什么是数据库管理系统
Database Management System (DBMS)- 数据 + 管理系统
数据库存在的价值
Data redundancy and inconsistency(冗余与不一致性)Difficulty in accessing data(获取数据困难)Data isolation(数据孤岛)Integrity problems(完整性问题)
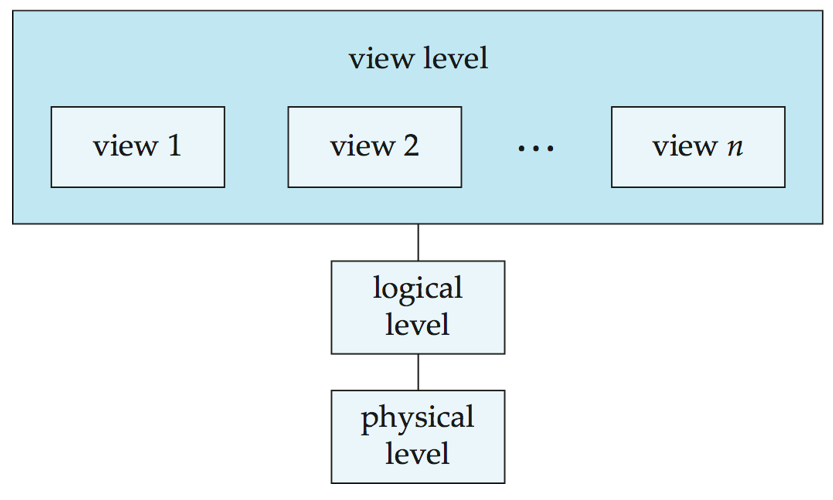
数据库的三层抽象
- 物理层(
Physical level):最低层次的抽象,描述数据实际上是怎样存储的。物理层详细描述复杂的底层数据结构。 - 逻辑层(
Logical level):比物理层层次稍高的抽象,描述数据库中存储什么数据及这些数据间存在什么关系。这样逻辑层就通过少量相对简单的结构描述了整个数据库。虽然逻辑层的简单结构的实现可能涉及复杂的物理层结构,但逻辑层的用户不必知道这样的复杂性。这称作物理数据独立性(physical data independence)。数据库管理员(DBA)使用抽象的逻辑层,他必须确定数据库中应该保存哪些信息。 - 视图层(
View level):视图层(view level)。最高层次的抽象,只描述整个数据库的某个部分。尽管在逻辑层使用了比较简单的结构,但由于一个大型数据库中所存信息的多样性,仍存在一定程度的复杂性。数据库系统的很多用户并不需要关心所有的信息,而只需要访问数据库的一部分。视图层抽象的定义正是为了使这样的用户与系统的交互更简单。系统可以为同一数据库提供多个视图。
实例与模式
-
实例(Instances):指特定时刻存储在数据库中的信息的集合
-
模式(Schemas):指数据库的总体设计
- 物理模式(physical schemas):在物理层描述数据库的设计
- 逻辑模式(logical schemas):在逻辑层描述数据库的设计。程序员使用逻辑模式来构造数据库应用程序
- 子模式(subschemas):描述了数据库的不同视图
数据模型(Data model)
- 关系模型(retional model):用表的集合来表示数据和数据间的联系
- 实体-联系模型(entity-relationship model):基于对现实世界的认识——现实世界由一组称作实体的基本对象以及这些对象间的联系构成。广泛用于数据库设计
- 基于对象的数据模型(object-based data model):基于面向对象设计思想
- 半结构化数据模型(semistructured data model):可拓展标记语言
xml,eXtensible,Markup,Language
数据库构成(Database System Internals)
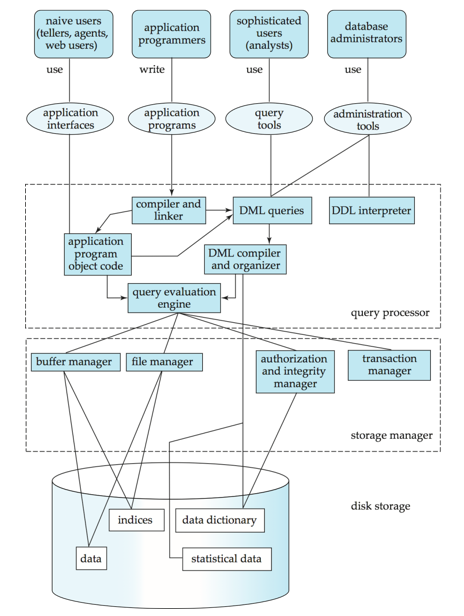
数据库架构(Database Architecture)
