论文介绍:Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching (跨模态置信度感知的图像文本匹配网络)AAAI 2022
主要优势:
1)首次提出跨模态置信度衡量机制,通过局部对齐语义与全局对齐语义的关系,进一步计算局部对齐语义是否被真正描述的可信程度。从而更加准确的实现细粒度的跨模态局部语义对齐。
2)提出一种新颖的置信度推理方法,以全局文本作为桥梁,计算局部图像区域是否被全局文本描述的置信度。
3)在主流数据集上取得SOTA性能。
一、前言
图像文本匹配任务定义:也称为跨模态图像文本检索,即通过某一种模态实例, 在另一模态中检索语义相关的实例。例如,给定一张图像,查询与之语义对应的文本,反之亦然。具体而言,对于任意输入的文本-图像对(Image-Text Pair),图文匹配的目的是衡量图像和文本之间的语义相似程度。

图1 图文匹配的输入和输出
核心挑战:图像文本跨模态语义关联致力于弥合视觉模态和语言模态之间的语义鸿沟,目的是实现异质模态(底层像素组成的图像和高层语义向量表示的文本)间的准确语义对齐,即挖掘和建立图像和文本的跨模态语义一致性关联对应关系。
现状分析:现有的图像文本图像文本匹配工作可以大致分为两类:1)全局关联:以整个文本和图像作为对象学习语义关联;2)局部关联:以细粒度的图像显著区域和文本单词作为对象学习语义关联。早期的工作属于全局关联,即将整个图像和文本通过相应的深度学习网络映射至一个潜在的公共子空间,在该空间中图像和文本的跨模态语义关联相似度可以被直接衡量,并且约束语义匹配的图文对相似度大于其余不匹配的图文对。然而,这种全局关联范式忽略了图像局部显著信息以及文本局部重要单词的细粒度交互,阻碍了图像文本语义关联精度的进一步提升。因此,基于细粒度图像区域和文本单词的局部关联受到广泛的关注和发展,并快速占据主导优势。对于现有的图像文本跨模态语义关联范式,核心思想是挖掘所有图像片段和文本片段之间的对齐关系。
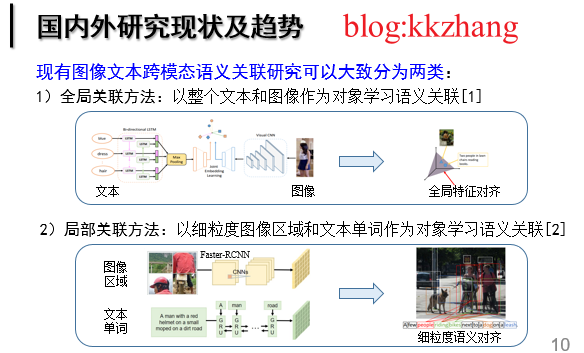
图2 图文匹配的发展现状
交叉注意力网络SCAN通过区域和单词之间的相互关注机制来捕捉所有潜在的局部对齐,并激发出了一系列工作。跨模态交叉注意力旨在挖掘所有图像区域和文本单词之间的对齐关系,通过局部语义对齐来推理整体相关性。得益 于细粒度的模态信息交互,基于交叉注意力的方法取得显著的性能提升,并成为当前图像文本跨模态语义关联的主流范式。
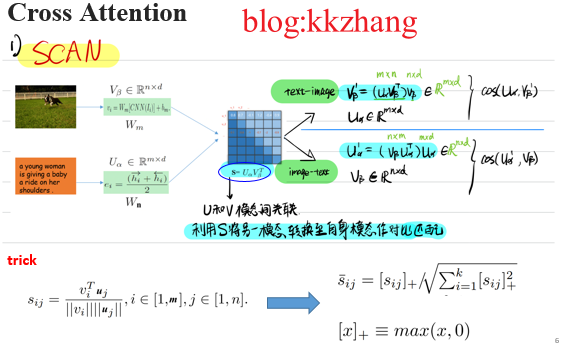
图3 跨模态交叉注意力范式SCAN
动机:现有的方法主要通过关联局部视觉-语义来匹配区域-单词,再机械地聚合区域-单词匹配对之间的局部语义相似度来衡量图像-文本的整体相关性。然而在现有的方法中,局部语义相似度,即区域-单词匹配对的相关性,被以默认的匹配置信度1被聚合,这是不合理的。因为匹配置信度,即区域-单词匹配对的可信程度,取决于全局图像-文本语义,相互间存在差异。也就是说,某局部区域-单词对虽然是匹配的,但它与全局的图像-文本语义并不一致,是不可信任的。因此,为了揭示局部语义相似度对整体跨模态相关性的真实合理的贡献水平,需要明确表示区域-单词对在匹配中的置信度。在不考虑置信度的情况下,与整体语义不一致的区域-单词匹配对将被不加区分地聚合,从而干扰整体相关性的度量。
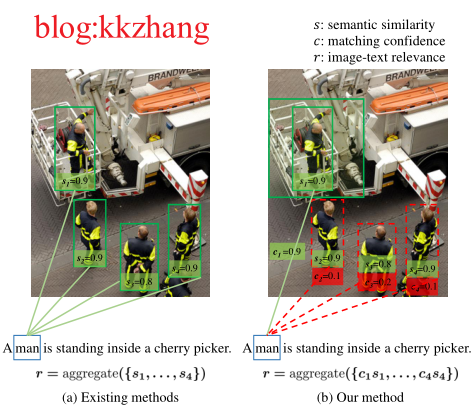
图4 动机示意图,通过进一步衡量每个局部对齐语义的置信程度,实现更加准确的跨模态对齐
二、总体框架
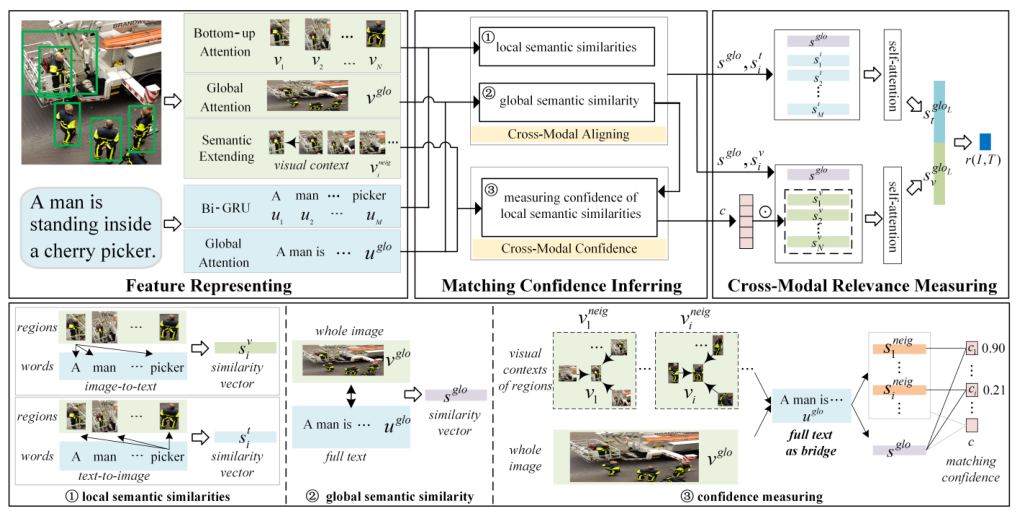
图5 总体框架
整个方法分为三部分:1)图像与文本特征表示;2)区域-单词匹配置信度推理;3)区分匹配置信度的跨模态相关性度量。对于给定的图像和文本,首先进行图像与文本的特征表示,以及各图像区域的视觉语义扩展,再以区域的视觉上下文和全文之间的语义相似度被包含在图像-文本的整体语义相似度中的程度,即该区域被文本所真正描述的相对程度,来推断其匹配置信度,最后根据置信度在整体相关性聚合中过滤掉与全局语义不一致的不可信局部对齐信息。
