前言
在日常工作中相信大家都会遇到数据洪峰这样的场景,例如电商平台搞活动时,大量的请求集中在一小段时间内,此时对系统造成的压力远超平常,如果不事先做好相应的防范措施,系统将极有可能崩溃、不可用。
业务背景
我们的应用系统每天都会产生大量的业务数据(可以简单理解为商品、订单等),有很多与我们合作的 外部平台 需要 订阅 这些数据,此时我们内部存在一个 数据推送平台 负责将我们系统内部数据推送至外部合作伙伴,数据链路如下:
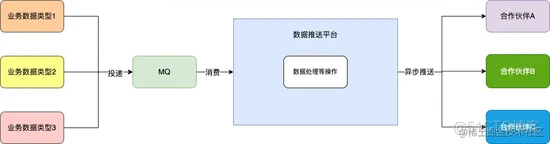
内部业务系统投递 不同类型的业务数据 至 MQ , 数据推送平台 通过消费 MQ 消息,进行一系列处理后采用 异步 的方式将数据推送至不同的合作伙伴 。
技术背景
方案选择
一般应对高并发场景常见的三板斧就是 缓存 、 熔断(降级) 、 限流 :
缓存 常用于高 QPS 的业务场景,显然不太适用这种数据推送的情况。
熔断(降级) 一般应用于调用下游服务失败,防止雪崩效应的场景。 数据推送平台 相对独立,不存在内部服务调用的情况;但是 外部的合作伙伴 确实存在服务可用性的问题,经常出现各种情况导致数据推送异常,因此是可以针对出现异常的外部合作伙伴采用 熔断(降级) 的处理。
限流 就是当高并发或者瞬时高并发时,为了保证系统的稳定性、可用性,系统以牺牲部分请求为代价或者延迟处理请求为代价,保证系统整体服务可用,该种方案与我们的业务场景极为契合。
熔断(降级) 确实可以解决部分外部平台偶发性不可用导致我们的系统资源被占用问题,但无法解决我们数据洪峰场景带来的根本性问题: 系统资源的有限性 ,因此数据推送平台选择了 限流 来应对数据洪峰的场景。
方案应用
限流的具体方案有很多,常见的有 令牌桶方式 、 漏桶方式 、 计数器方式 ,其中 计数器方式 按照实现方式又可以细分为 AtomicInteger 、 Semaphore 、 线程池 等,本次我们选择计数器的方式。
在数据推送时,如果采用同步推送的方式,推送效率将会因 MQ 消费者线程数量(默认设置20)受到极大的限制,如果采用线程池的方式而线程池的大小也不便设置(因为每个消息体的大小差异极大,从 1K 到 5M 不等)。
结合上诉因素,同时与 外部合作伙伴 对接时绝大部分场景都是采用 HTTP 的传输协议,最终推送时采用 Apache 的 HttpAsyncClient (内部基于 Reactor 模型) 异步模式 执行网络请求, Callback 回调的方式来获取推送结果。 将业务数据类型作为限流维度,根据在当前应用实例中正在推送的数量进行限流。
例如手机相关的商品数据业务类型为 PRODUCT_PHONE, 默认每种业务类型的 限流数设为 50 ,当 单台应用实例内存中 该种业务类型 正在推送 的数据量达到 50 后,该业务类型的数据从第 51 条开始都将会被拒绝,直到 正在推送 的数据量降至 50 以下。针对被拒绝的消息返给 MQ 稍后消费的状态, MQ 将会间歇性消费重试。
伪代码如下:
//该业务类型在当前节点的流量Integer flowCount = BizFlowLimitUtil.get(data.getBizType());
//该种业务类型对应的限流
Integer overload = BizFlowLimitUtil.getOverloadOrDefault(data.getBizType(), this.defaultLimit);
