Elasticsearch分布式大数据搜索集群
@[TOC]
1.elasticsearch集群介绍
elasticsearch可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级别数据
elasticsearch天生就是分布式的,并且在设计时屏蔽了分布式的复杂性
elasticsearch经肯屏蔽了风不是系统的复杂性
elasticsearch集群的特点:
- 分配文档到不同的容器或分配中,文档可以存储一个或多个节点
- 按集群节点来负载均衡这些分配,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任意节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合性节点,重新分配分片以便于从群节点中恢复
一个运行中的elasticsearch实例被称为一个节点,而集群是由一个或多个拥有相同cluster.name配置的节点组成,他们共同承担数据和负载的压力
当有节点加入集群或者从集群中移除节点时,集群将会重新平均分布所有的数据
当一个节点被选举称为主节点时,它将负责管理集群范围内所有的变更,例如增加、删除索引或者增加、删除节点等,而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个节点的情况下,即使流量增加它也不会成为瓶颈,任何节点都可以成为主节点,我们的实例集群只有一个节点,所以同时也成为了主节点,也就是谁先部署完并启动了第一个节点,谁就是master
作为用户,我们可以将请求发送到集群中的任何节点,包括主节点,每个节点的数据都是一样的,每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点,无论我们将请求发送到那个节点,它都能负责从各个包含我们所需文档节点进行收集,并将数据结果返回给客户端
文档doc就是索引中的一条数据
es集群搭建完后将不在往elasticsearch.log中写日志,而是在集群名.log中写日志
2.elasticsearch集群部署
2.1.192.168.81.210主节点配置
集群配置文件含义
cluster.name: es-application #集群名称,要求唯一node.name: node-1 #节点名称path.data: /data/elasticsearch #数据存储路径path.logs: /var/log/elasticsearch #日志路径network.host: 192.168.81.210,127.0.0.1 #对外暴露的地址http.port: 9200 #端口号discovery.zen.ping.unicast.hosts: ["192.168.81.210", "192.168.81.220"] #主节点要配置上集群各节点ip地址,从节点配置的时候只写上主节点的ip和自己节点的ip即可discovery.zen.minimum_master_nodes: 1 #允许master的数量http.cors.enabled: truehttp.cors.allow-origin: "*"
2.1.1.安装elasticsearch
所有节点都要安装