Centralized(集中式)Client-server(客户/服务器式)Parallel (multi-processor)(并行)Distributed(分布式)
关系 (Relation)
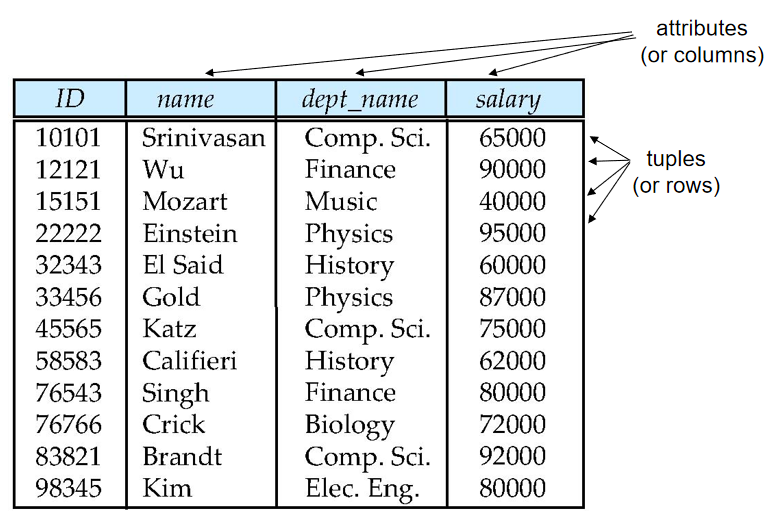
- 属性(attributes):表中每一列数据。
A1, A2, …, An - 元组(tuples):表中每一行数据
- 关系(relation):关系是无序的
- 关系实例(relation instance):表
- 关系模式(relation schema):
R = (A1, A2, …, An )。例如:instructor = (ID, name, dept_name, salary)
码/键(keys)
-
超码(super key):一个或一组属性,能够唯一区分一个关系的任何一个元组。例如
{ID, name},{ID} -
候选码(candidate key):最小的(包含属性个数最少)超码。例如
{ID} -
主码(primary key):候选码中挑出一个作为主码,任何关系只能有一个主码
-
外码(foreign key):一个表中某一列的所有值一定出现在另一张表的某一列,且在另一张表中为主码
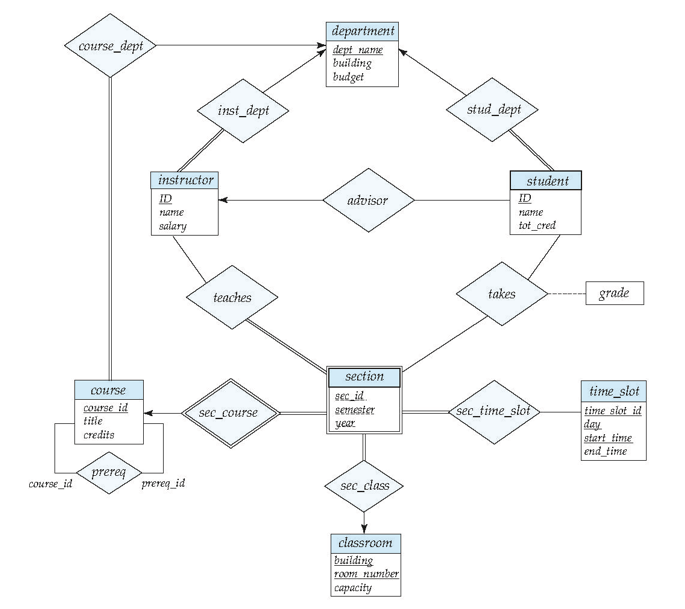
大学数据库模式图

department(dept_name,building,budget);
instructor(ID, name,dept_name,salary);
course(course_id,title,dept_name,credits);
section(course_id,sec_id,semester,year,building,room_number,time_slot_id);
teaches(ID,course_id,section_id,semester,year);
student(ID,name,dept_name,tot_cred);
prereq(course_id,prereq_id);
Advisor(s_id,i_id)
takes(ID,course_id,sec_id,semester,year,grade)
classroom(building,room_number,capacity)
time_slot(time_slot_id,day,start_time,end_time)
大学数据库 E-R 图
 形式化关系查询语言( Formal Relational Query Languages )
关系代数(Relational Algebra)
形式化关系查询语言( Formal Relational Query Languages )
关系代数(Relational Algebra)