if (flowCount >= overload) {
throw new OverloadException("业务类型:" + data.getBizType() + "负载过高,阈值:" + overload + ",当前负载值:"
数据推送平台内增加了业务限流的一环:
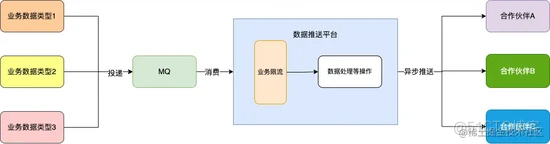
可能存在的问题
按照上述的方案,系统应对数据洪峰的 所需最大资源 = 业务类型种数 * 限流数 ,而随着业务的扩张, 业务类型种数 也在不断的增加, 所需最大资源 也会不断的增加,然而服务实例的资源始终是有限。在该种情况下,只根据业务数据类型的数据量来进行限流,效果将会逐渐变得不理想,极端场景下甚至可能出现服务崩溃的情况。
压力测试
当然以上方案存在的问题只是我们的一个设想,我们进行压测来观察推送系统的整体情况。
资源配置
应用实例数量:1
实例配置:1核2G
jvm参数:
-Xmx1g -Xms1g -Xmn512m -XX:SurvivorRatio=10 -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+ExplicitGCInvokesConcurrent -XX:ParallelGCThreads=2数据指标及工具选择
在压测时我们通常会关注 cpu 、 内存 、 网络io 、 数据库 等多项数据指标,在不考虑 网络io 、 数据库 等外部中间件因素的情况下, cpu 、 内存 是我们观察系统稳定性最为直观的数据指标。
Arthas 是 Alibaba 开源的 JAVA 诊断工具,具体使用可阅读官方文档: arthas.aliyun.com/doc/。我们使用 Arthas 来对服务进行观测,登录服务器打开控制台,使用如下命令安装并启动 Arthas :
curl -O https://arthas.aliyun.com/arthas-boot.jarArthas 提供了 dashboard 命令,可以查看服务 JVM 的实时运行状态,如不指定刷新间隔时间,默认 5s 刷新一次。在启动 Arthas 后的控制台键入 dashboard 出现如下画面:
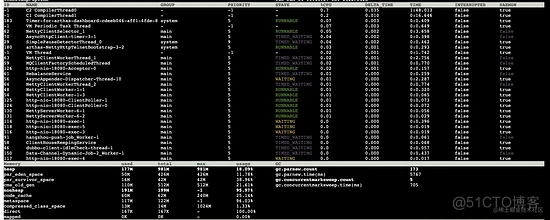
上半部分主要是当前服务 JVM 中的线程情况,可以看到各线程对 cpu 的使用率极低,基本处于闲置状态。
下半部分 Memory 框中的信息,我们主要关心以下几项数据指标:
- heap(堆大小)
- par_eden_space(伊甸区大小)
- par_survivor_space(S区大小)
- cms_old_gen(老年代大小)
- gc.parnew.count(young gc总次数)
- gc.parnew.time(young gc总耗时)
- gc.concurrentmarksweep.count(full gc总次数)
- gc.concurrentmarksweep.time(full gc总耗时)
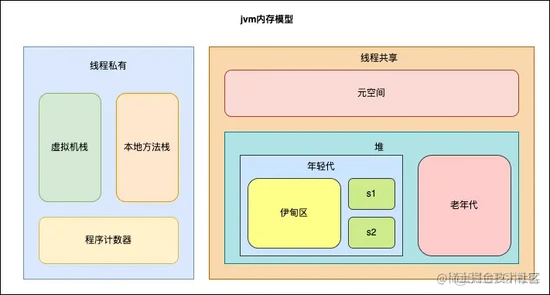
各列代表的意思也很清楚,分别是已使用、总大小、最大值、已使用百分比。光看名词可能一时想不起 JVM 内部的划分 ,来一张图帮助大家回忆下:
