目录 爬虫实战(六):爬笔趣阁 一、 网站分析 1、 页面分析 2、 源码分析 3、 链接分析 二、 编写代码 1、 获取目录 2、 访问目录 3、 下载数据 4、 搜索功能 三、 总代码 爬虫实战(
- 爬虫实战(六):爬笔趣阁
- 一、 网站分析
- 1、 页面分析
- 2、 源码分析
- 3、 链接分析
- 二、 编写代码
- 1、 获取目录
- 2、 访问目录
- 3、 下载数据
- 4、 搜索功能
- 三、 总代码
- 一、 网站分析
通过抓包分析可以得到,该网站为静态网站,所有信息都保存在页面源码中,可以直接从页面源码获取信息。
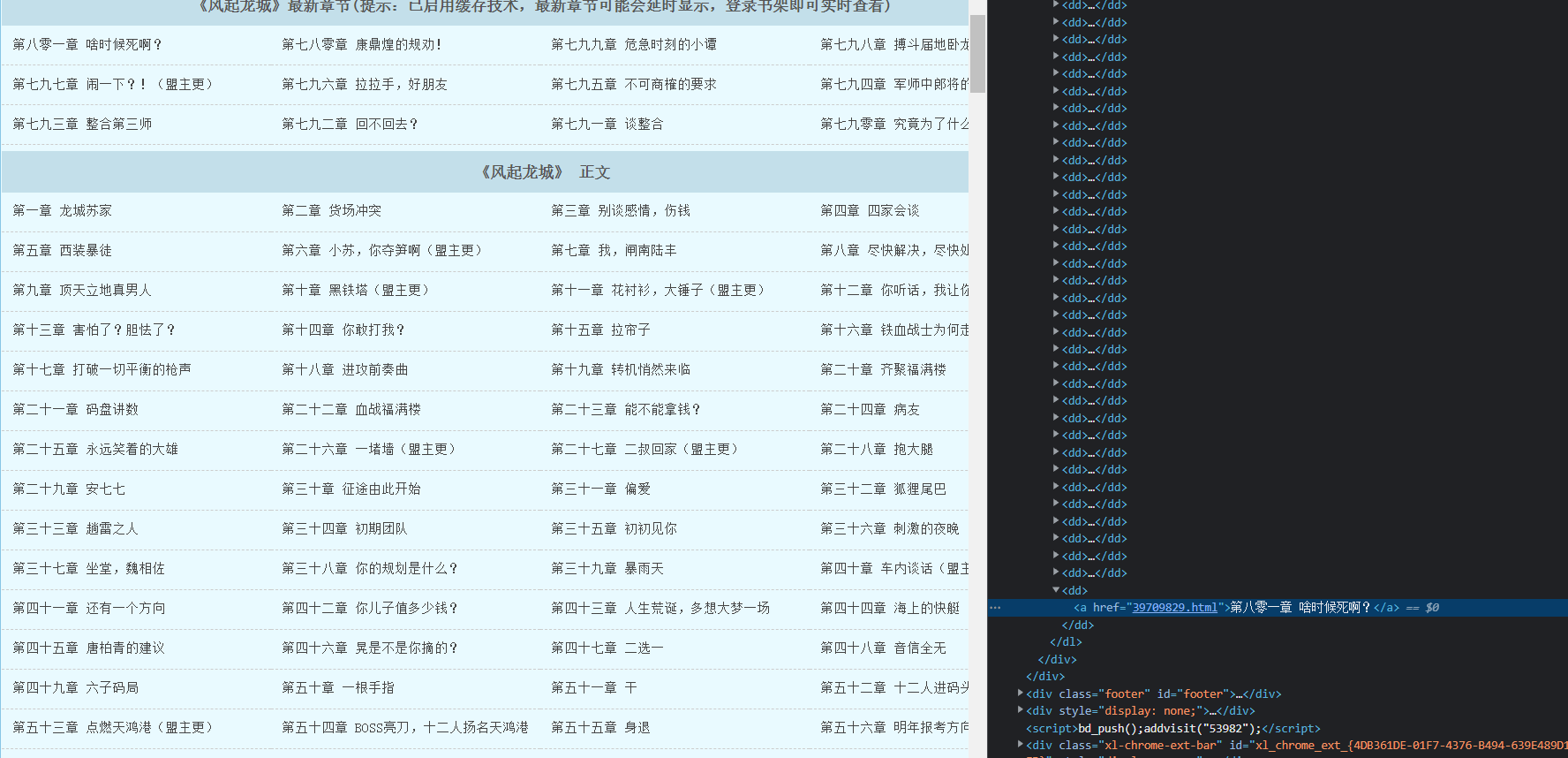
在目录中,发现其全部存储在一个dl的标签中
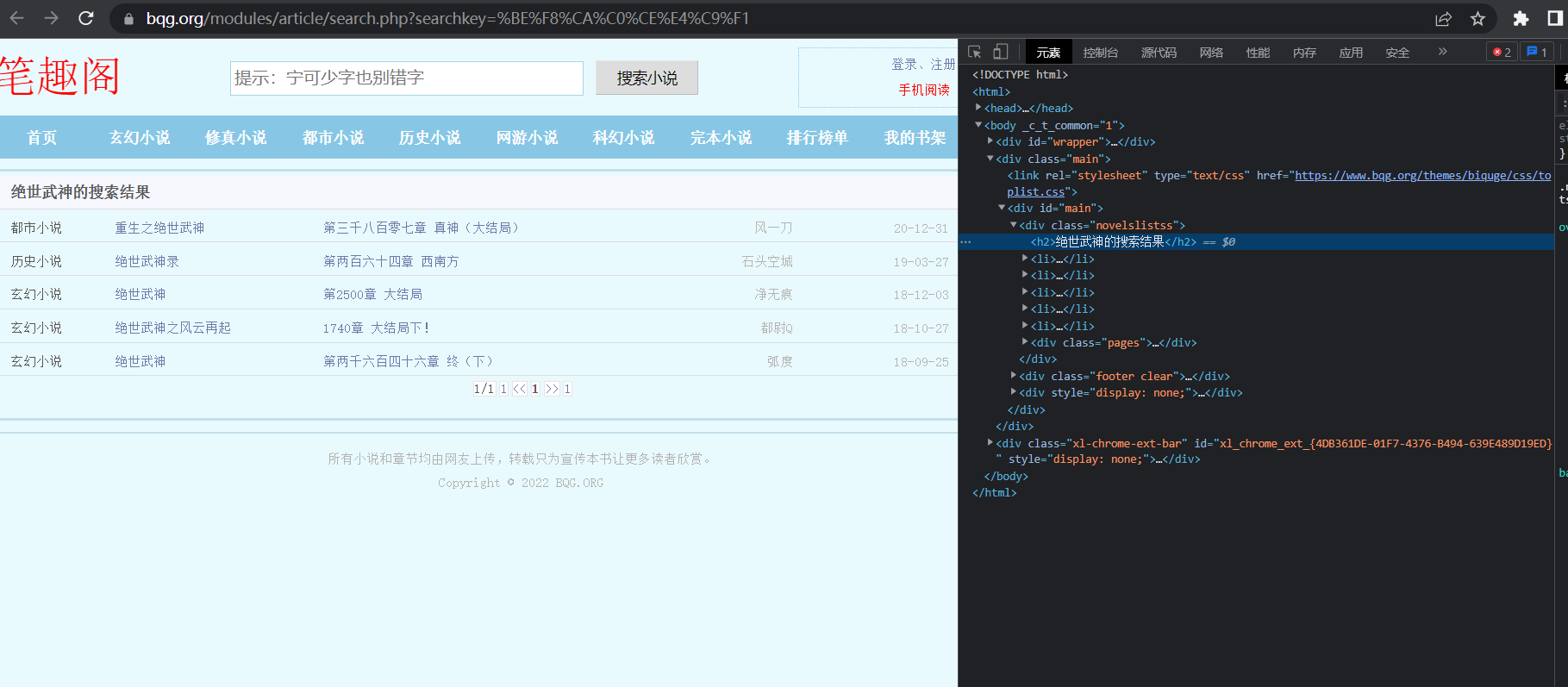
在搜索目录中,搜索内容存储在一个列表中,我们可以通过获取列表的长度来知道是否查找到了结果;如果没有搜索到结果,则不会将列表哦渲染出来,我们可以通过<div class="novelslistss"></div>来判断是否查找成功
 2、 源码分析
2、 源码分析
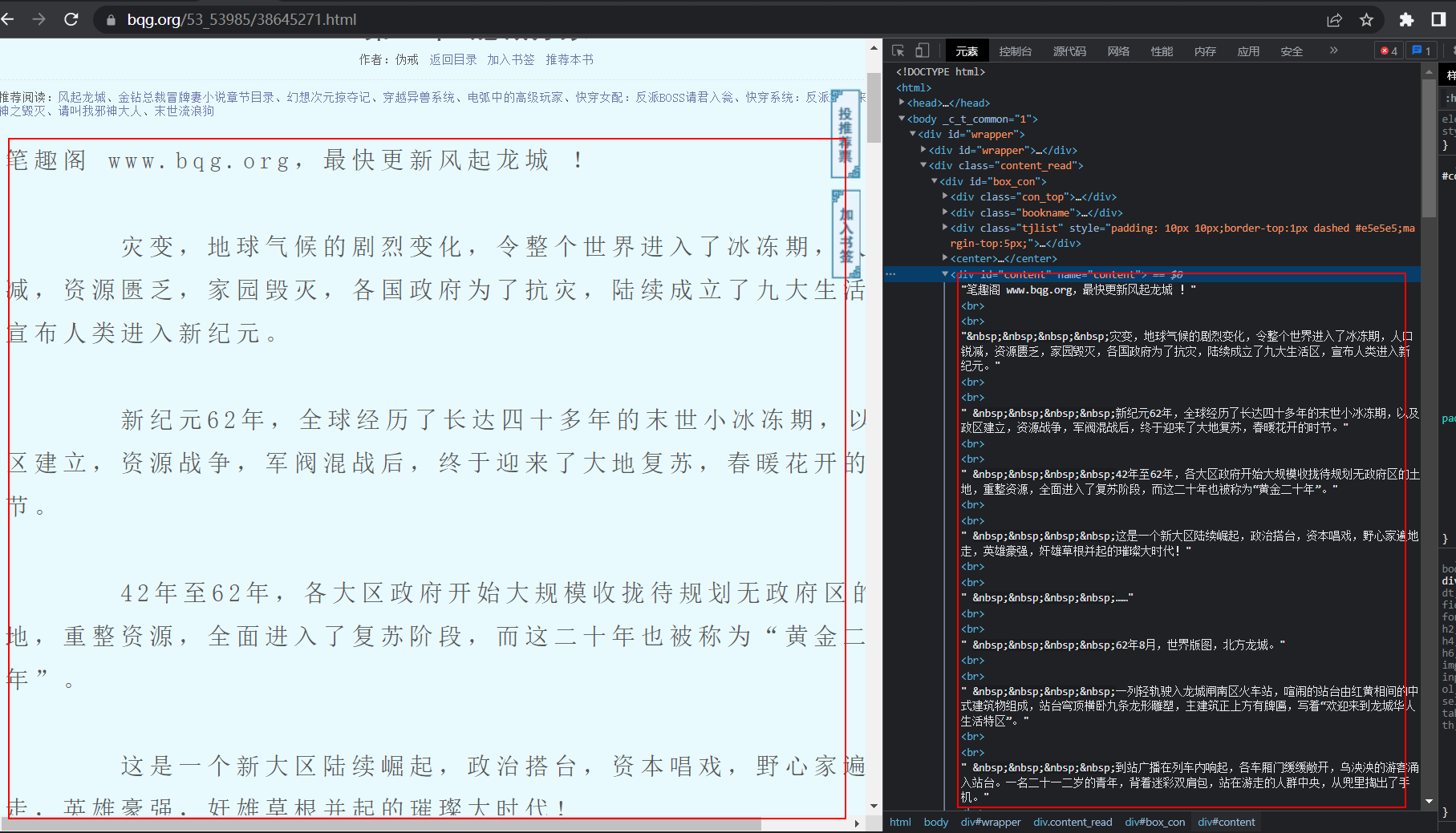
通过分析源码,发现,目录包裹在<dl></dl>,内容包裹在一个<div id="content"></div>中
 3、 链接分析
3、 链接分析
# 通过几次搜索可以得到几个url
# https://www.bqg.org/modules/article/search.php?searchkey=%BE%F8%CA%C0%CE%E4%C9%F1 # 绝世武神
# https://www.bqg.org/modules/article/search.php?searchkey=%BE%F8%CA%C0%CC%C6%C3%C5 # 绝世唐门
url = "https://www.bqg.org/modules/article/search.php?searchkey=%s"
from urllib import parse
print(parse.quote("绝世武神".encode("gbk")))
# 在多次尝试下,发现,其先是对文本内容进行gbk编码,再进行url编码
# 故,我们可以模拟搜索工具,来对内容进行精确的查找
name = input("请输入书名:") # 获取用户输入的书名
print(url % parse.quote(name.encode("gbk"))) # 得到url
# !/usr/bin/python3
# -*- coding: UTF-8 -*-
__author__ = "A.L.Kun"
__file__ = "biquge.py"
__time__ = "2022/7/6 14:03"
# 导入必要的模块
import requests, re # 发送请求,使用正则获取全部内容
from urllib import parse # 进行书名的编码
from fake_useragent import UserAgent # UA伪装
# 这次获取的是风起龙城的目录
url = "https://www.bqg.org/53_53985/" # 要爬取的url
