本文主要介绍Kubernetes 的核心组件、架构、服务编排,以及在集群规模、网络&隔离、SideCar、高可用上的一些使用建议,尤其是在CICD中落地,什么是 GitOps. 通过此文可彻底了解 k8s 的整体核心技术以及如何应用在 DevOps 实践中。
荣辛是我的同事,阿里云过来的一位大佬,我也把他邀请到了我们「研发效能DevOps」中来交流。Kubernetes 在现在的云原生体系基础设施中的地位太重要了,无论是做 Dev 还是 Ops 都要了解一些,欢迎大家一起来讨论。本文内容大纲如下
K8s核心组件介绍 1.1 什么是云原生?
云原生(Cloud Native)是一种构建和运行应用程序的方法,是一套技术体系和方法论。
- Cloud Native是一个组合词,Cloud+Native。
- Cloud是适应范围为云平台
- Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
CNCF(Cloud Native Computing Foundation,云原生计算基金会)在定义中给出了云原生的关键技术,容器、服务网格、微服务、不可变基础设施和声明式API,是目前云原生应用的最佳实践。
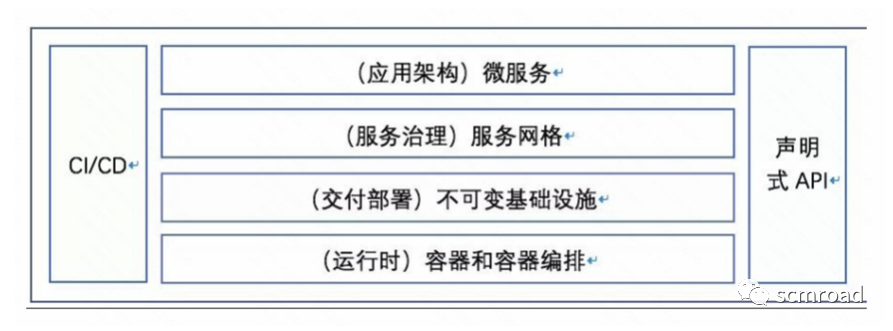
微服务架构向开发人员提出新的挑战。应用向微服务演进的过程遇到新的问题?
- 无法静态配置;
- 服务数量多,需要服务注册/发现;
- 无法人工管理海量的服务;
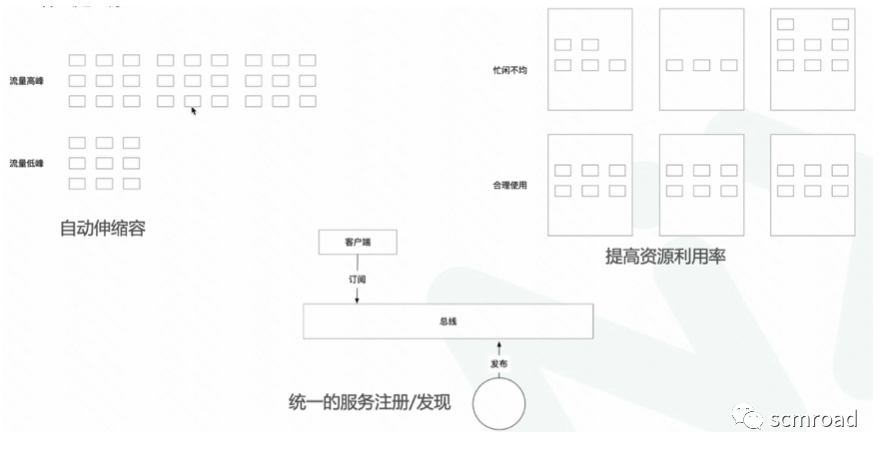
云原生就是面向云环境的,从设计层面支持自动伸缩容,资源控制和支持统一服务注册/发现的应用 。
1.2 容器、K8s、云原生的关系
容器的兴起
- 云计算的大潮与Pass概念的普及;
- Docker 通过镜像容器,保证应用环境的一致性,解决了应用打包的难题
- 但是容器本身是没有价值的,有价值的是容器编排
- 容器编排的战争最后以kubernetes和CNCF的胜利告终;
容器的本质是一个特别的线程
- 以 Namespace 为隔离,是容器的边界墙;
- 以 Cgroups 为限制,是容器的盖子和屋顶;
- 以 Mount 挂载指定路径为文件系统,是容器的底座;
但是容器和容器之间的关系如何维护?如何编排容器?
