-
开启事务。
-
命令进入队列。
- 执行事务。
Redis 事务命令,如表所示。
| 命 令 | 说 明 | 备 注 |
| --- | --- | --- |
| multi | 开启事务命令,之后的命令就进入队列,而不会马上被执行 | 在事务生存期间,所有的 Redis 关于数据结构的命令都会入队 |
| watch key1 [key2…] | 监听某些键,当被监听的键在事务执行前被修改,则事务会被回滚 | 使用乐观锁 |
| unwatch key1 [key2…] | 取消监听某些键 | —— |
| exec | 执行事务,如果被监听的键没有被修改,则采用执行命令,否则就回滚命令 | 在执行事务队列存储的命令前,Redis 会检测被监听的键值对有没有发生变化,如果没有则执行命令, 否则就回滚事务 |
| discard | 回滚事务 | 回滚进入队列的事务命令,之后就不能再用 exec 命令提交了 |
在 Redis 中开启事务是 multi 命令,而执行事务是 exec 命令。multi 到 exec 命令之间的 Redis 命令将采取进入队列的形式,直至 exec 命令的出现,才会一次性发送队列里的命令去执行,而在执行这些命令的时候其他客户端就不能再插入任何命令了,这就是 Redis 的事务机制。
Redis 命令执行事务的过程,如图 1 所示。
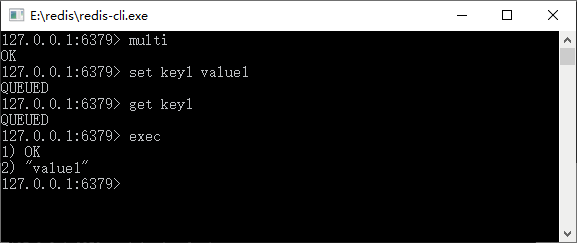
? 图 1 Redis命令执行事务的过程
从图 1 中可以看到,先使用 multi 启动了 Redis 的事务,因此进入了 set 和 get 命令,我们可以发现它并未马上执行,而是返回了一个“QUEUED”的结果。
这说明 Redis 将其放入队列中,并不会马上执行,当命令执行到 exec 的时候它就会把队列中的命令发送给 Redis 服务器,这样存储在队列中的命令就会被执行了,所以才会有“OK”和“value1”的输出返回。
如果回滚事务,则可以使用 discard 命令,它就会进入在事务队列中的命令,这样事务中的方法就不会被执行了,使用 discard 命令取消事务如图 2 所示。
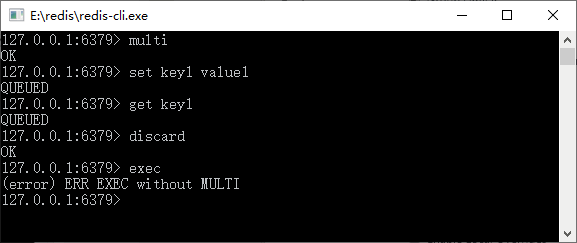
? 图 2 使用 discard 命令取消事务
当我们使用了 discard 命令后,再使用 exec 命令时就会报错,因为 discard 命令已经取消了事务中的命令,而到了 exec 命令时,队列里面已经没有命令可以执行了,所以就出现了报错的情况。
教程前面我们讨论过,在 Spring 中要使用同一个连接操作 Redis 命令的场景,这个时候我们借助的是 Spring 提供的 SessionCallback 接口,采用 Spring 去实现本节的命令,代码如下所示。
ApplicationContext applicationContext= new ClassPathXmlApplicationContext("applicationContext.xml");
RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class);
SessionCallback callBack = (SessionCallback) (RedisOperations ops)-> {
ops.multi();
ops.boundValueOps("key1").set("value1");
//注意由于命令只是进入队列,而没有被执行,所以此处采用get命令,而value却返回为null
String value = (String) ops.boundValueOps("key1").get();
System.out.println ("事务执行过程中,命令入队列,而没有被执行,所以value为空: value="+value);
//此时list会保存之前进入队列的所有命令的结果
List list = ops.exec(); //执行事务
//事务结束后,获取value1
value = (String) redisTemplate.opsForValue().get("key1");
