@TOC
synchronized 的 锁优化的机制
这也是属于我们编译器优化,以及说 JVM ,操作系统,它们的一些优化策略所涉及到一些小细节。
这些东西,其实说白了:如果我们不需要去实现 JVM 和 编译器,就并不需要去理解。
但奈何,现在都卷到这个份上,那我们就学吧
基本特点
结合上面的锁策略, 我们就可以总结出
Synchronized 具有以下特性(只考虑 JDK 1.8):
1、 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
2、 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
3、 实现轻量级锁的时候大概率用到自旋锁策略
4、 是一种不公平锁
5、 是一种可重入锁
6、 不是读写锁
7、实现重量级锁的时候大概率会用到 挂起等待锁。
加锁工作过程
JVM 将 synchronized 锁分为 无锁、偏向锁、轻量级锁、重量级锁 状态。会根据情况,进行依次升级 。
1. 偏向锁
偏向锁不是真的加锁, 而只是在锁的对象头中记录一个标记(记录该锁所属的线程),如果没有其他
线程参与竞争锁,那么就不会真正执行加锁操作,从而降低程序开销,一旦真的涉及到其他的线程竞
争,再取消偏向锁状态,进入轻量级锁状态

举个栗子理解偏向锁 :
有一天我看上了一个小哥哥,长的又帅又有钱万一后面有一天,我腻歪了,然后想把他甩了,但是他要是对我纠缠不休,这还麻烦
- 我就只是和这个小哥哥搞暧昧。同时,又不明确我们彼此的关系。
- 这样做的目的就是为了有朝一日,我想换男朋友了,就直接甩了就行
- 但是如果再这个过程中,有另外一个妹子,也在对这个小哥哥频频示好我就需要提高警惕了,对于这种情况,就要立即和小哥哥确认关系 (男女朋友的关系),立即对另外的妹子进行回击:他是我男朋友。你离他远点
偏向锁 并不是真的加锁,只是做了一个标记
带来的好处就是,后续如果没人竞争的时候,就避免了加锁解锁的开销
偏向锁,升级到轻量级锁的过程
- 如果没有其他的妹子和我竞争,就一直不去确立关系,(节省了确立关系 / 分手的开销)
- 如果没有其他的线程来竞争这个锁,就不必真的加锁,(节省了加锁解锁的开销)
文里的偏向锁,和懒汉模式也有点像,思路都是一致的,只是在必要的时候,才进行操作,如果不必要,则能省就省
2. 轻量级锁
其他线程进入竞争,偏向锁状态被消除,进入轻量级锁状态 (自适应的自旋锁).
此处的轻量级锁就是通过 CAS 来实现
- 通过 CAS 检查并更新一块内存 (比如 null => 该线程引用)
- 如果更新成功, 则认为加锁成功
- 如果更新失败, 则认为锁被占用, 继续自旋式的等待(并不放弃 CPU)
自旋操作是一直让 CPU 空转, 比较浪费 CPU 资源.
因此此处的自旋不会一直持续进行, 而是达到一定的时间/重试次数, 就不再自旋了.也就是所谓的 “自适应”
3. 重量级锁
如果竞争进一步激烈, 自旋不能快速获取到锁状态, 就会膨胀为重量级锁
此处的重量级锁就是指用到内核提供的 mutex
- 执行加锁操作, 先进入内核态.
