摘要:基于预见性运维,我们利用NetinSide可观测性模块,自定义网络性能传导视图,对某k8s集群进行性能监测,意外的发现了linux内核与容器关系的特别处,并深入分析了namespace在linux内核里的实现机制,为推动潜在问题解决提供了理论基础。
一、网络关键路径性能传导视图
在netinside可观测性模块中,我们基于k8s集群的业务逻辑结构,自定义的建立了以用户体验为中心的网络性能模型,如下图:
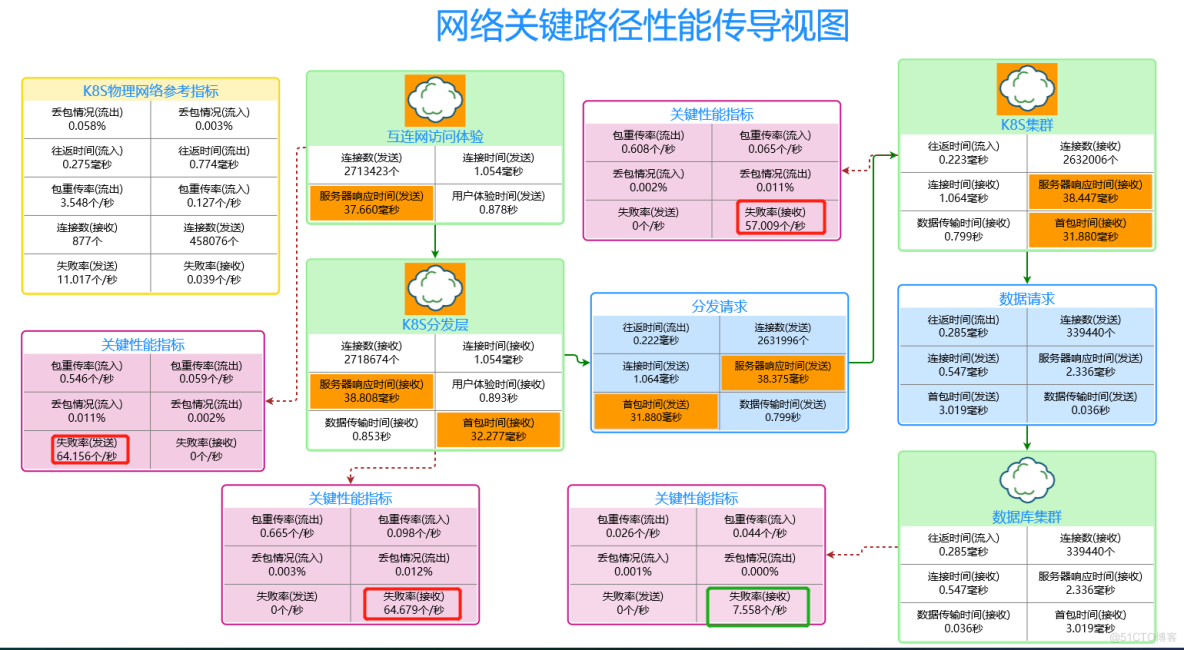
在这个流量模型中,浅绿色为体验传递与消减情况,因为用户的一个服务请求,在内部有多个处理逻辑,前一个逻辑的体验时间,依赖后一个逻辑的处理时间,所以其体验时间,会在多个处理逻辑进行传导,我们称之为性能传导视图,浅蓝色部分为处理逻辑向外请求的数据,浅红色则为处理逻辑中影响性能的关键指标。
二、发现问题
视图构建完成之后,竟然出现了橙色体验告警色块,这与我们的想象中的预期不符。在此之前,k8s集群一直是稳定运行,服务器接入也是全千M,基于我们对比业务和流量的了解,纯千的接入完全够用,且传统意义上的监控,也没有出现任何异常,所以出现个近40MS的服务器响应延迟,让我们有点惊讶。
继续看视图,我们发现这个橙色体验告警色块到数据库集群时就没有了,可以初步判断问题的关键在于k8s集群。而k8s存在SDN网络,所以是SDN网络问题,还是物理网络问题,我们得区分出来,所以我们把k8s物理网络的性能指标也构建出来做为比较,结果问题还是指向k8s的SDN网络上,结合k8s集群SDN网络里面的关键性能指标,发现TCP的连接失败率还挺高的,由此其实已经可以判断,问题点,应该还是在k8s集群里面。
基于现有分析,我们决定先解决连接失败问题,因为这个问题与响应延迟是同一类型的问题,只是问题表现的程度不同。但面对这个问题的时候,让我们不得不面对一个让我们有点无语的问题。我们知道,TCP连接的建立是由linux内核完成的,而无论是容器也好,k8s的SDN也好,服务器的物理网络也好,对于k8s集群而言,其实都是在同一个内核上!也就是说,同一个人,干的同样的活,为什么表现的情况是不一样的?