1.准备Java环境 yum -y install java java -version 2.下载elasticsearch rpm包 mkdir soft cd soft wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.rpm 3.安装elasticsearch yum -y localinstall elasticsearch-6.6.0.rpm 4.启动elasticsearch systemctl daemon-reload systemctl start elasticsearch systemctl enable elasticsearch2.1.2.配置node-1主节点
1.修改主配置文件 [root@elasticsearch ~]# vim /etc/elasticsearch/elasticsearch.yml cluster.name: es-application node.name: node-1 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.81.210,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.81.210", "192.168.81.220"] discovery.zen.minimum_master_nodes: 1 http.cors.enabled: true http.cors.allow-origin: "*" 2.重启 [root@elaticsearch ~]# systemctl restart elasticsearch2.1.3.访问node-1节点
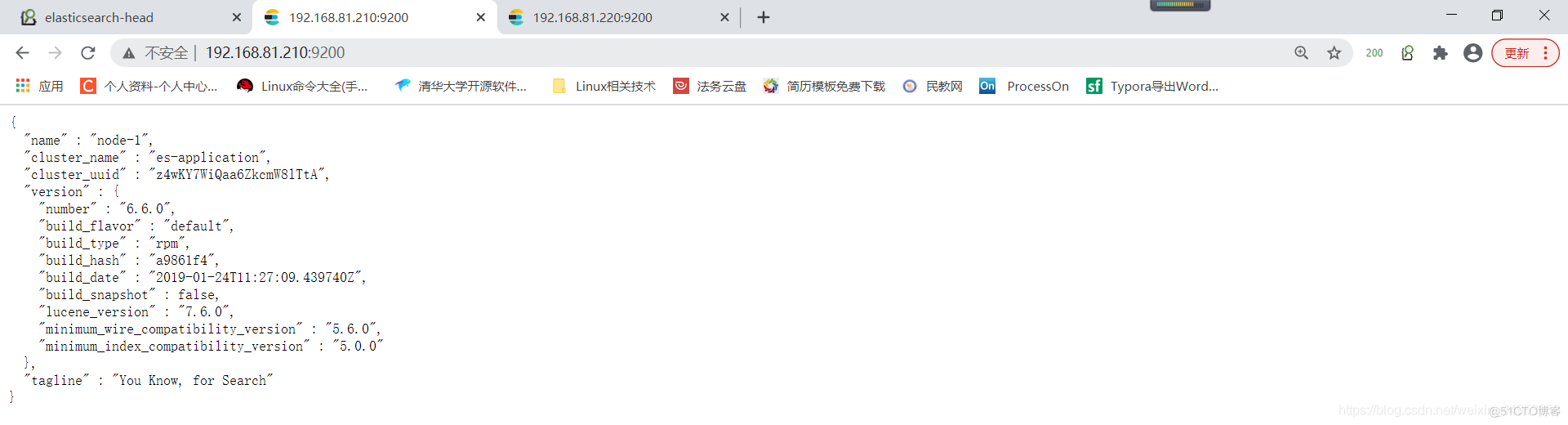
访问:http://192.168.81.210:9200
2.2.192.168.81.220从节点配置
2.2.1.安装elasticsearch
1.准备Java环境 [root@node-2 ~]# yum -y install java [root@node-2 ~]# java -version openjdk version "1.8.0_262" OpenJDK Runtime Environment (build 1.8.0_262-b10) OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode) 2.下载elasticsearch rpm包 [root@node-2 ~]# mkdir soft [root@node-2 ~]# cd soft [root@node-2 soft]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.rpm [root@elasticsearch soft]# ll -h -rw-r--r--. 1 root root 109M 11月 15 08:58 elasticsearch-6.6.0.rpm 3.安装elasticsearch [root@node-2 soft]# yum -y localinstall elasticsearch-6.6.0.rpm 4.启动elasticsearch [root@node-2 soft]# systemctl daemon-reload [root@node-2 soft]# systemctl start elasticsearch [root@node-2 soft]# systemctl enable elasticsearch2.2.2.配置node-2节点
