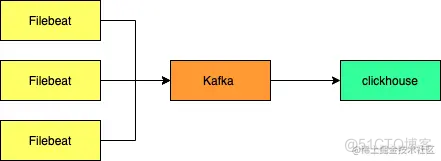
背景
saas服务未来会面临数据安全、合规等问题。公司的业务需要沉淀一套私有化部署能力,帮助业务提升行业竞争力。为了完善平台系统能力、我们需要沉淀一套数据体系帮助运营分析活动效果、提升运营能力。然而在实际的开发过程中,如果直接部署一套大数据体系,对于使用者来说将是一笔比较大的服务器开销。为此我们选用折中方案完善数据分析能力。
elasticsearch vs clickhouse
ClickHouse是一款高性能列式分布式数据库管理系统,我们对ClickHouse进行了测试,发现有下列优势:
ClickHouse写入吞吐量大,单服务器日志写入量在50MB到200MB/s,每秒写入超过60w记录数,是ES的5倍以上。在ES中比较常见的写Rejected导致数据丢失、写入延迟等问题,在ClickHouse中不容易发生。
查询速度快,官方宣称数据在pagecache中,单服务器查询速率大约在2-30GB/s;没在pagecache的情况下,查询速度取决于磁盘的读取速率和数据的压缩率。经测试ClickHouse的查询速度比ES快5-30倍以上。
ClickHouse比ES服务器成本更低。一方面ClickHouse的数据压缩比比ES高,相同数据占用的磁盘空间只有ES的1/3到1/30,节省了磁盘空间的同时,也能有效的减少磁盘IO,这也是ClickHouse查询效率更高的原因之一;另一方面ClickHouse比ES占用更少的内存,消耗更少的CPU资源。我们预估用ClickHouse处理日志可以将服务器成本降低一半。
支持功能\开源项目
ElasticSearch
ClickHouse
查询
java
c++
存储类型
文档存储
列式数据库
分布式支持
分片和副本都支持
分片和副本都支持
扩展性
高
低
写入速度
慢
快
CPU/内存占用
高
低
存储占用(54G日志数据导入)
高 94G(174%)
低 23G(42.6%)
精确匹配查询速度
一般
快
模糊匹配查询速度
快
慢
权限管理
支持
支持
查询难度
低
高
可视化支持
高
低
使用案例
很多
携程
维护难度
低
高
成本分析
备注:在没有任何折扣的情况下,基于aliyun分析
成本项
标准
费用
说明
总费用
zookeeper 集群
2核4g 共享计算型 n4 50G SSD 云盘
222/月
3台高可用
666/月
kafka 集群
4核 8g 共享标准型 s650G SSD 云盘300G 数据盘
590/月
3台高可用
1770/月
filebeat 部署
混部相关的应用,会产生一定的内存以及磁盘开销,对应用的可用性会造成一定的影响。
clickhouse
16核32g 共享计算型 n450G SSD 云盘1000G 数据盘
2652/月
2台高可用
5304/月
总费用
7740/月
环境部署
zookeeper 集群部署

yum install java-1.8.0-openjdk-devel.x86_64
/etc/profile 配置环境变量
更新系统时间
yum install ntpdate
ntpdate asia.pool.ntp.org
mkdir zookeeper
mkdir ./zookeeper/data
mkdir ./zookeeper/logs
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
tar -zvxf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/apache-zookeeper-3.7.1-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
进入ZooKeeper配置目录
cd $ZOOKEEPER_HOME/conf
新建配置文件
vi zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/data
dataLogDir=/usr/zookeeper/logs
clientPort=2181
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888
在每台服务器上执行,给zookeeper创建myid
echo "1" > /usr/zookeeper/data/myid
echo "2" > /usr/zookeeper/data/myid
echo "3" > /usr/zookeeper/data/myid
进入ZooKeeper bin目录
cd $ZOOKEEPER_HOME/bin
sh zkServer.sh start
Kafka 集群部署
mkdir -p /usr/kafkachmod 777 -R /usr/kafka
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.2.0/kafka_2.12-3.2.0.tgz
tar -zvxf kafka_2.12-3.2.0.tgz -C /usr/kafka
不同的broker Id 设置不一样,比如 1,2,3
broker.id=1
listeners=PLAINTEXT://ip:9092
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dir=/usr/kafka/logs
num.partitions=5
num.recovery.threads.per.data.dir=3
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zookeeper.connection.timeout.ms=30000
group.initial.rebalance.delay.ms=0
后台常驻进程启动kafka
nohup /usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-start.sh /usr/kafka/kafka_2.12-3.2.0/config/server.properties >/usr/kafka/logs/kafka.log >&1 &
/usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-stop.sh
$KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server ip:9092
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --topic test --from-beginning
$KAFKA_HOME/bin/kafka-topics.sh --create --bootstrap-server ip:9092 --replication-factor 2 --partitions 3 --topic xxx_data
FileBeat 部署
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearchCreate a file with a .repo extension (for example, elastic.repo) in your /etc/yum.repos.d/ directory and add the following lines:
在/etc/yum.repos.d/ 目录下创建elastic.repo
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
yum install filebeat
systemctl enable filebeat
chkconfig --add filebeat
FileBeat 配置文件说明,坑点1(需设置keys_under_root: true)。如果不设置kafka的消息字段如下:
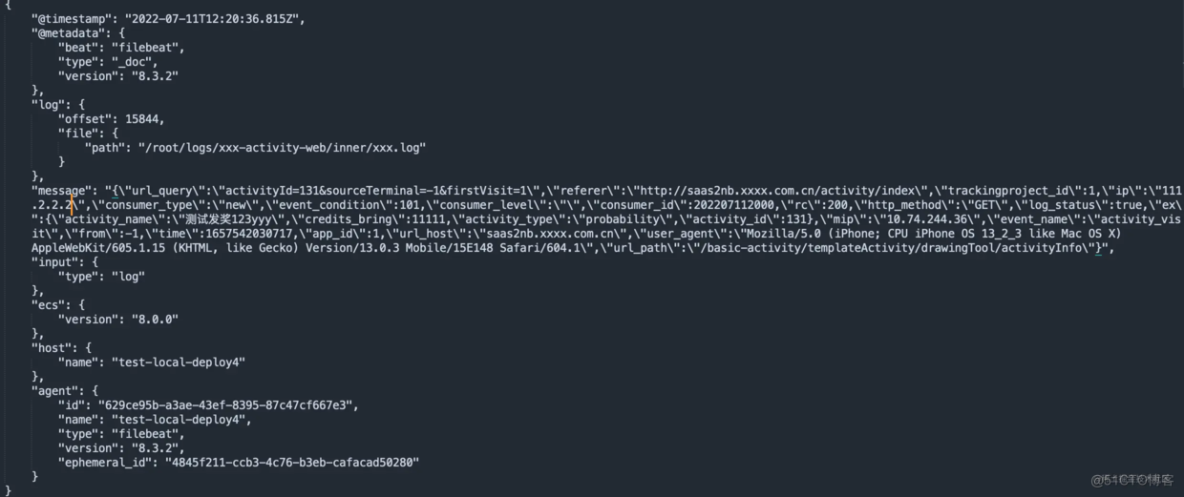
filebeat.inputs:
- type: log
enabled: true
paths:
- /root/logs/xxx/inner/*.log
json:
如果不设置该索性,所有的数据都存储在message里面,这样设置以后数据会平铺。
keys_under_root: true
output.kafka:
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
topic: 'xxx_data_clickhouse'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
processors:
剔除filebeat 无效的字段数据
- drop_fields:
fields: ["input", "agent", "ecs", "log", "metadata", "timestamp"]
ignore_missing: false
nohup ./filebeat -e -c /etc/filebeat/filebeat.yml > /user/filebeat/filebeat.log &
输出到filebeat.log文件中,方便排查
clickhouse 部署

grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
返回 "SSE 4.2 supported" 表示支持,返回 "SSE 4.2 not supported" 表示不支持
创建数据保存目录,将它创建到大容量磁盘挂载的路径
mkdir -p /data/clickhouse
修改/etc/hosts文件,添加clickhouse节点
举例:
10.190.85.92 bigdata-clickhouse-01
10.190.85.93 bigdata-clickhouse-02
服务器性能参数设置:
cpu频率调节,将CPU频率固定工作在其支持的最高运行频率上,而不动态调节,性能最好
echo 'performance' | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
内存调节,不要禁用 overcommit
echo 0 | tee /proc/sys/vm/overcommit_memory
始终禁用透明大页(transparent huge pages)。 它会干扰内存分配器,从而导致显着的性能下降
echo 'never' | tee /sys/kernel/mm/transparent_hugepage/enabled
首先,需要添加官方存储库:
yum install yum-utils
rpm --import <https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG>
yum-config-manager --add-repo <https://repo.clickhouse.tech/rpm/stable/x86_64>
查看clickhouse可安装的版本:
yum list | grep clickhouse
运行安装命令:
yum -y install clickhouse-server clickhouse-client
修改/etc/clickhouse-server/config.xml配置文件,修改日志级别为information,默认是trace
<level>information</level>
执行日志所在目录:
正常日志
/var/log/clickhouse-server/clickhouse-server.log
异常错误日志
/var/log/clickhouse-server/clickhouse-server.err.log
查看安装的clickhouse版本:
clickhouse-server --version
clickhouse-client --password
sudo clickhouse stop
sudo clickhouse tart
sudo clickhouse start
总结
整个部署的过程踩了不少坑,尤其是filebeat yml的参数设置。clickhouse 的配置说明我会再更新一篇跟大家同步一下过程中踩的坑。很久没有更新博客了,经常看到博客35岁以后怎么办的问题。说实话我自己也没想好以后怎么办,核心还是持续的学习&输出。不断的构建自己的护城河,不管是技术专家、业务专家、架构、管理等。个人建议如果能持续写代码就奋战在一线,管理彻底与公司绑定。除非你是有名的大厂,这另外看。如果所在的公司缺乏较大的行业影响力,个人感觉可以奋战在一线,未来选择新的工作。考量更多的还是行业影响、商业sense、技术架构能力。