上篇主要对 Synchronized 的锁实现原理 Monitor 机制进行了介绍,由于 Monitor 基于操作系统调用,上下文切换导致开销大,在竞争不激烈时性能不算很好, 在 jdk6 之后进了系列优化。前文对优化措施进行了简单介绍,下面将一一介绍这些优化的细节,行文思路大致如下:
- 从重量级锁的优化开始讲,一是自旋锁,二是尽量避免进入 Monitor ,即使用轻量级锁
- 讲解轻量级锁及加锁解锁流程
- 轻量级锁在没有竞争时,每次重入仍然需要执行cas操作,为解决这个问题,因而产生了偏向锁
- 详细介绍偏向锁
自旋锁比较简单,逻辑在上篇也已经进行过阐述,这一篇章我们着重看下它的性能如何?
在竞争度较小的时候,重量级锁的上下文切换导致的开销相对于 CPU 处理任务的时间占比较重,此种情况下,自旋锁的性能有优势,因自旋而导致的 CPU 浪费在可接受范围内;当竞争激烈的时候,继续使用自旋锁则得不偿失,性能上比直接使用重量级锁要差,大量的等待锁的时间被浪费。
根据任务处理时间不同,自旋锁表现也不一,在任务持续时间长的情况下,自旋太久显然是对 CPU 时间片的浪费,且因任务持续时间长,在 10 此默认自旋次数的情况下,易出现自旋结束也无法获取到锁,那么此次空转就是毫无收益的性能浪费。在任务处理时间较短的情况下,显然自旋获得锁的几率要大,因此如果对要执行的任务有很明确的处理时长认知,可以根据情况适当的调整初始自旋次数,JVM 参数为:-XX:PreBlockSpin。
根据观察,多线程中并不总是存在着竞争,使用轻量级锁避免了锁 Monitor 这繁重的数据结构,轻量级锁通常只锁一个字段(锁记录),在 HotSpot 中的实现是在当前线程的栈帧中创建锁记录结构(Lock Record)。
1.轻量级锁加锁流程- 在当前线程的栈帧中创建 Lock Record
- 构建一个无锁状态的 Displaced Mark Word
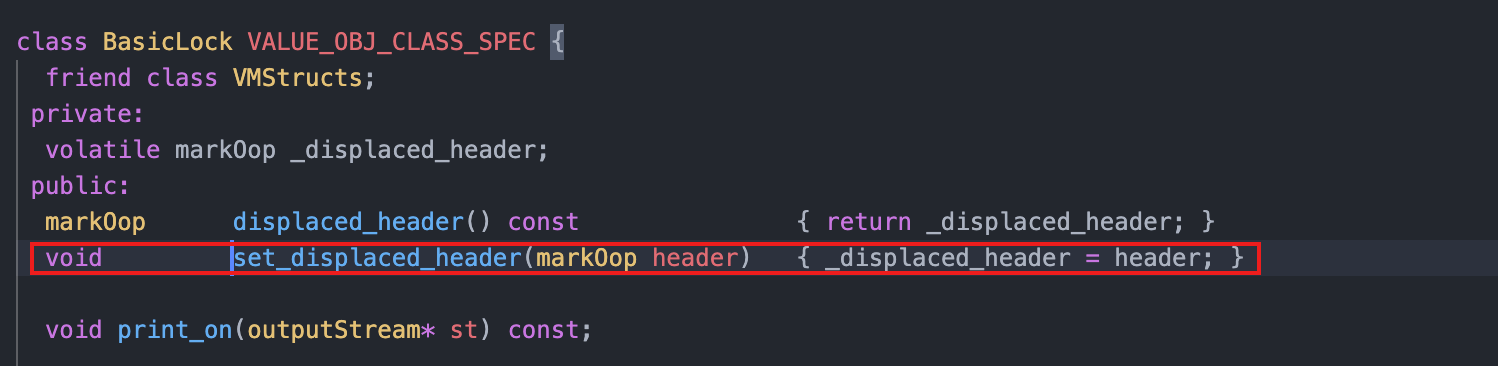
- 将 Displaced Mark Word 存储到 Lock Record 中的 _displaced_header 属性
- CAS 更新 Displaced Mark Word 指针,注意【3】是将 Lock record 的 header 的值设置成一个 displaced mark word,【4】这一步是将当前对象头的 Mark Word 中的高30 位(全文都是只针对 32 位虚拟机来谈)指向 Lock Record 中的 header。
4.1 CAS 成功,执行同步代码块
4.2 CAS 失败,存在两种情况
3.2.1 判断是否为锁重入(关于轻量级锁的可重入有疑问,见下文)
3.2.2 锁被其他线程占有,需要竞争锁,进入锁膨胀过程 - 加锁成功的话,当前对象的 Mark Word 后两位锁标志位置为 00,余下高位作为指针存储 Lock Record 的地址
轻量级锁加锁源码如下:
// traditional lightweight locking
if (!success) {
// markOop就是对象头结构, 生成对象头,这个对象头的状态设置为无锁,生成的这个对象头就是displaced Mark word
markOop displaced = lockee->mark()->set_unlocked();
// 将 displaced Mark word 设置到 lock record 的 _displaced_header 字段
entry->lock()->set_displaced_header(displaced);
// 判断JVM参数-XX:+UseHeavyMonitors 是否设置了只有重量级锁
bool call_vm = UseHeavyMonitors;
// cmpxchg_ptr即 cas 交换指令,将当前对象头的 Mark Word 中的高30 位指向 Lock Record 中的 header 使用重量级锁或者CAS 失败进入这个if块
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// Is it simple recursive case? 是否为锁重入
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
entry->lock()->set_displaced_header(NULL);
} else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
