5.判断字符串操作 1.isidentifier():判断指定的字符串是不是合法的标识符(字母数字下划线) 2.isspace():判断是否全部由空白字符组成(回车、换行、水平制表符) 3.isalpha():判断是否全
5.判断字符串操作
1.isidentifier():判断指定的字符串是不是合法的标识符(字母数字下划线)
2.isspace():判断是否全部由空白字符组成(回车、换行、水平制表符)
3.isalpha():判断是否全部由字母组成
4.isdecimal():判断是否全部由十进制的数字组成
5.isnumeric():判断是否全部由数字组成
6.isalnum():判断是否全部由字母和数字组成
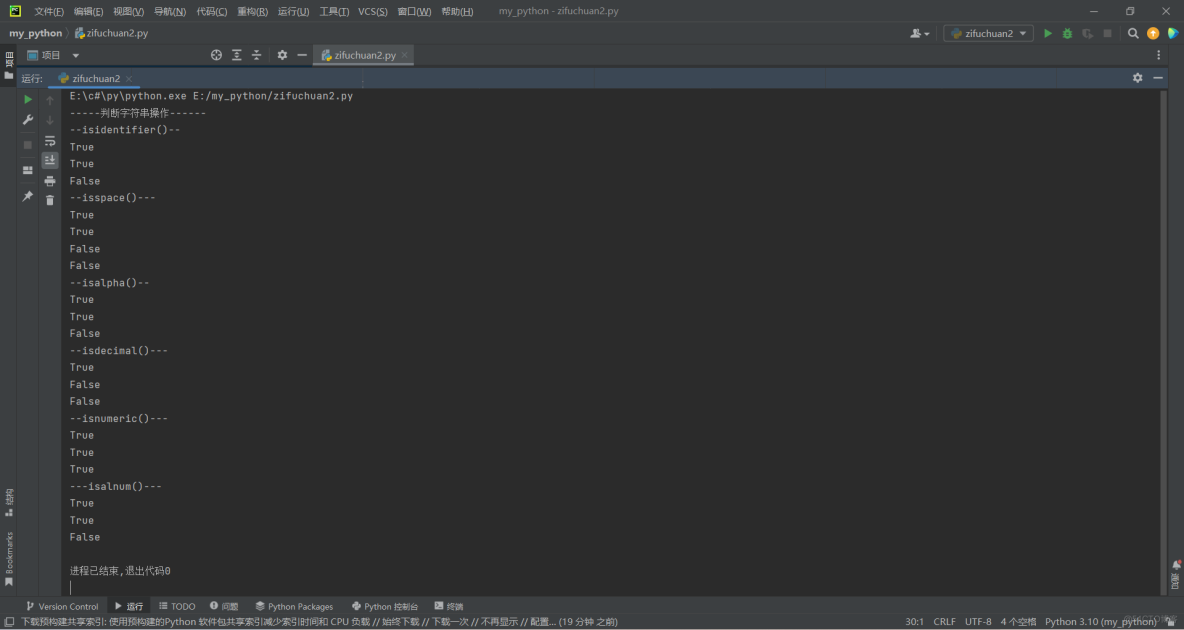
print('-----判断字符串操作------')print('--isidentifier()--')
s = 'helloworld'
print(s.isidentifier()) #True
s = 'kkk_123'
print(s.isidentifier()) #True
s = '%kah'
print(s.isidentifier()) #False,存在%
print('--isspace()---')
s = ' '
print(s.isspace()) #True
s = '\t'
print(s.isspace()) #True
s = ''
print(s.isspace()) #False
s = 'a'
print(s.isspace()) #False
print('--isalpha()--')
s = 'abc'
print(s.isalpha()) #True
s = '张三'
print(s.isalpha()) #True
s = 'abc3'
print(s.isalpha()) #False
print('--isdecimal()---')
s = '123'
print(s.isdecimal()) #True
s = '123四'
print(s.isdecimal()) #False
s = 'ⅡⅡⅡ'
print(s.isdecimal()) #False
print('--isnumeric()---')
s = '652'
print(s.isnumeric()) #True
s = '65二'
print(s.isnumeric()) #True
s = 'ⅡⅡⅡ'
print(s.isnumeric()) #True
print('---isalnum()---')
s = 'abc1'
print(s.isalnum()) #True
s = '张三555'
print(s.isalnum()) #True
s = 'abc!'