5s后 Arthas 控制台输出如下:
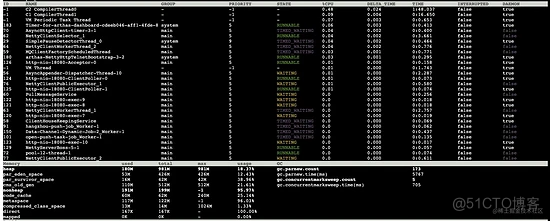
结合 **5s **前的数据,我们主要关注以下指标:
- 线程情况:线程cpu使用率并没有明显变化
- heap(堆大小):堆使用大小增加 3m
- par_eden_space(伊甸区大小): 年轻代中的伊甸区只增加 3m,按照伊甸区 426m、s区 42m 的大小,大约需要780秒(约13分钟)才会触发一次 young gc
- par_survivor_space(S区大小):无变化
- cms_old_gen(老年代大小):无变化
- gc.parnew.count(young gc总次数):无变化
- gc.parnew.time(young gc总耗时):无变化
- gc.concurrentmarksweep.count(full gc总次数):无变化
- gc.concurrentmarksweep.time(full gc总耗时):无变化
这是服务无流量基本处于闲置状态时一个情况,接下来模拟积压大量 不同业务类型数据 进行推送时的场景,数据由测试同学提前通过自动化脚本投递到 MQ 当中。
积压5000条数据
使用 Arthas 命令 dashboard -i 1000 ,按照 1s 的间隔输出:
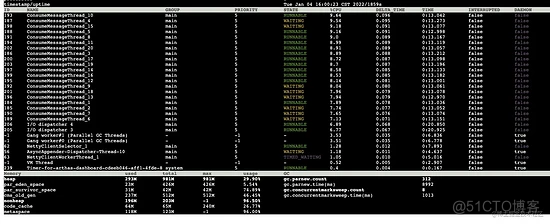
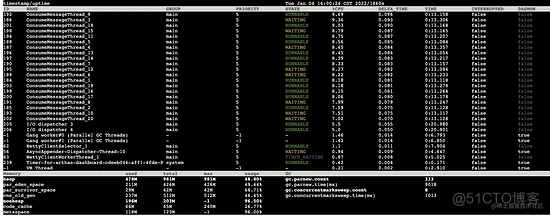
1s 后:
对比两次数据发现:
- 线程情况:MQ 默认的20个消费者线程都处于活跃状态占用cpu资源
- heap(堆大小):已使用大小从 293m 上升至 478m
- par_eden_space(伊甸区大小): 发生 young gc 之前伊甸区使用 23m,伊甸区总大小为 426m,发生 young gc 之后伊甸区使用了 211m,这说明在 1s 之内至少增加了(426-23)+211 = 614m 大小的对象
- par_survivor_space(S区大小): young gc 之前S区大小为 31m,young gc 之后S区大小为 29m
- cms_old_gen(老年代大小):无变化
- gc.parnew.count(young gc总次数):发生了 1 次 young gc
- gc.parnew.time(young gc总耗时): 时间增加了(9018-8992)= 26 毫秒,为一次 young gc 的时长
- gc.concurrentmarksweep.count(full gc总次数):无变化
- gc.concurrentmarksweep.time(full gc总耗时):无变化
按照 1s 的间隔发现发生了 young gc ,而老年代的数据没有变化,可能是时间间隔较短导致的,我们按照 5s 的间隔来观察下,键入 dashboard -i 5000 输出如下:
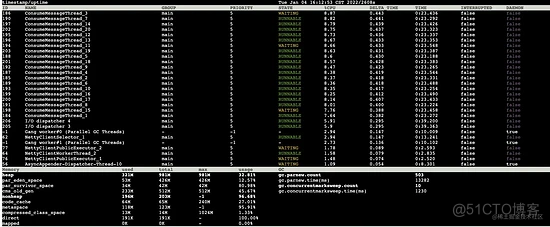
5s 后:
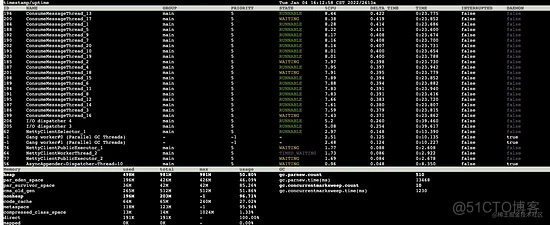
对比两次数据,关键信息如下:
- 5s 之内发生了 7 次 young gc
- 老年代由 233m 增长至 265m,增长了 32m 左右,按照老年代 512m 的大小,大约 80s 就会发生一次 full gc