三、分析问题
按下疑问,我们先对问题本身进行一些分析。
TCP连接的建立与维护是由linux内核完成的,所以,影响TCP连接失败的,通常有三种情况:
- 1,半连接及全连接队列溢出;
- 2,因时间戳而丢弃的;
- 3,程序异常;
程序异常暂时本次不考虑,因为这种情况多半都是百分百连接失败,也比较好识别,我们将把这种情况单独抽出来做另案处理。
而第一种情况的也有三种可能:
- 1,并发连接太多;
- 2,队列太小;
- 3,程序处理太慢;
基于本次问题的实际情况,处理起来比较快的,还是队列大小问题,经过核查,队列确实太小,都是默认值没有做优化。队列太小只要优化一下内核参数就可以,但怎么处理就又回到了刚才的问题:优化linux内核对容器里面的应用有效吗?
四、深入linux内核分析
我们知道,容器里进程本身也是宿主机上的一个进程,只是通过namesapce(命名空间)进行隔离了,本质上也使用的是同一个内核,与宿主上的进程没有什么区别。那么对宿主机的内核化是否就会影响到容器里面?为回答这个问题,我们需要了解namespace在内核中是如何实现的。
既然都是进程 ,我们就从进程开始。在linux内核里面,对进程的处理及调度,都是通过task_struct这个结构体,所有与进程相关的信息,都在这个结构体里面,我们在这个里面找找关于namespace相关的内容:
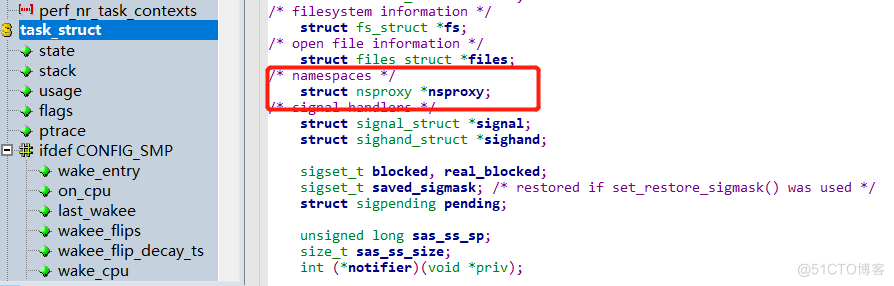
与namespaces相关的结构体是nsproxy,我们接着看这个结构体面有什么:
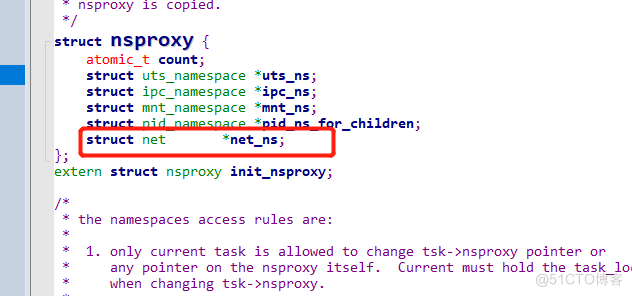