return value;
};
//执行Redis的命令
String value = (String)redisTemplate.execute(callBack);
System.out.println(value);
这里采用了 Lambda 表达式(注意,Java 8 以后才引入 Lambda 表达式)来为 SessionCallBack 接口实现了业务逻辑。从代码看,使用了 SessionCallBack 接口,从而保证所有的命令都是通过同一个 Redis 的连接进行操作的。
在使用 multi 命令后,要特别注意的是,使用 get 等返回值的方法一律返回为空,因为在 Redis 中它只是把命令缓存到队列中,而没有去执行。使用 exec 后就会执行事务,执行完了事务后,执行 get 命令就能正常返回结果了。
最后使用 redisTemplate.execute(callBack); 就能执行我们在 SessionCallBack 接口定义的 Lambda 表达式的业务逻辑,并将获得其返回值。执行代码后可以看到这样的结果,如图 3 所示:
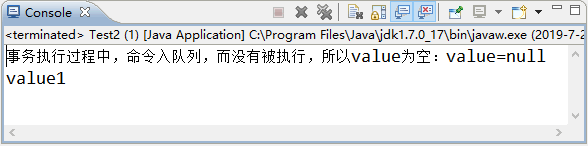
? 图 3 运行结果
需要再强调的是:这里打印出来的 value=null,是因为在事务中,所有的方法都只会被缓存到 Redis 事务队列中,而没有立即执行,所以返回为 null,这是在 Java 对 Redis 事务编程中开发者极其容易犯错的地方,一定要十分注意才行。如果我们希望得到 Redis 执行事务各个命令的结果,可以用这行代码:
List list = ops.exec(); //执行事务
这段代码将返回之前在事务队列中所有命令的执行结果,并保存在一个 List 中,我们只要在 SessionCallback 接口的 execute 方法中将 list 返回,就可以在程序中获得各个命令执行的结果了。
[](()探索Redis事务回滚
==============================================================================
对于 Redis 而言,不单单需要注意其事务处理的过程,其回滚的能力也和数据库不太一样,这也是需要特别注意的一个问题——Redis 事务遇到的命令格式正确而数据类型不符合,如图所示。
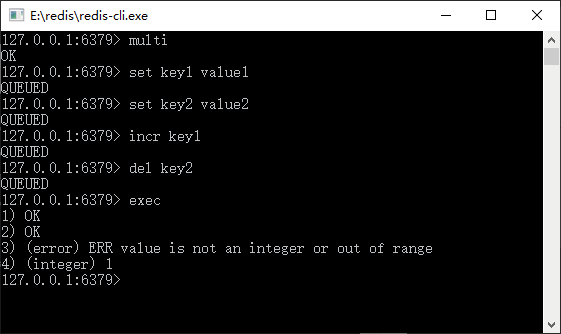
? 图 1 Redis事务遇到命令格式正确而数据类型不符合
从图 1 中可知,我们将 key1 设置为字符串,而使用命令 incr 对其自增,但是命令只会进入事务队列,而没有被执行,所以它不会有任何的错误发生,而是等待 exec 命令的执行。
当 exec 命令执行后,之前进入队列的命令就依次执行,当遇到 incr 时发生命令操作的数据类型错误,所以显示出了错误,而其之前和之后的命令都会被正常执行。注意,这里命令格式是正确的,问题在于数据类型,对于命令格式是错误的却是另外一种情形,如图 2 所示。
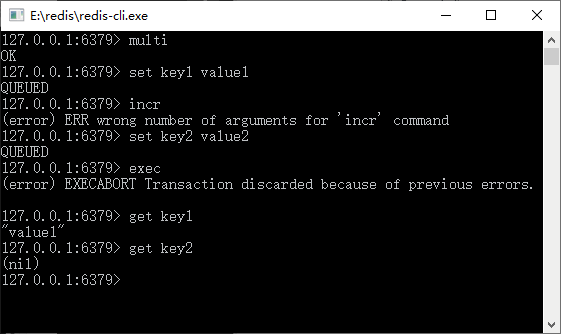
? 图 2 Redis事务遇到命令格式错误的
从图 2 中可以看到我们使用的 incr 命令格式是错误的,这个时候 Redis 会立即检测出来并产生错误,而在此之前我们设置了 key1,在此之后我们设置了 key2。当事务执行的时候,我们发现 key2 的值为空,说明被 Redis 事务回滚了。
通过上面两个例子,可以看出在执行事务命令的时候,在命令入队的时候,Redis 就会检测事务的命令是否正确,如果不正确则会产生错误。无论之前和之后的命令都会被事务所回滚,就变为什么都没有执行。
当命令格式正确,而因为操作数据结构引起的错误,则该命令执行出现错误,而其之前和之后的命令都会被正常执行。这点和数据库很不一样,这是需要读者注意的地方。
对于一些重要的操作,我们必须通过程序去检测数据的正确性,以保证 Redis 事务的正确执行,避免出现数据不一致的情况。Redis 之所以保持这样简易的事务,完全是为了保证移动互联网的核心问题——性能。
