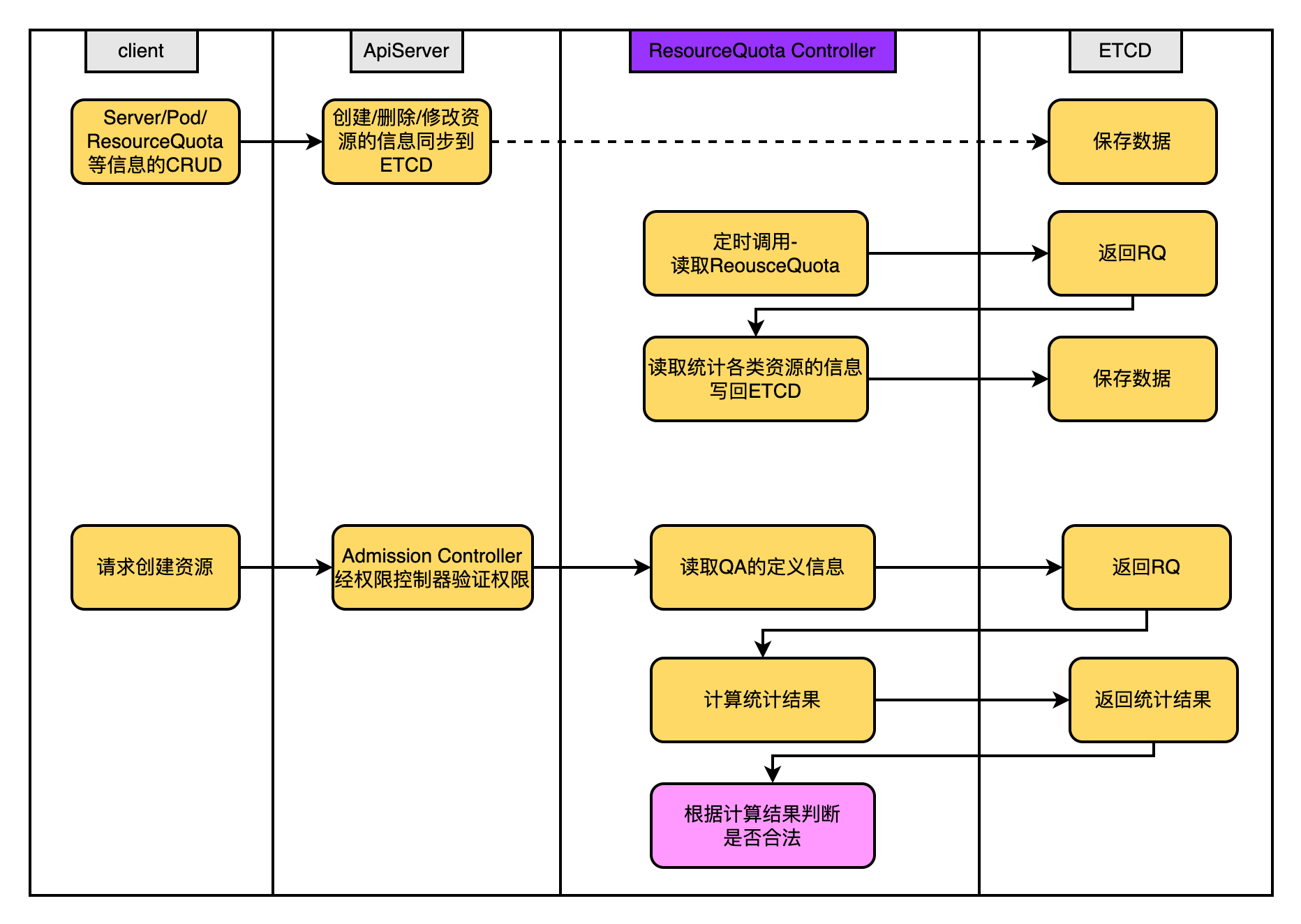
4.2.4、Namespace Controller感兴趣自己去了解LimitRange资源对象,LimitRange的配额自动为Pod添加Cpu和Memory的配置,这里不再展开
用户通过apiserver创建namespace,apiserver会将namespace的信息存储入etcd中。
namespaceController通过apiserver读取维护这些namespace的信息,若ns被标记为删除状态,namespaceController会将其状态改为Terminating
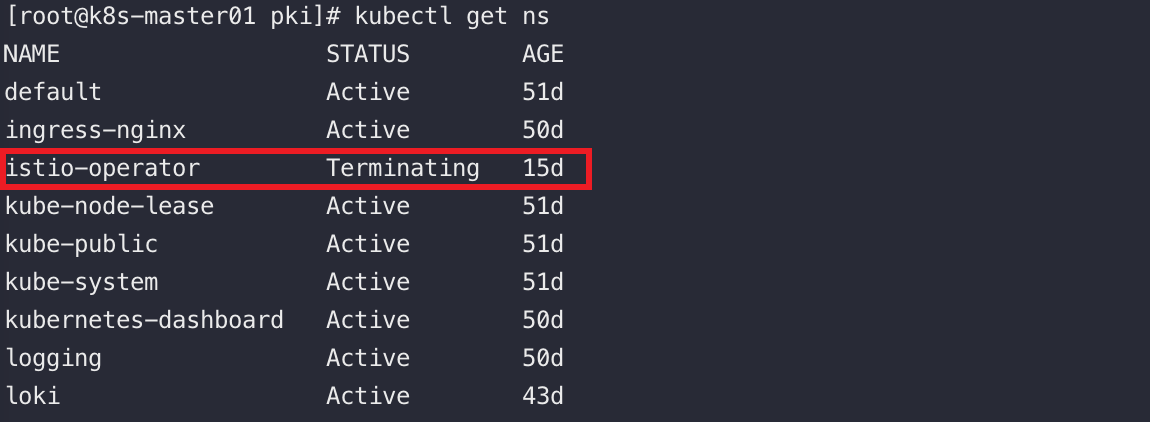
然后会删除它里面的ServiceAccount、RC、Pod等一切资源对象。
4.2.5、Service Controller - Endpoint ControllerService Controller 会监听维护Service的状态、变化
Service、Pod、Endpoint之间的关系如下图:Service通过标签选择器找到并代理对应的pod,pod的ip维护和Service同名的Endpoint中~
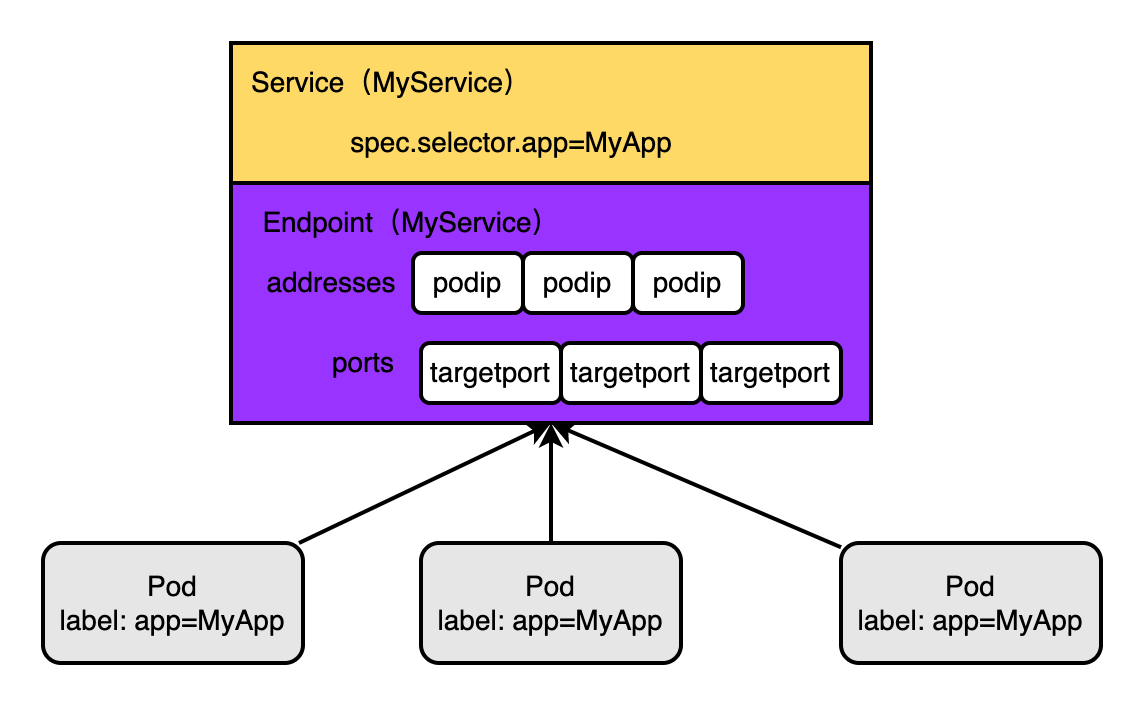
Endpoint Controller的作用是:监听Service和他对应的pod的变化
- 当Service被删除时,同步删除和Service同名的Endpoint对象
- 新建/更新Service时,同步更新对应Endpoint的ip:port列表信息
4.3、Schedulerendpoint对象由每个node上的kube-proxy的进程使用,下文会说