1.修改配置文件 [root@node-2 ~]# vim /etc/elasticsearch/elasticsearch.yml cluster.name: es-application node.name: node-2 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.81.220,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.81.210", "192.168.81.220"] discovery.zen.minimum_master_nodes: 1 http.cors.enabled: true http.cors.allow-origin: "*" 2.重启 [root@node-2 ~]# systemctl restart elasticsearch2.2.3.访问node-2节点
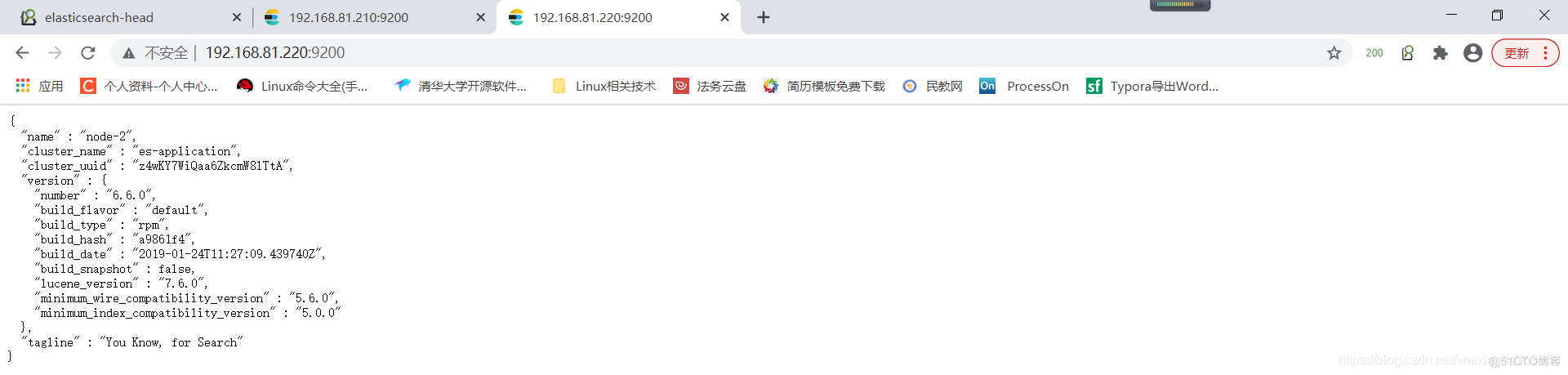
访问:http://192.168.81.220:9200
2.3.查看集群状态
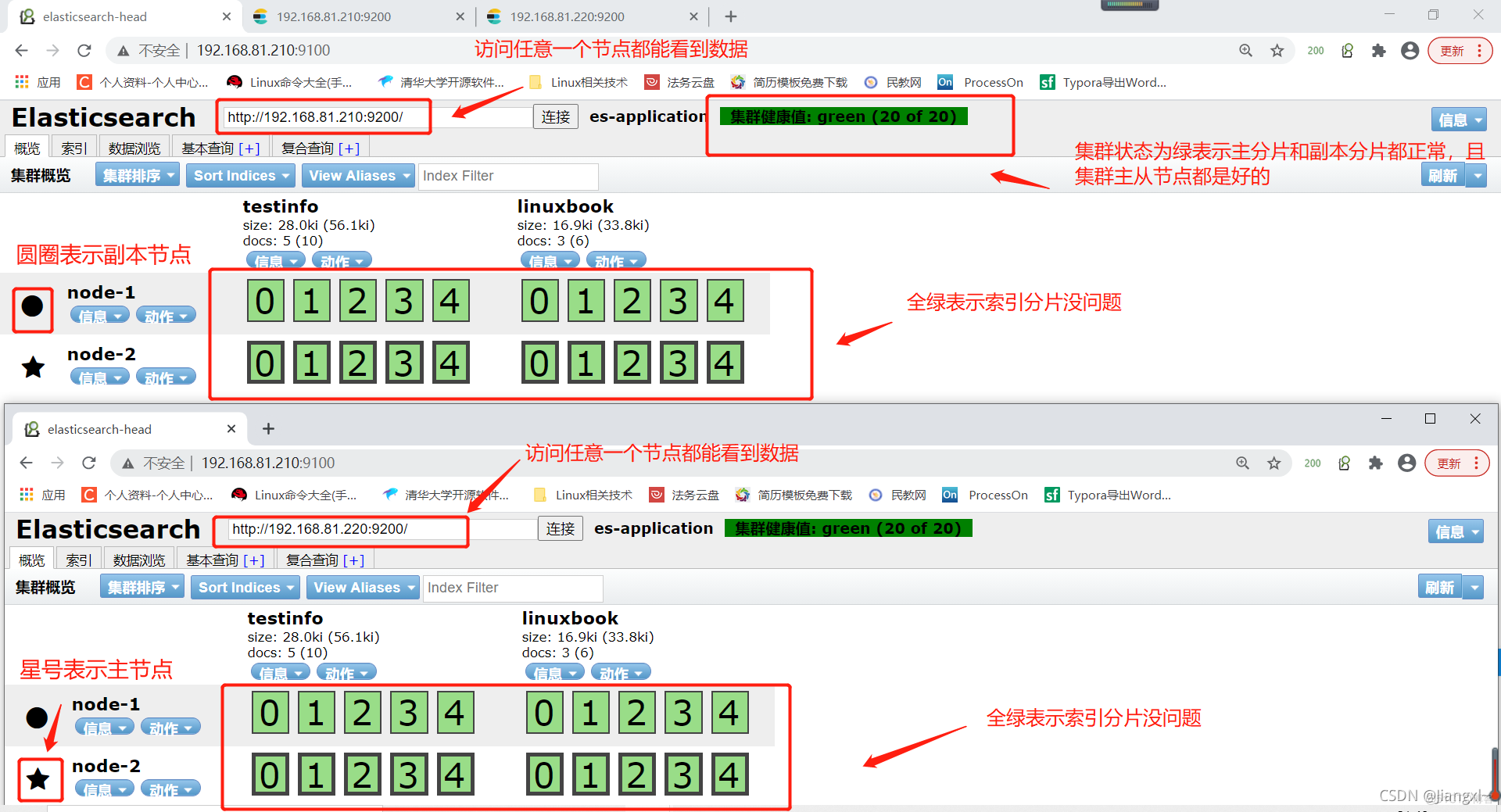
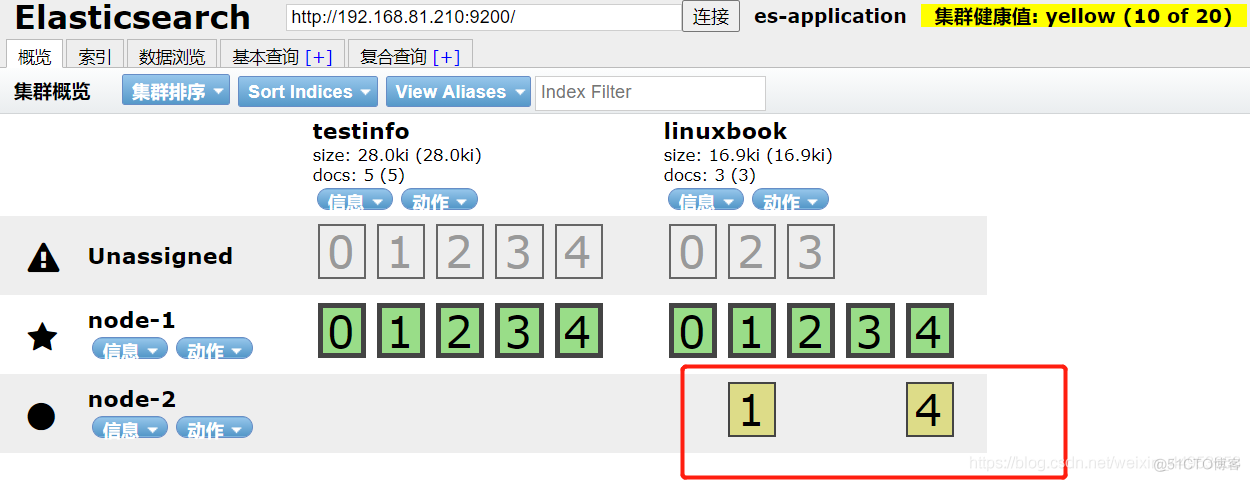
在es-head插件中连接任意es节点都能看到数据则表示集群搭建成功
集群状态为绿色的要求:最少一个集群节点,且主分片和副本分片都正常,没有数据丢失
星号表示主节点、圆圈表示副本节点
索引分片全绿表示数据无丢失
3.elasticsearch集群状态码
集群状态最低要求:至少一个副本五个分片
副本的数量是可以控制的,每次创建索引的时候可以指定拥有几个副本分片,如果超出了当前节点数,则会变灰
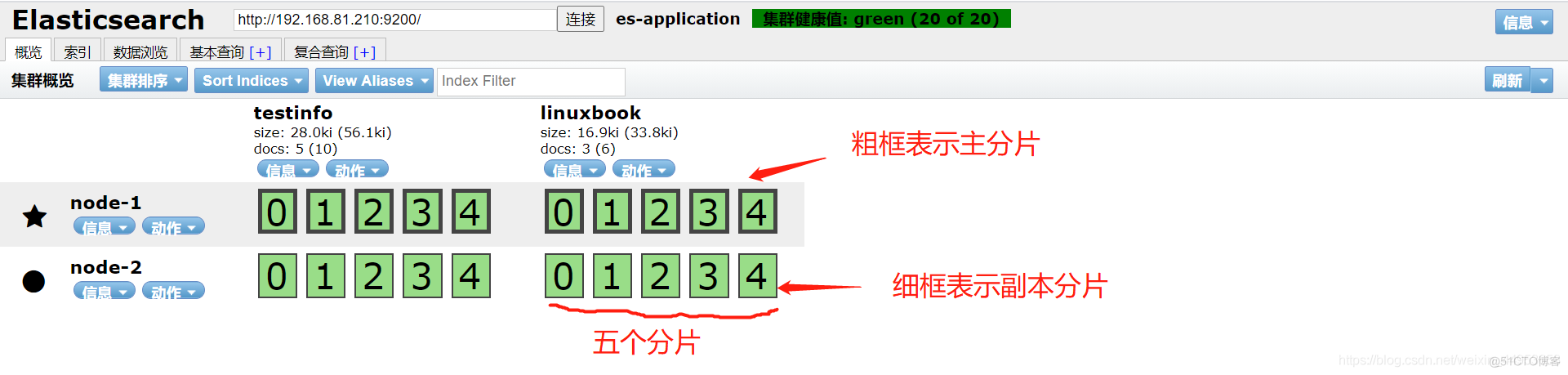
3.1.green状态
要想达到green状态需要满足的条件:所有索引数据都存在,副本满足条件、所有的数据都完整
一条数据会分布在所有分片中,假如一个数据本来应该是五个分片,但是只在其中三个分片中有数据,则表示数据不完整,集群状态就达不到green状态
由于是是刚搭建好的集群,之前单台节点的时候也做过索引,因此主分片都会在一个节点上,后面创建的所有将会分布在所有节点上,提供冗余,当系统负载小的时候在一定时间内,它也会重新分片
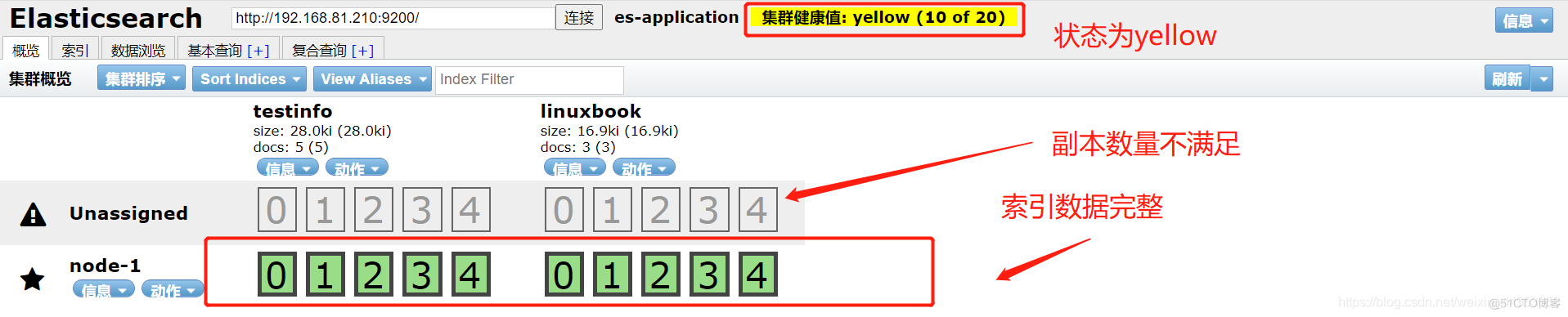
3.2.yellow状态
yellow的状态:所有索引数据完整,但是副本不满足条件,yellow状态常常是刚刚搭建起一个elasticsearch节点,这时没有副本分片,因此会处于yellow状态
我们可以停掉一个node节点查看 效果
停止任意一个node节点的命令systemctl stop elasticsearch
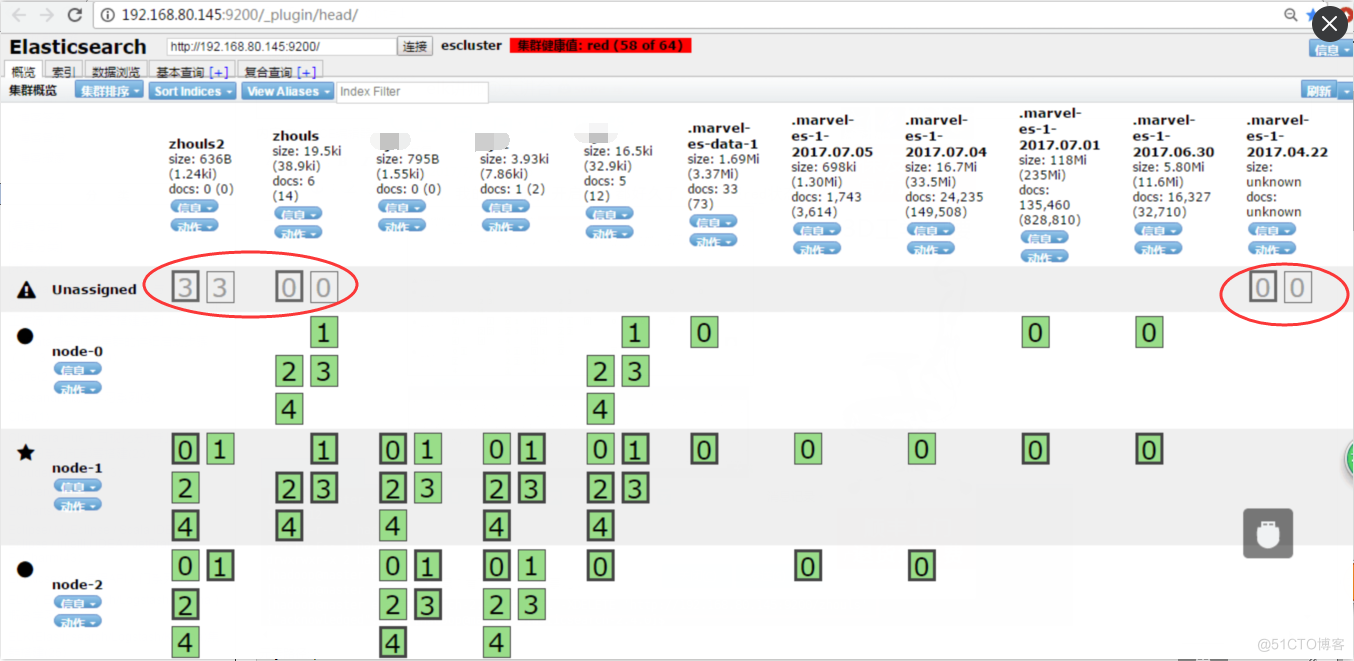
3.3.red状态
red状态:数据不完整,有点所以数据丢失