关于轻量级锁的重入,实现方式主要有两种,一是如 Monitor 一样通过一个变量来计数,二是每重入一次都生成一个 Lock Record,对Lock Record 的个数计数来隐士计数。在查找资料的过程中发现,大部分的说法是 HotSpot 选择第二种实现方式。
- 第一个疑问是为何会选择第二种实现方式,是否对空间造成了一定的浪费,生成 Lock Record 相比整型加一操作性能消耗应该也更大,不知道 HotSpot 作何考量选择此种方式。下图为此种实现方式下的轻量级锁结构。
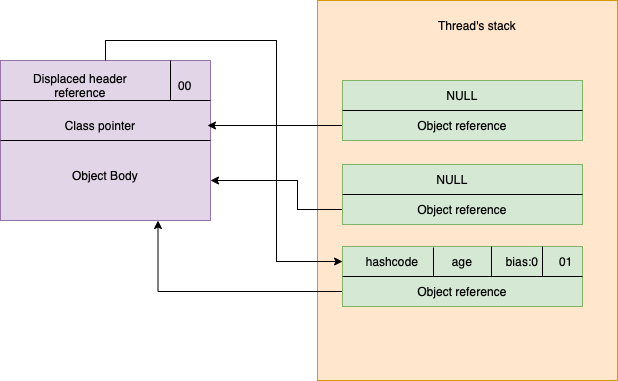

- 遍历栈的Lock Record,如果_displaced_header 为 NULL,表明锁是可重入的,跳过不作处理
- 如果_displaced_header 不为 NULL,即最后一个锁记录,调用 CAS 将 _displaced_header 恢复到当前对象头,解锁成功
It also follows the principle of optimizing com- mon cases. The observation exploited is the biased distri- bution of lockers called thread locality. That is, for a given object, the lock tends to be dominantly acquired and re- leased by a specific thread, which is obviously the case in single-threaded applications [2]
根据观察结果来看,多线程下很多时候会出现以下情况:一个线程在频繁的释放和加锁;即多线程实际上已经退化成了单线程线性运行,在这种情况下,减少 CAS 这种原子操作,也能提高性能。偏向锁的原理是为线程保留锁,Mark Word 中存储 ThreadId,只有第一次需要进行 CAS 操作将这个字段设置为当前线程的线程ID,后续加锁的时候只需要查看 ThreadId 是否指向自己,而轻量级锁每次锁字段都需要进行 CAS 操作。
1.偏向锁加锁流程如下:- 检查锁是否可偏向,对象头低位倒数第三位为1(即后三位的值为 0x5)表明可偏向
- 如果可偏向,首先判断 Mark Word 的内容是否是当前线程ID,
2.1 是,执行同步代码
2.2 不是,执行 CAS 将 Mark Word 的高位设置为当前线程ID, CAS 执行分以下情况:
2.2.1 执行成功,则加锁成功
2.2.2 执行失败,说明此锁已经偏向了其他线程,因为产生了竞争所以撤销偏向锁,进入轻量级锁加锁流程

由于Hash码必须是唯一的,即 hashcode() 方法只能被调用一次,因此产生了以下规则来保证hash code 的唯一性:
- HashCode 是懒加载,当调用 hashcode() 方法的时候,生成的 hash code 才会保存到对象头指定位置
- 当一个对象已经调用过 hashcode() 方法,那么偏向锁状态会置为0,无法进入偏向锁状态,直接进入轻量级锁
- 如果一个对象现在已经处于偏向锁状态,在同步代码块中需要执行 hashcode() 方法,则偏向锁会撤销,进入重量级锁
在无锁状态下,如果没有调用 hashcode() ,高 25 位未使用,如果调用过 hashcode(),则保存的是 hash code,只有当高 25 位未使用时,才能进入偏向锁,mark word 保存获取到锁的线程ID,当锁撤销的时候,恢复为无锁状态,即高 25 位为 NULL。

在一些博客中发现以下说法:使用偏向锁时,每重入一次创建一个Lock Record。这个说法毫无疑问是错误的,偏向锁在重入的时候只检查 ThreadId,是自己的线程 Id 就可以执行同步代码块;解锁则只需要看是否是偏向模式,因此完全没有必要进行重入计数,生成 Lock Record 来计数就更没有这个必要了。
5.什么时候偏向锁不可用- 升级为轻量级锁之后,当一个线程持有锁,另一个线程来竞争锁的时候 CAS 失败,就会将低三位 101 设置为 001,即不可偏向,这也是锁可升级不可降级的原因。
- 发生了批量撤销后,就不会再进入偏向锁了
JDK 15 开始默认不使用偏向锁,且相关的命令行指令被标记为过时

