awk的由来 awk这个工具的名字是由三个发明者的首字母组合而成。 awk是一个文本处理工具。 awk的版本 AWK:最早AWK是在unix上实现的,属于贝尔实验室的 NAWK:即NEW AWK,是AWK的升级版,也属于
-
awk这个工具的名字是由三个发明者的首字母组合而成。
-
awk是一个文本处理工具。
-
AWK:最早AWK是在unix上实现的,属于贝尔实验室的
-
NAWK:即NEW AWK,是AWK的升级版,也属于贝尔实验室。
-
GAWK:即GNU AWK,基于GNU重新编译而来的,兼容NAWK和AWK。
linux使用的是gawk,我们执行的awk是gawk的一个软连接。
which awk #查看awk这个命令所在的位置
ll /usr/bin/awk #awk是一个软连接,指向GAWK
awk是逐行处理文本内容,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以”换行符”为标记,识别每一行
会把读入的一行按照一个的条件分割成列 #默认使用空格作为分隔符
格式:
ark [option] 'program' file..
选项:
-F:用于指定分隔符 #例如:-F"|" 表示使用|作为每行的分隔符
-v:用于指定变量
awk 的 program 参数由 pattern 和 action 组成。
Pattern 用于指定匹配模式,并对匹配的行执行后面的 action 操作,不匹配的行不做处理。
Action 用于指定要对匹配到的行进行什么样的操作,这些操作语句要包含在大括号 {} 里面。
如果没有提供 pattern 参数,默认处理所有行。
program需要用单引号括起来
常见的action动作:print
pattern省略或为1,等价于 /.*/(任意字符)
action省略,等价于 { print }
program就是由pattern和action组成的
-
第一步:BEGIN:在文件处理之前所作的操作
-
第二步:读入文件的每一行进行处理
-
第三步:文件处理完成之后执行END的语句块
-
print这个动作可以实现打印的功能。
-
使用分隔符将一行切成若干列(默认的分隔符:空格),用S1..$n来表示第几列 $0表示整行
格式:print item1, item2, ...
逗号作为分隔符
只有一个print动作,默认为:print $0
打印字符串要用双引号括起来,不然就会认为是要给变量,数字不用加双引号,变量和数字不需要
例如:获取分区的利用率
df -h | awk '{print $5}'
df | awk -F"[ %]+" '{print$1,$5}' #[ %]+:表示以一个以上空格或百分号作为分隔符
例如:取出网站访问量最大的前3个IP
awk '{print $1}' nginx.access.log-20200428 |sort | uniq -c |sort -nr|head -3
sort命令:实现排序的功能(默认从小到大)
选项:
-n:以字符串的数字作为排序的一句
-r:将要比较的结果反转 #逆序排序 最大的排最前面
uniq命令:用于去除重复的行
选项:
-c:在每一行的前面显示统计改行出现过的次数
-d:仅显示重复的行
-u:仅显示不重复的行
head命令:显示文件指定的前几行
-n num或 -num:显示文件的开头num行
例如:获取指定网卡的ip地址
ifconfig eth0 | sed -n '2p' | awk '{print $2}'
sed命令:对指定的行进行操作,
-n:关闭自动打印功能
脚本位置:
2:表示第二行
脚本指定:
p:表示打印指定的行内容
-
内置变量
-
外置变量
行;称为记录
列:称为字段或者域
awk的program中引用变量,不需要添加$符号
例如: awk -v FS=":" #指定冒号作为每行分段的分隔符
NF:一行有多少列
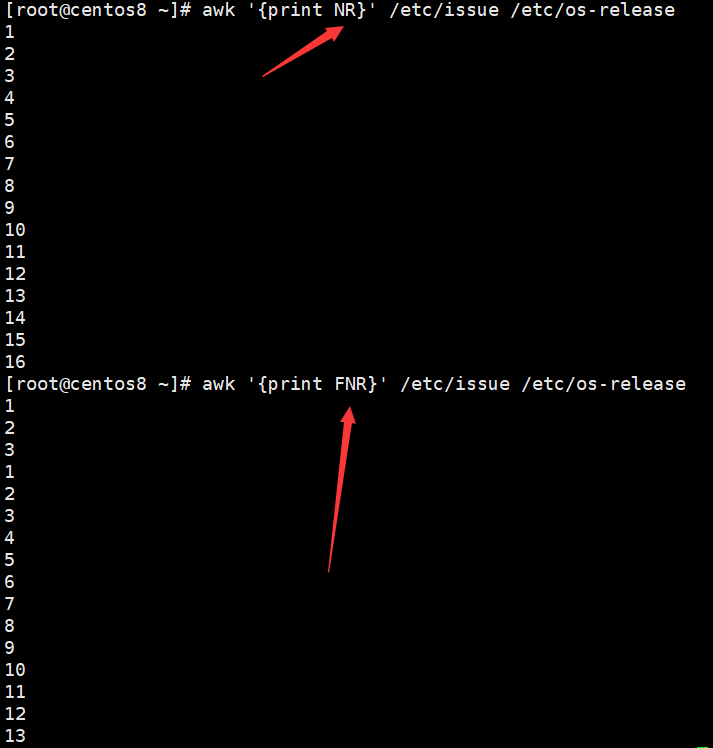
NR:记录的编号NR:第几行的编号,比如第四行,NR就是4
范例:获取指定网卡的ip地址
ifconfig eth0 | awk 'NR==2{print $2}' #表示取第二行的内容 NR==2就是条件
使用NR的话就是把多个文件合在一起进行编号。
自定义变量的格式:-v 变量名=值
pattern(模式)用户指定需要处理文本的那些行。
-
没指定pattern:表示匹配所有
-
匹配指定的行
-
匹配一个范围
没有写pattern:表示空模式,所有的行都匹配(大括号前面没任何条件内容)
/正则表达式/:过滤符合正则表达式的行进行打印 --和sed的使用方法一样的
#范例:ifconfig eth0 | awk '/netmask/{print }'
-
正则表达式写法
-
内置变量NR写法
行的区间范围:不能直接写行号,使用NR变量
例如:
NR>=5 && NR <=8 --- 第五行到第八行
正则表达式的写法: /pattern1/,/pattern2/
-
算数操作符
-
模式匹配符
-
逻辑操作符
范例:取奇,偶数行
seq 10 | awk 'NR%2==0' #能被2整除的就是偶数
seq 10 | awk 'NR%2==1' #不能被2整除的就是奇数
-
~ 左边是否和右边匹配,包含关系
-
!~ 是否不匹配
awk -F: '$0 ~ /root/{print $1}' /etc/passwd #表示包含root的行
-
与:&&,并且关系
-
或:||,或者关系
-
非:!,取反
例如:
awk -F: '$3>=0 && $3<=1000 {print $1,$3}' /etc/passwd #第三列大于等于0并且第三列的值小于等于1000
-
真:结果为非0值或非空字符串
-
假:结果为空字符串或0值
例如:
seq 10 | awk '1' #会输出1到10,因为pattern为1表示为真,而action省略等价于 { print }
seq 10 | awk '0' #什么都不会输出,0表示为假
seq 10 | awk '"false"' #会输出0到10,因为它不是空字符串