[](()Redis watch命令—监控事务
=====================================================================================
在 Redis 中使用 watch 命令可以决定事务是执行还是回滚。一般而言,可以在 multi 命令之前使用 watch 命令监控某些键值对,然后使用 multi 命令开启事务,执行各类对数据结构进行操作的命令,这个时候这些命令就会进入队列。
当 Redis 使用 exec 命令执行事务的时候,它首先会去比对被 watch 命令所监控的键值对,如果没有发生变化,那么它会执行事务队列中的命令,提交事务;如果发生变化,那么它不会执行任何事务中的命令,而去事务回滚。无论事务是否回滚,Redis 都会去取消执行事务前的 watch 命令,这个过程如图所示。
? 图 1 Redis 执行事务过程
Redis 参考了多线程中使用的 CAS(比较与交换,Compare And Swap)去执行的。在数据高并发环境的操作中,我们把这样的一个机制称为乐观锁。
这句话还是比较抽象,也不好理解。
所以先简要论述其操作的过程,当一条线程去执行某些业务逻辑,但是这些业务逻辑操作的数据可能被其他线程共享了,这样会引发多线程中数据不一致的情况。
为了克服这个问题,首先,在线程开始时读取这些多线程共享的数据,并将其保存到当前进程的副本中,我们称为旧值(old value),watch 命令就是这样的一个功能。
然后,开启线程业务逻辑,由 multi 命令提供这一功能。在执行更新前,比较当前线程副本保存的旧值和当前线程共享的值是否一致,如果不一致,那么该数据已经被其他线程操作过,此次更新失败。
为了保持一致,线程就不去更新任何值,而将事务回滚;否则就认为它没有被其他线程操作过,执行对应的业务逻辑,exec 命令就是执行“类似”这样的一个功能。
注意,“类似”这个字眼,因为不完全是,原因是 CAS 原理会产生 ABA 问题。所谓 ABA 问题来自于 CAS 原理的一个设计缺陷,它可能引发 ABA 问题,如表 1 所示。
| 时间顺序 | 线程1 | 线程2 | 说明 |
| --- | --- | --- | --- |
| T1 | X=A | — | 线程 1 加入监控 X |
| T2 | 复杂运算开始 | 修改 X=B | 线程 2 修改 X,此刻为 B |
| T3 | 处理简单业务 | — | |
| T4 | 修改 X=A | 线程 2 修改 X,此刻又变回 A | |
| T5 | 结束线程 2 | 线程 2 结束 | |
| T6 | 检测X=A,验证通过,提交事务 | — | CAS 原理检测通过,因为和旧值保持一致 |
在处理复杂运算的时候,被线程 2 修改的 X 的值有可能导致线程 1 的运算出错,而最后线程 2 将 X 的值修改为原来的旧值 A,那么到了线程 1 运算结束的时间顺序 T6,它将检测 X 的值是否发生变化,就会拿旧值 A 和当前的 X 的值 A 比对,结果是一致的,于是提交事务。
然后在复杂计算的过程中 X 被线程 2 修改过了,这会导致线程 1 的运算出错。在这个过程中,对于线程 2 而言,X 的值的变化为 A->B->A,所以 CAS 原理的这个设计缺陷被形象地称为“ABA 问题”。
仅仅记录一个旧值去比较是不足够的,还要通过其他方法避免 ABA 问题。常见的方法如 Hibernate 对缓存的持久对象(PO)加入字段 version 值,当每次操作一次该 PO,则 version=version+1,这样采用 CAS 原理探测 version 字段,就能在多线程的环境中,排除 ABA 问题,从而保证数据的一致性。
关于 CAS 和乐观锁的概念,本教程还会从更深层次讨论它们,暂时讨论到这里,当讨论完了 CAS 和乐观锁,读者再回头来看这个过程,就会有更深的理解了。
从上面的分析可以看出,Redis 在执行事务的过程中,并不会阻塞其他连接的并发,而只是通过比较 watch 监控的键值对去保证数据的一致性,所以 Redis 多个事务完全可以在非阻塞的多线程环境中并发执行,而且 Redis 的机制是不会产生 ABA 问题的,这样就有利于在保证数据一致的基础上,提高高并发系统的数据读/写性能。