- 在内核态判定当前锁是否已经被占用
- 如果该锁没有占用, 则加锁成功, 并切换回用户态.
- 如果该锁被占用, 则加锁失败. 此时线程进入锁的等待队列, 挂起. 等待被操作系统唤醒.
- 经历了一系列的沧海桑田, 这个锁被其他线程释放了, 操作系统也想起了这个挂起的线程, 于是唤醒这个线程, 尝试重新获取锁
synchronized 几个典型的优化手段
1、锁膨胀/锁升级
体现了 synchronized 能够 “自适应” 这样的能力。

所以,当我们使用 synchronized 进行加锁的时候,它会根据实际情况来进行逐步升级的。
-
如果当前没有线程跟它竞争,它就始终保持在偏向锁的状态。
-
如果有其他现场称跟它竞争,它会升级成一个自旋锁/轻量级锁。
【如果锁竞争就保持轻微的情况下,它就会一直抱着一个 自旋锁的状态】
- 如果锁竞争进一步加剧,它就会进一步的升级到 重量级锁。
synchronized 就有这样的一个自适应的过程。
2、锁粗化
有锁粗化,也就有锁细化。
此处的粗细指的是“锁的粒度”。
粒度:加锁代码涉及到的范围。
加锁代码的范围越大,认为锁的粒度就 越粗。
加锁代码的范围越小,认为锁的粒度就 越细。
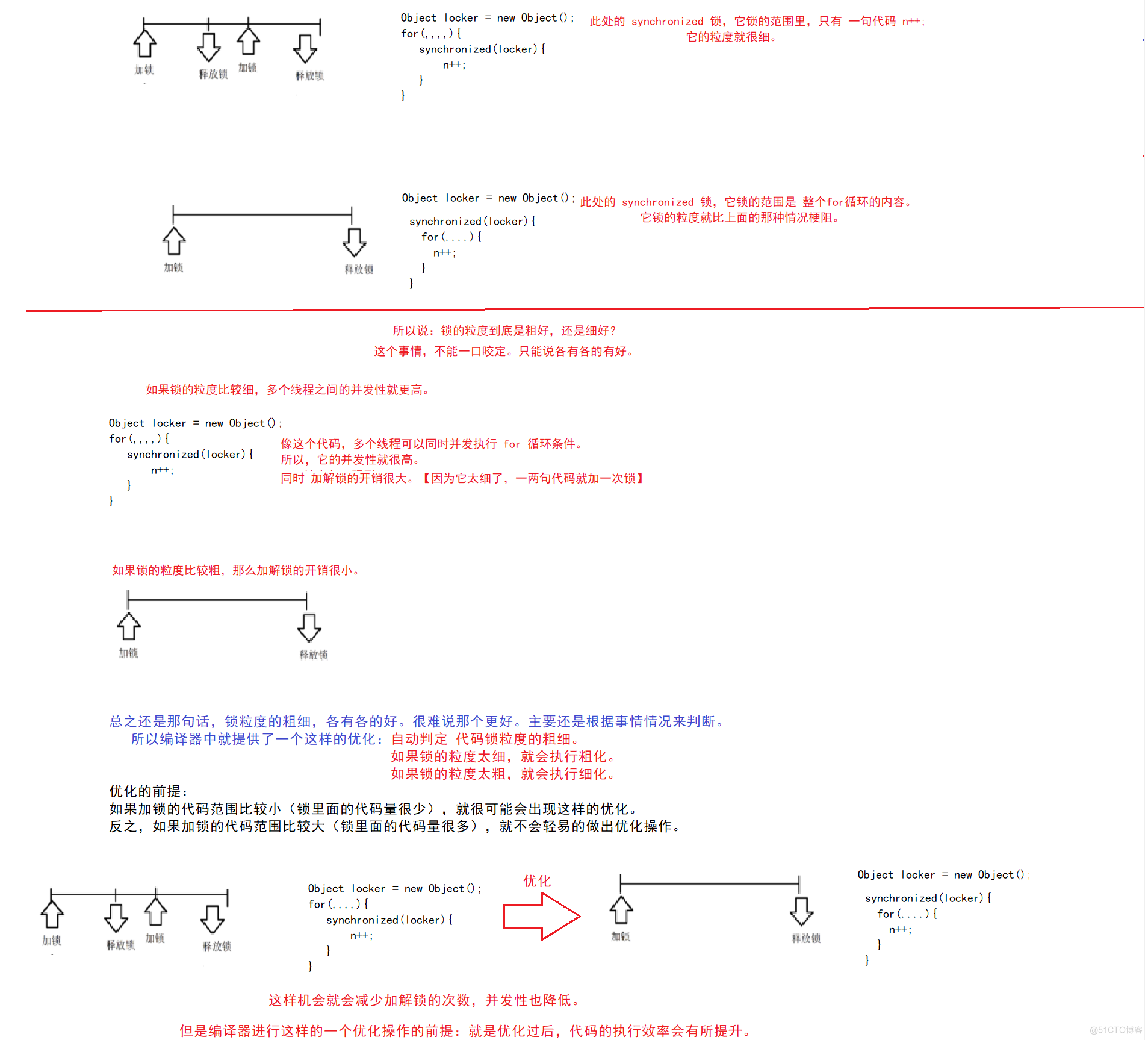
实际开发过程中, 使用细粒度锁, 是期望释放锁的时候其他线程能使用锁.
但是实际上可能并没有其他线程来抢占这个锁. 这种情况 JVM 就会自动把锁粗化, 避免频繁申请释放锁
举个栗子理解锁粗化 :
领导给下属交代工作任务:方式一:
- 打电话, 交代任务1, 挂电话.打电话, 交代任务2, 挂电话.打电话, 交代任务3, 挂电话.
方式二:
- 打电话, 交代任务1, 任务2, 任务3, 挂电话.
显然, 方式二是更高效的方案.
到底锁粒度是粗好还是细好?
如果锁粒度比较细,多个线程之间的并发性就更高
如果锁粒度比较粗,加锁解锁的开销就更小
编译器就会有一个优化,就会自动判定,如果某个地方的代码锁的粒度太细了就会进行粗化
如果两次加锁之间的间隔较大 (中间隔的代码多),一般不会进行这种优化;如果加锁之间间隔比较小 (中间隔的代码少),就很可能触发这个优化
3、锁消除
有些代码,明明不用加锁,结果你给加上锁了
编译器在编译的时候,发现这个锁好像没有存在的必要,就直接把锁给去掉了。
就比如你当前的代码是处于单线程的情况,你还咔咔的顿加锁操作。这个时候,编译器就会你创建的锁,都去掉。 疑问:单线程的代码,有谁会去加锁的?
其实有时候加锁操作并不是很明显,稍不留神就可能会做出这种错误的决定。
StringBuffer sb = new StringBuffer(); sb.append("a"); sb.append("b"); sb.append("c"); sb.append("d");此时每个 append 的调用都会涉及加锁和解锁,但如果只是在单线程中执行这个代码,那么这些加锁解
锁操作是没有必要的,白白浪费了一些资源开销
【文章原创作者:香港显卡服务器 http://www.558idc.com/hkgpu.html 网络转载请说明出处】