积压1W条数据
按照 1s 的时间间隔开始:
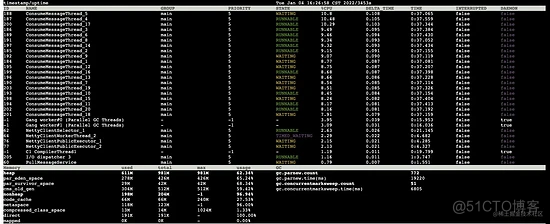
1s 后:
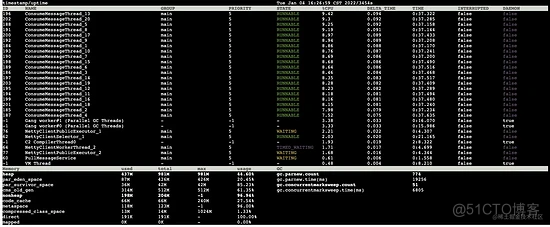
对比两次数据得知:
- 1s之内发生了两次 young gc
- 同时老年代从 304m 增长至 314m,1s 增长了 10m,老年代大小为 512m,按照这个速率,大约 50s 就会触发一次 full gc
由于采用 异步 的方式进行数据推送,此时推送平台的下游还未将数据推送完成,而上游还在不断的从 MQ 中消费消息,继续观察:
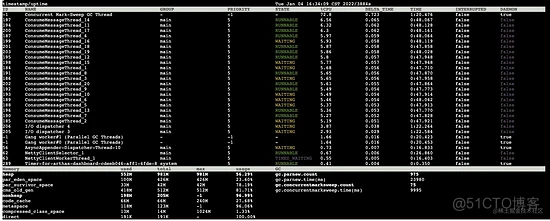
1s 后:
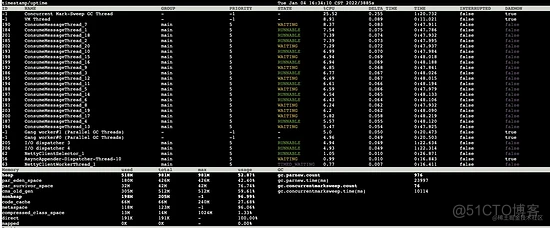
对比两次数据发现:
- GC 线程的 cpu 使用率居高不下
- 1s 内发生了一次 full gc
一秒前老年代已使用大小为 418m,总大小为 512m,1s 后发现触发了一次 full gc,按照上面的数据分析出老年代以每 10m/s 的速度增长,显然老年代的剩余空间是足够的,为什么还会提前出现 full gc 这种情况呢?
首先我们回顾一下 full gc 发生的时机:
第一种情况:老年代可用内存小于年轻代全部对象大小,同时没有开启空间担保参数( -XX:-HandlePromotionFailure )。
从 JDK6 之后, HandlePromotionFailure 参数不会再影响到虚拟机的空间分配担保策略,我们使用的都是 JDK8 ,所以第一种情况不满足。
第二种情况:老年代可用内存小于年轻代全部对象大小,开启了空间担保参数,但是可用内存小于历次年轻代GC后进入老年代的平均对象大小。
根据之前的分析,每秒进入老年代的对象大小大约为 10m ,而目前老年代剩余大小约为( 512-418)= 94m ,所以第二种情况也不满足。
第三种情况:年轻代 young gc 后存活对象大于s区,就会进入老年代,但是老年代内存不足。
同第二种情况,第三种情况也不太满足。
第四种情况:设置了参数 -XX:CMSInitiatingOccupancyFaction ,老年代可用内存大于历次年轻代GC后进入老年代的对象的平均大小,但是老年代已使用内存超过该参数指定的比例,自动触发 full gc 。
查看服务实例的资源配置信息,发现 JVM 启动参数中加了该参数: -XX:CMSInitiatingOccupancyFraction=80 , 该参数表示老年代在达到 512 * 80% = 409M 大小时就会触发一次 full gc 。该参数主要是为了解决 CMF ( Concurrent Mode Failure )问题,不过该参数在某些情况也会导致 full gc 更加频繁。看来就是该参数就是老年代空间未满却提前出现了 full gc 的原因。
现在我们知道了提前触发了 full gc 的原因是由于 CMSInitiatingOccupancyFraction 参数的配置,正常情况下设为 80% 也不会有什么问题,但是有没有这种极端情况呢:
发生 full gc 后老年代的空间并没有回收多少,老年代已使用空间大小一直在 CMSInitiatingOccupancyFraction 设定的阈值之上,导致不停的 full gc ?