负责接收ApiServer创建Pod的请求,为Pod选择一个合适的Node,由该Node上的kubelet启动Pod中的相应容器
调度流程分两大步
- 预选策略
- 初步筛选出符合条件的Node
- 优选策略
- 在第一步的基础上选择更合适的Node
通过设置启动参数register-node参数开启kubelet向apiserver注册自己的信息,apiserver会将数据
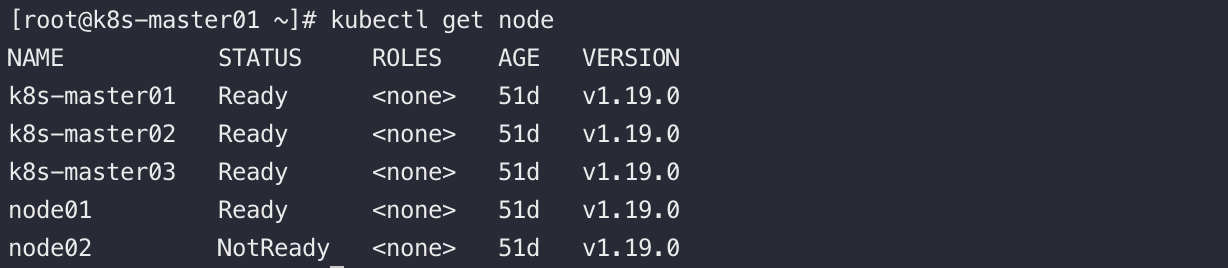
注册之后通过kubectl如下命令可用查看到集群中的所有node 的信息
若Node有问题,可以看到Status被标记为NotReady
最终管理员下发的创建Pod的请求由Kubelet转发给它所在节点的容器运行时(Docker)处理
4.4.3、容器健康检查容器的livenessProbe探针(httpGet、tcpSocket、ExecAction)用于判断容器的健康状态。
kubelet会定期调用这些探针来判断容器是否存活~
httpGet
向容器发送Http Get请求,调用成功(通过Http状态码判断)则确定Pod就绪;
使用方式:
livenessProbe:
httpGet:
path: /app/healthz
port: 80
exec
在容器内执行某命令,命令执行成功(通过命令退出状态码为0判断)则确定Pod就绪;
使用方式:
livenessProbe:
exec:
command:
- cat
- /app/healthz
tcpSocket
打开一个TCP连接到容器的指定端口,连接成功建立则确定Pod就绪。
使用方式:
livenessProbe:
tcpSocket:
port: 80
一般就绪探针会在启动容器一段时间后才开始第一次的就绪探测,之后做周期性探测。所以在定义就绪指针时,会给以下几个参数:
- initialDelaySeconds:在初始化容器多少秒后开始第一次就绪探测;
- timeoutSeconds:如果该次就绪探测超过多少秒后还未成功,判定为超时,该次探测失败,Pod不就绪。默认值1,最小值1;
- periodSeconds:如果Pod未就绪,则每隔多少秒周期性的做就绪探测。默认值10,最小值1;
- failureThreshold:如果容器之前探测成功,后续连续几次探测失败,则确定容器未就绪。默认值3,最小值1;
- successThreshold:如果容器之前探测失败,后续连续几次探测成功,则确定容器就绪。默认值1,最小值1。
K8S原生的支持通过Service的方式代理一组Pod暴露到集群外部对外提供服务,创建Service时会这个Service创建一个Cluster-IP。而kubeproxy本质上就是这个Service的cluster-ip的负载均衡器。
在k8s的不同版本中,kubeproxy负载均衡Service的ClusterIp的方式不尽相同,主要如下
4.5.1、k8s1.2版本前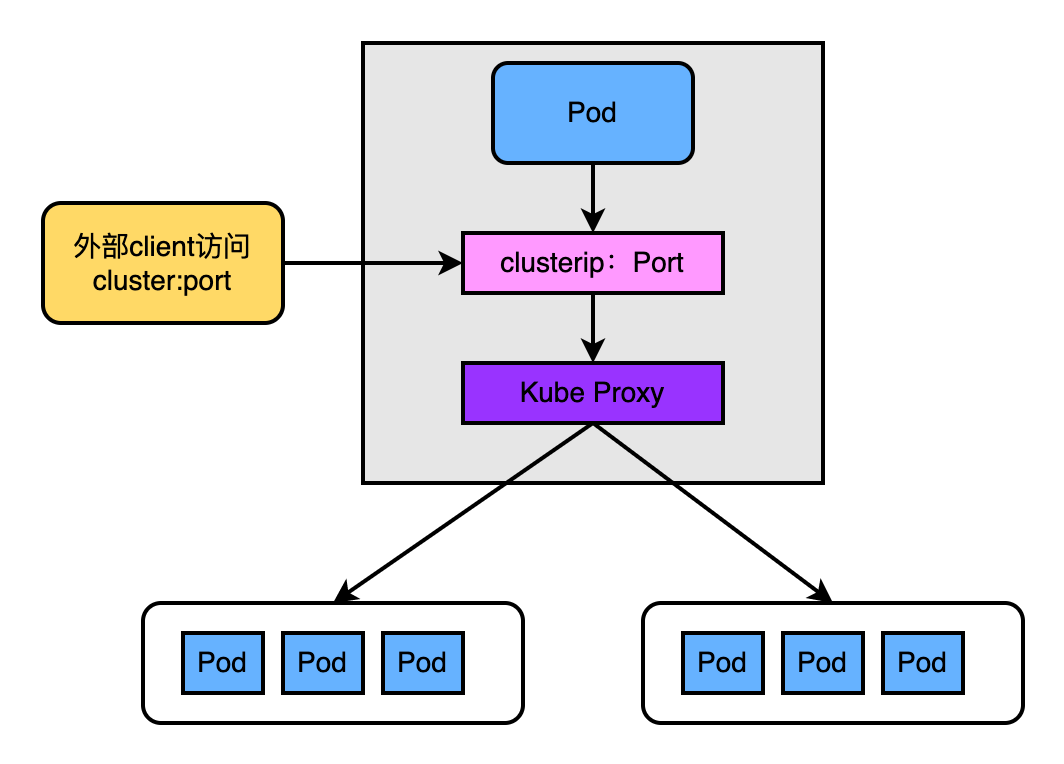
如上图这个版本的KubeProxy的更像是一个TCP/UDP代理,最明显的特征是:外部用户访问cluster:port过来的流量真实的经过了KubeProxy的处理和转发,即流量经过了userspace中。
4.5.2、k8s1.2~1.7版本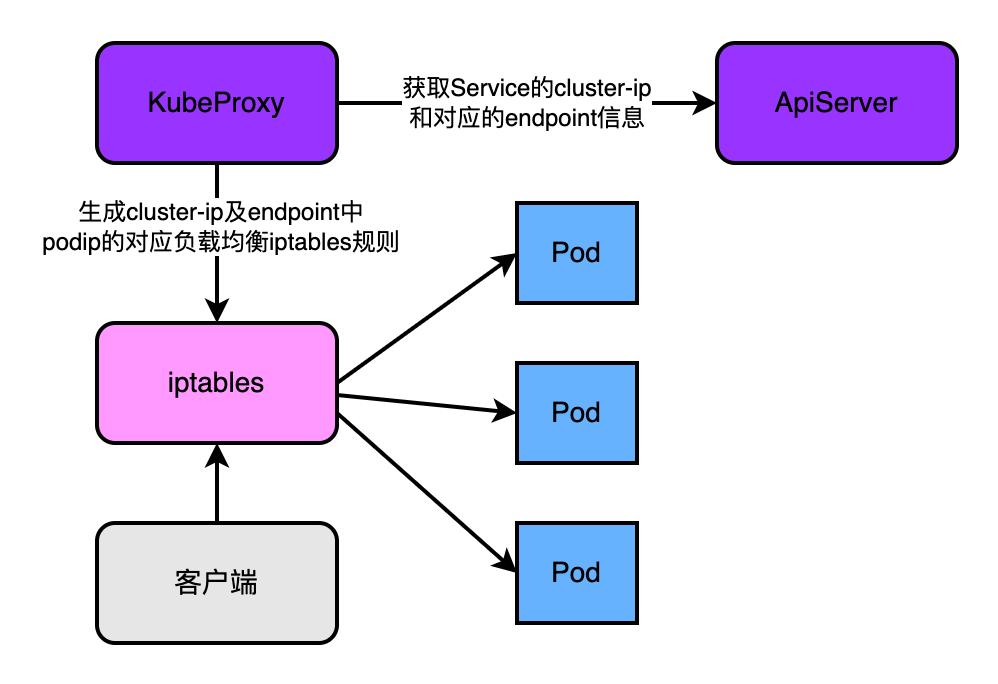