实际上,过去很多的集群管理项目(比如 Yarn、Mesos,以及 Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能,我们称为“调度”。
而 Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。
所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。不过,更重要的是,Kubernetes 项目为用户提供的不仅限于一个工具。它真正的价值,乃在于提供了一套基于容器构建分布式系统的基础依赖。
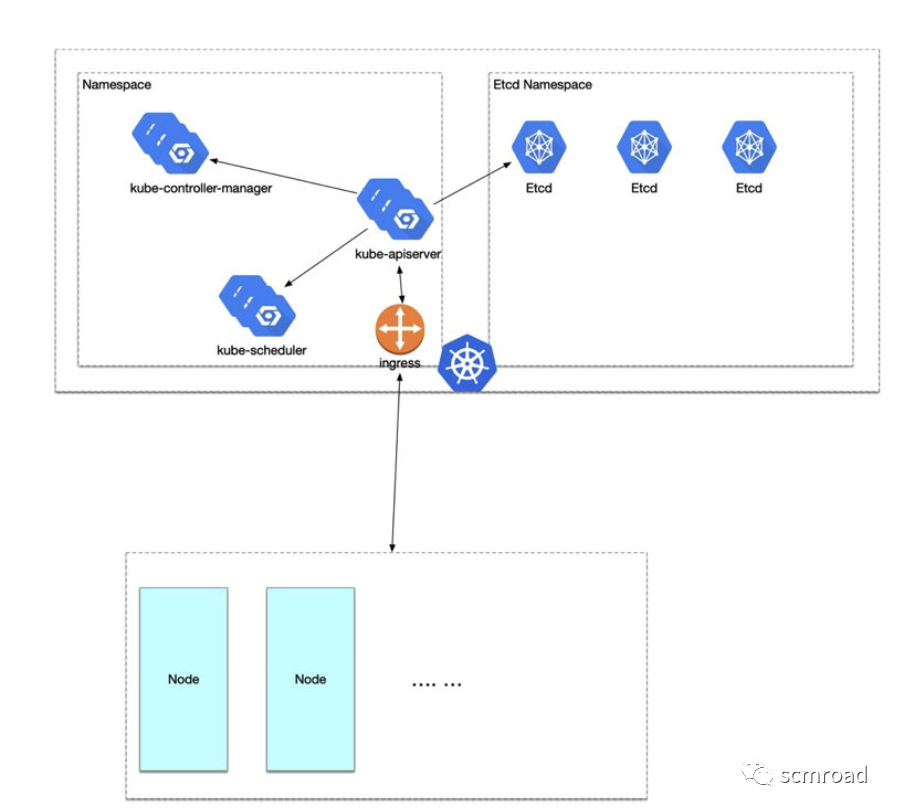
1.3 k8s核心架构
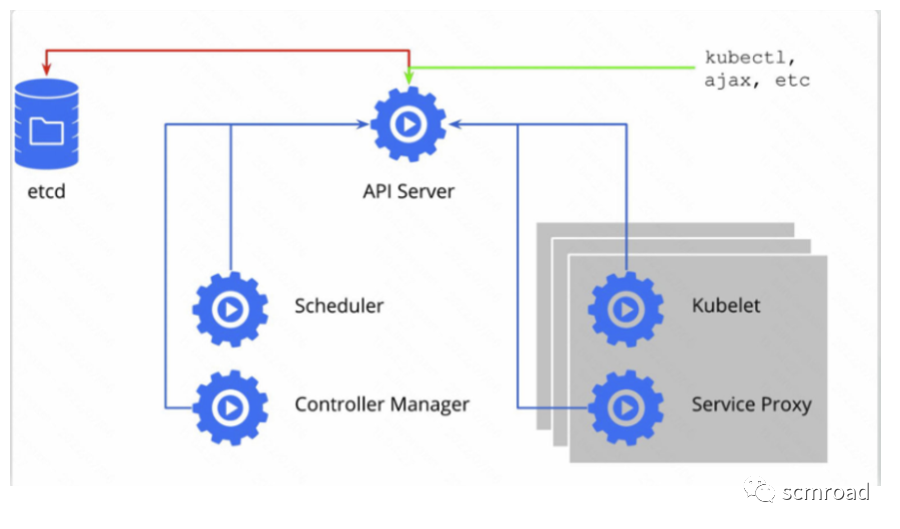
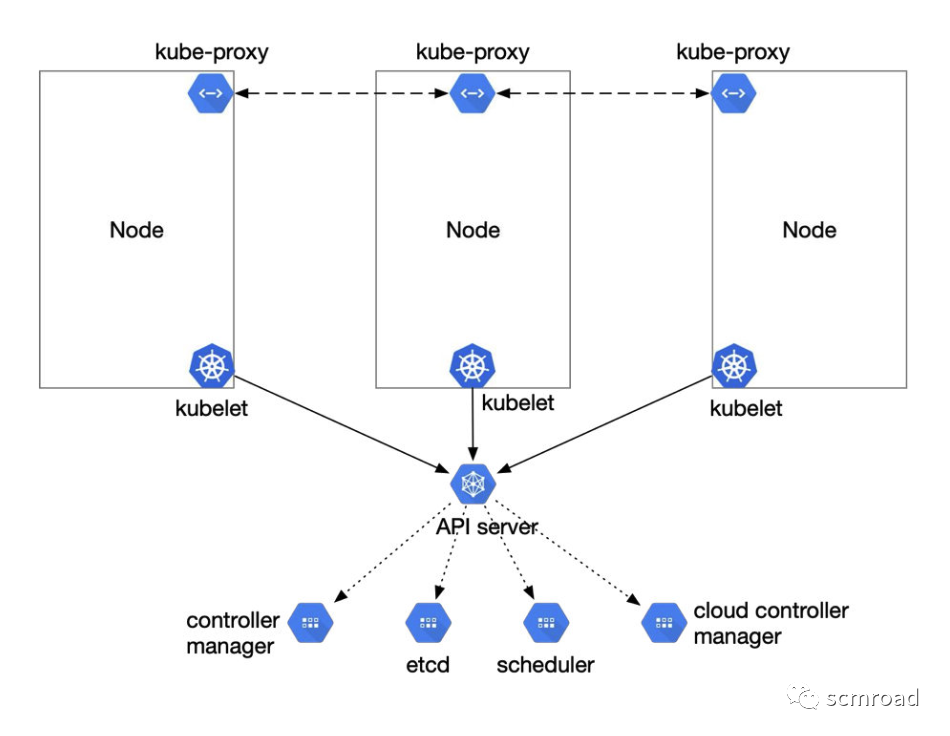
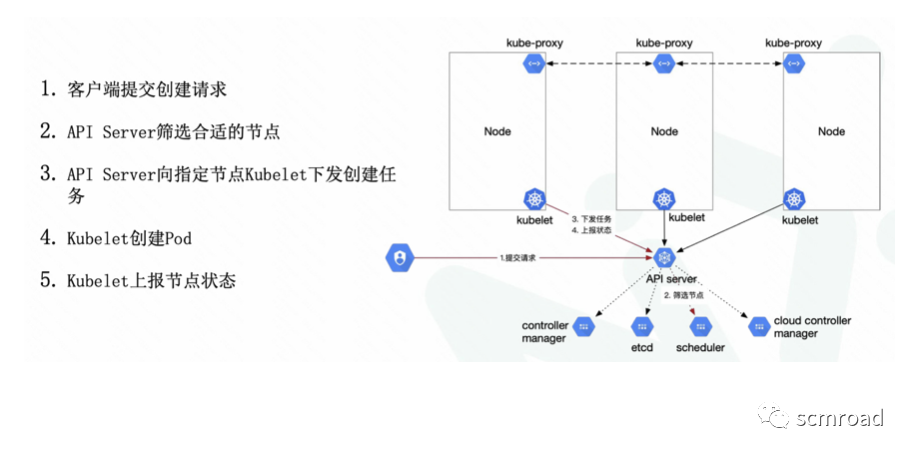
- API Server 核心组件。对外公开 Kubernetes API;
- Etcd 持久化所有的数据内容;
- Scheduler 负责监视新创建的、未指定运行节点(node)的 Pods,选择Pod运行节点;