积压2W条数据
按照 5s 的时间间隔开始:
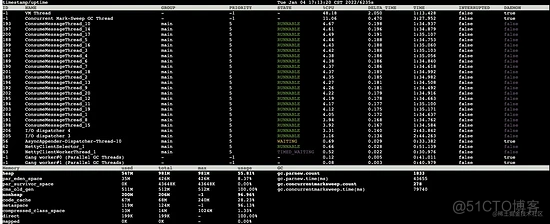
5s 后:
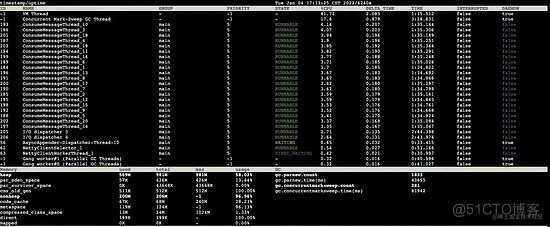
对比两次数据发现:
- 线程情况:cms垃圾回收线程cpu占用率极高
- 老年代:已使用 511m(总大小 512m)
- full gc次数:5s 内发生了 3 次 full gc
- full gc总耗时:总耗时由 15131ms 增加至 14742ms
5s内发生了 3 次 full gc ,老年代始终处于 已使用 511m ( 总大小512m )的情况,每次的 full gc 平均耗时 (81942-79740)/ 3 = 734 ms ,相当于 5s 内有 2.2s 的时间都在 full gc 。
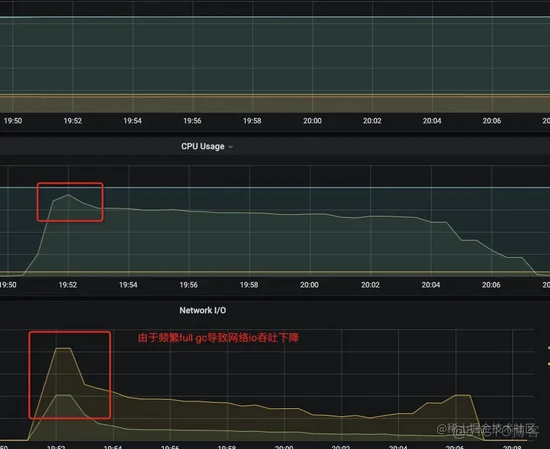
此时查看日志发现数据推送时发生大量的 socket连接超时 :
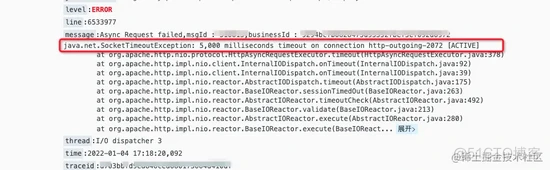
再查看下当时的 **gc **日志,发现两次 full gc 之间只差了 1.4s 左右,从 524287k 回收至 524275k , 只回收了 12k 的内存空间,却花费了 0.71s , 系统有一半的时间都在进行 full gc!