下面演示一个成功提交的事务,如表 2 所示。
| 时刻 | 客户端 | 说 明 |
| --- | --- | --- |
| T1 | set key1 value1 | 初始化key1 |
| T2 | watch key1 | 监控 key1 的键值对 |
| T3 | multi | 开启事务 |
| T4 | set key2 value2 | 设置 key2 的值 |
| T5 | exec | 提交事务,Redis 会在这个时间点检测 key1 的值在 T2 时刻后,有没有被其他命令修改过,如果没有,则提交事务去执行 |
这里我们使用了 watch 命令设置了一个 key1 的监控,然后开启事务设置 key2,直至 exec 命令去执行事务,这个过程和图 2 所演示的一样。
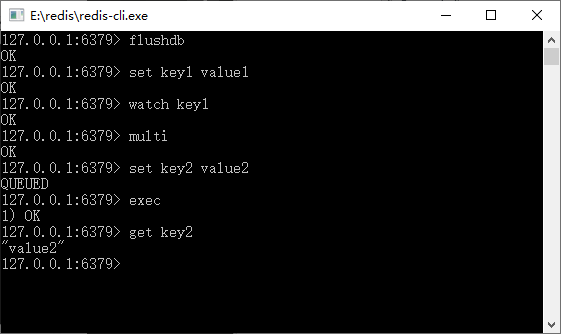
? 图 2 运行结果
这里我们看到了一个事务的过程,而 key2 也在事务中被成功设置。下面将演示一个提交事务的案例,如表 3 所示。
| 时刻 | 客户端1 | 客户端2 | 说 明 |
| --- | --- | --- | --- |
| T1 | set key1 value1 | | 客户端1:返回 OK |
| T2 | watch key1 | | 客户端1:监控 key1 |
| T3 | multi | | 客户端1:开启事务 |
| T4 | set key2 value2 | | 客户端1:事务命令入列 |
| T5 | —— | set key1 vall | 客户端2:修改 key1 的值 |
| T6 | exec | —— | 客户端1:执行事务,但是事务会先检査在 T2 时刻被监控的 key1 是否被 其他命令修改过。 因为客户端 2 修改过,所以它会回滚事务,事实上如果客户端执行的是 set key1 value1 命令,它也会认为 key1 被修改过,然后返回(nil),所以是不会产生 ABA 问题的 |
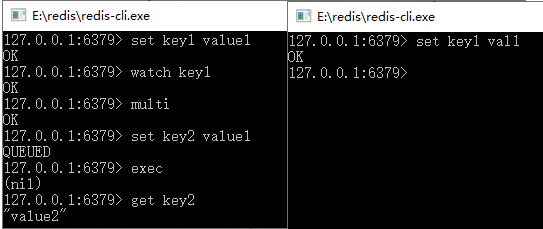
? 图 3 测试 Redis 事务回滚
在表 3 中有比较详尽的说明,注意 T2 和 T6 时刻命令的说明,使用 Redis 事务要掌握这些内容。
[](()使用流水线(pipelined)提高Redis的命令性能
===============================================================================================
在事务中 Redis 提供了队列,这是一个可以批量执行任务的队列,这样性能就比较高,但是使用 multi…exec 事务命令是有系统开销的,因为它会检测对应的锁和序列化命令。
有时候我们希望在没有任何附加条件的场景下去使用队列批量执行一系列的命令,从而提高系统性能,这就是 Redis 的流水线(pipelined)技术。
而现实中 Redis 执行读/写速度十分快,而系统的瓶颈往往是在网络通信中的延时,如图 1 所示。
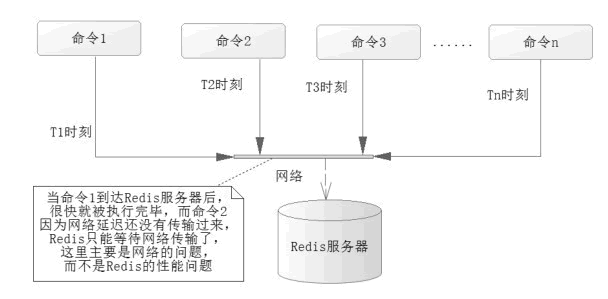
? 图 1 系统的瓶颈
在实际的操作中,往往会发生这样的场景,当命令 1 在时刻 T1 发送到 Redis 服务器后,服务器就很快执行完了命令 1,而命令 2 在 T2 时刻却没有通过网络送达 Redis 服务器,这样就变成了 Redis 服务器在等待命令 2 的到来,当命令 2 送达,被执行后,而命令 3 又没有送达 Redis,Redis 又要继续等待,依此类推,这样 Redis 的等待时间就会很长,很多时候在空闲的状态,而问题出在网络的延迟中,造成了系统瓶颈。
为了解决这个问题,可以使用 Redis 的流水线,但是 Redis 的流水线是一种通信协议,通过 Java API 或者使用 Spring 操作它,测试一下它的性能,代码如下。
Jedis jedis = pool.getResource();
long start = System.currentTimeMillis();