- Controller-Manager 管理所有的控制器;
- Kubelet 每个Node上运行的代理,保证容器运行在指定节点中;
2. K8s服务编排 2.1 k8s编排思想概念
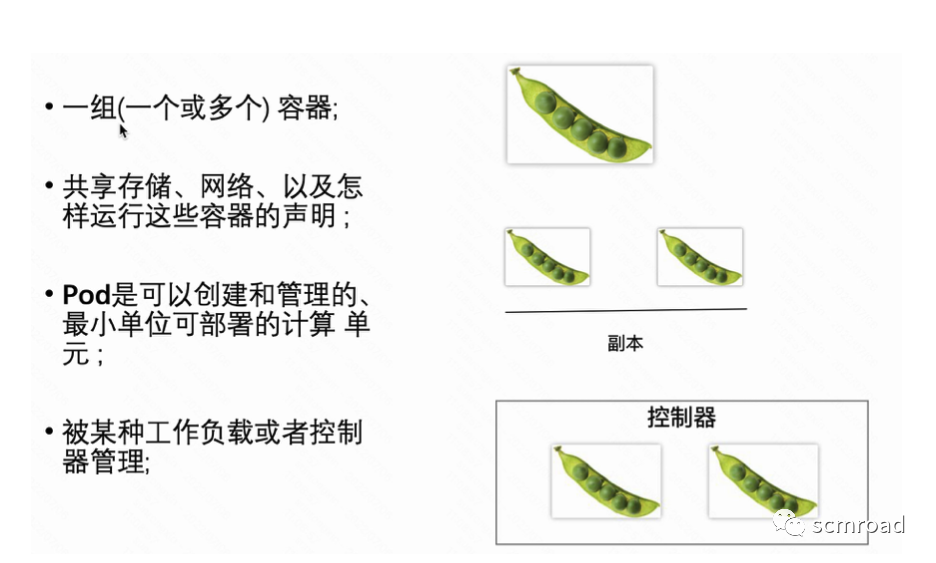
Pod,是 Kubernetes 项目中最小的 API 对象。Kubernetes 项目的原子调度单位。
容器本质是线程,那么K8s管理容器就对应着操作系统,在OS中管理线程是以线程组的形式存在,因此通过Pod的对象将进程组的概念映射到容器的世界里。
- Pod里的容器作为一个整体进行调度。
- Pod它只是一个逻辑概念
- Pod 里面的所有容器,共享的是同一个 Network Namespace
- 并且可以声明共享同一个Volume。
可是对于容器来说,一个容器永远只能管理一个进程。更确切地说,一个容器,就是一个进程。这是容器技术的“天性”,不可能被修改。所以,将一个原本运行在虚拟机里的应用,“无缝迁移”到容器中的想法,实际上跟容器的本质是相悖的。
工作负载/控制器类型
- Deployment 集群上的无状态应用, 是保证其管理的Pod数量永远符合用户的期望(最常用);
- StatefulSet 通过一个或者多个以某种方式 跟踪状态的应用,用于有状态应用;
- Daemonset 本地节点常驻运行的应用;