使用监控大盘 grafana 查看下当时的 cpu 、 网络 io 情况,可以看到由于 full gc 频繁引发 Stop the World 、 cpu 负载过高 等问题,网络请求相关的线程得不到有效的调度,导致 网络 io 吞吐下降 。
优化方案
问题分析
通过上面的测试可以发现系统存在的问题主要是:由于下游消费速率(执行网络请求进行数据推送)跟不上上游的投递速率(mq消费),导致 jvm 堆内存逐渐被打满,系统频繁 full gc 造成服务不可用,直至产生 OOM 程序崩溃。
优化思路
在该场景中系统的主要瓶颈在于 jvm 堆内存大小上面,避免系统频繁 full gc 即可达到提升系统稳定性的目的,可以从以下两方面着手。
JVM参数优化
原来的 jvm 参数为:
-Xmx1g -Xms1g -Xmn512m -XX:SurvivorRatio=10 -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+ExplicitGCInvokesConcurrent -XX:ParallelGCThreads=2调整点如下:
- 实例总内存为 2G,实例上除了我们的服务之外也没有安装其他比较占用内存的服务,原来给jvm 的堆大小只分配了 1G,有点浪费,所以调整jvm 的堆大小为 1.5G:-Xmx1536M -Xms1536M
- 之前年轻代大小设为512M在数据推送平台这种业务场景并不太恰当。在晚上业务低峰期,通过jmap 命令触发full gc后观察老年代发现常驻对象约150M左右,考虑浮动垃圾等,老年代分配521M,再考虑到元空间以及线程栈所需的资源,所以年轻代调整为1G大小:-Xmn1024M
- 年轻代中的伊甸区和s区的比例由10:1:1调整为8:1:1,避免young gc后存活对象过多s区空间不足导致直接进入老年代:-XX:SurvivorRatio=8
- 元空间大小一般分配256m:-XX:MaxMetaspaceSize=256M -XX:MetaspaceSize=256M
- 线程栈一般设为1m:-Xss1M
- 针对年轻代使用ParNew垃圾收集器:-XX:+UseParNewGC
最终优化后的 jvm 参数为:
-Xmx1536M -Xms1536M -Xmn1024M -Xss1M -XX:MaxMetaspaceSize=256M -XX:MetaspaceSize=256M -XX:SurvivorRatio=8-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80
JVM资源限流
通过压测发现老年代的空间使用率过高(超过 -XX:CMSInitiatingOccupancyFraction 参数值)导致频繁发生 full gc ,那么是否可以尝试基于 jvm 堆内存使用率来对上游进行限流控制 ,起到一个类似背压的效果。我们添加一个 JVM 资源限流器 ,限流核心逻辑为:
设定一个 jvm 堆内存的使用率,当超过这个阈值后对当前的消费线程进行阻塞或直接拒绝消费,直到使用率低于阈值后再进行放行。
伪代码如下:
public class ResourceLimitHandler{/**
* jvm堆限流阈值
*/
private Integer threshold = 70;
/**
* 单次睡眠时间(毫秒)
*/
private Integer sleepTime = 1000;
/**
* 最大阻塞时间(毫秒)
*/
private Integer maxBlockTime = 15000;
private MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();
@SneakyThrows
public void process(){
long startTime = System.currentTimeMillis();
double percent = this.getHeapUsedPercent();
//jvm heap使用率超过阈值,进入限流逻辑
