前言: 用CSDN这么久了,为了更好的回忆我在CSDN的过往,我想了想要不把我发过的文章信息都扒下来吧,然后用了小半个小时研究了一下,主要是爬虫代码,毕竟我只是爬完自己的,这个
前言:
用CSDN这么久了,为了更好的回忆我在CSDN的过往,我想了想要不把我发过的文章信息都扒下来吧,然后用了小半个小时研究了一下,主要是爬虫代码,毕竟我只是爬完自己的,这个爬虫只要传入博主的主页链接就OK了,后续什么数据分析大家可以获取更多用户名称后再for循环存储,嘎嘎香,今天先来个初级版本
思路:
先分析json返回内容,一层层获取文章信息,然后一次性把所有文章信息获取下来保存到CSV文件中,前期分析时可以边分析边输出查看内容
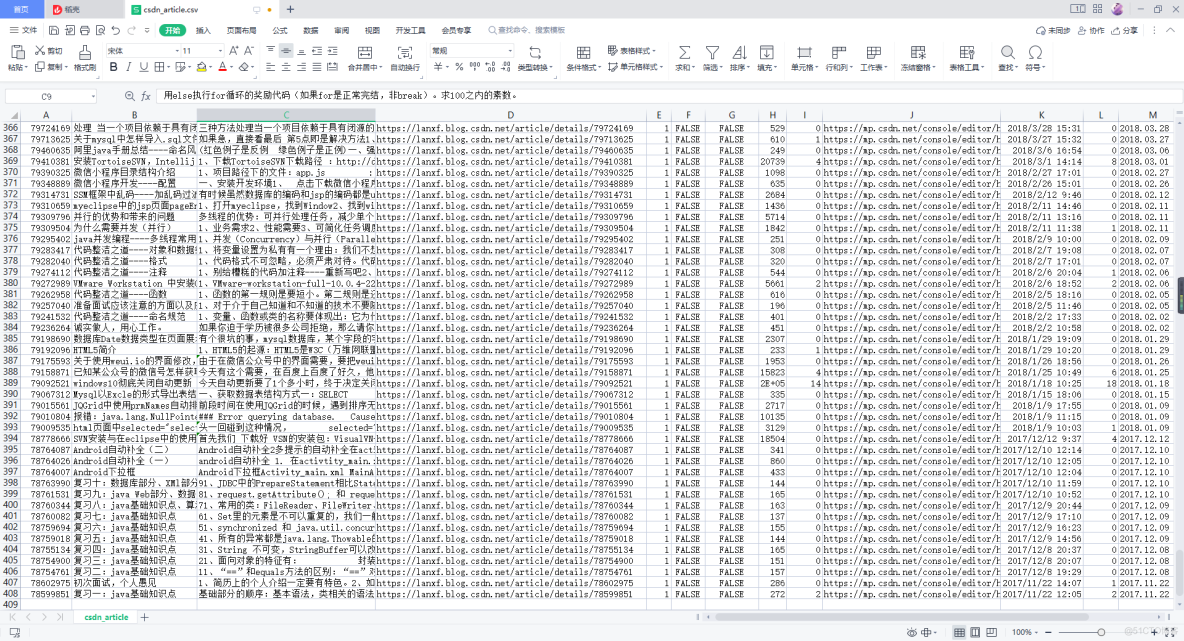
1、先来看一下存储结果
2、现在来分析网页找到json文件
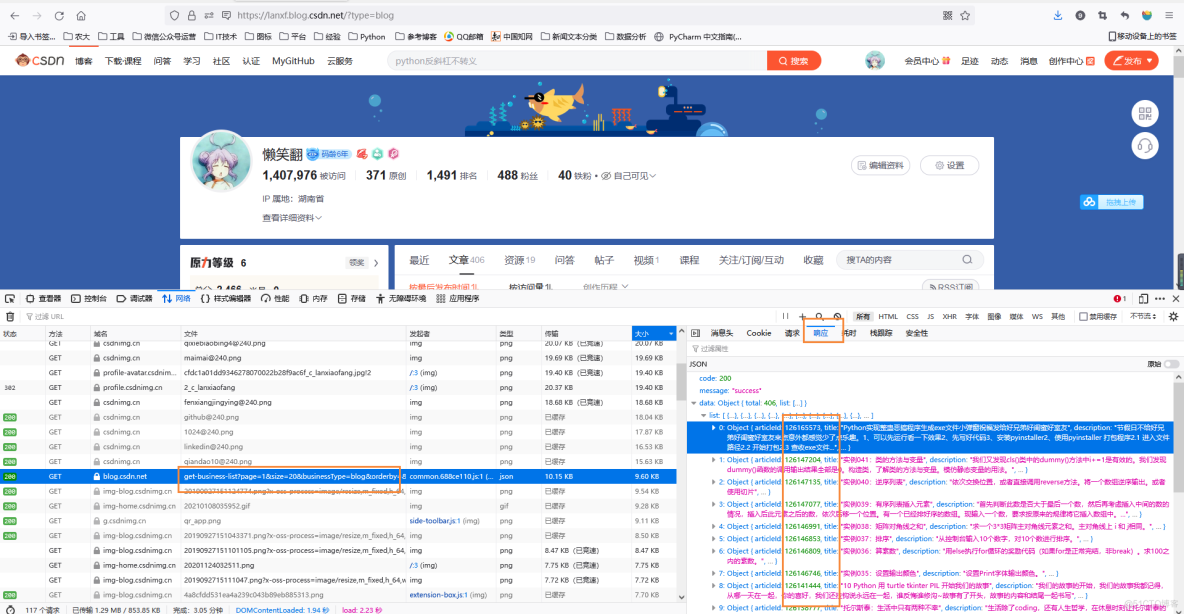
看响应信息,很快就能找到目的,复制网址到代码中
3、代码
"""* @Author: xiaofang
* @Description: 存储csdn文章数据,传入主页链接即可
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
import csv
articleid_list = [] # 用来存储我所有的文章编号
# 打开一个文件,假设是info.csv,写入所以是w
# newline='',写入时需要指定
fo = open("csdn_article.csv", "w", encoding='utf-8', newline='')
# 将表头存储到一个列表里
header = ["articleId", "title", "description", 'url', 'type', 'top', 'forcePlan', 'viewCount', 'commentCount',
'editUrl', 'postTime', 'diggCount', 'formatTime']
# 创建一个DictWriter对象,第二个参数就是上面创建的表头
csv_writer = csv.writer(fo)
csv_writer.writerow(header)
# 写入一行记录,以字典的形式,key需要与表头对应
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Referer": "https://lanxf.blog.csdn.net/?type=blog",
}
# 获取文章信息的list
def get_article_list(page):
url = "https://blog.csdn.net/community/home-api/v1/get-business-list?page={}&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=c_lanxiaofang".format(
page)
res = requests.get(url, headers=headers).json()
article_list = res["data"]["list"]
return article_list
# 获取文章信息
def get_article_info(article_list):
for al in article_list:
print(al)
articleId = al['articleId'] # 文章id
articleid_list.append(articleId)
title = al['title'] # 文章标题
description = al['description'] # 描述
url = al['url'] # 访问链接
type = al['type'] #
top = al['top'] # 是否置顶
forcePlan = al['forcePlan']
viewCount = al['viewCount'] # 浏览数
commentCount = al['commentCount'] # 评论数
editUrl = al['editUrl']
postTime = al['postTime']
diggCount = al['diggCount']
formatTime = al['formatTime']
csv_writer.writerow(
[articleId, title, description, url, type, top, forcePlan, viewCount, commentCount, editUrl, postTime,
diggCount, formatTime])
# 有408篇 20篇一页,所以来21页
for i in range(1, 22):
article_list = get_article_list(i)
get_article_info(article_list)
# 关闭文件
fo.close()
print("下载完成!!!")
print(articleid_list)