在这个版本KubeProxy端明显特征是:用户的流量不再由kubeproxy负责转发负载均衡。kubeproxy仅负责通过apiserver获取service和它对应的endpoint,然后根据这些数据信息生成iptables的规则,用户的流量通过iptables找到最终的pod。
4.5.3、k8s1.8版本及之后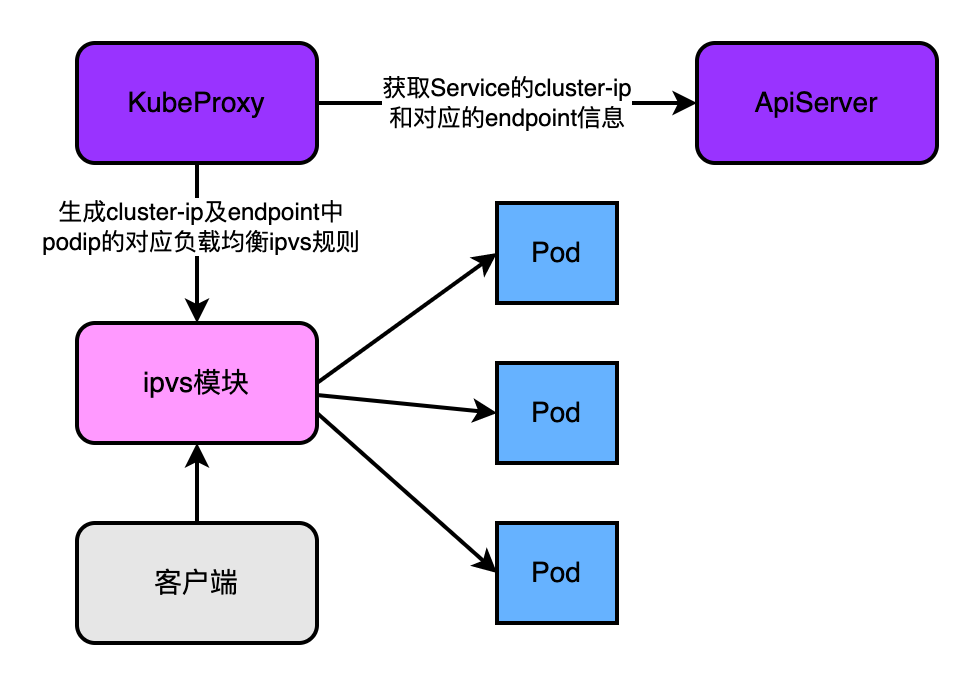
和上一个版本的区别是支持了ipvs模块。
两者的定位不同:虽然iptables和ipvs都是基于netfilter实现的,但是iptables为防火墙而设计,而ipvs的定位是高性能的负载均衡。
在数据结构层面实现不同:iptables是链式结构,流量流经iptables要过所谓的四表五链,当集群中中的pod数量剧增,iptables会变得十分臃肿,效率下降。而ipvs是基于hash表实现的,理论上支持无限扩张,且寻址快。
ipvs也有不足,比如不支持包过滤、地址伪装、SNAT,在使用Nodeport类型的Service时,依然需要和iptables搭配使用。
点击查看白日梦的iptables笔记
视频串讲iptables和docker网络
五、网络组件 5.1、CoreDNSCoreDNS是K8S的服务发现机制(有DNS能力),实现了通过解析service-name解析出cluster-ip的能力。而且service被重新创建时cluter-ip是可能发生变化的,但是server-name不会改变。
我们是以POD的形式将CoreDNS部署进K8S的,如下查看CoreDNS的service