// 开启流水线
Pipeline pipeline = jedis.pipelined();
// 这里测试10万条的读/写2个操作
for (int i = 0; i < 100000; i++) {
int j = i + 1;
pipeline.set("pipelinekey" + j, "pipelinevalue" + j);
pipeline.get("pipelinekey" + j);
}
// pipeline.sync(); //这里只执行同步,但是不返回结果
// pipeline.syncAndReturnAll ();将返回执行过的命令返回的List列表结果
List result = pipeline.syncAndRetrunAll();
long end = System.currentTimeMillis();
// 计算耗时
System.err.println("耗时:" + (end - start) + "毫秒");
在电脑上测试这段代码,它的耗时在 550 毫秒到 700 毫秒之间,也就是不到 1 秒的时间就完成多达 10 万次读/写,可见其性能远超数据库。笔者的测试是 1 秒 2 万多次,可见使用流水线后其性能提高了数倍之多,效果十分明显。执行过的命令的返回值都会放入到一个 List 中。
注意,这里只是为了测试性能而已,当你要执行很多的命令并返回结果的时候,需要考虑 List 对象的大小,因为它会“吃掉”服务器上许多的内存空间,严重时会导致内存不足,引发 JVM 溢出异常,所以在工作环境中,是需要读者自己去评估的,可以考虑使用迭代的方式去处理。
在 Spring 中,执行流水线和执行事务的方法如出一辙都比较简单,使用 RedisTemplate 提供的 executePipelined 方法即可。下面将上面代码的功能修改为 Spring 的形式供大家参考,代码如下所示。
public static void testPipeline() {
Applicationcontext applicationcontext = new ClassPathXmlApplicationContext("applicationcontext.xml");
RedisTemplate redisTemplate = applicationcontext.getBean(RedisTemplate.class);
// 使用Java8的Lambda表达式
SessionCallback callBack = (SessionCallback) (RedisOperations ops)-> {
for (int i = 0; i<100000; i++) {
int j = i + 1;
ops . boundValueOps ("pipelinekey" + j ).set("piepelinevalue"+j);
ops.boundValueOps("pipelinekey" + j).get();
}
return null;
};
long start = System.currentTimeMillis();
//执行Redis的流水线命令
List resultList= redisTemplate.executePipelined(callBack);
long end = System.currentTimeMillis();
System.err.println(end-start);
}
这段代码进行测试,其性能慢于不用 RedisTemplate 的,测试消耗的时间大约在 1 100 毫秒到 1 300 毫秒之间,也就是消耗的时间大约是其两倍,但也属于完全可以接受的性能范围,同样的在执行很多命令的时候,也需要考虑其对运行环境内存空间的开销。
[](()Redis发布订阅模式
==============================================================================
当使用银行卡消费的时候,银行往往会通过微信、短信或邮件通知用户这笔交易的信息,这便是一种发布订阅模式,这里的发布是交易信息的发布,订阅则是各个渠道。这在实际工作中十分常用,Redis 支持这样的一个模式。
