@[toc]
一、前言
1984年被授予图灵奖的计算机编程领域的祖师爷 尼古拉斯•威茨(Niklaus Wirth),有一句名言在计算机领域人尽皆知,那就是:
算法 + 数据结构 = 程序 (Algorithm+Data Structures=Programs)
关于公式中的三个元素含义可以对照下表
元素 含义 程序 特定问题解决方案的具体实现 算法 解决特定问题的有限求解步骤(思想) 数据结构 数据与数据之间的结构(逻辑)关系关于这句名言有不少争论,感兴趣的可以移步: "算法+数据结构=程序"过时了吗?
顺便补充一下我的片面理解:我们只不过是站在巨人的肩膀上俯视前人,如今在很多场景中虽然不会直接考虑算法和数据结构,但是其底层仍然离不开算法和数据结构。所以我觉得 可以理解为 程序的灵魂是算法和数据结构。
二、正文
1 复杂度
1.1 什么是复杂度?
复杂度其实就是对于程序占用计算机资源大小的一种衡量。通常使用大O复杂度表示法进行表示,它可以分为空间复杂度和时间复杂度。
公式表示:
$T(n) = O(f(n))$
其中:
字符 含义 $T_(n)$ 表示代码执行的时间 $n$ 表示数据规模大小 $f_(n)$ 表示每行代码执行的次数总和 $O(f_(n))$ 表示代码的执行时间T(n)与f(n)表达式成正比- 举个栗子
上述代码的目的是为了计算前 n 个整数累计求和的结果,怎么计算复杂度呢?
在python中,度量复杂度的指标可以选取赋值语句的执行次数
则有
$T_(n) = 1 + n$
当计算规模 $n -> ∞$ ,得到该代码的复杂度为:
$T_(n) = n$
可以看出, $T(n)$ 的精确值并不重要,最终决定 $T(n)$ 的是增速最快的主导部分。
那么,下式的复杂度为多少呢?
$T_(n) = 5n^2 + 27n + 1005$
很显然,答案是: $O_(n^2)$
1.2.复杂度分析法则
1.3 常见的大O数量级函数
- 当 n 较小时,难以确定其数量级
- 当 n 增长到较大时,容易看出其变化数量级
变化曲线如图

1.4 变位词
为了对于空间复杂度有更好的理解,下面引出 ”变位词“
所谓“变位词”是指两个词之间存在组成字母的重新排列关系。
例如 heart和earth,python和typhon
现在有一个题目,要求:写一个函数,以两个词作为参数,返回这两个词是否为变位词
解法1:逐字检查
- 实现思路
实现“打勾”标记:将词2对应字符设为None由于字符串是不可变类型,需要先复制到列表中
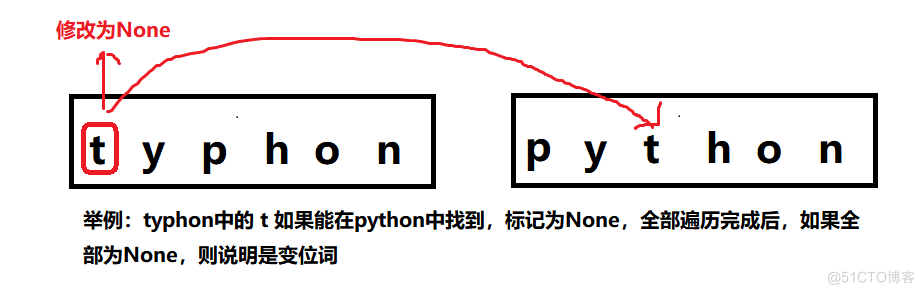
- 具体代码 def anagramSolution1(s1,s2): alist = list(s2) # 复制s2到列表 pos1 = 0 still0K = True while pos1 < len(s1) and stillOK: # 循环s1的每个字符 pos2 = 0 found = False while pos2 < len(alist) and not found: if s1[pos1] == alist[pos2]: # 在s2逐个对比 found = True else: pos2.=pos2.+.1 if found: alist[pos2] = None # 找到,打勾 else: stillOK = Falsepos1 = pos1 +1 # 未找到,失败 return still0K
print(anagramSolution1( ' abcd' , 'dcba' ) )