- Job/CronJob 定时创建可以一直运行到结束 并停止的无状态应用(可以用于CICD任务,或者大数据计算任务);
此外:
- Services 一组相同Pods构成的网络组;
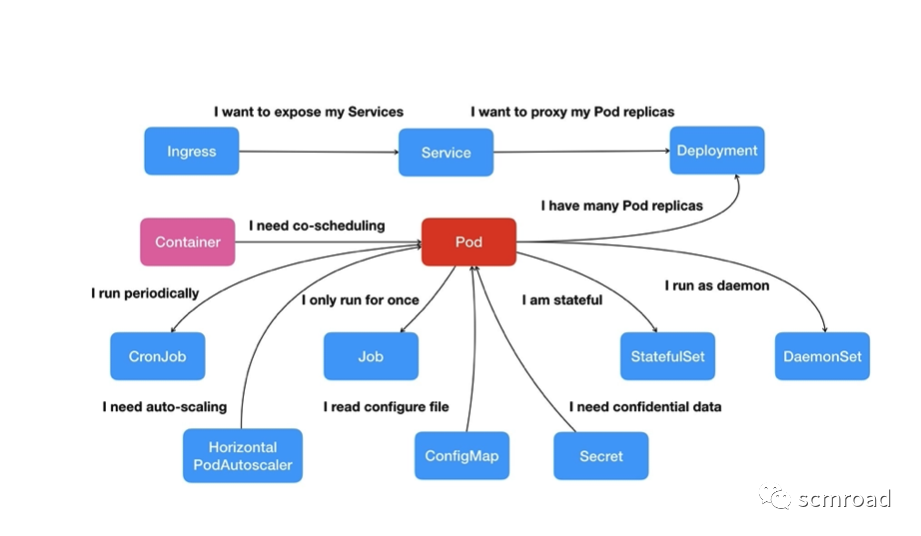
服务编排通俗地说就是将一个服务在合适的时间放在一个合适的地方,让其按照规划的方式运行。
- 合适的时间:当实际服务状态和预期状态不相符的时候;
- 合适的地方:资源最充足的地方;
- 规划的方式:满足用户的需求;
2.3 K8s 控制器工作原理
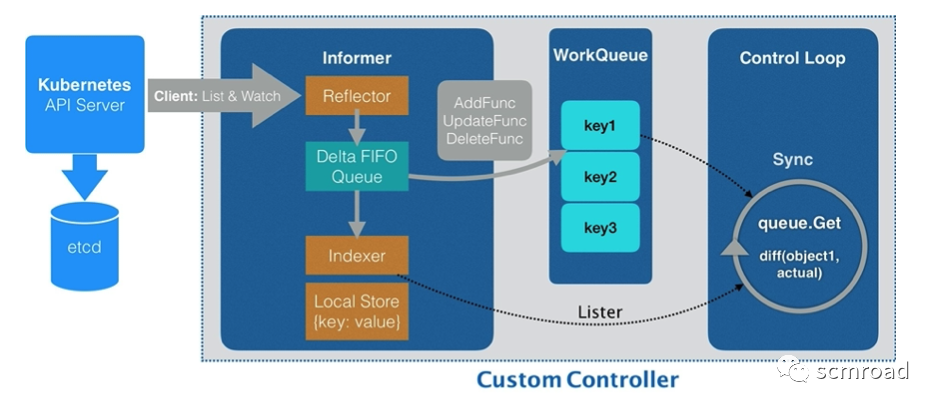
- Informer 通过一种叫作 ListAndWatch 的方法,把 APIServer 中的 API 对象缓存在了本地,并负责更新和维护这个缓存。
- ListAndWatch 方法的含义是:
首先,通过 APIServer 的 LIST API“获取”所有最新版本的 API 对象;
然后,再通过 WATCH API 来“监听”所有这些 API 对象的变化。
Informer 就可以实时地更新本地缓存,并且调用这些事件对应的 EventHandler 了。List&Watch关键设计:
- 基于chunk的消息通知;
- 本地缓存 & 本地索引 ;