1:图像与文本特征表示
文本采用双向GRU编码。图像采用在Visual Genomes数据集上训练完备的以ResNet-101为骨干网络的Faster R-CNN目标检测器来抽取图像上36个显著区域的特征$\boldsymbol{x}_i$,然后将$\boldsymbol{x}_i$线性映射为共同嵌入空间中的视觉向量$\boldsymbol{v}_i$ 。图像的全局表征$\boldsymbol{v}^{glo}$通过以区域平均值$\boldsymbol{v}_{\text {ave}}=\frac{1}{N} \sum_{i=1}^{N} \boldsymbol{v}_{i}$为查询键的注意力机制来编码:
\begin{equation}
\boldsymbol{v}^{glo}=\frac{\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}}{\left\|\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}\right\|_{2}}
\label{eq:vis_glo}
\end{equation}
其中注意力权重$w_{i}$是$\boldsymbol{v}_{\text {ave}}$和区域特征$\boldsymbol{v}_{i}$的相似度。
视觉语义扩展:为了使图像区域的语义更可区分,进一步提取各区域的视觉上下文进行语义扩展。考虑到一个区域的周边场景通常包含与其相关的语义内容,设计以其周边区域作为视觉上下文来扩展该区域。具体地,对于区域$\boldsymbol{v}_i$ ,将其周围场景划分为上、下、左、右四个视域,从每个视域中提取距其最近的3个区域并收集相关的索引号为集合${idx}_i$。将区域$\boldsymbol{v}_i$ 的语义扩展形式化表示为:
\begin{equation}
\boldsymbol{v}_{i}^{neig}=\frac{\sum_{i \in \text{idx}_i} w_{i} \boldsymbol{v}_{i}}{\left\|\sum_{i=1}^{N} w_{i} \boldsymbol{v}_{i}\right\|_{2}}
\label{eq:vis_context}
\end{equation}
其中$w_{i}$和全局表征$\boldsymbol{v}^{glo}$中区域$\boldsymbol{v}_i$相应的注意力权重相同。注意:这里的聚合权重不需要学习,而是复用公式(1)中的权重$w_{i}$。
2:区域-单词匹配置信度推理
匹配置信度由图像-文本的整体语义相似度中包含区域的视觉上下文与全文的语义相似度的多少来推断。它表明了从整体图像的角度来看,文本对区域描述的相对程度。具体地,置信度是以整个文本为桥梁,由局部区域-文本的语义相似度和整张图像-文本的语义相似度的内积来衡量的。
1)跨模态对齐
为了刻画视觉和语言之间的详细对齐关系,跨模态对齐视觉-语义,采用规范化距离向量来表示异质模态间的语义相似度。具体地,图像区域$\boldsymbol{s}^{v}_i$ 和其匹配到的语义相关文本$\boldsymbol{a}^t_i$ 的局部语义相似度$\boldsymbol{s}^{v}_i$ 计算为:
\begin{equation}
\boldsymbol{s}^{v}_i=\frac{W_s^v|\boldsymbol{v}_i-\boldsymbol{a}^t_i|^{2}}{\left\|W_s^v|\boldsymbol{v}_i-\boldsymbol{a}^t_i|^{2}\right\|_{2}}
\end{equation}
