链家二手房源数据深度采集
这部分的实践是基于上一个博客获得的数据,具体的参考网址如下:
爬虫逻辑 :【提取mongo里面的具体网页的链接】–> 【设置动态ip】–> 【获取详细信息】
函数式编程:
函数1:url_extract(database,table,field) → 【数据网页url提取】函数
database:数据库
table:源数据mongo集合对象
field:url字段
函数2:get_data(ui,d_h,ips,table) → 【数据采集及mongo入库】函数
ui:数据信息网页
d_h:user-agent信息
ips:代理设置
table:mongo集合对象
前期准备并封装第一个函数
上一个博客已经完成了分页中各个列表里面标题所对应的url(链接)采集,这里只需要加载一下即可
import requests
import time
from bs4 import BeautifulSoup
import pymongo
if __name__ == '__main__':
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
db = myclient['链家二手房_1']
datatable = db['data_1']
print(dlst)
print(dlst[0])
输出结果为:(dlst是一个可以迭代的对象,这里取出第一个元素示例)

3) 封装第一个函数
'''【数据网页url提取】函数
database:数据库
table:源数据mongo集合对象
field:url字段
'''
dlst = table.find()
lst = []
for item in dlst:
lst.append(item[field])
return lst
urllst = url_extract(db,datatable,'链接')[:10]
print(urllst)
输出结果为:(网页均可以打开)
[‘https://bj.lianjia.com/ershoufang/101106641912.html’, ‘https://bj.lianjia.com/ershoufang/101106120874.html’,
‘https://bj.lianjia.com/ershoufang/101106506136.html’, ‘https://bj.lianjia.com/ershoufang/101106369778.html’,
‘https://bj.lianjia.com/ershoufang/101106678537.html’, ‘https://bj.lianjia.com/ershoufang/101106148748.html’,
‘https://bj.lianjia.com/ershoufang/101106628849.html’, ‘https://bj.lianjia.com/ershoufang/101104451607.html’,
‘https://bj.lianjia.com/ershoufang/101104041998.html’, ‘https://bj.lianjia.com/ershoufang/101106586759.html’]
数据标签定位
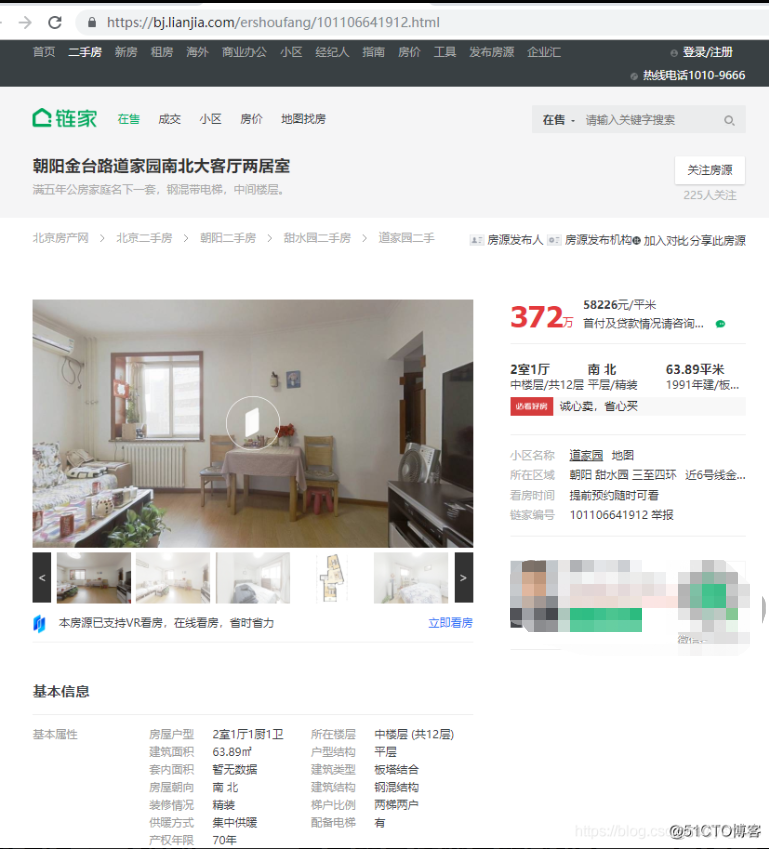
由于前一个博文已经测试了网址可以进行正常的数据请求响应,这里就不再进行测试了,以某一页面为例,进行试错,直接确定采集的字段(标题可以直接通h1获取),如下
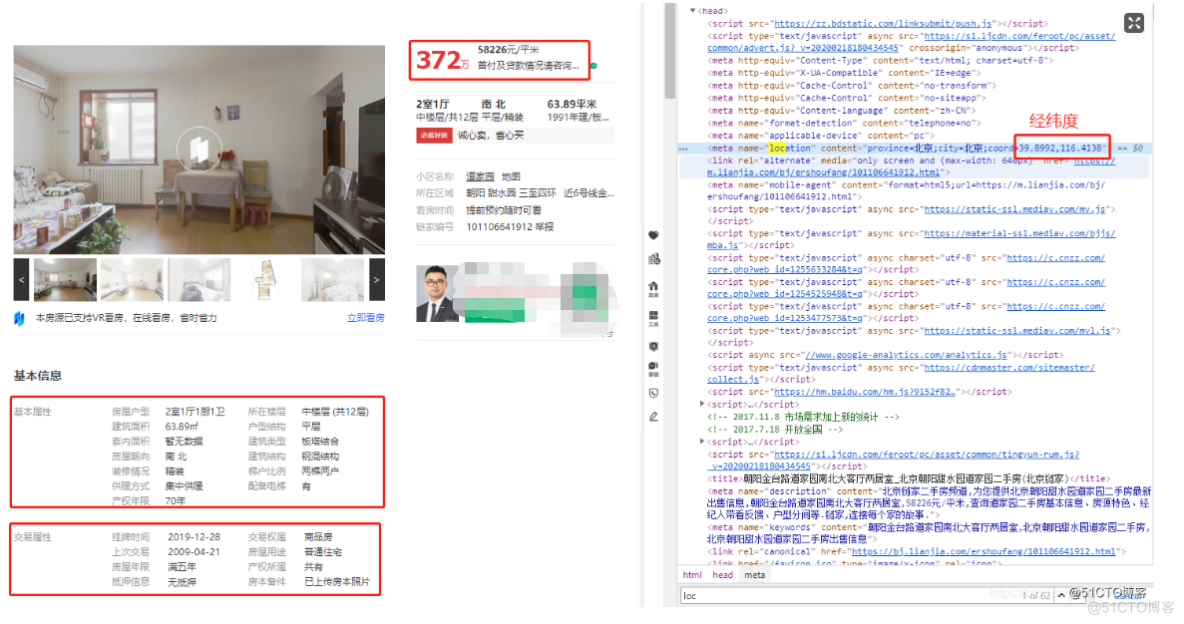