发布订阅模式首先需要消息源,也就是要有消息发布出来,比如例子中的银行通知。首先是银行的记账系统,收到了交易的命令,成功记账后,它就会把消息发送出来,这个时候,订阅者就可以收到这个消息进行处理了,观察者模式就是这个模式的典型应用了。下面用图 1 描述这样的一个过程。
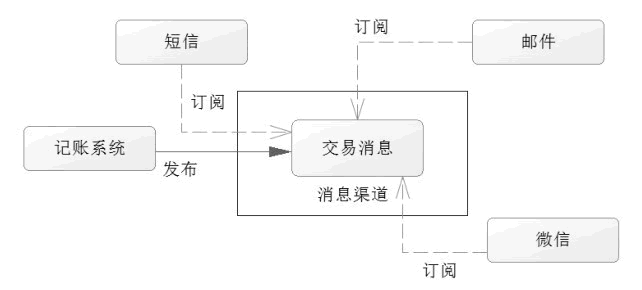
? 图 1 交易信息发布订阅机制
这里建立了一个消息渠道,短信系统、邮件系统和微信系统都在监听这个渠道,一旦记账系统把交易消息发送到消息渠道,则监听这个渠道的各个系统就可以拿到这个消息,这样就能处理各自的任务了。它也有利于系统的拓展,比如现在新增一个彩信平台,只要让彩信平台去监听这个消息渠道便能得到对应的消息了。
从上面的分析可以知道以下两点:
-
要有发送的消息渠道,让记账系统能够发送消息。
- 要有订阅者(短信、邮件、微信等系统)订阅这个渠道的消息。
同样的,Redis 也是如此。首先来注册一个订阅的客户端,这个时候使用 SUBSCRIBE 命令。
比如监听一个叫作 chat 的渠道,这个时候我们需要先打开一个客户端,这里记为客户端 1,然后输入命令:
SUBSCRIBE chat
这个时候客户端 1 就会订阅了一个叫作 chat 渠道的消息了。之后打开另外一个客户端,记为客户端 2,输入命令:
publish chat "let's go!!"
这个时候客户端 2 就向渠道 chat 发送消息:
"let's go!!"
我们观察客户端 1,就可以发现已经收到了消息,并有对应的信息打印出来。Redis 的发布订阅过程如图 2 和图 3 所示。
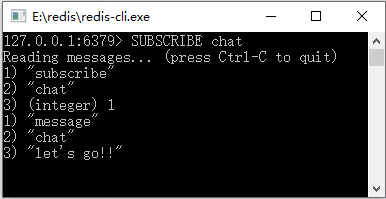
? 图 2 Redis的发布订阅过程(1)
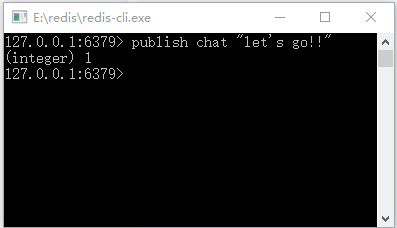
? 图 3 Redis的发布订阅过程(2)
其出现的先后顺序为先出现图 2 的上半部分,执行图 3 命令之后运行结果为图 2 所示,当发布消息的时候,对应的客户端已经获取到了这个信息。
下面在 Spring 的工作环境中展示如何配置发布订阅模式。首先提供接收消息的类,它将实现 org.springframework.data.redis.connection.MessageListener 接口,并实现接口定义的方法 public void onMessage(Message message,byte[]pattern),Redis 发布订阅监听类代码如下所示。
/ imports /
public class RedisMessageListener implements MessageListener {
private RedisTemplate redisTemplate;
/ 此处省略redisTemplate的 setter和getter方法 /
@Override
public void onMessage(Message message, byte[] bytes) {
// 获取消息
byte[] body = message.getBody();
// 使用值序列化器转换
String msgBody = (String) getRedisTemplate().getValueSerializer()
.deserialize(body);
System.err.println(msgBody);
// 获取 channel
byte[] channel = message.getChannel();
// 使用字符串序列化器转换
String channelStr = (String) getRedisTemplate().getStringSerializer()
.deserialize(channel);
System.err.println(channelStr);
// 渠道名称转换
String bytesStr = new String(bytes);
System.err.println(bytesStr);
}
}