namespaces命名空间有5个,都在这个结构体里面,我们主要是看关于网络的,所以接着找net:
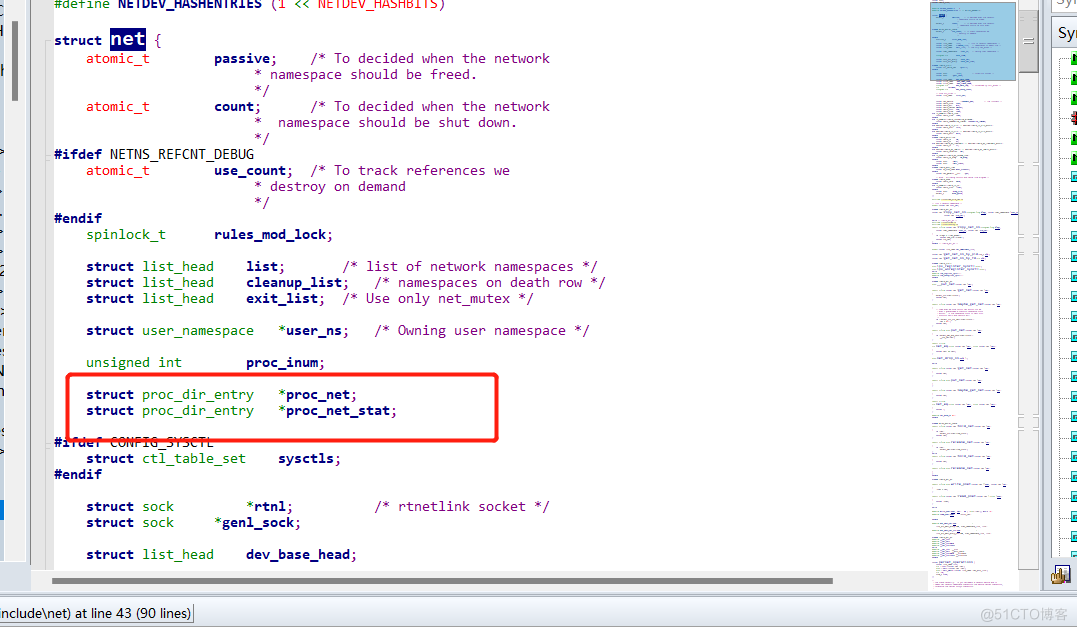
到这里我们看到了一个关键目录:proc_net,其实就是proc目录,我们可以看下他初始化的代码:
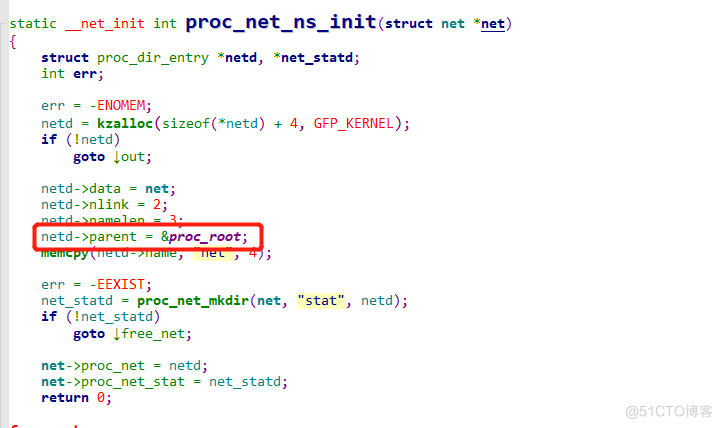
可以确认,proc_net初始化的时候,就是加载的proc根目录, 而proc这个目录是一个虚拟的文件系统, 它不存在于磁盘上, 而是存在于系统内存中。proc以文件系统的方式为访问系统内核的操作提供接口,且内核及进程运行时候的所有信息,都放在这里面。换句话说,我们对内核的优化,其实就是操作这个目录里面的文件。那么宿主上的proc目录与容器里面的proc目录是不是同一个呢?可惜,不是同一个,因为这个目录是动态从系统内核读出所需信息的,而namespaces又在内核及进程上命名隔离,所以信息不一样。
五、验证
无论理论研究的怎么样,都要实际验证一下我们的理解对不对。我们先在宿主上拿一个全连接队列优化的参数somaxconn来验证,如下图:
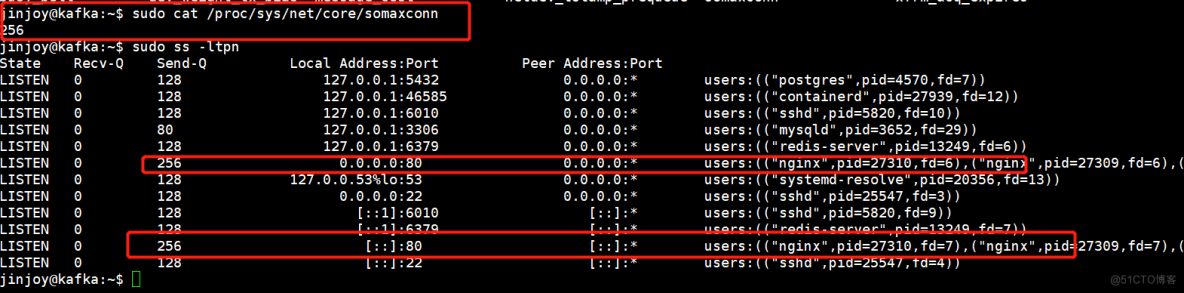
可以看到,此参数优化后,开启一个nginx进程,其队列最大值已经成256。现在我们启动一个nginx容器,看值变化了没有,如下图:

可以看到,容器里面的nginx的值,还是默认的128.也就是说,优化宿主内核,对容器内是无效的。
那么如果优化容器里面的参数,对TCP连接有没有实际的影响呢?我们也压测一下,为了方便比对,我们在同一台主机上开两台nginx容器,一台有优化的,端口是9001,一台没有优化的,端口9002,如下:
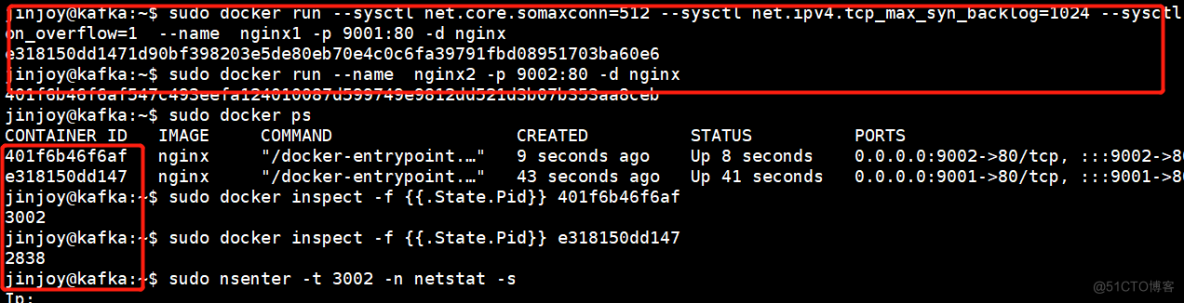
请注意,docker与k8s在内核优化的位置不太一样,此处简单验证。
确认是否优化情况:

通过ab 反复多次打连接流量:
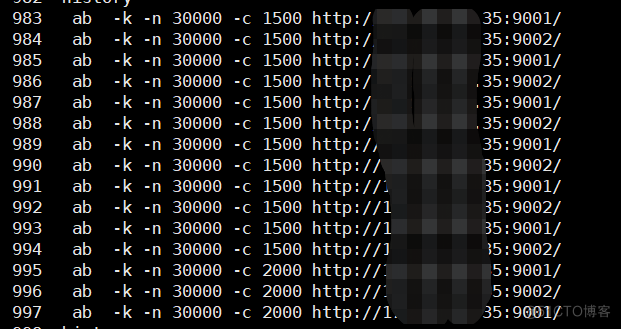
查看队列溢出情况:

可以看到,经过优化的,没有出现队列溢出,而没有优化的,则发生了6000多次的队列溢出。
由此,我们通过验证,确认容器内是需要单独进行优化的,这与我们理论上的分析一致。
六、补充一个知识点
为什么SS -ltpn里面的Send-Q是全连接队列最大值?这不是发送队列吗?你的怀疑没有错,但SS这个有点不一样,SS命令利用到了 TCP 协议栈中tcp_diag,tcp_diag 是一个用于分析统计的模块,可以获得 Linux 内核中第一手的信息,而这个模块通过区分状态来区分指标的含义,这种做法,我们也觉得好奇怪,看源码:

七、结语
通过netinside自定义的视图,我们预见了容器网络优化的问题,接下来,将推进集群的整体优化。在本次的预见性运维中所发现的问题,与相关的k8s领域内专业的朋友沟通后,发现大部份情况下,大家对此问题是忽视的,一方面是传统运维监控系统下视觉的不足,另一方面也是大家下意识的认为宿主机的内核优化会自然的与容器同步的,导致这个问题成了盲点。所以基于全流量的监测与分析,深入所有网络应用的“血液”进行诊断,可以消除我们的监测盲点,预见问题的存在,在问题发生前,解决问题,减少不必要的业务损失。