目录
Pandas
Series
序列的创建
序列的读取
DataFrame
DataFrame的创建
DataFrame数据的读取
Panel
Panel的创建
Pandas
Pandas ( Python Data Analysis Library )是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一
python中有三种数据结构
pandas可以读取很多种的数据,用的比较多的是读取 htm、json、csv的数据
import pandasdata1=pandas.read_html('1.html') #读取html格式数据
data2=pandas.read_json('2.json') #读取json格式数据
data3=pandas.read_csv('3.csv') #读取csv格式的数据
Series
系列(Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引
Series的创建函数:pandas.Series( data, index, dtype,copy )
参数
描述
data
数据采取各种形式,如:ndarray,list,constants
index
索引值必须是唯一的和散列的,与数据的长度相同。默认 np.arange(n) 如果没有索引被传递
dtype
dtype 用户数据类型。如果没有,将推断数据类型
copy
复制数据,默认为 false
序列的创建
创建一个空series序列

从字典创建一个series序列

序列的读取
读取直接用 ['行名'],序列只可以读取行的内容

DataFrame
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
数据帧(DataFrame)的功能特点:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
DataFrame的创建函数:pandas.DataFrame( data, index, columns, dtype, copy)
参数
描述
data
数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个DataFrame
index
对于行标签,要用于结果帧的索引是可选缺省值 np.arrange(n) ,如果没有传递索引值
columns
对于列标签,可选的默认语法是 np.arange(n) 这只有在没有索引传递的情况下才是这样
dtype
每列的数据类型
copy
如果默认值为false,则此命令用于复制数据
DataFrame的创建
创建一个空DataFrame序列

从字典创建一个series序列(必须加index)

DataFrame数据的读取
读取列,直接 ['列名']
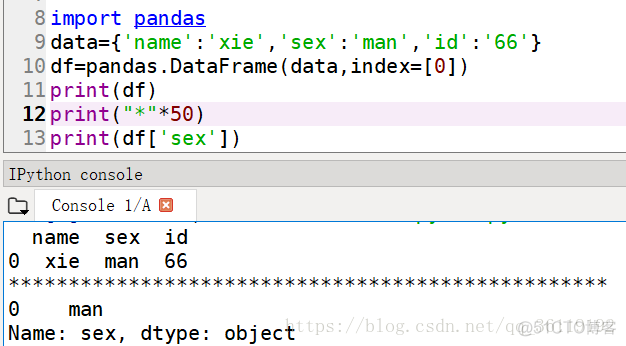
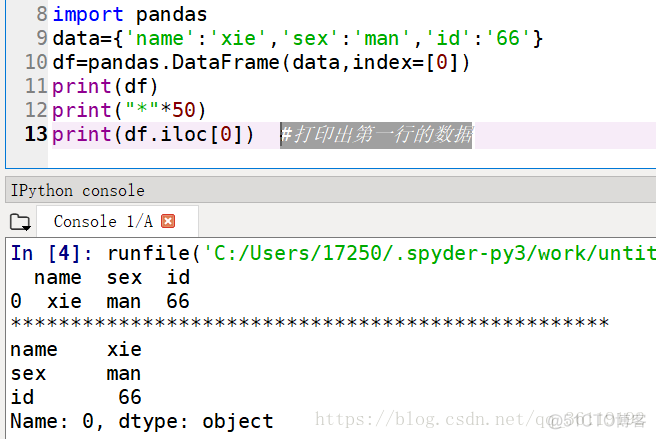
读取行
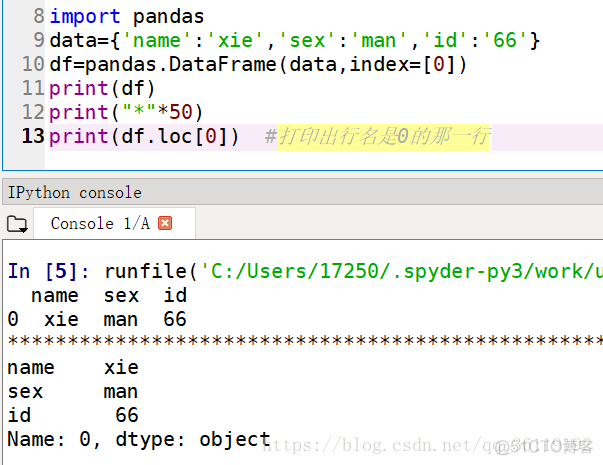
Panel
面板(Panel)是3D容器的数据。面板数据一词来源于计量经济学,部分源于名称:Pandas - pan(el)-da(ta)-s。
3轴(axis)这个名称旨在给出描述涉及面板数据的操作的一些语义。它们是
- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)
- major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列
Panel的创建函数:pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
参数
说明
data
数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个数据帧 DataFrame
items
axis=0
major_axis
axis=1
minor_axis
axis=2
dtype
每列的数据类型
copy
复制数据,默认 false
Panel的创建
创建一个空Panel序列