headers = {
'Accept': ' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': ' gzip, deflate, br',
'Accept-Language': ' zh-CN,zh;q=0.9',
'Cache-Control': ' no-cache',
'Connection': ' keep-alive',
'Cookie': ' jieqiVisitId=article_articleviews%3D53982; jieqiVisitTime=jieqiArticlesearchTime%3D1657088500; clickbids=53982',
'Host': ' www.bqg.org',
'Pragma': ' no-cache',
'Referer': ' https://www.bqg.org/',
'sec-ch-ua': ' " Not A;Brand";v="99", "Chromium";v="102", "Google Chrome";v="102"',
'sec-ch-ua-mobile': ' ?0',
'sec-ch-ua-platform': ' "Windows"',
'Sec-Fetch-Dest': ' document',
'Sec-Fetch-Mode': ' navigate',
'Sec-Fetch-Site': ' same-origin',
'Sec-Fetch-User': ' ?1',
'Upgrade-Insecure-Requests': ' 1',
'user-agent': UserAgent().random
}
def get_menu(url):
headers.update({'user-agent': UserAgent().random}) # 随机请求头
resp = requests.get(url, headers) # 发起请求
resp.encoding = resp.apparent_encoding # 要文件的编码应该为gbk
temp = re.search("正文.*?</dl>", resp.text).group() # 进行剪切,去除开头那新更新的目录
lis = re.findall(r'<a href="(.*?)">(.*?)</a>', temp) # 使用正则获取到目录和对应目录的链接
url_de = []
chapters = []
for i in lis:
url_de.append(f"{url}{i[0]}")
chapters.append(i[1])
# print(url_de, chapters)
return url_de, chapters # 返回结果
get_menu(url)
def get_content(url):
headers.update({'user-agent': UserAgent().random}) # 随机请求头
resp = requests.get(url, headers) # 获取响应
resp.encoding = resp.apparent_encoding # 编码