1️⃣ 选择(Select Operation)
-
定义:$ \sigma _p (r)$ = {t | t $ \in $ r and p(t)},p 是谓词,选择出满足谓词的元组
-
例题:
- 选出物理系或者年薪资大于70000美元的老师:$ \sigma _{dept_name=''Physics'' \lor ,,salary>70000}\left( instructor \right) ,,$
- 选出除了物理和计算机学院之外的老师:$ \sigma _{dept_name\ne ''Physics'' \land ,,depe_name\ne ''Comp.Sci.''}\left( instructor \right) $
2️⃣ 投影(Project Operation)
-
定义:$ \prod\nolimits_{A_1,A_2,...,A_k}^{}{\left( r \right)}$,选出特定的属性,结果只包含这 k 列,其他列不显示
-
例题:
- 找出所有计算机学院的老师的姓名:$ \prod\nolimits_{name}^{}{\left( \sigma _{\mathrm{de}pt_name=''Comp.Sci.''}\left( instructor \right) \right)}$
3️⃣ 集合并(Union Operation)
-
定义: r $ \cup $ s = {t | t $\in $ r or t $ \in $ s},两表查询结果合并
-
要点:
r,s必须包含相同属性,即同元r,s属性的域必须相容
-
例题:
-
找出所有在 2018 年秋季或者在 2019 年春季开课的课程:
\[\prod\nolimits_{course\_id}^{}{\left( \sigma _{semester=''Fall'' \land \,\,year=2018}\left( \sec tion \right) \right) \cup}\prod\nolimits_{course\_id}^{}{\left( \sigma _{semester=''Spring'' \land \,\,year=2019}\left( \sec tion \right) \right)} \]
-
4️⃣ 集合差(Set Difference Operation)
-
定义:r - s = {t | t $ \in $ r and t \(\notin\) s},查询出属于
r但不属于s的元组 -
要点:
r,s必须包含相同属性,即同元r,s属性的域必须相容
-
例题:
-
找出所有在 2018 年秋季但不在 2019 年春季开课的课程:
\[\prod\nolimits_{course\_id}^{}{\left( \sigma _{semester=''Fall''\land \,\,year=2018}\left( \sec tion \right) \right) -}\prod\nolimits_{course\_id}^{}{\left( \sigma _{semester=''Spring''\land \,\,year=2019}\left( \sec tion \right) \right)} \]
-
5️⃣ 笛卡尔积(Cartesian-Product Operation)
-
定义:r $ \times $ s = {t q | t $ \in $ r and q $ \in $ s}
-
要点:
- 笛卡尔积之后形成的新表要改名
- 注意两表中相同属性命名使用
表名.属性名或其别名
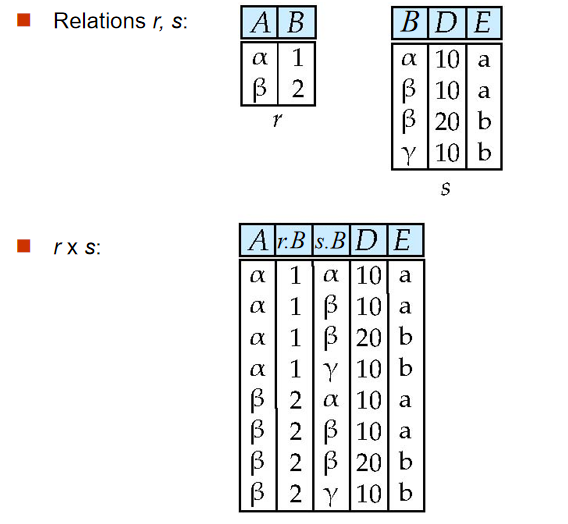
-
例题:
-
选出计算机学院所有学生的选课信息
先笛卡尔积再选择:$ \sigma _{dept_name='Comp.Sci.'}\left( \sigma _{student.ID=takes.ID}\left( student\times takes \right) \right) $
先选择在笛卡尔积:$ \sigma _{student.ID=takes.ID}\left( \sigma _{dept_name='Comp.Sci.'}\left( student \right) \times takes \right) $
-
6️⃣ 更名(Rename Operation)
- 定义:$ \rho _{x\left( A_1,A_2,...,A_n \right)}\left( E \right) $,对于表
E,重命名为x,投影属性重命名为 $ A_1,A_2,...,A_n $
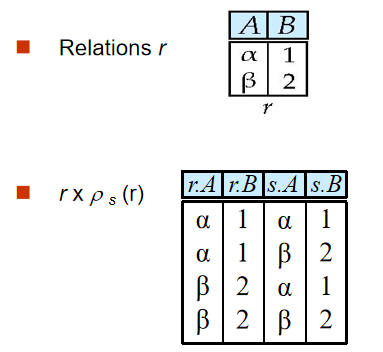
关系代数表达式
-
定义:把关系或常数关系通过关系代数连接起来形成的表达式
-
例题:
-
找出选了教师Einstein所教课程的所有学生的 ID,注意结果不能重复.
$ \prod\nolimits_{ta.ID}^{}{\left( \sigma _{te.course_id=ta.course_id\land te.\sec tion_id=ta.section_id\land te.semester=ta.semester\land te.year=ta.year}\left( \sigma _{i.ID=te.ID\land name='Eisntein'}\left( \rho _i\left( instructor \right) \times \rho _{te}\left( teaches \right) \times \rho _{ta}\left( takes \right) \right) \right) \right)}$
-
查出大学里的最高工资
