目录
os模块的使用
open("test.txt","mode")
读取文件中的内容
f.read()
f.readline(size)
f.readlines(size)
写入数据到文件中
追加数据
覆盖原数据
读写文件的IO指针的一些问题
os模块中一些基本的判断文件的函数
CSV模块的使用
读文件
reader(csvfile, dialect='excel', **fmtparams)
读取指定的列
DictReader函数是返回字典格式的数据
读取指定列的数据
写文件
writer(csvfile, dialect='excel', **fmtparams)
追加一行数据进去
覆盖之前的数据
xlrd模块
OS模块简单的来说它是一个Python的系统编程的操作模块,可以处理文件和目录
以下都是python3.7环境下
os模块的使用
open("test.txt","mode")
mode有以下几种:
- r : 只读,如果无此文件的话就会报错
- r+: 读写方式打开,既可读也可写
- w: 写入,覆盖之前的内容,如果无此文件就新建,只能写不能读
- a: 写入,在文件末尾追加新的内容,文件如果不存在,则新建,只能写不能读
- +: 更新,须结合 r、w、a 参数使用,指针在最后面
- b: 打开二进制的文件,可以与 r、w、a、+ 结合使用
- U:支持所有的换行符号。“ \r ”、“ \n ", " \r\n "
注:r 、w 、a 不能结合使用。不写mode参数默认是只读
两种打开文件的方式
f=open("test.txt","r")或
with open("test.txt","r") as f:
如果是读取其他路径下的文件的话
open("c://users//desktop//test.txt")open("c:\\users\\desktop\\test.txt")
open("c:\/users\/desktop\/test.txt")
现在有一个 test.txt 文件,里面有以下内容
hello,word!iloveyou
xiaoxie
读取文件中的内容
不管用什么方法读取文件中的内容,只要不是文件的最后一行,其他行的末尾都会有一个 \n 。上面文件的内容,如果读取的话,在读取的字符串中实际上是这样的。所以我们在读取文件内容的时候,都会对文件去除\n ,使用字符串的 strip() 方法
hello,word!\niloveyou\n
xiaoxie
f.read()
函数,读取文件中的所有内容,返回一个 str 字符串
import ostry:
with open("test.txt",'r') as f:
a=f.read()
print(a)
print(type(a))
print(len(a))
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
##########################################################
hello,word!
iloveyou
xiaoxie
<class 'str'>
28
明明是26字节,为什么打印出来是28字节呢?这是因为第一行和第二行的 \n 也被算成了一个字符
f.readline(size)
函数,读取文件的第一行内容,返回一个字符串,参数size代表读取的字符串长度,不填默认读取所有第一行所有内容,包括 \n
import ostry:
with open("test.txt",'r') as f:
a=f.readline() #读取文件的第一行
print(a)
print(type(a))
print(len(a))
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
####################
hello,word!
<class 'str'>
12
这里为什么第二行是空的呢,字符串长度是12呢?这是因为第一行末尾还有一个 \n , 这是换行符,所以第二行是空的,也所以字符串长度读成了12,要想改成,我们可以修改下面几行,这样打印出来的就正常了
print(a.strip('\n'))
print(type(a))
print(len(a.strip('\n')))
########
hello,word!
<class 'str'>
11
f.readlines(size)
函数读取文件中的内容,参数size代表读取的行数,不填默认读取所有行,返回一个 list 列表,每一行作为列表的一个值
这里要注意的是,如果要打印出每行的内容的话,要用 str.strip() 方法把末尾的 \n 给去掉
import ostry:
with open("test.txt",'r') as f:
lines=f.readlines()
print(lines,type(lines))
for line in lines:
print(line.strip('\n'),end='---')
print(len(line.strip('\n')))
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
######################
['hello,word!\n', 'iloveyou\n', 'xiaoxie'] <class 'list'>
hello,word!---11
iloveyou---8
xiaoxie---7
写入数据到文件中
- f.write(str) 的参数是一个字符串,就是你要写入的内容
- f.writelines(sequence)的参数是序列,比如列表,它会迭代帮你写入文件。但是序列中的元素也必须是str字符串
追加数据
默认我们写入的数据是在原数据的末尾的,也就是不是新的一行。如果我们想一行一行写入,我们可以在写入每一行之前,先写入 \n
import ostry:
with open("test.txt",'a',encoding='utf-8') as f:
f.write("\n")
f.write("nihao")
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
覆盖原数据
import ostry:
with open("test.txt",'w',encoding='utf-8') as f:
f.write("nihao")
f.write("\n")
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
还有一种利用print写入数据,知道就好,不常用
import osf=open("test.txt","w",encoding='utf-8')
print("hello,word!",file=f) #将hello,word!追加写入test.txt文件中
f.close()
读写文件的IO指针的一些问题
比如我们有一个文件 test.txt 里面的内容是: hello,word!
import oswith open("test.txt","r") as f:
print("*"*50)
print(f.read())
print("*"*50)
print(f.read())
print("*"*50)
f.close()
**************************************************
hello,word!