content = re.search('<div id="content" name="content">(?P<content>.*?)</div>', resp.text, re.S).group("content") # 获取到内容
content = re.sub(r'<br.*?>', "\n", content) # 使用正则替换清洗数据
content = re.sub(r' ', " ", content) # 使用正则替换清洗数据
return content # 返回结果
get_content("https://www.bqg.org/53_53985/38645272.html") # 测试使用
def save_data(url_):
with open("./风起龙城.txt", "w", encoding="utf-8") as f:
urls, menus = get_menu(url_)
for index, url in enumerate(urls):
f.write(f"==============={menus[index]}===============\n")
print(f"正在下载:{menus[index]}")
content = get_content(url)
f.write(content + "\n")
print(f"{menus[index]},下载完成")
save_data("https://www.bqg.org/53_53985/")
url = "https://www.bqg.org/modules/article/search.php?searchkey=%s"
from lxml import etree
from prettytable import PrettyTable
def have_content(text):
# 当查找到内容时,展示查找到的内容给用户选择
html = etree.HTML(text)
li_s = html.xpath("//*[@id='main']/div[1]/li")
table = PrettyTable(['序号', "类型", '书名', '作者'])
lis_ = []
index = 0
for index, li in enumerate(li_s):
print(index)
type_ = li.xpath("./span[@class='s1']/text()")[0]
name = li.xpath("./span[@class='s2']/a/text()")[0]
url = li.xpath("./span[@class='s2']/a/@href")[0]
lis_.append(url)
author = li.xpath("./span[@class='s4']/text()")[0]
table.add_row([index + 1, type_, name, author])
print(table)
i = int(input("请输入要下载的序号:")) - 1
print(index)
if 0 < i <= index:
return lis_[i]
print("请按要求输入哦!")
sys.exit(0)
def search(n):
arg = parse.quote(n.encode("gbk"))