$ \prod\nolimits_{salary}^{}{\left( instructor \right) -\prod\nolimits_{instructor.salary}^{}{\left( \sigma _{instructor.salary<d.salary}\left( instructor\times \rho _d\left( instructor \right) \right) \right)}}$
-
1️⃣ 集合交(Set-Intersection Operation)
-
定义: r $ \cap $ s = {t | t $\in $ r and t $ \in $ s}
-
要点:
r,s必须包含相同属性,即同元r,s属性的域必须相容
-
注意:$ r\cap s=r-\left( r-s \right) $
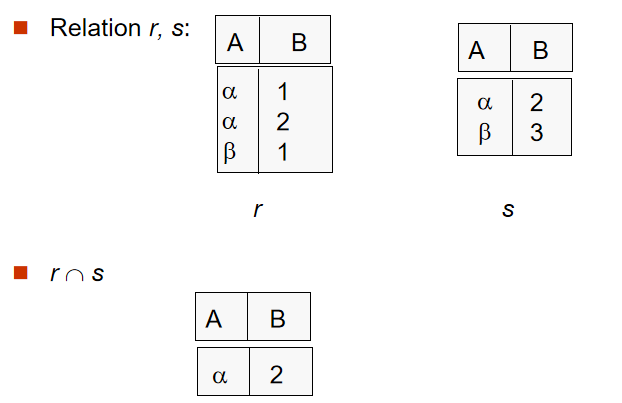
2️⃣ 除法(Division Operation)
- 定义:$ r\div s $
- $ R=\left( A_1,A_2,...A_m,B_1,B_2,...B_n \right) ,S=\left( B_1,B_2,...B_n \right)$
- 解释:前提是
s表的属性包含于r表。则r表属性去掉s表的属性之后,r表中包含s表所有数据的元组被选出。其实文字比较难以形容,看图理解更好。
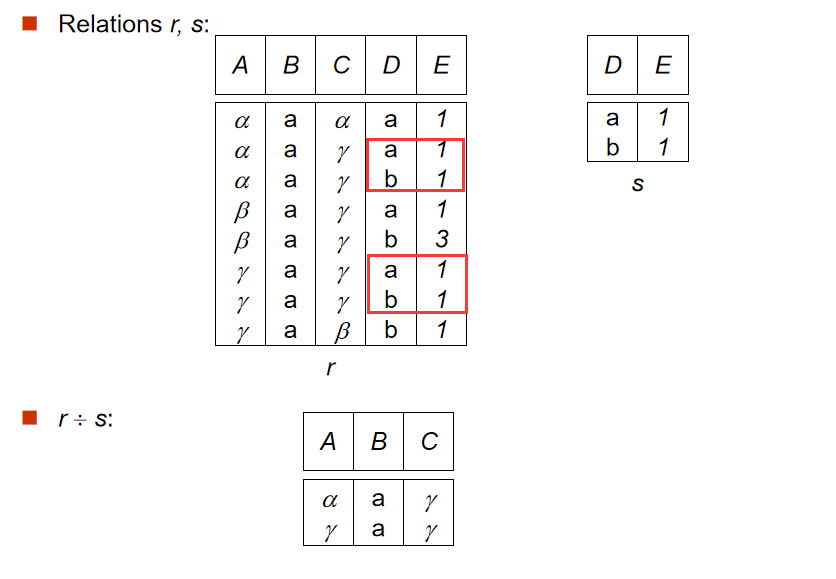
-
应用:带有“包含某某集合所有元素”的问题,可以使用除法解决
-
例题:
- 选出选了计算机系所有课程的学生的 ID:$ \prod\nolimits_{course_id,ID}^{}{\left( takes \right) \div \left( \prod\nolimits_{course_id}^{}{\left( \sigma _{department='Comp.Sci.'}\left( course \right) \right)} \right)}$
3️⃣ 赋值(Assignment Operation)
- 定义:$ temp\gets expression $,查询结果保存在临时表
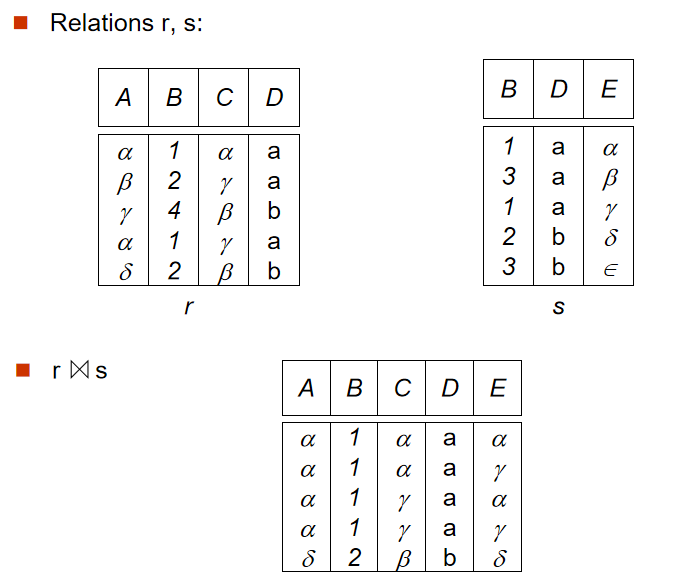
4️⃣ 自然连接(Natural Join Operation)
- 定义:$ r\Join s $,
r表和s表根据重复属性进行笛卡尔积,最后去除重复属性
-
例题:
-
查找计算机学院所有老师的名字以及他们所上课程的名字
$ \prod\nolimits_{name,title}^{}{\left( \sigma _{dept_name='Comp.Sci.'}\left( instructor\Join teaches\Join course \right) \right)}$
-
查找教授 ‘D.B.S' 和 ’O.S‘ 的老师的名字以及课程名称