elasticsearch中会有多个索引,其中一个索引数据有丢失不会影响整个集群其他索引的使用,只是单单某一个有问题,这时集群的状态也会显示为red状态
red状态示意图,其中一个副本的数据有问题
3.4.索引分片处于黄色状态
处于黄色状态表示正在同步数据,当数据同步完会变成绿色
刚起来的node节点它是没有数据的,因此需要从主节点进行同步数据,新增一个node节点都会从主节点去同步数据,最后同步完就变成了绿色
4.elasticsearch集群操作
集群的任意操作命令都可以在任意node节点去执行,因为数据都是同步的
curl命令中的GET一般都是获取某些信息,PUT是提交某些信息
在elasticsearch交互模式中只能使用GET、DELETE、HEAD、PUT

集群操作指令帮助文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-node-info.html
4.1.查看集群状态
[root@elasticsearch ~]# curl -XGET 'http://localhost:9200/_cluster/health?pretty' { "cluster_name" : "es-application", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 10, "active_shards" : 20, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }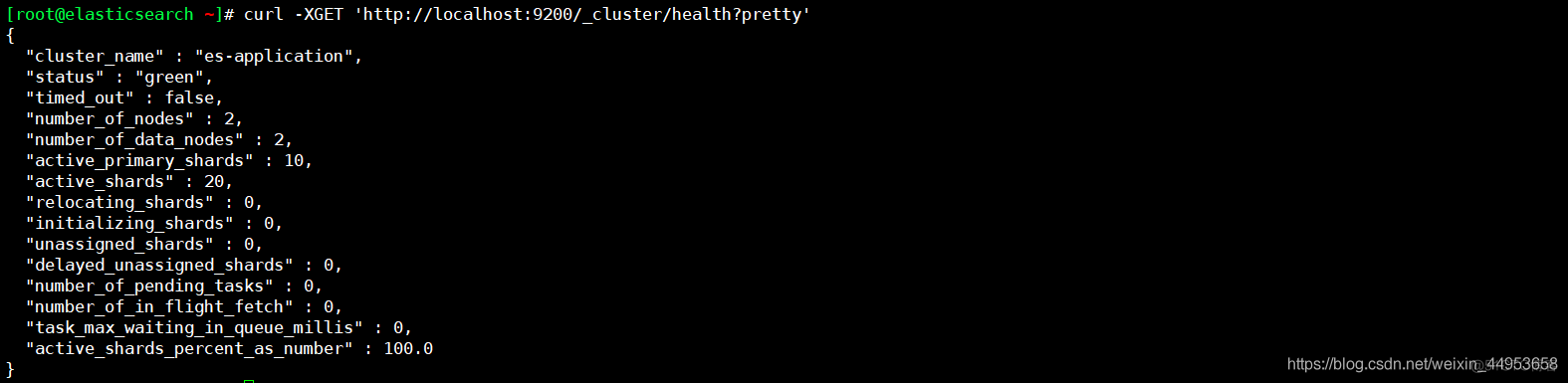
4.2.查看集群所有信息
输出的信息超级多,包含了集群的节点信息、索引信息
[root@elasticsearch ~]# curl -XGET 'http://localhost:9200/_cluster/stats?human&pretty' { "_nodes" : { "total" : 2, #node节点的数量 "successful" : 2, #成功的几个 "failed" : 0 #失败的几个 }, "cluster_name" : "es-application", "cluster_uuid" : "z4wKY7WiQaa6ZkcmW8lTtA", "timestamp" : 1609636910311, "status" : "green", #集群的状态码 "indices" : { "count" : 2, "shards" : { "total" : 20, "primaries" : 10, "replication" : 1.0, "index" : { "shards" : { "min" : 10, "max" : 10, "avg" : 10.0 }, "primaries" : { "min" : 5, "max" : 5, "avg" : 5.0 }, "replication" : { "min" : 1.0, "max" : 1.0, "avg" : 1.0 } } }, "docs" : { "count" : 8, #所有索引的文档总数 "deleted" : 0 }, "store" : { "size" : "89.9kb", #所有索引总大小 "size_in_bytes" : 92094 }, "fielddata" : { "memory_size" : "1.3kb", "memory_size_in_bytes" : 1396, "evictions" : 0 }, "query_cache" : { "memory_size" : "0b", "memory_size_in_bytes" : 0, "total_count" : 0, "hit_count" : 0, "miss_count" : 0, "cache_size" : 0, "cache_count" : 0, "evictions" : 0 }, "completion" : { "size" : "0b", "size_in_bytes" : 0 }, "segments" : { "count" : 16, "memory" : "43.9kb", "memory_in_bytes" : 44992, "terms_memory" : "32.6kb", "terms_memory_in_bytes" : 33424, "stored_fields_memory" : "4.8kb", "stored_fields_memory_in_bytes" : 4992, "term_vectors_memory" : "0b", "term_vectors_memory_in_bytes" : 0, "norms_memory" : "4kb", "norms_memory_in_bytes" : 4096, "points_memory" : "32b", "points_memory_in_bytes" : 32, "doc_values_memory" : "2.3kb", "doc_values_memory_in_bytes" : 2448, "index_writer_memory" : "0b", "index_writer_memory_in_bytes" : 0, "version_map_memory" : "0b", "version_map_memory_in_bytes" : 0, "fixed_bit_set" : "0b", "fixed_bit_set_memory_in_bytes" : 0, "max_unsafe_auto_id_timestamp" : -1, "file_sizes" : { } } }, "nodes" : { "count" : { "total" : 2, "data" : 2, "coordinating_only" : 0, "master" : 2, "ingest" : 2 }, "versions" : [ "6.6.0" ], "os" : { "available_processors" : 2, "allocated_processors" : 2, "names" : [ { "name" : "Linux", "count" : 2 } ], "pretty_names" : [ { "pretty_name" : "CentOS Linux 7 (Core)", "count" : 2 } ], "mem" : { "total" : "3.5gb", "total_in_bytes" : 3815882752, "free" : "144.8mb", "free_in_bytes" : 151838720, "used" : "3.4gb", "used_in_bytes" : 