headers.update({
'User-Agent': UserAgent().random,
"Cookie": f"jieqiVisitTime=jieqiArticlesearchTime%{int(time())}"
}) # 随机请求头
print(headers)
url_ = url % arg
print(url_)
resp = requests.get(url_, headers=headers) # 发起请求
print(resp)
resp.encoding = resp.apparent_encoding # 设置当前编码
tet = resp.text # 获取内容
print(tet)
if re.search("错误原因:对不起,没有搜索.*?文章!", tet):
print("对不起,没有搜索到您要的文章!")
return
if re.search("错误原因:对不起,两次搜索.*?秒", tet):
print("对不起,两次搜索的间隔时间不得少于30秒")
return
# 剩下的都是查到内容的
return have_content(tet) # 获取具体的下载名,并且把url返回
name = input("请输入要下载的小说:")
search(name)
# !/usr/bin/python3
# -*- coding: UTF-8 -*-
__author__ = "A.L.Kun"
__file__ = "biquge.py"
__time__ = "2022/7/6 14:03"
# 导入必要的模块
import requests, re, sys # 发送请求,使用正则获取全部内容
from urllib import parse # 进行书名的编码
from fake_useragent import UserAgent # UA伪装
from lxml import etree
from prettytable import PrettyTable
url = "https://www.bqg.org/modules/article/search.php?searchkey=%s" # 查找的url
headers = {
'Accept': ' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': ' gzip, deflate, br',
'Accept-Language': ' zh-CN,zh;q=0.9',
'Cache-Control': ' no-cache',
'Connection': ' keep-alive',
'Cookie': ' jieqiVisitId=article_articleviews%3D53982; jieqiVisitTime=jieqiArticlesearchTime%3D1657088500; clickbids=53982',
'Host': ' www.bqg.org',
'Pragma': ' no-cache',
'Referer': ' https://www.bqg.org/',
'sec-ch-ua': ' " Not A;Brand";v="99", "Chromium";v="102", "Google Chrome";v="102"',