$ \prod\nolimits_{name,title}^{}{\left( instructor\Join teaches\Join course \right) } $ \(\div \rho _{title}\left( temp \right) \left( \left\{ \left( ''D.B.S'' \right) ,\left( ''O.S'' \right) \right\} \right)\)
-
1️⃣ 广义投影(Generalized Projection)
-
定义:$ \prod\nolimits_{F_1,F_2,...F_n}^{}{\left( E \right)}$
-
解释:投影可以进行四则运算
-
举例:$ \prod\nolimits_{customer,limit-balance}^{}{\left( credit \right)}$
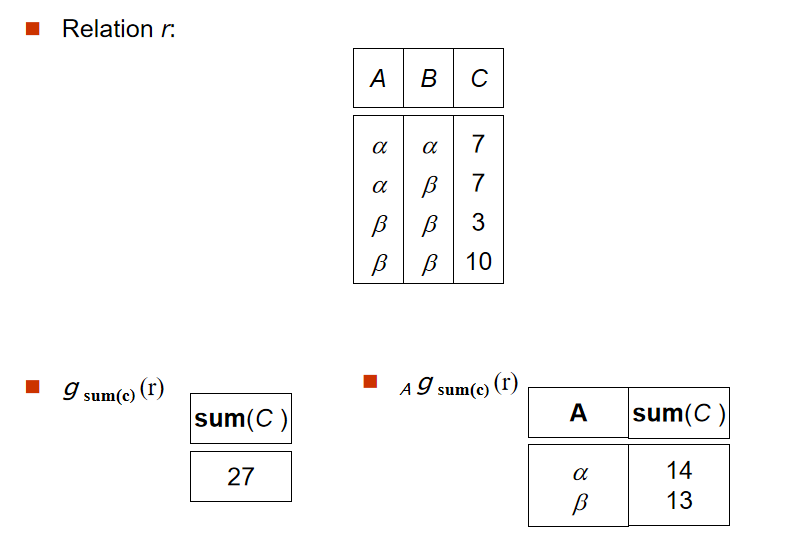
2️⃣ 聚集函数(Aggregate Functions and Operations)
-
定义:
\[_{G_1,G_2,...,G_n}g_{F_1\left( A_1 \right) ,F_2\left( A_2 \right) ,...,F_n\left( A_n \right)}\left( E \right) \] -
解释:
G:选中进行分组的属性(可以为空)F:聚集函数(sum,avg,min,max,count)A:聚集函数作用的属性
-
要点:
- 除了
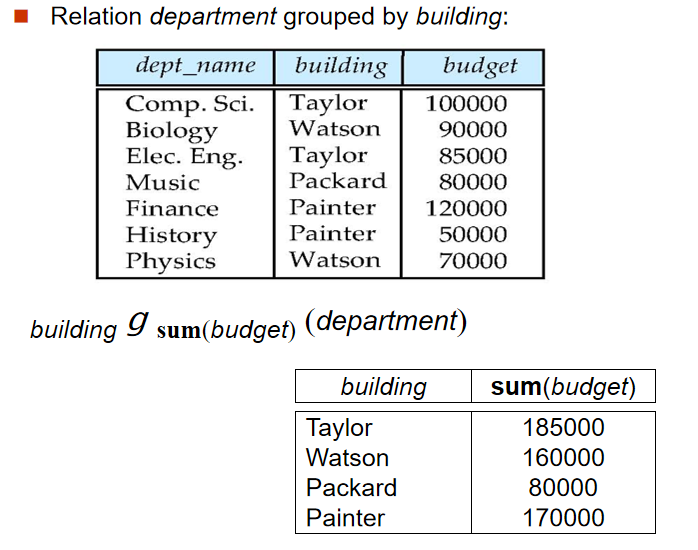
count(*)会保留null,对所有行进行统计,其他聚集函数会忽视值为null的属性 - 可对聚集之后的属性进行更名操作:\[_{building}g_{sum\left( budget \right) \,\,as\,\,sum\_budget}\left( department \right) \]
- 除了
3️⃣ 外连接(Outer Join)
-
定义:保留连接过程中某表的所有数据,连接操作的延申,能避免信息的丢失
-
左外连接(左表完整),右外连接(右表完整),全外连接(左右表完整)
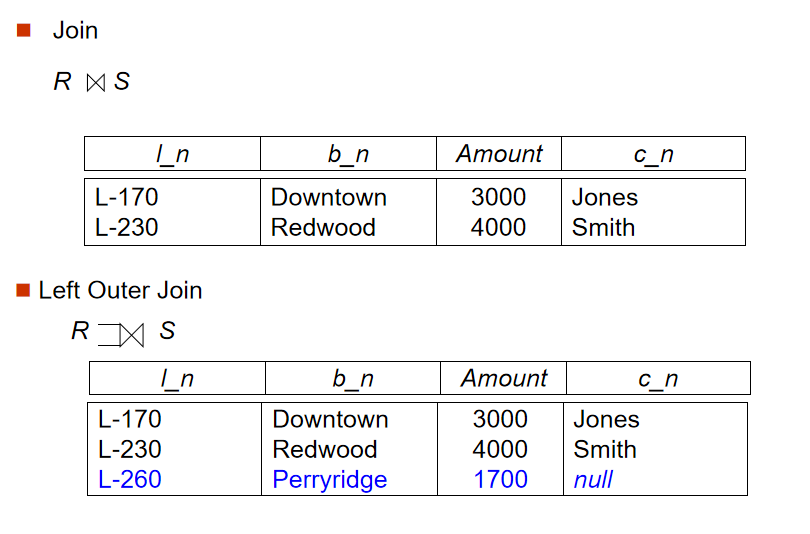

NULL值问题
-
定义:
null表示一个不确定(unknown)的值,或一个不存在的值 -
unknown的逻辑运算:优先级上false < unknown < true# OR unknown or true = true unknown or false = unknown unknown or unknown = unknown # AND unknown and true = unknown unknown and false = false unknown and unknown = unknown # NOT not unknown = unknown