**************************************************
**************************************************
我们可以看到,第二次打印什么东西也没打印出来。那是因为我们第一次读取文件的时候,我们的指针已经到文件的末尾了,当我们再次读取文件的时候,自然就没有东西了。除非我们关闭文件流,再次打开读取。
os模块中一些基本的判断文件的函数
os.getcwd() 返回当前工作路径os.chdir("e://") 修改工作路径
open("test.txt","w") 创建文件
os.remove("test.txt") 删除文件
os.mkdir("e://test") 在当前目录下创建目录
os.rmdir("e://test") 删除给定路径的目录(该目录必须是空目录,不然报错)
os.removedirs("e://test") 删除给定路径的目录(该目录必须是空目录,不然报错)
os.listdir("e://") 返回给定路径下的所有文件和目录,返回的是列表类型的数据
os.path.abspath("123.txt") 获取当前目录下某文件的绝对路径,如果该文件不存在,也返回路径
os.path.exists("123") 判断该目录下文件或者目录是否存在,如果存在返回true,否则返回false
如果存在,则再判断是目录还是文件,如果存在返回true,否则返回false
os.path.isdir("123") 判断是否是目录
os.path.isfile("123") 判断是否是文件
os.path.isabs("c://users//") 判断给定的路径是绝对路径还是相对路径,绝对路径是话返回True,相对路径返回False。他不会去判断你给定的路径是否真实存在
os.path.split("c://users//test.txt") 将给定路径的路径和文件名分隔开,返回元组型数据 ('c://users', 'test.txt')
os.path.split("c://users//test.txt")[0] 返回给定路径的路径名 c://users
os.path.dirname("c://users/test.txt") 返回给定路径的路径名 c://users
os.path.split("c://users//test.txt")[1] 返回给定路径的文件名 test.txt
os.path.basename("c://users//test.txt") 返回给定路径的文件名 test.txt
path=os.path.join("c:// ",123.txt) 将路径和文件名加在一起
实例:递归打印出给定路径下的所有文件
#递归打印出给定路径内的所有文件import os
def Test(path):
lines=os.listdir(path)
for line in lines:
pathname=os.path.join(path,line)
if os.path.isdir(pathname): #如果是目录的话
print("这是目录:",pathname)
Test(pathname) #再递归调用该函数
else:
print(pathname) #如果是文件
Test("g://xie")
CSV模块的使用
CSV (Comma Separated Values) 即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件,它的使用是比较广泛的,python内置了处理csv格式数据的csv模块。
读文件
比如我们现在有一个 test.csv的文件,文件内容如下
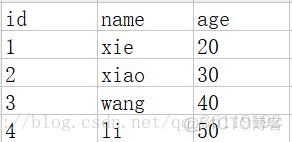
我们使用reader函数来读取 test.csv 文件中的内容
reader(csvfile, dialect='excel', **fmtparams)
- csvfile 参数,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象,如果是文件对象,打开时需要加"b"标志参数。
- dialect参数,编码风格,不写则默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册
- fmtparams参数,格式化参数,用来覆盖之前dialect对象指定的编码风格。
try:
with open("test.csv","r") as f:
lines=csv.reader(f) #返回的是 _csv.reader 对象
print(lines,type(lines))
for line in lines:
print(line,type(line)) #返回的每一行是列表格式
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
#########################
<_csv.reader object at 0x00000141BEC9E938> <class '_csv.reader'>
['id', 'name', 'age'] <class 'list'>
['1', 'xie', '20'] <class 'list'>
['2', 'xiao', '30'] <class 'list'>
['3', 'wang', '40'] <class 'list'>
['4', 'li', '50'] <class 'list'>
读取指定的列
import csvtry:
with open("test.csv","r") as f:
lines=csv.reader(f)
for line in lines:
print(line[1],type(line[1])) ##返回的是字符串
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
##########################
name <class 'str'>
xie <class 'str'>
xiao <class 'str'>
wang <class 'str'>
li <class 'str'>
DictReader函数是返回字典格式的数据
import csvtry:
with open("test.csv","r") as f:
lines=csv.DictReader(f) #返回的是 _csv.reader 对象
print(lines,type(lines))
for line in lines:
print(line,type(line)) #返回的每一行是列表格式
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
##########################
<csv.DictReader object at 0x000001E63C477668> <class 'csv.DictReader'>
OrderedDict([('id', '1'), ('name', 'xie'), ('age', '20')]) <class 'collections.OrderedDict'>