'sec-ch-ua-mobile': ' ?0',
'sec-ch-ua-platform': ' "Windows"',
'Sec-Fetch-Dest': ' document',
'Sec-Fetch-Mode': ' navigate',
'Sec-Fetch-Site': ' same-origin',
'Sec-Fetch-User': ' ?1',
'Upgrade-Insecure-Requests': ' 1',
'user-agent': UserAgent().random
}
def have_content(text):
# 当查找到内容时,展示查找到的内容给用户选择
html = etree.HTML(text)
li_s = html.xpath("//*[@id='main']/div[1]/li")
table = PrettyTable(['序号', "类型", '书名', '作者'])
lis_ = []
index = 0
for index, li in enumerate(li_s):
print(index)
type_ = li.xpath("./span[@class='s1']/text()")[0]
name = li.xpath("./span[@class='s2']/a/text()")[0]
url = li.xpath("./span[@class='s2']/a/@href")[0]
lis_.append(url)
author = li.xpath("./span[@class='s4']/text()")[0]
table.add_row([index + 1, type_, name, author])
print(table)
i = int(input("请输入要下载的序号:")) - 1
print(index)
if 0 < i <= index:
return lis_[i]
print("请按要求输入哦!")
sys.exit(0)
def search(n):
arg = parse.quote(n.encode("gbk"))
headers.update({
'User-Agent': UserAgent().random,
"Cookie": f"jieqiVisitTime=jieqiArticlesearchTime%{int(time())}" # cookie反爬
}) # 随机请求头
url_ = url % arg
resp = requests.get(url_, headers=headers) # 发起请求
resp.encoding = resp.apparent_encoding # 设置当前编码
tet = resp.text # 获取内容
if re.search("错误原因:对不起,没有搜索.*?文章!", tet):
print("对不起,没有搜索到您要的文章!")
return
if re.search("错误原因:对不起,两次搜索.*?秒", tet):
print("对不起,两次搜索的间隔时间不得少于30秒")
return
# 剩下的都是查到内容的
return have_content(tet) # 获取具体的下载名,并且把url返回