3664044032, "free_percent" : 4, "used_percent" : 96 } }, "process" : { "cpu" : { "percent" : 0 }, "open_file_descriptors" : { "min" : 291, "max" : 301, "avg" : 296 } }, "jvm" : { "max_uptime" : "2.2h", "max_uptime_in_millis" : 7944670, "versions" : [ { "version" : "1.8.0_275", "vm_name" : "OpenJDK 64-Bit Server VM", "vm_version" : "25.275-b01", "vm_vendor" : "Red Hat, Inc.", "count" : 2 } ], "mem" : { "heap_used" : "307.9mb", "heap_used_in_bytes" : 322941368, "heap_max" : "1.4gb", "heap_max_in_bytes" : 1593180160 }, "threads" : 67 }, "fs" : { "total" : "93.9gb", "total_in_bytes" : 100865679360, "free" : "82.7gb", "free_in_bytes" : 88830054400, "available" : "82.7gb", "available_in_bytes" : 88830054400 }, "plugins" : [ ], "network_types" : { "transport_types" : { "security4" : 2 }, "http_types" : { "security4" : 2 } } } }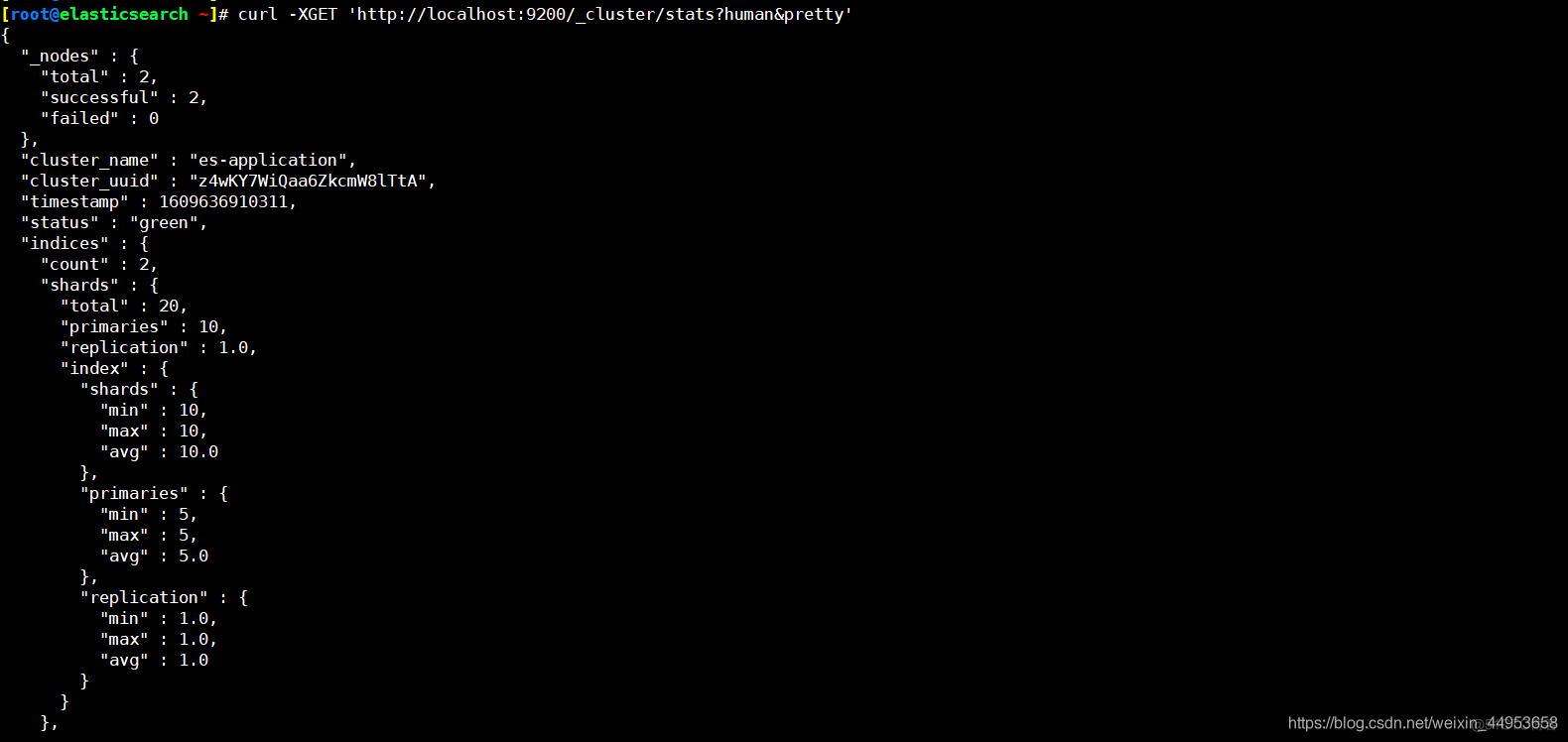
4.3.查看集群节点信息
[root@elasticsearch ~]# curl -XGET 'http://localhost:9200/_cat/nodes?human&pretty' 192.168.81.210 21 96 0 0.00 0.01 0.05 mdi * node-1 192.168.81.220 15 96 0 0.00 0.01 0.05 mdi - node-2 第一列显示集群节点的ip 倒数第二列显示集群节点的类型,*表示主节点,-表示工作节点,主节点也属于工作节点,只是多了一个调度的作用4.4.查看集群jvm信息
这个输出信息属实有点长
会输出jvm的版本、内存设置的大小、调优参数
[root@elasticsearch ~]# curl -XGET 'http://localhost:9200/_nodes/_all/info/jvm,process?human&pretty'
4.5.在集群中创建一个索引观察分片
[root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index1?pretty' { "acknowledged" : true, "shards_acknowledged" : true, "index" : "index1" }创建完后打开head插件,可以看到:集群创建完之后再次创建的索引主分片和副本分片都会分散存放在不同的节点上,不再是主分片在一台机器,副本分片在一台机器