1️⃣ 删除(Deletion)
-
定义:$ r\gets r-E $
-
解释:可以删除整条元组,但不可以删除某些属性
-
例题:
- 删除所有物理学院的老师:$ instructor\gets instructor-\sigma _{dept_name='Physics'}\left( instructor \right) $
2️⃣ 插入(Insertion)
-
定义:$ r\gets r\cup E $
-
解释:
r表并上查询结果E,赋值给r表 -
例题:
-
插入
\[instructor\gets instructor\cup \left\{ \left( ''1111'',''Peter'',,72000 \right) \right\} \]\[instructor\gets instructor\cup \left\{ \left( ''1111'',''Peter'',null,72000 \right) \right\} \]instrutor表,ID 为 1111,教师"Peter",年薪 72000:
-
3️⃣ 更新(Updating)
-
定义:$ r\gets \prod\nolimits_{F_1,F_2,...F_I}^{}{(r)} $
-
解释:可以改变某个元组当中的某个值。
-
例题:
- 所有老师年薪提高百分之五:$ instructor\gets \prod\nolimits_{id,name,dept_name,salary*1.05}^{}{\left( instructor \right)}$
SQL 语言在功能上主要分为如下3大类:
DDL(Data Definition Language、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。SELECT是 SQL 语言的基础,最为重要。
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等
DQL(Data Query Language、数据查询语言),有时单独把 SELECT 拿出来作为 DQL 分类
DDL(Data Definition Language)常用数据库数据类型

VARCHAR vs CHAR
CHAR 和 VARCHAR 类型都可以存储比较短的字符串。
CHAR类型CHAR(M)类型一般需要预先定义字符串长度。如果不指定(M),则表示长度默认是1个字符。- 如果保存时,数据的实际长度比
CHAR类型声明的长度小,则会在右侧填充空格以达到指定的长度;如果数据的实际长度比CHAR类型声明的长度大,则会截取前M个字符。当MySQL检索CHAR类型的数据时,CHAR类型的字段会去除尾部的空格。