这里的kube-dns的ip地址通常可以在安装coredns的配置文件中指定:coredns.yaml

验证下kube-dns解析外网域名的DNS能力
[root@master01 ~]# yum -y install bind-utils
[root@master01 ~]# dig -t A www.baidu.com @192.168.0.10 +short
www.a.shifen.com.
39.156.66.18
39.156.66.14
验证下kube-dns解析service名的DNS能力
# ${serviceName}.${名称空间}.svc.cluster.local.
[root@master01 ~]# dig -t A kubernetes.default.svc.cluster.local. @192.168.0.10 +short
192.168.0.1
像Calico或者flanel等,都是符合CNI规范的网络插件,作用如下:
- 保证集群中的pod生成集群内全局唯一的IP地址。
- 为K8S集群提供了一个扁平化的集群网络(service网络)意思就是说,它实现了集群内的Pod跨node也能直接互通。
注意点:flanel不支持NetworkPolicy资源对象定义的网络策略,而Calico支持。
什么是网络策略?如下
- 只有来自IngressController的流量才能访问带有role=frontend标签的pod
- 只有namespaceA的pod不能访问其他namespace的pod
- 只有源ip地址在某个网段的请求才能访问Project-A
- 从ProjectB出去的流量指定访问指定网段的Pod
参考:kubernetes官网、《kubernetes权威指南》