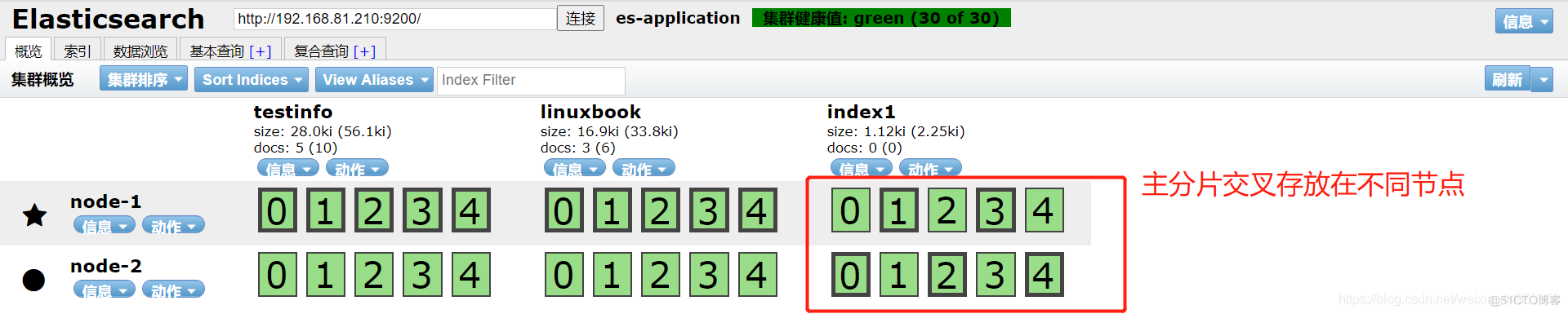
4.6.在集群中创建索引指定分片数量
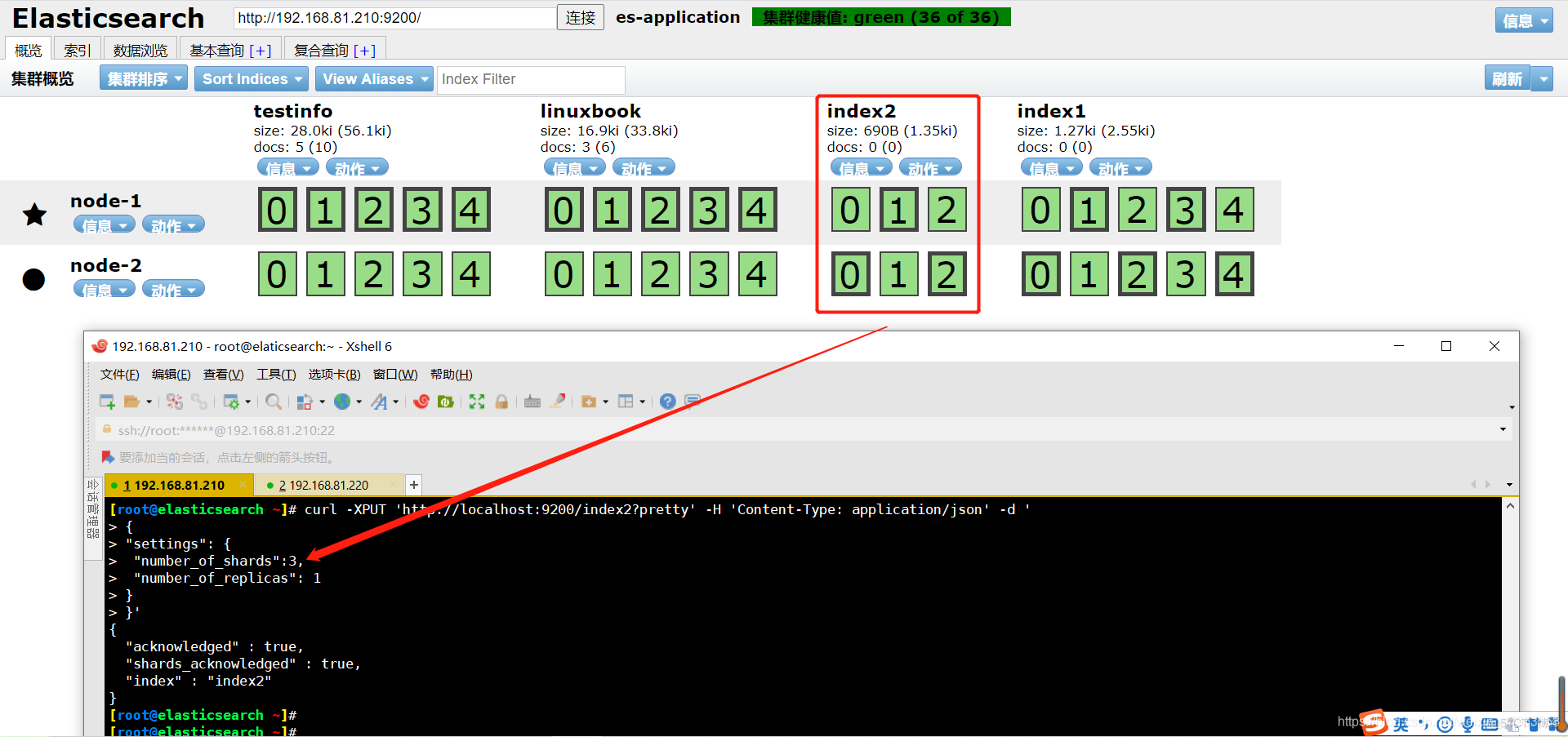
[root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index2?pretty' -H 'Content-Type: application/json' -d ' { "settings": { "number_of_shards":3, #指定分片数量 "number_of_replicas": 1 #指定副本数量 } }' { "acknowledged" : true, "shards_acknowledged" : true, "index" : "index2" }主要用到两个参数"number_of_shards"指定分片数量,"number_of_replicas"指定副本数量
创建完成后可以在elasticsearch-head中明显看到刚刚创建的索引只有3个分片,1个副本
4.7.修改索引的副本数
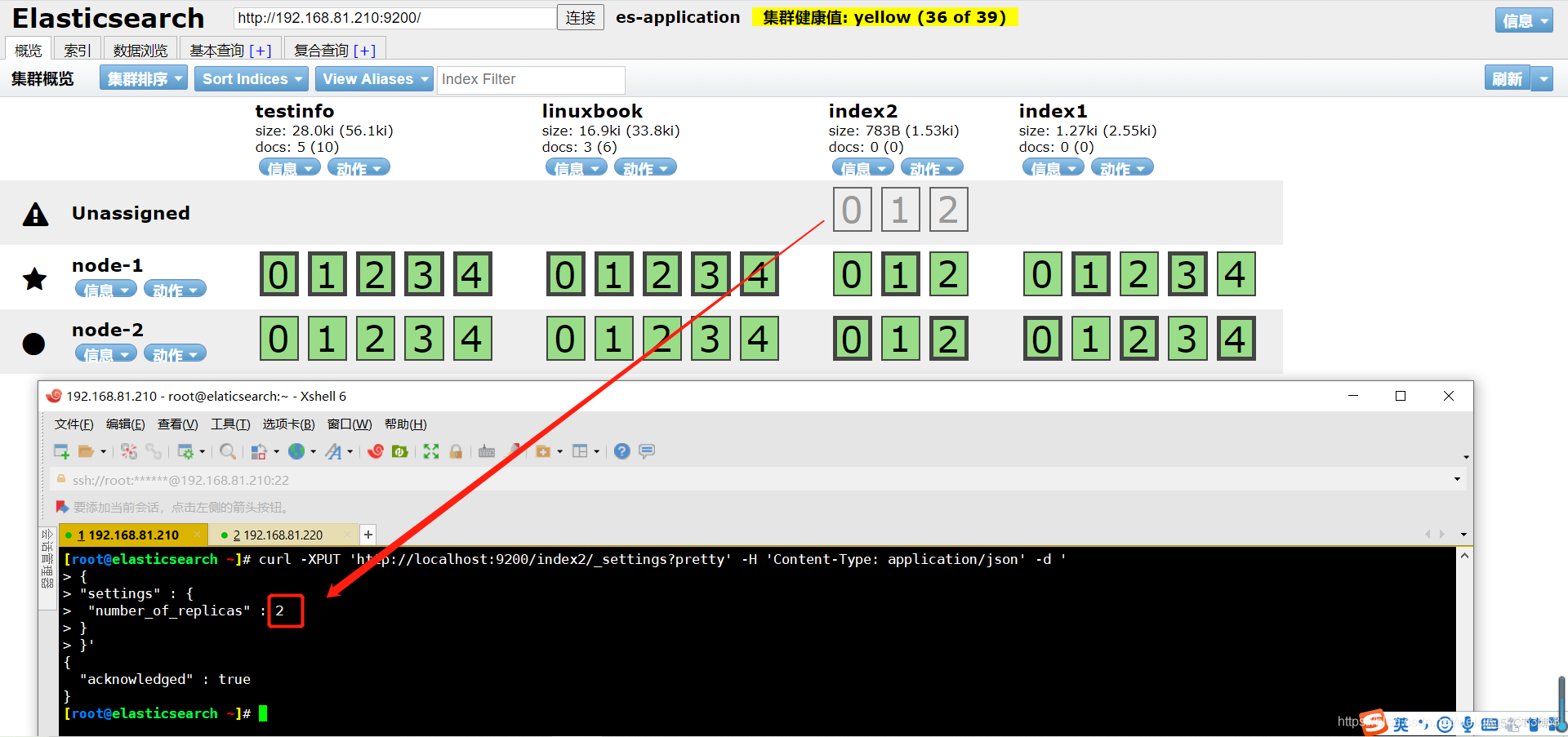
[root@elasticsearch ~]# curl -XPUT 'http://localhost:9200/index2/_settings?pretty' -H 'Content-Type: application/json' -d ' { "settings" : { "number_of_replicas" : 2 } }' { "acknowledged" : true }调整为副本可以看到有一个副本变灰了,是由于我们没有那么多集群节点导致的,一个副本相当于一个机器,俩副本相当于3个节点,我们没有那么多节点因此就会变灰
可以看到当有一个索引的副本数有问题时,集群的状态就会变黄,但是其他的索引不会影响使用
5.增加一个elasticsearch节点解决副本数问题
现在的环境
IP 服务 192.168.81.210 elasticsearch+head 主节点 192.168.81.220 elasticsearch 从节点 192.168.81.230 elasticsearch 从节点5.1.增加一个节点
5.1.1.安装elasticsearch
1.准备Java环境 [root@node-3 ~]# yum -y install java java -version 2.下载elasticsearch rpm包 [root@node-3 ~]# mkdir soft [root@node-3 ~]# cd soft [root@node-3 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.rpm 3.安装elasticsearch [root@node-3 ~]# yum -y localinstall elasticsearch-6.6.0.rpm 4.启动elasticsearch [root@node-3 ~]# systemctl daemon-reload [root@node-3 ~]# systemctl start elasticsearch [root@node-3 ~]# systemctl enable elasticsearch5.1.2.修改主节点配置增加node-3节点