OrderedDict([('id', '2'), ('name', 'xiao'), ('age', '30')]) <class 'collections.OrderedDict'>
OrderedDict([('id', '3'), ('name', 'wang'), ('age', '40')]) <class 'collections.OrderedDict'>
OrderedDict([('id', '4'), ('name', 'li'), ('age', '50')]) <class 'collections.OrderedDict'>
读取指定列的数据
import csvtry:
with open("test.csv","r") as f:
lines=csv.DictReader(f) #返回的是 _csv.reader 对象
col=[line['name'] for line in lines]
print(col,type(col))
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
##################################
['xie', 'xiao', 'wang', 'li'] <class 'list'>
写文件
writer(csvfile, dialect='excel', **fmtparams)
- csvfile 参数,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象
- dialect参数,编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册
- fmtparams参数,格式化参数,用来覆盖之前dialect对象指定的编码风格。
写入数据时传入的数据,可以是元组,也可以是列表,他会自动把元组或列表中的数据写进不同列中。
追加一行数据进去
import csvrow=['5','zhang','60']
try:
with open("test.csv","a",newline='') as f:
csv_writer=csv.writer(f)
csv_writer.writerow(row)
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()
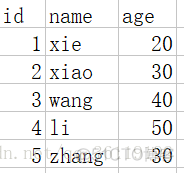
注:python3 和 python2 这个模块的使用有点不同。python3写入为了防止空一行,会在加一个 newline 参数。python2的话,则是写入方式加一个b
python3:with open("test.csv","a",newline='') as f:python2:with open("test.csv","ab") as f:
覆盖之前的数据
import csvtry:
with open("test.csv","w",newline='') as f:
csv_writer=csv.writer(f)
csv_writer.writerow(["id","name","age"])
csv_writer.writerow(["1","xie","20"])
csv_writer.writerow(["2","wang","30"])
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()

xlrd模块
xlrd模块是用来处理 .xls 格式的文档
打开.xls格式的文档
import xlrddata=xlrd.open_workbook('test.xls')
print(data)
##############################################
<xlrd.book.Book object at 0x000001BAC978E2B0>
获取.xls文档的列
import xlrddata=xlrd.open_workbook('test.xls')
line=data.sheets()
print(line) #打印所有的列
print(line[1]) #打印第2列
可以看到有三列
#############################################################################
[<xlrd.sheet.Sheet object at 0x000001BACDE2EE10>, <xlrd.sheet.Sheet object at 0x000001BACDC55860>, <xlrd.sheet.Sheet object at 0x000001BACD7692E8>]
<xlrd.sheet.Sheet object at 0x000001BACDC55860>
查看有多少行
import xlrddata=xlrd.open_workbook('test.xls')
line=data.sheets()[0] #选定第一列
rows=line.nrows
print(rows)
##########################
984
打印第一行的数据
import xlrddata=xlrd.open_workbook('test.xls')
line=data.sheets()[0]
print(line.row_values(0))
################################
['教工号', '单位', '姓名']
打印所有数据
import xlrddata=xlrd.open_workbook('test.xls')
line=data.sheets()[0]
rows=line.nrows
for i in range(rows):
print(int(line.row_values(i)[0]))
将.xls格式的文档转换为 .txt格式的
import xlrddatas=xlrd.open_workbook('test.xls')
allline=datas.sheets() #数据中的所有列数
lines=len(allline)
line=datas.sheets()[0] #选定第一列
rows=line.nrows #数据中的列数
print("这个文档有%s列,有%s行"%(lines,rows))
try:
with open("test.txt","w",encoding='utf-8') as f:
for i in range(rows):
for j in range(lines):
data=line.row_values(i)[j]
f.write(str(data))
f.write(" ") #用空格隔开
f.write("\n") #每一行加换行符
except Exception as e:
print("异常对象的类型是:%s"%type(e))
print("异常对象的内容是:%s"%e)
finally:
f.close()