本文内将主要介绍Celery的相关知识点,其中会涉及到其架构原理、重要功能讲解、相关配置以及使用技巧等。本文适合的阅读人群为在使用编写项目的主语言为Python且需要快速实现异步架构的开发者。笔者也会将自己的理解在文中进行阐述,这也算是在和大家交流心得的一个过程。若文中有错误的理解和概念,请大家及时纠正;吸纳大家的建议,对于我来说也是很重要的学习过程之一。
1. 架构
Celery是基于Python开发的一个分布式任务队列框架,支持使用任务队列的方式在分布的机器/进程/线程上执行任务调度。
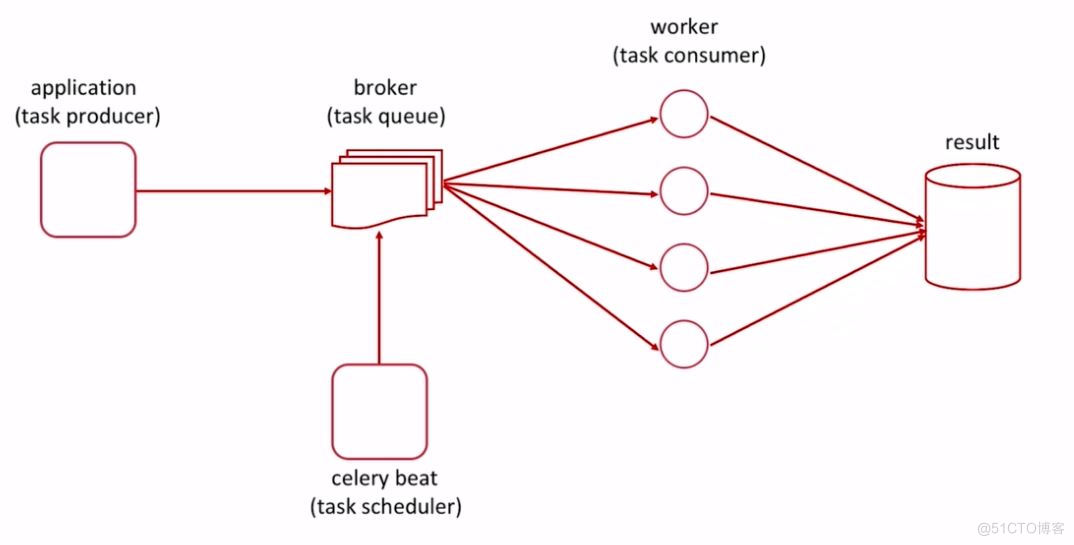
其中,Celery的任务队列支持使用多种介质来实现,例如Redis, RabbitMQ和Amazon SQS等。通过使用其自带的任务调度器还可快速实现定时任务推送的功能。
Tips: Celery本质是一个任务队列框架,而非消息队列。虽然Celery和消息队列相同,都能够为项目提供异步处理数据的功能;但两者本质上适用的使用场景是不同的。消息队列除了能够提供异步处理数据的功能外,其还可以做到削峰填谷以及工程解耦。而Celery主要还是为项目提供异步处理任务的功能和易于扩展的分布式任务处理框架。笔者提醒大家一定要注意这一点认知,以便能够更好的、正确的使用Celery。
2. 任务路由
Celery中的任务路由是由Exchange和Queue这两个概念来实现的。
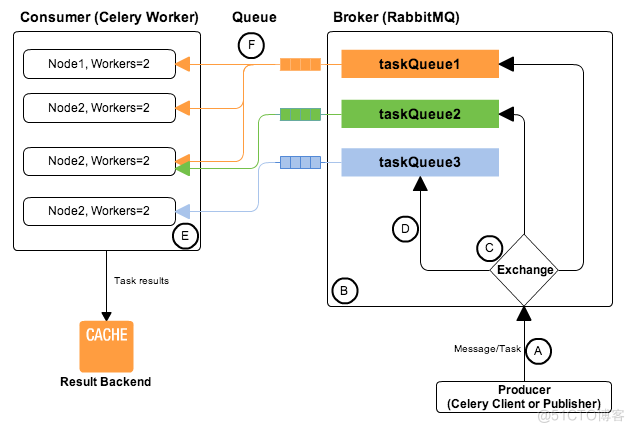
Celery可以在一个Broker上面开辟多个Queue,每个Queue绑定指定类型的任务;对应的Worker通过指定的队列获取任务;Exchange用来决定哪些任务发送到哪些Queue中。Celery结合了上述的这些功能从而实现了任务路由。本章节将会对于这两个概念展开介绍。
Tips: 这里需要注意一点的是,Celery中传递的是任务(Task),而非消息。任务(Task)中会描述该任务所使用的方法(代码),方法的入参等等。即任务发布方在发布任务之前,是需要清楚Task的调用细节的(至少要知道方法名以及入参规则)。这区别于消息队列的一点,消息队列中传递的是消息(可以理解为传送的方法的入参,而并没有指定处理的逻辑)。、
2.1 Exchange
发布的任务首先会经过Exchange。Exchange会根据设定条件将任务路由到不同的Queue中。不同类型的Exchange有着不同的路由规则。Exchange的类型有如下几类:
在一个架构中,可以包含多个Exchange,每一个Exchange管理着不同的Queue与Worker(即真正执行Task逻辑的对象)。
2.2 Queue
当确定好Exchange的类型后,还需要创建所需的Queue,并将Queue绑定到相应的Exchange上。因此,在定义Queue的同时,还需要定义Queue与Exchange的绑定关系。定义Queue的配置如下所示:
CELERY_QUEUES = { Queue('queue01',Exchange('ex01',type='topic'), routing_key='*.task.*'), Queue('queue02', Exchange('ex01',type='topic'), routing_key='*.*.email'), Queue('queue03', Exchange('ex01',type='topic'), routing_key='*.add') }其中,Exchange('ex01',type='topic')表示定义了一个名为ex01的Exchange,其类型为Topic Exchange。其次,Queue('queue01',Exchange('ex01',type='topic'), routing_key='.task.')表示定义了一个名叫queue01的队列,该列队绑定在了Exchange ex01上,并且只有当Routing key满足通配公式.task.时,ex01才会将任务转发到queue01中。
Tips: Exchange的定义是包含在Queue的定义当中的。
为了系统可靠性,还可以配置默认的Queue,Exchange以及Routing key;以保证任务必定会被处理。其相关的配置项如下:
default_exchange = Exchange('default', type='topic') app.conf.task_default_queue = 'Lost' app.conf.task_default_exchange = 'default' app.conf.task_default_routing_key = 'lost'上述给出的示例,使用的是编码形式的配置方式。Celery同时还支持使用配置文件的方式进行配置,这里笔者也给出该种方式的Exchange与Queue的定义细节:
# Queues and Route Config task_default_exchange = "tsmp_topic_exchange" task_default_exchange_type = "topic" task_default_queue = "Lost" task_default_routing_key = "lost" task_queues = { "Alert": { "exchange": "tsmp_topic_exchange", "exchange_type": "topic", "routing_key": "alert" }, "Email": { "exchange": "tsmp_topic_exchange", "exchange_type": "topic", "routing_key": "email" } }使用配置文件的方式进行定义,往往能够满足那些需要统一声明,统一配置的需求场景。
3. 任务
在Celery中,由于传递的是任务(Task);因此构造Task便成为了Celery的另一大重点。本章节中会介绍Task的一些相关概念以及编写技巧。
3.1 任务注册
当Task方法实现后,需要使用app.task()装饰器来装饰Task方法。app.task()装饰器负责在应用任务注册表中注册你的任务。当任务被发送时,没有实际函数的代码被发送,只是将要执行任务对应的方法名称以及参数发送到Broker。当Worker收到消息时,它会在任务注册表中查找任务名称并使用指定参数执行相关方法。因此,任务发布者和Worker都应该有完整的Task源码。如果代码需要更新,则两者的源码都应同步更新。
Tips:
3.2 自定义Task类
在Celery内部,是将Task看作为一个对象。即Celery实际上对Task这一概念进行了抽象。当多数任务都有着类似的内部逻辑时,或任务中逻辑过于复杂时;此时可以考虑将Task的内容封装到一个Task类中。之后,将自定义Task类作为app.task()装饰器中base的参数值后,就可以在Task的相应方法中调用自定义Task类中的方法了。例如:
from celery.utils.log import get_task_logger from cdm_celery import celery_config from cdm_celery.celery import app from cdm_celery.task.base.dns import CloudDomainServiceConsumer from factory.route53 import Route53Factory logger = get_task_logger(__name__) @app.task(base=CloudDomainServiceConsumer, bind=True, retry_backoff=True) def create_route53_record(self, type='', domain='', records=[]): factory = Route53Factory( access_key=celery_config.route53['access_key'], secret_access_key=celery_config.route53['secret_access_key'], domain=domain ) self.set_factory(factory) self.set_service_name('Route53') self.set_action_type('添加DNS记录') task_result = self.create_record(type, domain, records) # 调用自定义Task类方法 return task_result除了将自身的业务需求封装在自定义Task类中,还可以重写一些celery.Task类本身的方法逻辑。例如通过重写<br/>on_success、on_failure以及on_retry这3个方法可以实现Task的回调接口。例如:
from celery import Task class CloudDomainServiceConsumer(Task): def on_success(self, retval, task_id, args, kwargs): """任务执行成功回调方法 """ logger.info(log_msg_to_json_str( msg='执行成功', data={'args': args, 'kwargs': kwargs}, celery_task_id=task_id )) self.alert(data=retval) # 发送通知邮件 def on_failure(self, exc, task_id, args, kwargs, einfo): """任务执行失败回调方法 """ logger.error(log_msg_to_json_str( msg='执行失败;exc_type:{0};exc_details:{1};celery_info:{2}'.format( type(exc), exc, einfo, ), data={'args': args, 'kwargs': kwargs}, celery_task_id=task_id )) # 发送通知邮件 retval = { 'action_type': self.get_action_type(), 'service': self.get_service_name(), 'status': '添加失败', 'query_params': str(exc) } self.alert(data=retval) def on_retry(self, exc, task_id, args, kwargs, einfo): """任务重试回调方法 """ logger.warning(log_msg_to_json_str( msg='重试;exc_type:{0};exc_details:{1};celery_info:{2}'.format( type(exc), exc, einfo, ), data={'args': args, 'kwargs': kwargs}, celery_task_id=task_id ))Tips: 自定义的Task类必须继承celery.Task类或其子类。
3.3 幂等性
Task的幂等性是需要开发者自己实现的,Celery是无法检测Task逻辑是否是幂等的。为了保证异步数据一致性,往往都需要我们将Task实现为支持幂等性的。
3.4 Task函数
之前的章节提到过,如果需要将指定Task注册到Celery队列中,需要使用app.task()装饰器来装饰Task方法。这其实也是将普通函数声明为Celery Task的方法。通过3.2章节的介绍,我们得知Celery将Task抽象为类对象,因此celery.Task类的实例属性和方法是可以在Task方法中使用的。只需要将装饰器方法中bind参数定义为True;之后就可以在Task方法中调用app.Task.request的属性和方法了。被装饰的Task方法第一个参数必须是self。该self为celery.app.task对象的实例,此时若自定义了Task类,则该self所指的就是自定义Task类的对象实例。
3.5 日志
Celery使用的也是Python的标准logging模块;因此具体的配置与使用配置logging模块大致相同。不同只是在配置入口时,需要使用相应的装饰器来获取Celery的logger对象。这里介绍一些关于自定义Celery日志的方法。
@celery.signals.setup_logging.connectdef on_setup_logging(**kwargs):pass
2. 自定义celery自身日志(非task日志) 使用装饰器@celery.signals.after_setup_logger.connect装饰自定义日志格式方法。 3. 自定义Task日志 使用装饰器@celery.signals.after_setup_task_logger.connect装饰自定义日志格式方法。 ```python import celery @celery.signals.after_setup_task_logger.connect def on_after_setup_task_logger(logger, *args, **kwargs): logger.setLevel(logging.INFO) set_logger_file_handler(os.path.join(BASE_DIR, 'log/celery/task/info.log'), custom_logger=logger, level=logging.INFO) set_logger_file_handler(os.path.join(BASE_DIR, 'log/celery/task/error.log'), custom_logger=logger, level=logging.ERROR) set_logger_file_handler(os.path.join(BASE_DIR, 'log/celery/task/warning.log'), custom_logger=logger, level=logging.WARNING)对于Celery日志的自定义,笔者有一些实践经验想分享给大家。由于Celery是一个异步任务框架,因此正常情况下会有多个Worker来并行处理任务。由于Python的logging模块对于多进程打印日志支持的不好,因此如果多个Worker往同一批日志文件中输出日志(仅针对单台服务器上启动多个Worker的情况),则会导致日志输出混乱。此时好的做法是为每一个Worker建立起独立的日志文件,例如可以使用Worker名称或进程号来命名等。命名时可以使用统一的命名前缀或后缀,这样也方便与后期的日志采集工作。
3.6 任务重试
任务重试有两种定义方式:
3.7 实时获取Task状态
- 对于获取Task状态,这里提供一个思路供大家参考:
1.将装饰器方法中bind参数定义为True。2.编写处理回调消息的逻辑方法3.启动任务4.调用任务的对象的get方法,其中on_message参数指定为自定义的消息回调处理方法;get方法的返回值即为当前任务的状态。可以配合while+sleep来不间断的判断任务的执行状态。