主节点要在discovery.zen.ping.unicast.hosts配置node-3节点的ip地址,主节点在这个参数中填写集群中所有node节点的地址,而node节点只需要填写一个主节点ip和自身ip即可
[root@elasticsearch ~]# vim /etc/elasticsearch/elasticsearch.yml discovery.zen.ping.unicast.hosts: ["192.168.81.210", "192.168.81.220","192.168.81.70"]5.1.3.配置node-3节点的elasticsearch
1.修改主配置文件 [root@node-3 ~]# vim /etc/elasticsearch/elasticsearch.yml cluster.name: es-application node.name: node-3 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.81.70,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.81.210", "192.168.81.70"] discovery.zen.minimum_master_nodes: 1 http.cors.enabled: true http.cors.allow-origin: "*" 2.增加以下配置防止bootstrap报错 [root@node-3 ~]# mkdir /etc/systemd/system/elasticsearch.service.d [root@node-3 ~]# vim /etc/systemd/system/elasticsearch.service.d/override.conf [Service] LimitMEMLOCK=infinity 3.重启 [root@node-3 ~]# systemctl restart elasticsearch5.1.4.查看日志
node加入集群后不再使用elasticsearch.log记录日志而是使用集群名.log进行记录日志
node已经成功加入集群
[root@node-3 ~]# tail -f /var/log/elasticsearch/es-application.log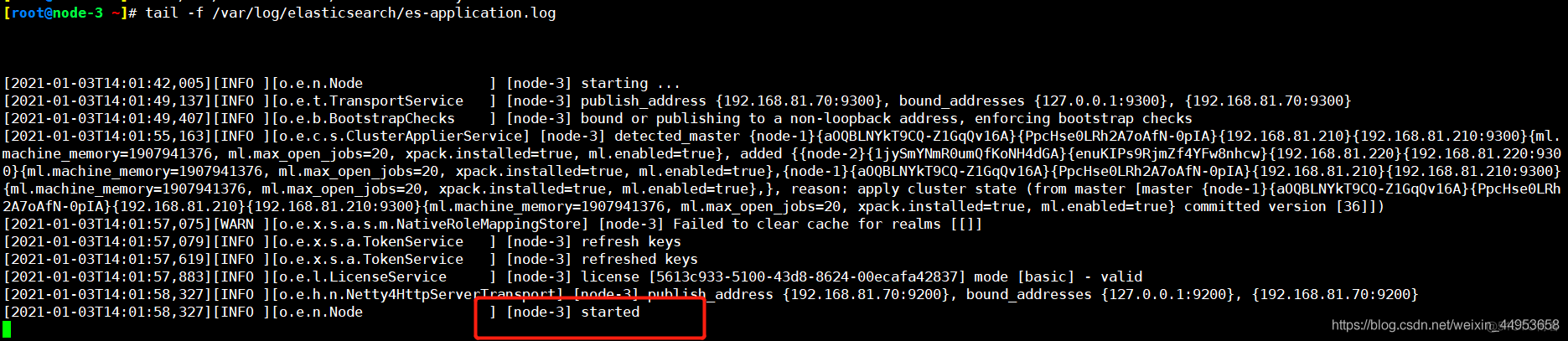
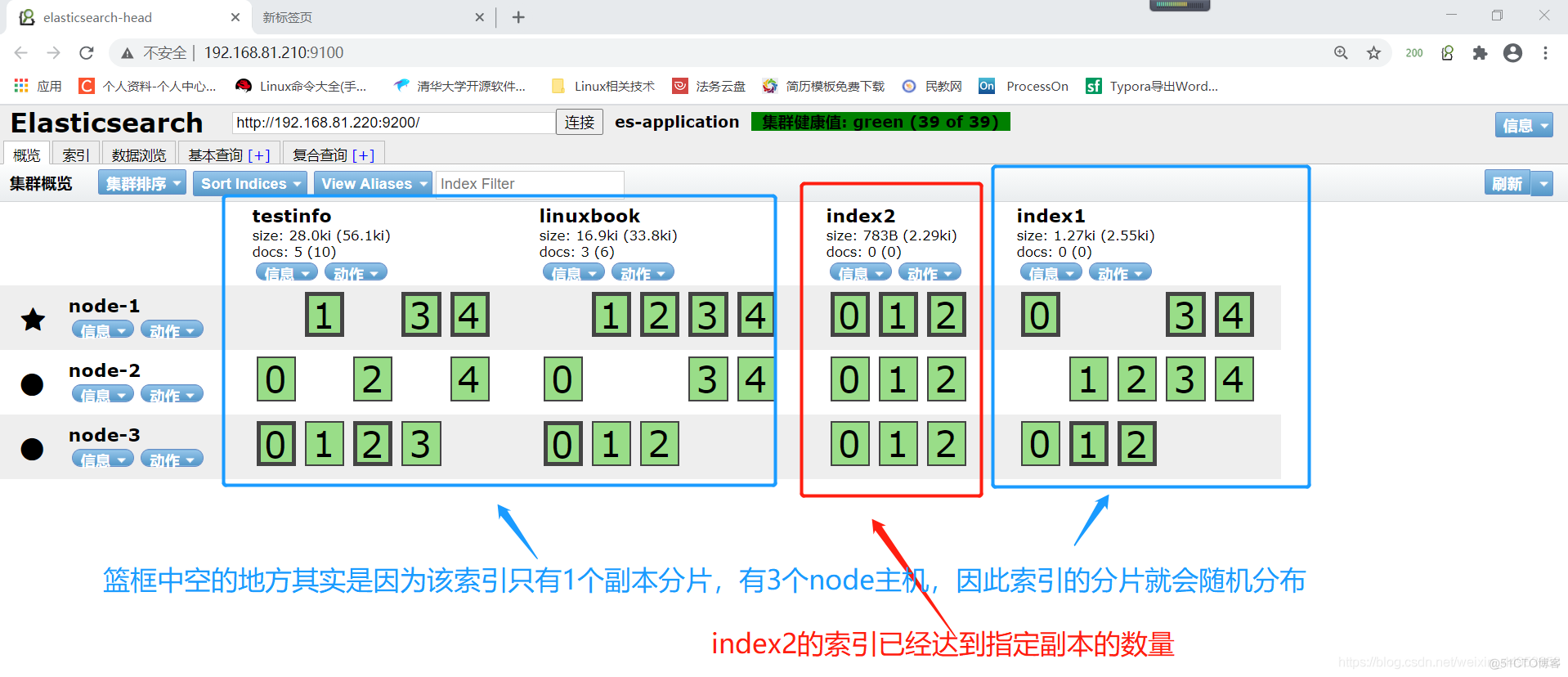
5.2.head插件查看集群状态
在插件中可以看到index2的索引已经达到我们再4.7中指定的副本数量,集群状态也变成了绿色,当副本数的数量是集群总数减去主节点的数量时,副本分片的分布就是特别整齐的,每个节点上都有分片,看起来不会空
篮框中的索引因为只有一个副本分片,而node节点有3个,副本分片会随机分配在不同的node,因此会看起来比较空缺,默认创建的索引就是1个副本,5个分片
副本也就是相当于备份,副本分片永远都是细框