while (percent >= this.threshold ) {
//资源使用过高,但超过最大阻塞时间,采用放行策略
if (this.maxBlockTime >= 0 && (System.currentTimeMillis() - startTime) > this.maxBlockTime) {
//兜底,防止因为限流导致年轻代无新对象产生,达不到young gc 触发条件的极端情况,所以手动触发一次full gc
synchronized (ResourceLimitHandler.class) {
if ((percent = this.getHeapUsedPercent()) >= this.threshold) {
System.gc();
}
}
return;
}
TimeUnit.MILLISECONDS.sleep(this.sleepTime);
percent = this.getHeapUsedPercent();
}
}
/**
* 计算堆的使用百分比
*
* @return
*/
private double getHeapUsedPercent(){
long max = this.getHeapMax();
long used = this.getHeapUsed();
double percent = NumberUtil.div(used, max) * 100;
return percent;
}
/**
* 可用堆最大值
*
* @return
*/
private long getHeapMax(){
MemoryUsage memoryUsage = this.memoryMXBean.getHeapMemoryUsage();
return memoryUsage.getMax();
}
/**
* 已使用堆大小
*
* @return
*/
private long getHeapUsed(){
MemoryUsage memoryUsage = this.memoryMXBean.getHeapMemoryUsage();
return
代码还是比较简单的,其中的 jvm 堆内存阈值的设置比较关键,该值的设置给出以下参考
最大阈值
由于 -XX:CMSInitiatingOccupancyFraction 参数而触发 full gc 的临界情况为:年轻代可用空间被全部使用,同时老年代空间使用率达到 -XX:CMSInitiatingOccupancyFraction 所设置的比例,所以得出如下计算公式:
最大阈值百分比 = (年轻代可使用大小 + 老年代大小 * CMSInitiatingOccupancyFraction- 年轻代可使用大小:*伊甸区大小+单个s区的大小(因为两个s区轮流替换,始终只有一个在存放对象)
代入优化的 jvm 参数得出 最大阈值百分比 = ( 1024 * 0.9 + 512*0.8 )/ 1536 = 87%
最小阈值
阈值设置过低会影响正常的业务处理,至少要保证能够触发 young gc ,而实际触发 young gc 的情况有很多,这里不做进一步讨论,暂时只考虑最常见的由于年轻代空间不足以放下新对象的场景,所以得出:
最小阈值百分比 = 年轻代可使用大小 / 堆大小代入优化后的 jvm 参数得出 最小阈值百分比 = (1024 * 0.9)/ 1536 = 60%
方案验证
实践出真章,我们按照之前的方式再次测试
资源配置
应用实例数量:2
实例配置:2核4G
数据量: MQ 中积压5w条数据
说明:测试过程中的数据这里不再做展示,只取所有数据最终推送完成后的结果。
优化前
优化前推送完成后 Arthas 仪表盘:
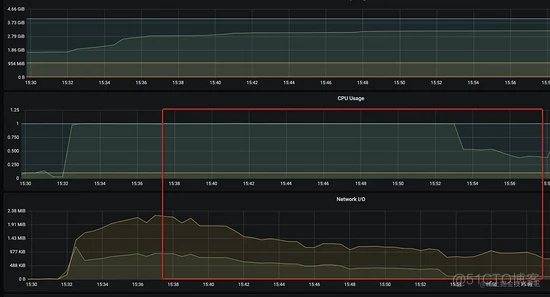
Grafana 监控大盘:
优化后
在对 jvm 参数进行优化 以及 添加资源限流器 后,推送完成后 Arthas 仪表盘:
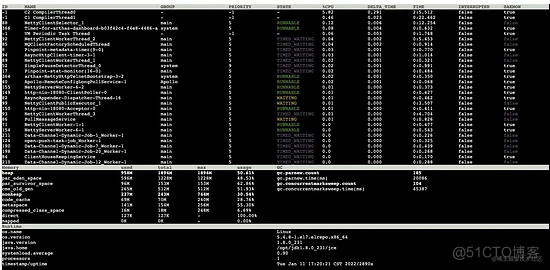
Grafana 监控大盘:
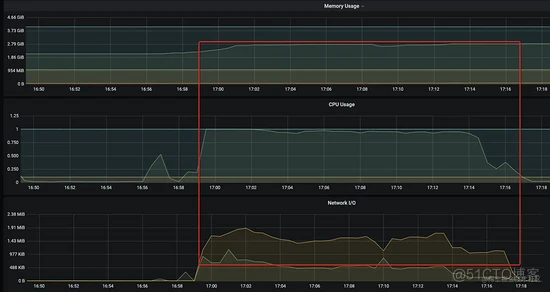
结果比对
数据推送总耗时
full gc次数
full gc总耗时
单次full gc平均耗时
优化前
约35分钟
312
309232
991ms
优化后
约18分钟
104
45387
436ms
优化前后进行比对,可以发现优化后无论是 数据推送总耗时 还是 full gc 的次数 或是 full gc平均耗时 都有了很大的减少,整体效能近乎提升了一倍。
总结
基于数据推送平台的业务场景、技术背景,我们推测在数据洪峰场景下单纯的从 任务并发数 进行流控,可能会达不到保障系统稳定性的目的,并通过压测验证了我们这一猜想。通过分析发现系统的瓶颈主要是 jvm 堆内存资源有限,由于下游消费速率(执行网络请求进行数据推送)不及上游的投递速率(消费 MQ 消息、组装推送任务), jvm 中堆积的对象不断增长并且无法被回收,造成频繁 full gc ,导致系统不可用。
通常我们系统中主流的限流方式都是 基于并发数 来处理,需要测试同学进行压测,综合考虑网络IO、数据库等外部中间件的情况下得出一个相对合理的数值,在日常工作中不同环境下的服务实例配置都略有不同, 承载的并发数 也会存在一定的差异。如果 限流并发数 设置的过高,将会存在高并发场景下服务崩溃的风险,此时如果 辅以系统资源级别的限流 ,可以保证服务不会被暴增的流量瞬间打崩。
方案适用场景:
- 系统级别的全局限流,防止服务崩溃,例如运用在Spring MCV 过滤器、dubbo 过滤器等。
- 需要设置一个缓存队列,而队列中的每个任务中的数据对象大小差异极大,队列的大小难以设置,单纯使用无界队列又存在OOM 的风险,此时可配合该方案对无界队列进行限制。
方案不足:
- 此次基于jvm 堆内存限流的方案因为依赖于CMSInitiatingOccupancyFraction 参数对full gc引发的作用,所以仅适用于老年代使用CMS 垃圾回收器的服务,而大部分 **16G **内存以上的服务都使用G1垃圾回收器。
- jvm 堆使用率阈值的具体值依赖jvm 相关参数设置,需要使用者对jvm 的内部机制有一定的了解。
- 不建议作为唯一的限流处理逻辑,因为实际场景中服务的承载能力还与网络io、数据库等其他因素有关。
- 该方案的稳定性、可靠性需要更多的案例验证。
结语:每种方案都有各自的优缺点、局限性,根据 jvm 堆内存使用率进行限流,并不适用所有的业务场景,只是作为一个新的限流方案供大家参考扩展思路,起到一个抛砖引玉的作用,文中如有不对之处还请指正。
推荐阅读
Flink checkpoint 算法(上)
从线上死锁分析到 Next-Key Lock 理解
深入理解 MyBatis
Linux 是如何启动的
招贤纳士
政采云技术团队(Zero),一个富有激情、创造力和执行力的团队,Base 在风景如画的杭州。团队现有300多名研发小伙伴,既有来自阿里、华为、网易的“老”兵,也有来自浙大、中科大、杭电等校的新人。团队在日常业务开发之外,还分别在云原生、区块链、人工智能、低代码平台、中间件、大数据、物料体系、工程平台、性能体验、可视化等领域进行技术探索和实践,推动并落地了一系列的内部技术产品,持续探索技术的新边界。此外,团队还纷纷投身社区建设,目前已经是 google flutter、scikit-learn、Apache Dubbo、Apache Rocketmq、Apache Pulsar、CNCF Dapr、Apache DolphinScheduler、alibaba Seata 等众多优秀开源社区的贡献者。如果你想改变一直被事折腾,希望开始折腾事;如果你想改变一直被告诫需要多些想法,却无从破局;如果你想改变你有能力去做成那个结果,却不需要你;如果你想改变你想做成的事需要一个团队去支撑,但没你带人的位置;如果你想改变本来悟性不错,但总是有那一层窗户纸的模糊……如果你相信相信的力量,相信平凡人能成就非凡事,相信能遇到更好的自己。如果你希望参与到随着业务腾飞的过程,亲手推动一个有着深入的业务理解、完善的技术体系、技术创造价值、影响力外溢的技术团队的成长过程,我觉得我们该聊聊。