- 无界队列 & 事件去重;
- 基于
- 观察者
- 模式
性能瓶颈
API资源对象在ETCD里面是以JSON格式来存储的,而K8S的API对象是以protobuf格式存储,在资源对象数量多的时候JSON的序列化和反序列化性能会成为瓶颈。
3. K8s集群落地实践建议
单集群(可用区)规模(NC数量):
- K8s 500以下;
- OpenStack 5000以下;
- 自研 5000以上;
3.1 网络&隔离
- 提前规划集群Pod网段(k8s要求所有节点网络互通,而pod网络通信的网段是初始化配置,后期修改很麻烦);
- 使用 Namespace 隔离应用(比如按照业务线隔离) ,并尽可能早引入混沌工程(全流程故障演练);
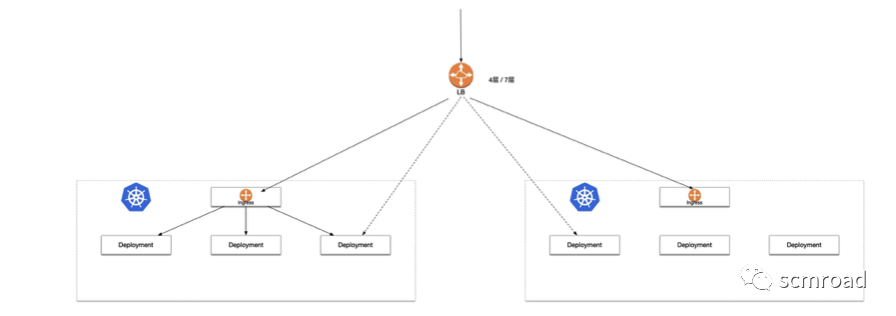
- 自建网关VS Ingress
- 自建网关 适合多集群,多可用区场景
- Ingress 适合单集群场景
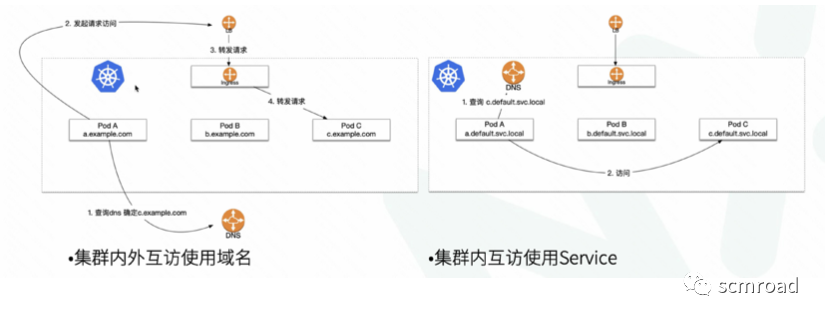
- 域名 VS Service Name
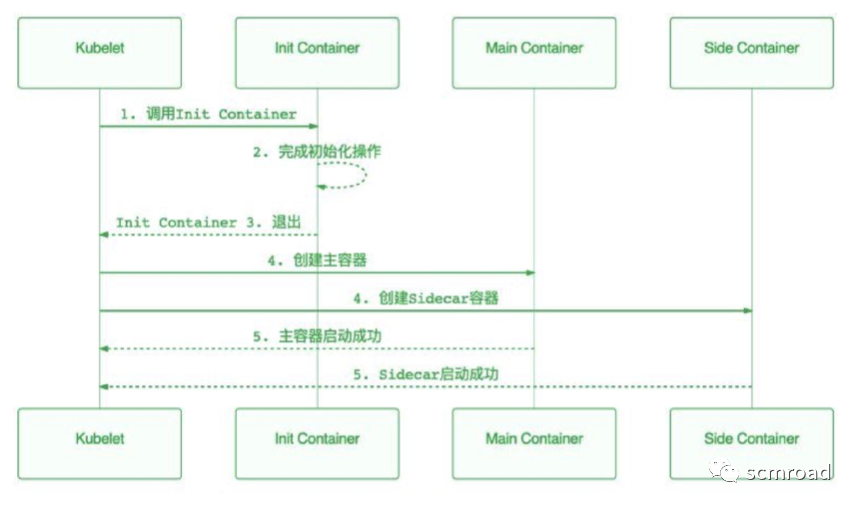
3.2 SideCar
- SideCar 只设置辅助类的工具
- SideCar 不要用于Init初始化