其中$W_s^v \in \mathbb{R}^{P \times D}$ 是可学习参数矩阵。$\boldsymbol{s}^{v}_i$ 的文本模态上下文$\boldsymbol{a}^t_i$ 是 $\alpha_{i j} \boldsymbol{u}_{j}$的累加。其中
$\alpha_{i j}=\frac{e^{\left(\lambda \hat{c}_{i j}\right)}}{\sum_{i=1}^{K} e^{\left(\lambda \hat{c}_{i j}\right)}}$, $\hat{c}_{i j}=\left[c_{i j}\right]_{+} / \sqrt{\sum_{j=1}^{L}\left[c_{i j}\right]_{+}^{2}}$
,$c_{i j}$是图像区域 和单词 的余弦相似度。相似地,单词$\boldsymbol{s}^{u}_j$ 和其视觉模态上下文$\boldsymbol{a}^v_j$ 之间的语义相似向量 被计算为
$\boldsymbol{s}^{u}_j=\frac{W_s^u|\boldsymbol{u}_j-\boldsymbol{a}^v_j|^{2}}{\left\|W_s^u|\boldsymbol{u}_j-\boldsymbol{a}^v_j|^{2}\right\|_{2}}$。
进一步度量整张图像$\boldsymbol{v}^{glo}$和全文本 $\boldsymbol{u}^{glo}$的全局语义相似向量 :
\begin{equation}
\boldsymbol{s}^{glo}=\frac{W_s^g|\boldsymbol{v}^{glo}-\boldsymbol{u}^{glo}|^{2}}{\left\|W_s^g|\boldsymbol{v}^{glo}-\boldsymbol{u}^{glo}|^{2}\right\|_{2}}
\end{equation}
其中, $W_s^g \in \mathbb{R}^{P \times D}$是可学习参数矩阵。
2) 匹配置信度推理
当图像的显著区域被分开查看时,它们的视觉语义是片段化的,以至于局部对齐的区域-单词可能与全局的图像-文本语义不一致。置信度是指各区域的视觉语义和图像-文本全局视野的一致性程度,可以过滤掉和全局语义不一致的区域-单词匹配对。具体地,首先将区域$\boldsymbol{v}_{i}$ 扩展为它的视觉上下文 $\boldsymbol{v}_{i}^{neig}$,以使各区域 的语义更加可分。扩展的视觉上下文可以用来验证各区域在全文中被描述的程度
\begin{equation}
\boldsymbol{s}^{neig}_i=\frac{W_s^n|\boldsymbol{v}^{neig}_i-\boldsymbol{u}^{glo}|^{2}}{\left\|W_s^n|\boldsymbol{v}^{neig}_i-\boldsymbol{u}^{glo}|^{2}\right\|_{2}}
\end{equation}
,其中 $W_s^n \in \mathbb{R}^{P \times D}$是可学习参数矩阵。
参考给定的文本,全局文本语义中对整个图像的语义描述的程度可由 $s^{glo}$度量。以文本为桥梁,由全局语义对齐$\boldsymbol{s}^{glo}$ 和$\boldsymbol{s}^{neig}_i$ 来度量相应区域的匹配置信度$\epsilon_i$ :
\begin{eqnarray}
\epsilon_i = \boldsymbol{w}_{n}\left( \boldsymbol{s}^{glo} \odot \boldsymbol{s}^{neig}_i \right),\;i=1,2,\cdots,N \\
\boldsymbol{c} = \sigma\left(\operatorname{LayerNorm}\left([\epsilon_1,\epsilon_2,\cdots,\epsilon_N] \right)\right)