print(s.isalnum()) #False
6.字符串替换和合并
1.替换replace()
第一个参数指定被替换的子串,第二个参数指定替换该字串得字符串,该方法返回替换后得到得字符串,替换前的字符串不发生变化,调用该方法时可以通过第三个参数指定最大替换次数
2.合并join()
将列表或元组的字符合并成一个字符串
print('----字符串的替换----')s = 'hellohello'
#其中有两个lo字符串=
s1 = s.replace('lo','kk')
print(s)
print(s1)
#两个hello字符串,替换一个
s2 = s.replace('hello','java',1)
print(s2)
print('---字符串的合并----')
lst = ['p','y','t','h','o','n']
print('1'.join(lst)) #1作为间隔符
print(''.join(lst))

7.字符串的比较操作
1.运算符:>,>=,<,<=,==,!=
2.比较规则
首先比较两个字符串中的第一个字符,如果想等则继续比较下一个字符,一次比较下去,直到两个字符串中的字符不相等,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较;如果两个字符串比较到最后,一个没有比较完毕,另一个没有后续字符串时,前者大于后者,若都没有后续字符串,两者相等。
3.比较原理
两个以上字符进行比较时,比较的是其 ordinal value(原始值),调用内置函数ord()可以得到指定字符的原始值,与内置函数ord()对应的是内置函数chr,调用chr()时指定原始值可以得到其对应的字符
print('----字符串的比较----')print('apple' > 'banana')
print('apple' > 'app')
print(ord('a'),ord('b'))
#a 97 , b 98 , a < b
print(ord('王'))
#王的原始值为29579
print(chr(29579))
#通过原始值得到对应字符
8.字符串的切片操作
字符串是不可变类型,不具备增、删、改等操作,切片操作将产生新的对象
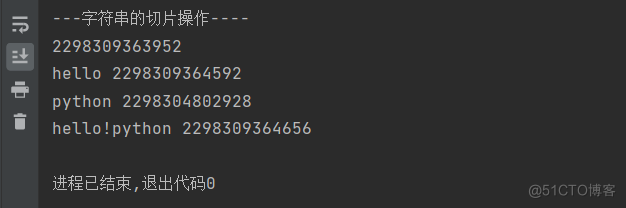
print('---字符串的切片操作----')s = 'hello,python'
print(id(s))
s1 = s[:5]
print(s1,id(s1))
s2 = s[6:]
print(s2,id(s2))
s3 = '!'
newstr = s1+s3+s2
print(newstr,id(newstr))
9.格式化字符串
1.%作占位符:%s->字符串,%i/%d->整数,%f->浮点数
2.{}做占位符
print('--格式化字符串----')name = '张三'
age = 20
print('我叫%s,今年%d岁'%(name,age))
print('我叫{0},今年{1}岁'.format(name,age))
print(f'我叫{name},今年{age}岁')
print('---字符串的宽度与精度---')
print('%10d'%99) #10 表示宽度
print('%.3f'%3.1415926) #.3表示三位小数
print('%10.3f'%3.1415926) #同时表示宽度和精度
print('{0}'.format(3.1415926))
print('{0:.3}'.format(3.1415926))
print('{0:.3f}'.format(3.1415926))
print('{0:10.3f}'.format(3.1415926))

10.字符串的编码转换
str在内存中以Unicode表示,通过编码解码显示在计算机上
编码:将字符串转换为二进制数据
解码:将bytes类型的数据转换成字符串类型
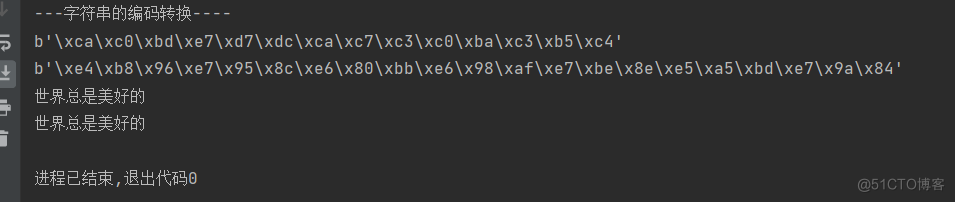
print('---字符串的编码转换----')s = '世界总是美好的'
print(s.encode(encoding='GBK'))
#在GBK这种编码方式中,一个中文占两个字节
print(s.encode(encoding='UTF-8'))
#在UTF-8这种编码方式中,一个中文占三个字节
byte = s.encode(encoding='GBK')
print(byte.decode(encoding='GBK'))
byte = s.encode(encoding='UTF-8')
print(byte.decode(encoding='UTF-8'))