3.3 高可用
- 单集群高可用是基础,然后在规划多可用区
- K8s ON K8s 实现“自托举”,增加水平扩展性;
4. K8s&CICD

Kubernetes 这种声明式配置尤其适合 CI/CD 流程,况且现在还有如 Helm、Draft、Spinnaker、Skaffold 等开源工具可以帮助我们发布 Kuberentes 应用。
4.1 k8s 上的 Pipeline
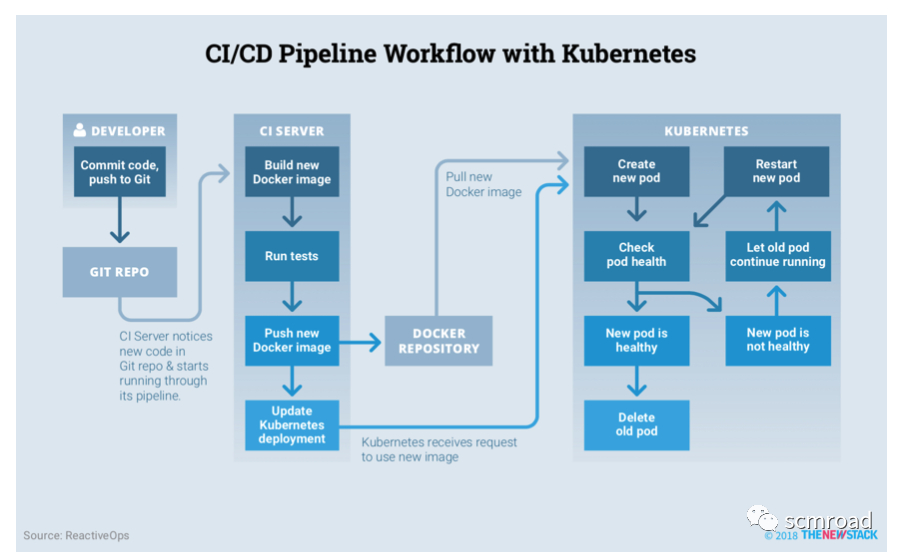
技术选项:
- Git Repo: gitlab
- CICD Server : Jenkins&各种插件
- k8s相关
Kubernetes :: Pipeline :: DevOps Steps
Kubernetes CLI Plugin
Kubernetes plugin
Kubernetes Credentials Plugin
- gitlab相关
GitLab Plugin
Generic Webhook Trigger Plugin
- Docker Registry : Harbor
- K8s可视化管理:kuboard
实战范例参考
https://juejin.cn/post/6963466680613896206