\end{eqnarray}
其中 , $\boldsymbol{w}_{n}\in \mathbb{R}^{1 \times P} $是可学习参数向量,$\odot$ 指示元素对应相乘操作, $\sigma$表示sigmoid函数, $\operatorname{LayerNorm}$表示层规范化操作。匹配置信度是由区域的视觉上下文和全文之间的语义相似度被包含在图像-文本的整体语义相似度中的程度推断出来的,它表明了该区域是否真的从全局的图像-文本的角度被描述的相对程度。
3:区分匹配置信度的跨模态相关性度量
为在图文匹配中区分区域-单词匹配对的置信度,过滤虽然局部匹配但在文本整体语义中没有真正提及区域相关的区域-单词对所贡献的局部语义相似度,即不可靠的区域-单词匹配对,首先将每个区域查询到的语义相似度 $\boldsymbol{s}^{v}_i$与其相应的 $c_i$相乘,并将全局语义相似度和被置信度缩放后的局部相似度集合为:
\begin{equation}
S_v=[\boldsymbol{s}^{glo}, c_1 \boldsymbol{s}^{v}_1, \cdots, c_N \boldsymbol{s}^{v}_N]
\end{equation}
同时,$\boldsymbol{s}^{glo}$和由单词查询到的语义相似度$\boldsymbol{s}^{t}_1, \boldsymbol{s}^{t}_2, \cdots, \boldsymbol{s}^{t}_M$被集合为$S_t=[\boldsymbol{s}^{glo}, \boldsymbol{s}^{t}_1, \cdots, \boldsymbol{s}^{t}_M]$。
分别在集合起来的$S_v$和$S_t$上应用多层自注意力推理,以便特定模态增强的全局对齐信息:
\begin{equation}
S^{l+1}=\operatorname{ReLU}\left(W_r^l\cdot\operatorname{softmax}\left(W_{q}^l S^{l} \cdot\left(W_{k}^l S^{l}\right)^{\top}\right) \cdot S^{l}\right)
\label{eq:atten_qk}
\end{equation}
进一步地,拼接最后第L层的视觉增强的全局语义相似度$\boldsymbol{s}_v^{glo_L}$ 和语言增强的全局语义相似度$\boldsymbol{s}_t^{glo_L}$ ,并将拼接向量输入到由sigmoid函数激活的全连接层来计算图像 $I$ 和文本 $T$ 之间的跨模态相关性 :
\begin{equation}
r(I,T) =\sigma \left(\boldsymbol{w}_s\left([\boldsymbol{s}^{{glo}_L}_v:\boldsymbol{s}^{{glo}_L}_t]\right)\right)
\label{eq:sim}
\end{equation}
其中$\boldsymbol{w}_s \in \mathbb{R}^{1 \times {2P}}$是将拼接全局对齐信息映射为标量相关性的可学习参数。
三、试验效果
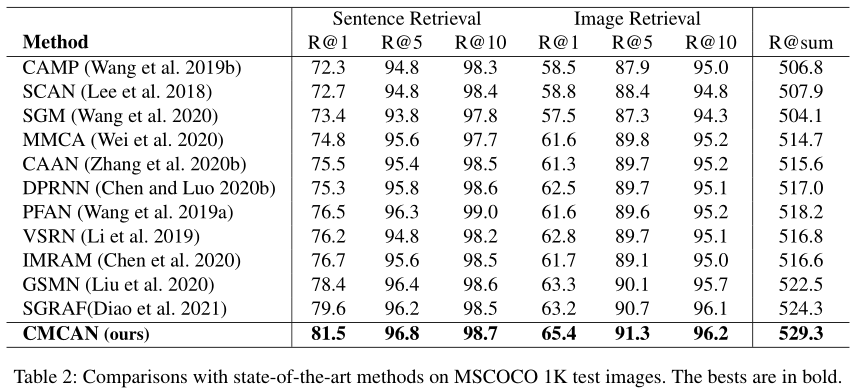
1、在主流数据集Flickr30K和MSCOCO上取得SOTA性能:

2、置信度可视化

四、参考论文
Zhang H, Mao Z, Zhang K, et al. Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching[C]// Proceedings of the AAAI conference on artificial intelligence. 2022.
【文章原创作者:阿里云代理商 http://www.558idc.com/aliyun.html 网络转载请说明出处】