def get_menu(url):
headers.update({'user-agent': UserAgent().random}) # 随机请求头
resp = requests.get(url, headers) # 发起请求
resp.encoding = resp.apparent_encoding # 要文件的编码应该为gbk
temp = re.search("正文.*?</dl>", resp.text).group() # 进行剪切,去除开头那新更新的目录
lis = re.findall(r'<a href="(.*?)">(.*?)</a>', temp) # 使用正则获取到目录和对应目录的链接
url_de = []
chapters = []
for i in lis:
url_de.append(f"{url}{i[0]}")
chapters.append(i[1])
# print(url_de, chapters)
return url_de, chapters # 返回结果
def get_content(url):
headers.update({'user-agent': UserAgent().random}) # 随机请求头
resp = requests.get(url, headers) # 获取响应
resp.encoding = resp.apparent_encoding # 编码
content = re.search('<div id="content" name="content">(?P<content>.*?)</div>', resp.text, re.S).group(
"content") # 获取到内容
content = re.sub(r'<br.*?>', "\n", content) # 使用正则替换清洗数据
content = re.sub(r' ', " ", content) # 使用正则替换清洗数据
return content # 返回结果
def save_data(url_, name):
with open(f"./{name}.txt", "w", encoding="utf-8") as f:
urls, menus = get_menu(url_) # 获取目录信息
for index, url in enumerate(urls): # 遍历链接
f.write(f"==============={menus[index]}===============\n")
print(f"正在下载:{menus[index]}")
content = get_content(url) # 获取详细信息
f.write(content + "\n") # 写入文件
print(f"{menus[index]},下载完成") # 提示信息
print("--------------------------")
def main():
name = input("请输入要下载的小说名:")
save_data(search(name), name)
print("下载完成")
if __name__ == "__main__":
main()