这里可以通过网页里面的出现的位置,然后复制到坐标拾取器里面,查看经纬度,然后复制经度的前面的数字,在源代码(不是检查页面)中找到相应的位置


获取标签中的内容数据
这里还是以该页面为例,获取里面标签的对应内容,进行试错
urllst = url_extract(db,datatable,'链接')[:10]u = urllst[0]
r = requests.get(u,headers = dic_headers, cookies = dic_cookies)
soup = BeautifulSoup(r.text, 'lxml')
dic = {}
dic['标题'] = soup.h1.text
price = soup.find('div', class_="price").text
dic['总价_万'] = re.search(r'(\d+)万', price).group(1)
dic['单价_元'] = re.search(r'(\d+)元', price).group(1)
base_info = soup.find('div', class_="base").find('ul').find_all('li')
for li in base_info:
st = re.split(r'<.*?>',str(li))
dic[st[2]] = st[3]
transaction_info = soup.find('div', class_="transaction").find('ul').find_all('li')
for li in transaction_info:
st = re.split(r'<.*?>',str(li))
dic[st[2]] = st[4].replace('\n','').replace(' ','')
loc = re.search(r"resblockPosition:'([\d.]+),([\d.]+)'",r.text)
dic['lng'] = loc.group(1)
dic['lat'] = loc.group(2)
print(dic)
输出的结果为:

封装第二个函数及输出可视化
关于base_info和transaction_info获取的过程有点难度
def get_data(ui,d_h,d_c,ips,table):''' 【数据采集及mongo入库】函数
ui:数据信息网页
d_h:user-agent信息
ips:代理设置
table:mongo集合对象
'''
r = requests.get(ui,headers = d_h, cookies = d_c)
soup = BeautifulSoup(r.text, 'lxml')
dic = {}
dic['标题'] = soup.h1.text
price = soup.find('div', class_="price").text
dic['总价_万'] = re.search(r'(\d+)万', price).group(1)
dic['单价_元'] = re.search(r'(\d+)元', price).group(1)
base_info = soup.find('div', class_="base").find('ul').find_all('li')
for li in base_info:
st = re.split(r'<.*?>',str(li))
dic[st[2]] = st[3]
transaction_info = soup.find('div', class_="transaction").find('ul').find_all('li')
for li in transaction_info:
st = re.split(r'<.*?>',str(li))
dic[st[2]] = st[4].replace('\n','').replace(' ','')
loc = re.search(r"resblockPosition:'([\d.]+),([\d.]+)'",r.text)
dic['lng'] = loc.group(1)
dic['lat'] = loc.group(2)
table.insert_one(dic)
最后的可视化代码如下
urllst = url_extract(db,datatable,'链接')[:100]errorlst = []
count = 1
for u in urllst:
print("程序正在休息......")
time.sleep(5)
try:
get_data(u,dic_headers,dic_cookies,'a', datatable2)
print(f'成功采集{count}条数据')
count += 1
except:
errorlst.append(u)
print('数据采集失败,网址为:',u)
输出结果:

数据库中的数据