3.8 相关配置
在编写完相应的Task后,还需要配置如下一些配置才可以进行使用:
3.9 任务调用链
一般,我们都会将所需的业务逻辑或计算任务封装到Task中。当一个任务过于繁杂时,可能需要将其拆分为多个子任务。往往,这些子任务还存在一定的执行顺序。面对这个需求时,可以通过Task调用Task的方式,来将这些子任务串连起来,达到顺序执行的效果。这里笔者提供一个曾经实现过的思路,供大家学习和思考。通过结合上述的任务调用链和反射概念,可以实现动态配置任务调用链的功能。即在无需更改原代码的情况下可以快速在链中增加,修改或删除任务。
3.9.1 反射
通过反射操作,可以实现动态加载Task的功能,这为后续维护任务增加了很大的便利性。其实现的思路如下:
首先,在一些全局的配置中建立反射任务队列
alert_actions = [ 'cdm_celery.task.email.tasks.send_email', 'cdm_celery.task.qywx.tasks.qywx_alert' ]def modules_extract(module_names=None):if not isinstance(module_names, Iterable):raise ValueError("需要提供包含了模块全路径名称字符串的可迭代对象")
for m in module_names: obj = CloudDomainServiceConsumer.module_extract(m) yield obj ### 3.9.2 Task调用Task 在相关的逻辑中加载反射任务队列和调用反射逻辑。同时,`通过使用Celery Task signature的概念来调用相关Task`即可。 ```python def alert(self, data=None): for alert_task in CloudDomainServiceConsumer.modules_extract(alert_actions): alert_task.signature( (), data, exchange=app.conf.task_queues['Alert']['exchange'], routing_key=app.conf.task_queues['Alert']['routing_key'] ).apply_async()4. 配置
对于Celery的使用配置,笔者在这里想提醒大家注意一点: 4.0版本以后启用了新的小写的配置项名称。配置文件中不能同时出现老版本的CELERY开头大写和新的小写配置项名,建议统一使用新的小写配置项名。
5. 小彩蛋
这里之所以说是彩蛋,是因为这个章节所介绍的不是Celery的相关知识点。只是笔者在日常工作和学习中偶然碰到的与Celery相关的一个知识点,觉得很有意思,想给大家分享一下而已。我们经常会在一些业务或异步任务中添加重试机制的相关逻辑,业界使用最多的重试机制实现方式为指数退避算法。这里先对指数退避算法做一个简单的介绍:
在以太网中,该算法通常用于冲突后的调度重传。根据时隙和重传尝试次数来决定延迟重传。在 c 次碰撞后(比如请求失败),会选择 0 和 $2^c-1$ 之间的随机值作为时隙的数量。
- 对于第 1 次碰撞来说,每个发送者将会等待 0 或 1 个时隙进行发送。
- 而在第 2 次碰撞后,发送者将会等待 0 到 3( 由 $2^2-1$ 计算得到)个时隙进行发送。
- 而在第 3 次碰撞后,发送者将会等待 0 到 7( 由 $2^3-1$ 计算得到)个时隙进行发送。
- 以此类推……
随着重传次数的增加,延迟的程度也会指数增长。说的通俗点,每次重试的时间间隔都是上一次的两倍。注意: 每次延长的是时间区间的最大值,并且每次的真正需要等待的时间是随机从时间区间中取出的。
恰巧,在Celery中有指数退避算法的相关实现(celery/utils/time.py中):
def get_exponential_backoff_interval( factor, retries, maximum, full_jitter=False ): """Calculate the exponential backoff wait time.""" # Will be zero if factor equals 0 countdown = factor * (2 ** retries) # Full jitter according to # https://www.awsarchitectureblog.com/2015/03/backoff.html if full_jitter: countdown = random.randrange(countdown + 1) # Adjust according to maximum wait time and account for negative values. return max(0, min(maximum, countdown))大家可以模仿上述的代码来实现自需的指数退避算法。