Biased locking introduced a lot of complex code into the synchronization subsystem and is invasive to other HotSpot components as well. This complexity is a barrier to understanding various parts of the code and an impediment to making significant design changes within the synchronization subsystem. To that end we would like to disable, deprecate, and eventually remove support for biased locking.[3]
偏向锁在同步子系统中引入了许多复杂的代码,并且还侵入了其他 HotSpot 组件。这种复杂性造成了对代码各个部分的理解障碍,也阻碍了同步子系统进行重大设计更改。为此,我们希望禁用、弃用并最终移除对偏向锁的支持。
偏向锁的撤销 1.何为撤销?撤销是指当对象处于偏向锁模式的时候,不再使用偏向锁,且标记不可偏向(低位 001);注意撤销不是常规意义上的解锁,偏向锁的解锁是当锁处于偏向锁状态时,同步块执行完毕,需要对锁进行释放,只需要检查是否处于已偏向(此处检查两个参数,一是偏向位即低位倒数第三位为1,为 1 即表示可偏向也可表示已偏向,故还需要检查 ThreadID 不为空),如果处于偏向锁模式,则直接 return 释放锁成功。撤销与解锁的区别是撤销需要将偏向锁标识位置为0,标记该对象不可偏向。
撤销操作不是必须在安全点操作,首先会尝试在不安全点使用 CAS 操作修改 Mark Word 为无锁状态,如果尝试失败会等待在安全点(JVM 概念)撤销,等待安全点的操作开销很大,即需要STW。
- 线程 A 首先获取了偏向锁,此时来了线程 B 尝试对锁偏向,发现锁已经被偏向 A 线程,B 线程会触发锁的偏向撤销并进一步膨胀成轻量级锁。
- 触发了批量撤销
- 调用 wait()/notify() 触发重量级锁
当一个类产生了大量对象,在线程 A 访问这些对象时,所有对象偏向A,线程 A 释放锁后,线程 B 访问这些所有对象,每个对象都会触发锁的撤销升级成轻量级锁,这个撤销的次数达到一定阈值(默认20次),JVM 就会把该类产生的所有对象的偏向状态偏向到 B,这就是批量重偏向。批量重偏向的重点即避免进入轻量级锁,由于 A B的竞争导致多个对象都进入了轻量级锁,而通过撤销的阈值判断发现大多数线程都偏向了 B,那么只需要将此类的所有对象都修改成偏向 B 就可以大概率的避免进入轻量级锁。
举个例子:一个类一共生成了30个对象,A 线程访问了 30 个,这 30 个对象都偏向 A,接着 B 只访问了 25 个对象,前20个对象都由于竞争升级成了轻量级锁,由于超过阈值 20 触发了批量重偏向,后续 10 个对象的偏向线程 ID 也被修改为线程 B,线程 B 访问第 21 个之后的对象都只需要使用偏向锁,无需使用轻量级锁。
与批量重偏向同理,都是某个类的对象频繁撤销锁偏向,撤销次数达到一定阈值(默认40次),就会触发以下操作:将次类的对象的偏向锁标记置为 0,即锁不再可偏向,新建的对象也是不可偏向的,若再次发生锁竞争,直接进入轻量级锁。
可以看到,批量重偏向和批量撤销的操作是都是对撤销操作的优化,批量重偏向是第一阶段的优化,批量撤销是在第一阶段优化没有奏效的情况下第二阶段的优化,所以很明显,批量撤销的阈值应该设置的比批量重偏向的大。
Synchronized 的原理和优化就暂且讲到这,两篇文章主要都是对概念的介绍、各个状态的锁的结构介绍和阐述简化后的流程。还有诸多细节没有进行叙述,例如重量级锁就没有讲到重入、锁膨胀的过程、偏向撤销的流程、串联起来整个加锁的流程,如此种种细节皆略过了,一是精力有限,二是水平有限(个人拙见,要理清这些细节和流程必须自己亲自看源码,然现阶段读 C ++ 源码略为吃力),故而等后续有更多的理解后再补充。文中必然有疏漏或是错误,若有发现,还请海涵并指正。
Reference[1] Evaluating and improving biased locking in the HotSpot virtual machine.
[2] Lock Reservation: Java Locks Can Mostly Do Without Atomic Operations
[3] [JEP 374: Deprecate and Disable Biased Locking]: https://openjdk.org/jeps/374