- 代码规模计算: > 外层循环遍历s1每个字符,将内层循环执行n次而内层循环在s2中查找字符,每个字符的对比次数,分别是1、2…n中的一个,而且各不相同 两重**循环**,使用乘积来进行计算,所以总执行次数为: > $∑_{i=1}^n i = n(n+1)/2 = 1/2 n^2 + 1/2 n -> O(n^2)$ #### 解法2:排序比较 - 实现思路 > 将两个字符串都按照字母顺序排好序再逐个字符对比是否相同,如果相同则是变位词有任何不同就不是变位词  - 具体代码 ```python def anagramSolution2(s1,s2): alist1 = list(s1) # 转为列表 alist2 = list(s2) alist1.sort( ) # 分别排序 alist2.sort( ) pos = 0 matches = True while pos < len(s1) and matches: if alist1[pos] == alist2[pos]: pos = pos + 1 else: matches = False # 逐个对比 return matches print(anagramSolution2( ' abcde' , 'edcba' ) )- 代码规模计算:
乍看上去,本算法只有一个循环,最多执行n次,数量级是O(n),但是循环比较浅的两个sort函数并不是无偿的,而排序算法的时间数量级约是 $O(n^2)$ 或者 $O(n log_n)$,显然二者均大于$O(n)$
解法3:暴力枚举
- 实现思路
代码规模计算:将s1中出现的字符进行全排列,再查看s2是否出现在全排列列表中
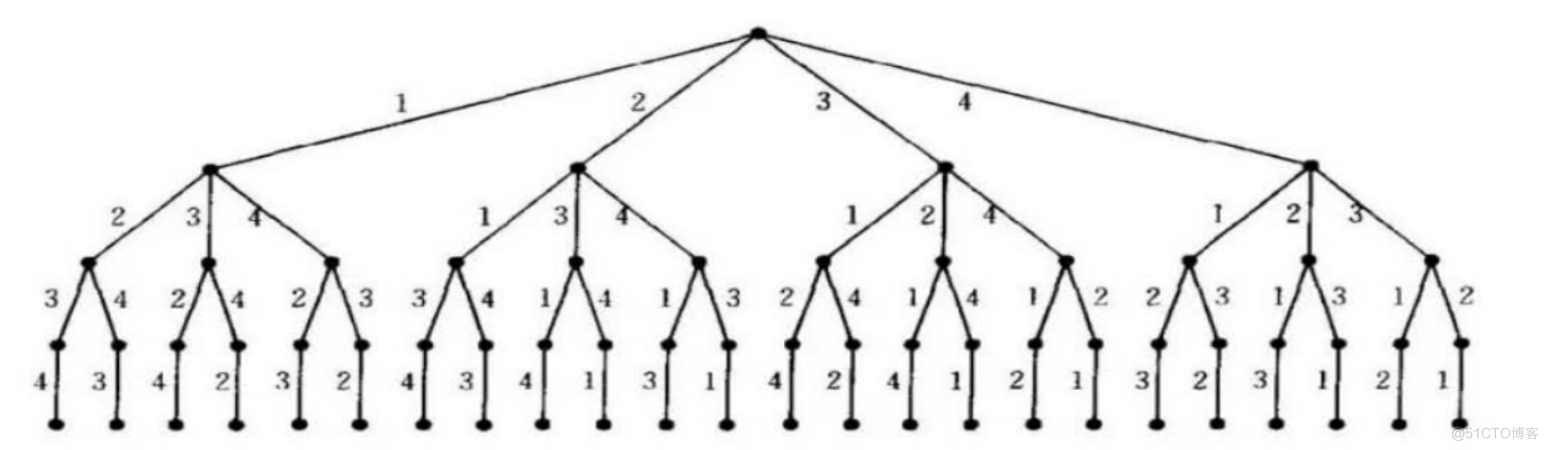
暴力枚举往往算作下策,因为 $n!$ 的增长速度是大于 $2^n$ 的
例如,对于20个字符长的词来说,将产生20!=2,432,902,008,176,640,000个候选词如果每微秒处理1个候选词的话,需要近8万年时间来做完所有的匹配。
因此暴力枚举恐怕不能算是个好算法
解法4:计数比较
- 实现思路
解题思路:对比两个词中每个字母出现的次数,如果26个字母出现的次数都相同的话,这两个字符串就一定是变位词
具体做法:为每个词设置一个26位的计数器,先检查每个词,在计数器中设定好每个字母出现的次数
计数完成后,进入比较阶段,看两个字符串的计数器是否相同,如果相同则输出是变位词的结论
def anagramSolution4(s1, s2): c1 = [0]* 26 c2 = [0]* 26 for i in range(len(s1) ): # 分别都计数 pos = ord( s1[i]) - ord( 'a' ) c1[pos] = c1[pos] +1 for i in range(len(s2) ): pos = ord(s2[i])_- ord ( 'a') c2[pos] = c2 [pos] +1 j = 0 still0K = True # 计数器比较 while j < 26 and still0K: if c1[j] == c2[j]: j = i + 1 else: stillOK = False return still0K print(anagramSolution4( " apple', 'pleap ' ))- 代码规模计算:
计数比较算法中有3个循环迭代,但不同于解法1那样存在嵌套循坏
前两个循环用于对字符串进行计数,操作次数等于字符串长度n第3个循环用于计数器比较,操作次数总是26次所以总操作次数为
$T_(n) = 2n +26$
其数量级为
$O(n)$
这是一个线性数量级的算法,也就是说是四种解法中性能最优的,但我们就应该选择它吗?
1.5 算法的选择
通过前面关于变位词的例子,我们知道第四种解法 计数比较的时间复杂度最小,但是值得一提的是该算法依赖于两个长度为26的计数器列表,用来保存字符,也就是说这相较于前三种需要更多的存储空间,所以最终要不要选择第四种解法是要自己进行权衡时间和空间之间的取舍的。