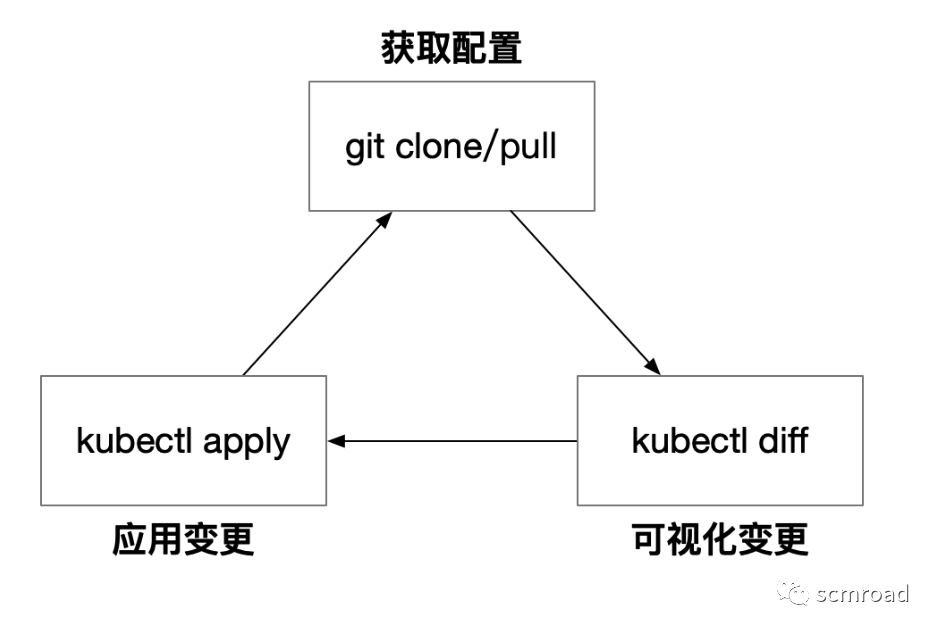
4.2 GitOps
GitOps 是一套使用 Git 来管理基础设施和应用配置的实践。对于 Kubernetes 来说,这意味着任何 GitOps 操作者都需要依次自动完成以下步骤:
- 通过克隆或拉取更新 Git 仓库(如 GitHub、GitLab),从 Git 中检索最新的配置清单
- 使用 kubectl diff 将 Git 配置清单与 Kubernetes 集群中的实时资源进行比较
- 最后,使用 kubectl apply 将更改推送到 Kubernetes 集群中
4.3 CICD实战建议
在 Kubernetes中发布应用时,需要注意的内容总结概括为以下8条 :
- 不要直接部署裸的Pod,为工作负载选择合适的 Controller
- 使用 Init 容器确保应用程序被正确初始化
- 在应用程序工作负载启动之前先启动 service
- 使用 Deployment history来回滚到历史版本
- 使用 ConfigMap 和 Secret 来存储配置
- 在 Pod 里增加 Readiness 和 Liveness 探针
- 给 Pod 设置 CPU 和内存资源限额 Limit / Request
- 定义多个 namespace 来限制默认 service 范围的可视性。